現在のモデル デバッグ プラクティスで最大の課題の 1 つは、集計したメトリックを使用して、ベンチマーク データセットでモデルをスコア付けすることです。 モデルの正確性は、データのサブグループ間で一様でない場合があり、モデルが失敗する頻度が高い入力コーホートが存在する可能性があります。 これらの失敗は、信頼性と安全性の欠如、公平性の問題の出現、機械学習に対する信頼の喪失につながります。

エラー分析は、集計した正確性メトリックとは異なります。 これは透過的な方法で開発者にエラーの分布を公開し、開発者が効率的にエラーを特定して診断できるようにします。
責任ある AI ダッシュボードのエラー分析コンポーネントを使用すると、機械学習の従事者はモデルの失敗分布をより深く理解でき、データの誤ったコーホートをすばやく特定できるようになります。 このコンポーネントは、全体的なベンチマーク エラー率と比較してエラー率が高いデータのコーホートを識別します。 これは次の方法を通じてモデル ライフサイクル ワークフローの識別段階に貢献します。
- エラー率が高いコーホートを明らかにするデシジョン ツリー。
- 入力特徴がコーホート全体のエラー率にどのように影響するかを視覚化するヒートマップ。
エラーの不一致は、トレーニング データ内の特定の人口統計グループや頻繁に観察されない入力コーホートに対してシステムのパフォーマンスが低い場合に発生する可能性があります。
このコンポーネントの機能は、モデル エラー プロファイルを生成するエラー分析パッケージから提供されます。
次のことを行う必要がある場合は、エラー分析を使用します。
- モデルの失敗がデータセット全体で、および複数の入力と特徴のディメンション間でどのように分散されるかについて深く理解する。
- 集計パフォーマンス メトリックを分割して、誤ったコーホートを自動的に検出して、対象を絞った軽減策の手順を実行できるようにします。
エラー ツリー
多くの場合、エラー パターンは複雑であり、複数の機能が含まれます。 すべての機能の組み合わせを探索して、重大な障害がある隠されたデータポケットを見つけるのが難しい場合があります。
負荷を軽減するために、バイナリ ツリーの視覚化では、ベンチマーク データが解釈可能なサブグループ (エラー率が予想外に高いか、低い) に自動的にパーティション分割されます。 言い換えると、ツリーでは入力特徴を使用して、モデル エラーが成功から最大限に分離されます。 データ サブグループを定義するノードごとに、次の情報を調査できます。
- エラー率: モデルが正しくないノード内のインスタンスの部分。 視覚化では、赤の色の強度によってこの値が表示されます。
- エラー カバレッジ: ノードに含まれるすべてのエラーの部分。 視覚化では、ノードのフィル レートを通じてこの値が表示されます。
- データ表現: エラー ツリーの各ノード内のインスタンスの数。 視覚化では、ノードへの入力エッジの太さと、ノード内のインスタンスの合計数を通じて、この値が表示されます。

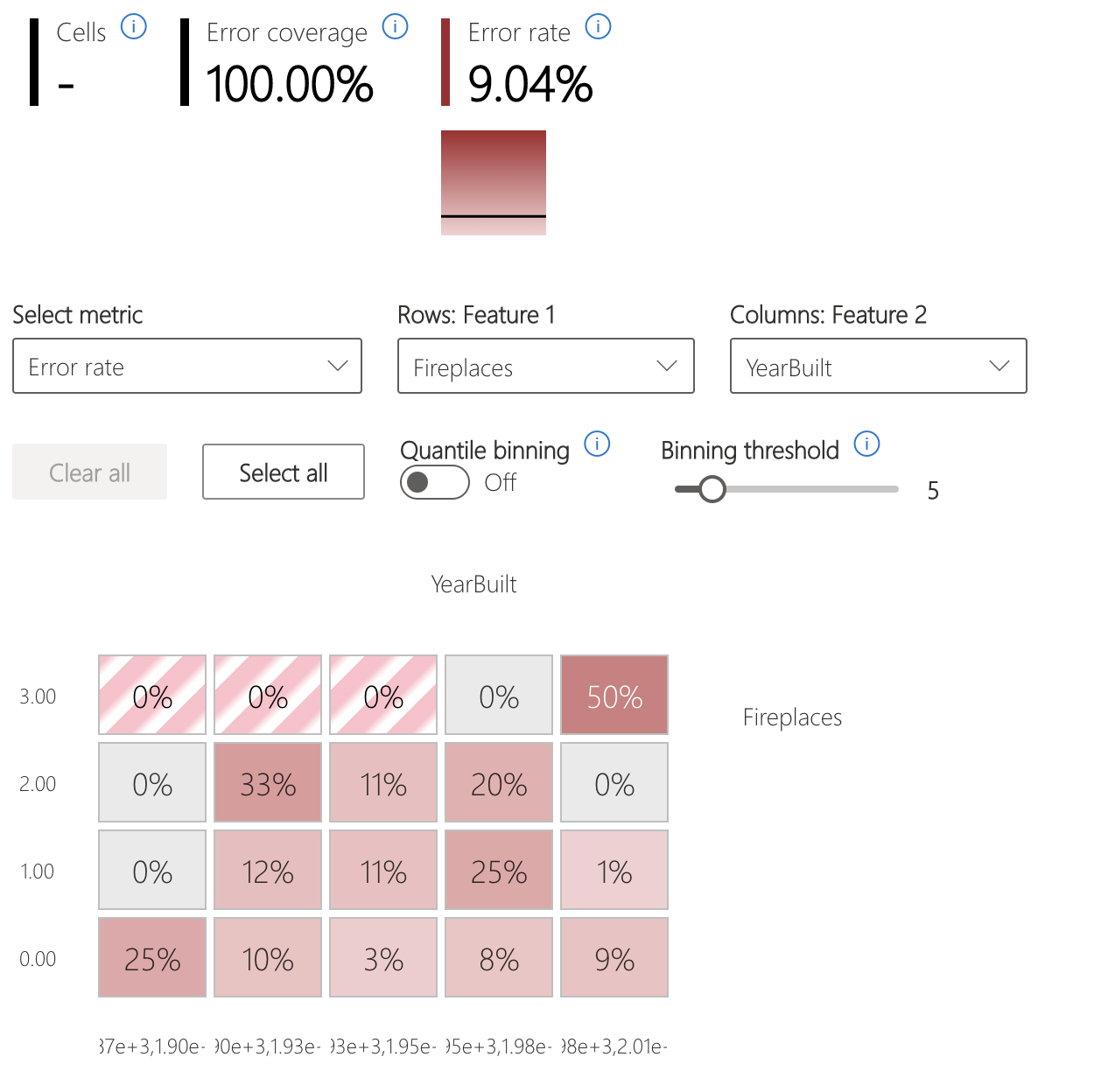
エラー ヒートマップ
このビューは、入力フィーチャの 1 次元または 2 次元グリッドに基づいてデータをスライスします。 分析に使用する入力機能を選択できます。
ヒートマップでは、暗い赤色を使用してエラーの多いセルを視覚化し、それらの領域に注意を向けます。 これは、エラー テーマがパーティション間で異なる場合 (これは実際に頻繁に発生します) に特に便利です。 このエラー識別ビューでは、知識または仮説が分析を導き、障害を理解するために最も重要な特徴を理解するのに役立ちます。
次のステップ
- CLI と SDK または Azure Machine Learning スタジオ UI を使用して責任ある AI ダッシュボードを生成する方法について学習します。
- サポートされているエラー分析の視覚化を確認します。
- 責任ある AI ダッシュボードで観察された分析情報に基づいて責任ある AI スコアカードを生成する方法について説明します。