AutoML での時系列予測のためのカレンダー特徴量
この記事では、回帰モデルの予測精度を高めるために AutoML によって作成されるカレンダーベースの特徴量について説明します。 休日はモデル化されたシステムの動作に強い影響を与える可能性があるため、休日の前後とその最中の時間は、時系列のパターンに偏りを与える可能性があります。 各休日は、学習者が効果を割り当てることができる既存のデータセットに対して時間枠を生成します。 これは、特定の製品に対して高い需要を生み出す休日などのシナリオで特に役立ちます。 AutoML での予測方法に関する一般的な情報については、方法の概要に関する記事を参照してください。 AutoML で予測モデルをトレーニングする手順と例については、時系列予測用に AutoML を設定するの記事を参照してください。
AutoML での特徴エンジニアリングの過程で、トレーニング データで与えられた datetime 型の列が、カレンダーベースの特徴量を表す新しい列に変換されます。 これらの特徴量は、回帰モデルでの複数周期の季節的なパターンの学習に役立ちます。 時系列の時間インデックスはトレーニング データの必須の列であるため、AutoML で常にカレンダー特徴量を作成できます。 datetime 型の他の列 (存在する場合) からもカレンダー特徴量が作成されます。 データ要件の詳細については、「AutoML でのデータの使用方法」のガイドを参照してください。
AutoML では、カレンダー特徴量の 2 つのカテゴリが考慮されます。日付と時刻の値のみに基づく標準の特徴量と、世界の国または地域に固有の休日の特徴量です。 この記事の残りの部分でこれらの特徴量について説明します。
標準のカレンダー特徴量
次の表は、AutoML の標準のカレンダー特徴量の完全なセットと出力例を示しています。 この例では、datetime 表現に標準の YY-mm-dd %H-%m-%d 形式を使用しています。
| 機能名 | 説明 | 2011-01-01 00:25:30 の場合の出力例 |
|---|---|---|
year |
暦年を表す数値の特徴量 | 2011 |
year_iso |
ISO 8601 で定義されている ISO 年を表します。 ISO の年は、年の週のうち木曜日がある最初の週から始まります。 たとえば、1 月 1 日が金曜日の場合、ISO 年は 1 月 4 日に始まります。 ISO 年は暦年とは異なる場合があります。 | 2010 |
half |
日付が年の前半か後半かを示す特徴量。 日付が 7 月 1 日より前の場合は 1、それ以外の場合は 2 です。 | |
quarter |
与えられた日付の四半期を表す数値の特徴量。 暦年の第 1、第 2、第 3、第 4 四半期を表す、1、2、3、4 のいずれかの値になります。 | 1 |
month |
カレンダー月を表す数値の特徴量。 1 から 12 の値になります。 | 1 |
month_lbl |
月の名前を表す文字列の特徴量。 | '1 月' |
day |
月の日付を表す数値の特徴量。 1 から 31 までの値になります。 | 1 |
hour |
1 日の時間を表す数値の特徴量。 0 から 23 までの値になります。 | 0 |
minute |
1 時間に含まれる分を表す数値の特徴量。 0 から 59 までの値になります。 | 25 |
second |
与えられた datetime の秒を表す数値の特徴量。 日付形式のみが指定されている場合は、0 と見なされます。 0 から 59 までの値になります。 | 30 |
am_pm |
時刻が午前か午後かを示す数値の特徴量。 正午より前の場合は 0、正午より後の場合は 1 です。 | 0 |
am_pm_lbl |
時刻が午前か午後かを示す文字列の特徴量。 | '午前' |
hour12 |
12 時間制の時刻を表す数値の特徴量。 午前中の場合は 0 から 12 まで、午後の場合は 1 から 11 までの値になります。 | 0 |
wday |
曜日を表す数値の特徴量。 0 から 6 までの値になります。0 が月曜日に当たります。 | 5 |
wday_lbl |
曜日の名前を表す文字列の特徴量。 | |
qday |
四半期の通算日を表す数値の特徴量。 1 から 92 までの値になります。 | 1 |
yday |
年間通算日を表す数値の特徴量。 1 から 365 までの値か、閏年の場合は 1 から 366 までの値になります。 | 1 |
week |
ISO 8601 で定義されている ISO 週を表す数値の特徴量。 ISO 週は常に、月曜日に始まり、日曜日に終わります。 1 から 52 まで、あるいは、1 月 1 日が木曜日に当たる年または 1 月 1 日が水曜日に当たる閏年の場合は 53 までの値になります。 | 52 |
すべてのケースで標準のカレンダー特徴量の完全なセットが作成されわけではありません。 生成されるセットは、時系列の頻度と、トレーニング データに時間インデックスに加えて datetime の特徴量が含まれているかどうかによって異なります。 次の表は、さまざまな列の種類に対して作成される特徴量を示しています。
| 列の目的 | カレンダーの機能 |
|---|---|
| 時間インデックス | 完全なセットから、他の特徴量と高い相関関係を持つカレンダー特徴量を除いたもの。 たとえば、時系列の頻度が毎日の場合、毎日よりも細かい頻度の特徴量は有用な情報を提供しないため、削除されます。 |
| 他の datetime 列 | Year、Month、Day、DayOfWeek、DayOfYear、QuarterOfYear、WeekOfMonth、Hour、Minute、Second で構成される縮小されたセット。 列が時刻のない日付である場合、Hour、Minute、Second は 0 になります。 |
休日の特徴量
AutoML では、必要に応じて、特定の国または地域の休日を表す特徴量を作成できます。 これらの特徴量は、AutoML で ISO 国コードを指定できる country_or_region_for_holidays パラメーターを使用して構成します。
注意
休日の特徴量は、毎日の頻度を持つ時系列に対してのみ作成できます。
次の表は、休日の特徴量をまとめたものです。
| 機能名 | 説明 |
|---|---|
Holiday |
日付が国または地域の休日であるかどうかを指定する文字列の特徴量。 休日から一定範囲の日もマークされます。 |
isPaidTimeOff |
与えられた国または地域でその日が "有給休暇" である場合に 1 の値を取るバイナリの特徴量。 |
AutoML では、休日情報のソースとして Azure Open Datasets が使用されます。 詳細については、PublicHolidays のドキュメントを参照してください。
休日の特徴量の生成について理解を深めるために、次のデータ例を考えてみましょう。
このデータで米国の休日の特徴量を作るには、次のサンプル コードに示すように、予測設定で country_or_region_for_holiday を "US" に設定します。
from azure.ai.ml import automl
# create a forcasting job
forecasting_job = automl.forecasting(
compute='test_cluster', # Name of single or multinode AML compute infrastructure created by user
experiment_name=exp_name, # name of experiment
training_data=sample_data,
target_column_name='demand',
primary_metric='NormalizedRootMeanSquaredError',
n_cross_validations=3,
enable_model_explainability=True
)
# set custom forecast settings
forecasting_job.set_forecast_settings(
time_column_name='timeStamp',
country_or_region_for_holidays='US'
)
生成される休日の特徴量は次の出力のようになります。
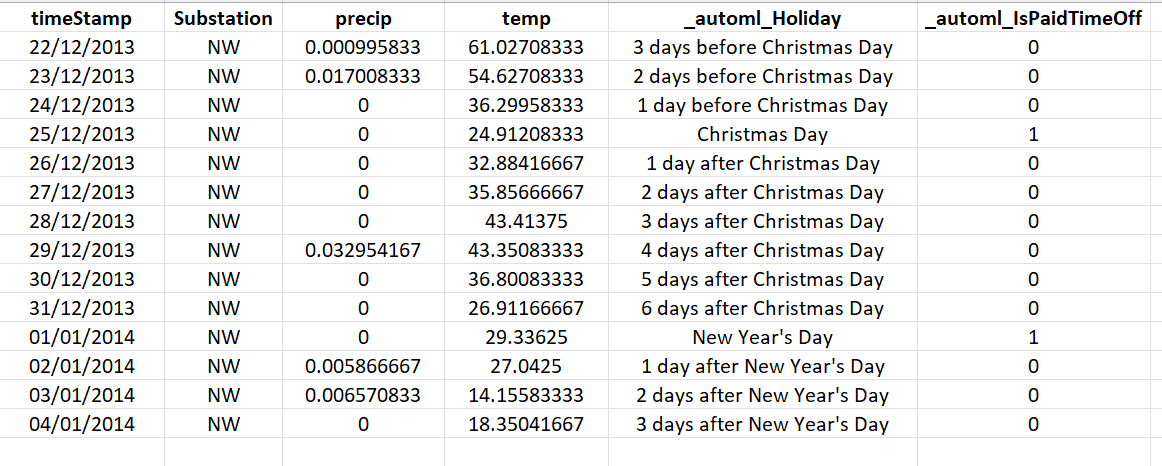
生成された特徴量には、列名の前にプレフィックス _automl_ が付いていることに注意してください。 AutoML では通常、このプレフィックスを使用して、入力された特徴量とエンジニアリングされた特徴量を区別します。
次の手順
- 時系列予測モデルをトレーニングするように AutoML を設定する方法の詳細について確認します。
- AutoML での予測に関してよく寄せられる質問を参照します。
- AutoML 予測のラグ機能について確認します。
- AutoML が機械学習を使用して予測モデルを構築する方法について確認します。