スタジオを使用して、デザイナーでトレーニングされたモデルをデプロイする
この記事では、Azure Machine Learning スタジオのオンライン (リアルタイム) エンドポイントとしてデザイナー モデルをデプロイする方法について説明します。
登録後またはダウンロード後、他のモデルと同じように、デザイナーでトレーニングされたモデルを使用できます。 エクスポートされたモデルは、モノのインターネット (IoT) やローカルのデプロイなどのユース ケースでデプロイできます。
スタジオでのデプロイは、次の手順で構成されています。
- トレーニングされたモデルを登録します。
- モデルのエントリ スクリプトと Conda 依存関係ファイルをダウンロードします。
- (省略可能) エントリ スクリプトを構成します。
- コンピューティング先にモデルをデプロイします。
モデルの登録やファイルのダウンロードの手順を省略するために、デザイナーでモデルを直接デプロイすることもできます。 これは、迅速なデプロイに役立ちます。 詳細については、デザイナーを使用してモデルをデプロイする方法に関するページを参照してください。
デザイナーでトレーニングされたモデルは、SDK またはコマンド ライン インターフェイス (CLI) を使用してデプロイすることもできます。 詳細については、「Azure Machine Learning を使用して既存のモデルをデプロイする」を参照してください。
前提条件
次のいずれかのコンポーネントを含む完成したトレーニング パイプライン:
モデルを登録する
トレーニング パイプラインが完了したら、トレーニングされたモデルを Azure Machine Learning ワークスペースに登録して、他のプロジェクトのモデルにアクセスできるようにします。
[Train Model](モデルのトレーニング) コンポーネントを選択します。
右側のウィンドウの [出力 + ログ] タブを選択します。
[モデルの登録] アイコンを選択します
 。
。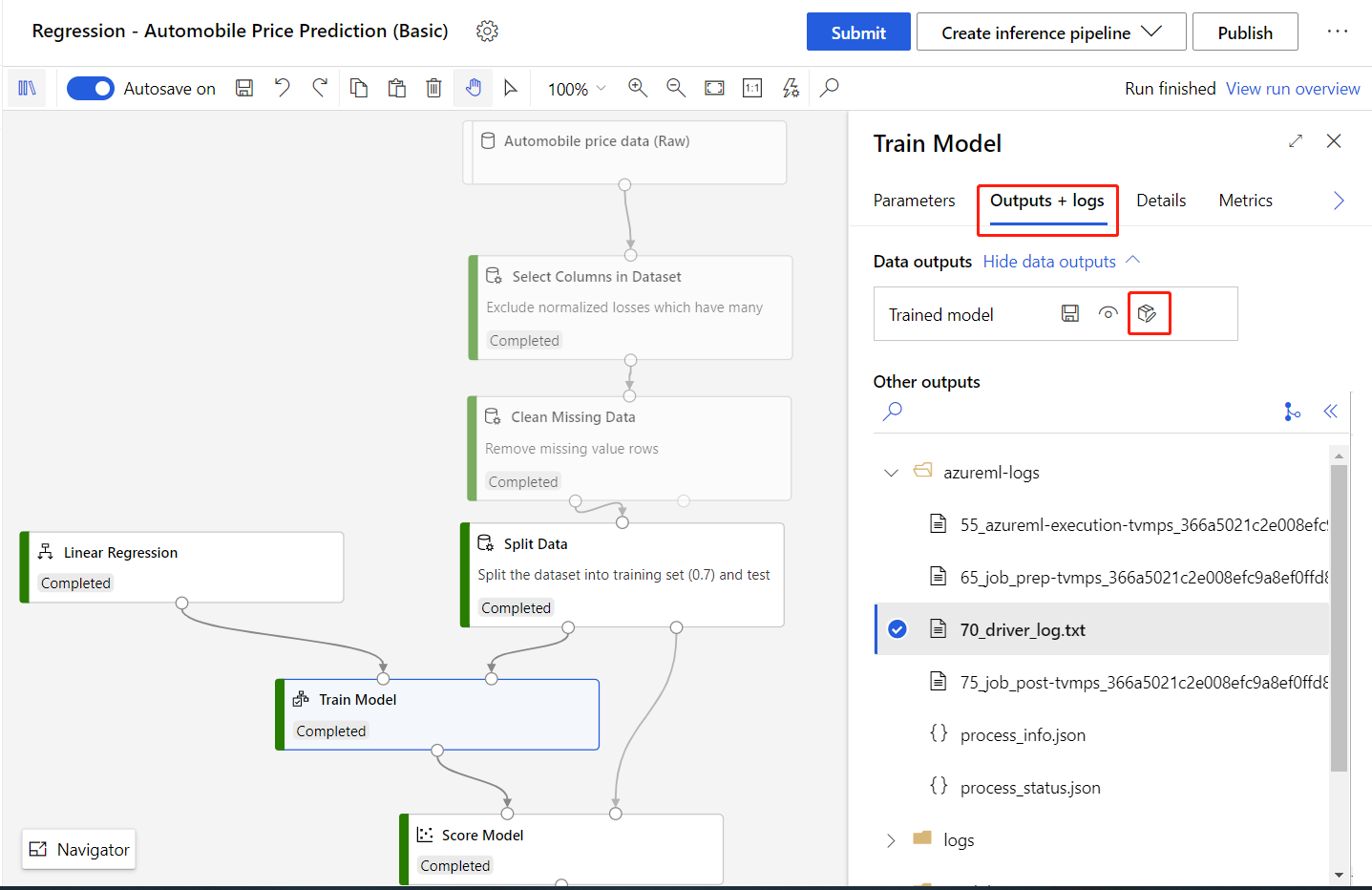
モデルの名前を入力し、 [保存] を選択します。
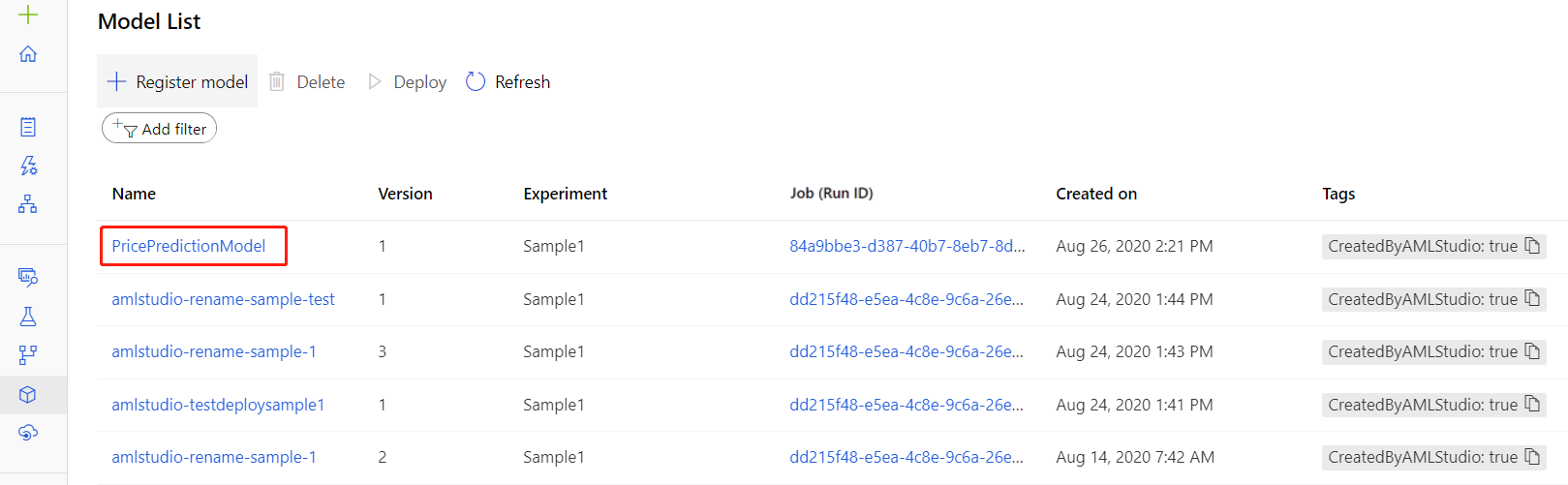
モデルを登録した後は、スタジオの [モデル] アセット ページで確認できます。
エントリ スクリプト ファイルと Conda 依存関係ファイルをダウンロードする
Azure Machine Learning スタジオにモデルをデプロイするには、次のファイルが必要です。
エントリ スクリプト ファイル - トレーニングされたモデルを読み込み、要求から入力データを処理し、リアルタイムの推論を行い、結果を返します。 モデルのトレーニング コンポーネントが完了すると、デザイナーによって
score.pyエントリ スクリプト ファイルが自動的に生成されます。Conda 依存関係ファイル - Web サービスが依存する PIP および Conda パッケージを指定します。 モデルのトレーニング コンポーネントが完了すると、デザイナーによって
conda_env.yamlファイルが自動的に作成されます。
これら 2 つのファイルは、モデルのトレーニング コンポーネントの右側のウィンドウでダウンロードできます。
[Train Model](モデルのトレーニング) コンポーネントを選択します。
[出力 + ログ] タブでフォルダー
trained_model_outputsを選択します。conda_env.yamlファイルとscore.pyファイルをダウンロードします。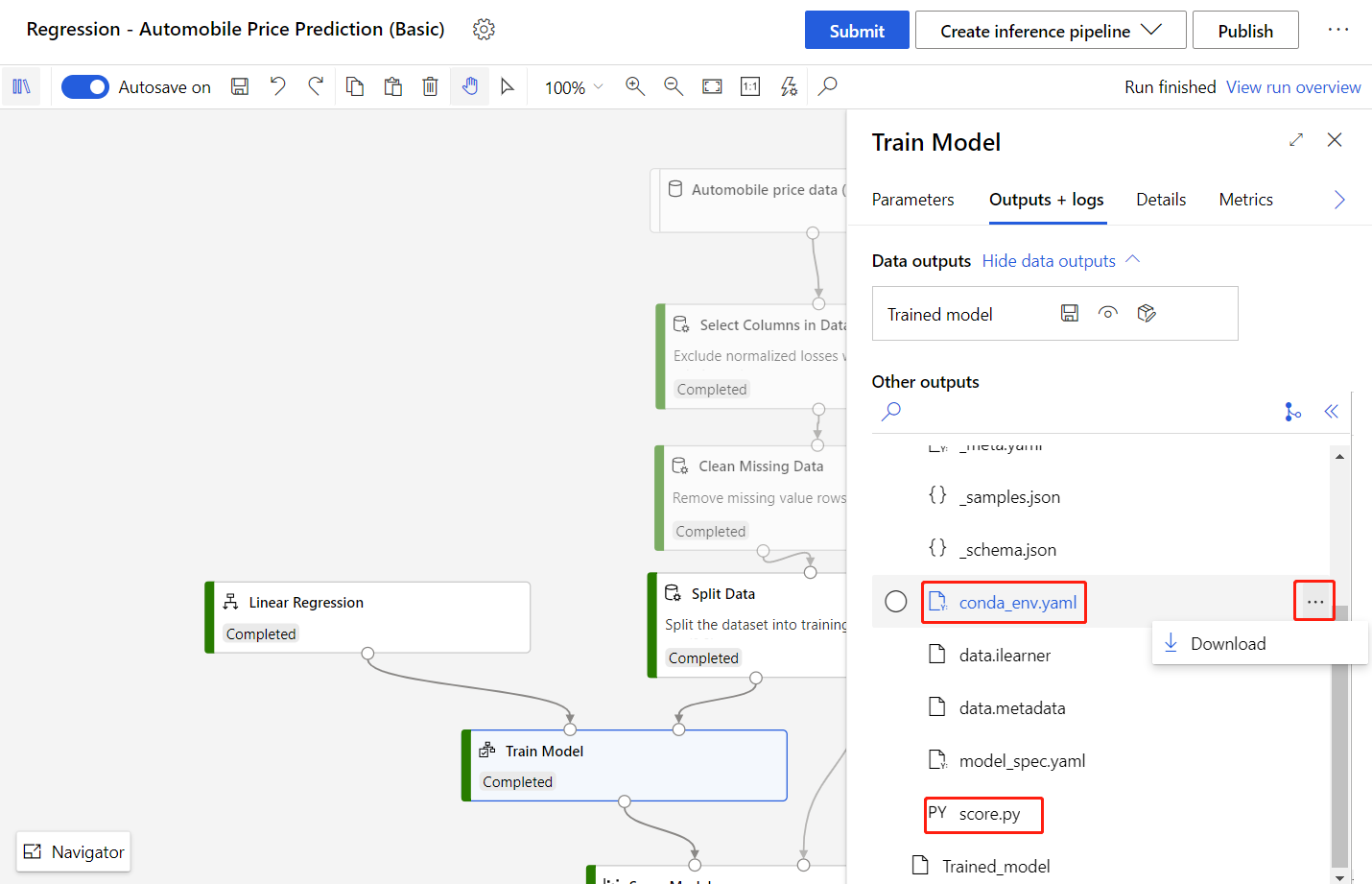
または、モデルを登録した後、 [モデル] アセット ページからファイルをダウンロードすることもできます。
[モデル] アセット ページに移動します。
デプロイするモデルを選択します。
[成果物] タブを選択します。
trained_model_outputsフォルダーを選択しますconda_env.yamlファイルとscore.pyファイルをダウンロードします。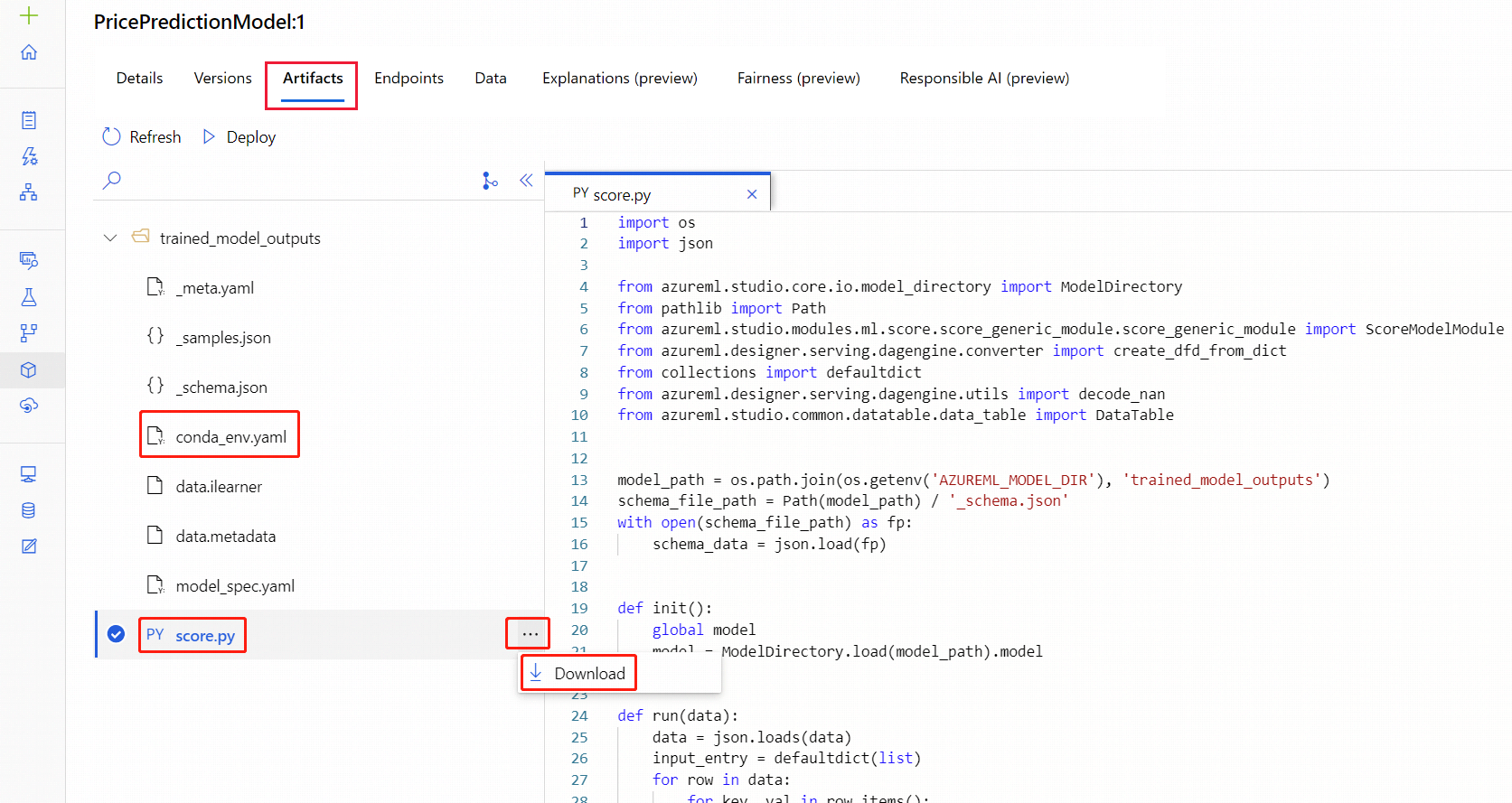
Note
score.py ファイルには、モデルのスコアリング コンポーネントとほぼ同じ機能が用意されています。 ただし、SVD レコメンダーのスコアリング、ワイドかつディープなレコメンダーのスコアリング、Vowpal Wabbit モデルのスコアリングのような一部のコンポーネントには、さまざまなスコアリング モード パラメーターがあります。 これらのパラメーターは、エントリ スクリプトで変更することもできます。
score.py ファイルでのパラメーターの設定の詳細については、エントリ スクリプトの構成に関するセクションを参照してください。
モデルをデプロイする
必要なファイルをダウンロードしたら、モデルをデプロイする準備は完了です。
[モデル] アセット ページで、登録されているモデルを選択します。
[デプロイ] を選択し、 [Deploy to web service](Web サービスにデプロイする) を選択します。
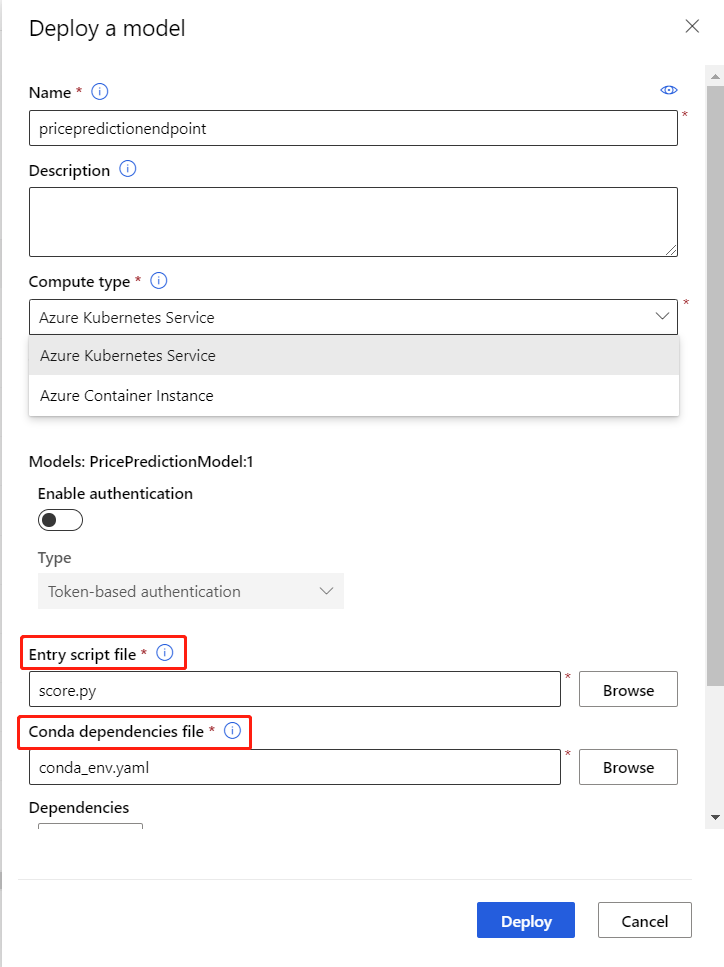
[構成] メニューで、次の情報を入力します。
- エンドポイントの名前を入力します。
- Azure Kubernetes Service または Azure Container Instance のどちらにモデルをデプロイするかを選択します。
- エントリ スクリプト ファイルの
score.pyをアップロードします。 - Conda 依存関係ファイルの
conda_env.ymlをアップロードします。
ヒント
[詳細] 設定では、CPU/メモリ容量およびデプロイのためのその他のパラメーターを設定できます。 これらの設定は、大量のメモリ (約 4 GB) を消費する PyTorch モデルなどの特定のモデルにおいて重要です。
[デプロイ] を選択して、モデルをオンライン エンドポイントとしてデプロイします。
オンライン エンドポイントを使用する
デプロイが成功した後は、[エンドポイント] アセット ページでエンドポイントを見つけることができます。 そこには、クライアントがエンドポイントにリクエストを送信するために使用できる REST エンドポイントがあります。
注意
また、デザイナーによってテスト用のサンプル データ json ファイルも生成されます。_samples.json は、trained_model_outputs フォルダーからダウンロードできます。
オンライン エンドポイントを使用するには、次のコード サンプルを使用します。
import json
from pathlib import Path
from azureml.core.workspace import Workspace, Webservice
service_name = 'YOUR_SERVICE_NAME'
ws = Workspace.get(
name='WORKSPACE_NAME',
subscription_id='SUBSCRIPTION_ID',
resource_group='RESOURCEGROUP_NAME'
)
service = Webservice(ws, service_name)
sample_file_path = '_samples.json'
with open(sample_file_path, 'r') as f:
sample_data = json.load(f)
score_result = service.run(json.dumps(sample_data))
print(f'Inference result = {score_result}')
コンピューター ビジョンに関連するオンライン エンドポイントを使用する
Web サービスの入力として受け入れられるのは文字列だけなので、コンピューター ビジョンに関連するオンライン エンドポイントを使用する場合は、イメージをバイトに変換する必要があります。 サンプル コードを次に示します:
import base64
import json
from copy import deepcopy
from pathlib import Path
from azureml.studio.core.io.image_directory import (IMG_EXTS, image_from_file, image_to_bytes)
from azureml.studio.core.io.transformation_directory import ImageTransformationDirectory
# image path
image_path = Path('YOUR_IMAGE_FILE_PATH')
# provide the same parameter setting as in the training pipeline. Just an example here.
image_transform = [
# format: (op, args). {} means using default parameter values of torchvision.transforms.
# See https://pytorch.org/docs/stable/torchvision/transforms.html
('Resize', 256),
('CenterCrop', 224),
# ('Pad', 0),
# ('ColorJitter', {}),
# ('Grayscale', {}),
# ('RandomResizedCrop', 256),
# ('RandomCrop', 224),
# ('RandomHorizontalFlip', {}),
# ('RandomVerticalFlip', {}),
# ('RandomRotation', 0),
# ('RandomAffine', 0),
# ('RandomGrayscale', {}),
# ('RandomPerspective', {}),
]
transform = ImageTransformationDirectory.create(transforms=image_transform).torch_transform
# download _samples.json file under Outputs+logs tab in the right pane of Train Pytorch Model component
sample_file_path = '_samples.json'
with open(sample_file_path, 'r') as f:
sample_data = json.load(f)
# use first sample item as the default value
default_data = sample_data[0]
data_list = []
for p in image_path.iterdir():
if p.suffix.lower() in IMG_EXTS:
data = deepcopy(default_data)
# convert image to bytes
data['image'] = base64.b64encode(image_to_bytes(transform(image_from_file(p)))).decode()
data_list.append(data)
# use data.json as input of consuming the endpoint
data_file_path = 'data.json'
with open(data_file_path, 'w') as f:
json.dump(data_list, f)
エントリ スクリプトを構成する
SVD レコメンダーのスコアリング、ワイドかつディープなレコメンダーのスコアリング、Vowpal Wabbit モデルのスコアリングのようなデザイナーの一部のコンポーネントには、さまざまなスコアリング モード パラメーターがあります。
このセクションでは、エントリ スクリプト ファイルでもこれらのパラメーターを更新する方法について説明します。
次の例では、トレーニングされたワイドかつディープなレコメンダー モデルの既定の動作を更新します。 既定では、score.py ファイルは、ユーザーと項目間の評価を予測するように Web サービスに指示します。
エントリ スクリプト ファイルを変更して項目の推奨を作成し、recommender_prediction_kind パラメーターを変更することによって推奨される項目を返すことができます。
import os
import json
from pathlib import Path
from collections import defaultdict
from azureml.studio.core.io.model_directory import ModelDirectory
from azureml.designer.modules.recommendation.dnn.wide_and_deep.score. \
score_wide_and_deep_recommender import ScoreWideAndDeepRecommenderModule
from azureml.designer.serving.dagengine.utils import decode_nan
from azureml.designer.serving.dagengine.converter import create_dfd_from_dict
model_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), 'trained_model_outputs')
schema_file_path = Path(model_path) / '_schema.json'
with open(schema_file_path) as fp:
schema_data = json.load(fp)
def init():
global model
model = ModelDirectory.load(load_from_dir=model_path)
def run(data):
data = json.loads(data)
input_entry = defaultdict(list)
for row in data:
for key, val in row.items():
input_entry[key].append(decode_nan(val))
data_frame_directory = create_dfd_from_dict(input_entry, schema_data)
# The parameter names can be inferred from Score Wide and Deep Recommender component parameters:
# convert the letters to lower cases and replace whitespaces to underscores.
score_params = dict(
trained_wide_and_deep_recommendation_model=model,
dataset_to_score=data_frame_directory,
training_data=None,
user_features=None,
item_features=None,
################### Note #################
# Set 'Recommender prediction kind' parameter to enable item recommendation model
recommender_prediction_kind='Item Recommendation',
recommended_item_selection='From All Items',
maximum_number_of_items_to_recommend_to_a_user=5,
whether_to_return_the_predicted_ratings_of_the_items_along_with_the_labels='True')
result_dfd, = ScoreWideAndDeepRecommenderModule().run(**score_params)
result_df = result_dfd.data
return json.dumps(result_df.to_dict("list"))
ワイドかつディープなレコメンダーおよび Vowpal Wabbit モデルでは、次のメソッドを使用してスコアリング モード パラメーターを構成できます。
- パラメーター名は、Vowpal Wabbit モデルのスコアリングとワイドかつディープなレコメンダーのスコアリングのパラメーター名の小文字とアンダースコアの組み合わせです。
- モードの型パラメーター値は、対応するオプション名の文字列です。 上記のコードのレコメンダー予測の種類を例にとると、値は
'Rating Prediction'または'Item Recommendation'にすることができます。 他の値は許容されません。
SVD レコメンダーのトレーニングされたモデルでは、パラメーターの名前と値は明確ではありませんが、以下の表を参照してパラメータの設定方法を決定することができます。
| SVD レコメンダーのスコアリングのパラメーター名 | エントリ スクリプト ファイル内のパラメーター名 |
|---|---|
| レコメンダーの予測の種類 | prediction_kind |
| 推奨項目の選択 | recommended_item_selection |
| 1 人のユーザーの推奨プールの最小サイズ | min_recommendation_pool_size |
| ユーザーに推奨する項目の最大数 | max_recommended_item_count |
| 項目の予測された評価をラベルと共に返すかどうか | return_ratings |
次のコードは、6 つのパラメータすべてを使用して、予測されたレーティングが添付された評価済みの項目を推奨する SVD レコメンダーのパラメータ設定方法を示しています。
score_params = dict(
learner=model,
test_data=DataTable.from_dfd(data_frame_directory),
training_data=None,
# RecommenderPredictionKind has 2 members, 'RatingPrediction' and 'ItemRecommendation'. You
# can specify prediction_kind parameter with one of them.
prediction_kind=RecommenderPredictionKind.ItemRecommendation,
# RecommendedItemSelection has 3 members, 'FromAllItems', 'FromRatedItems', 'FromUndatedItems'.
# You can specify recommended_item_selection parameter with one of them.
recommended_item_selection=RecommendedItemSelection.FromRatedItems,
min_recommendation_pool_size=1,
max_recommended_item_count=3,
return_ratings=True,
)
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示