バッチ エンドポイント (プレビュー) を使用して、Fabric から Azure Machine Learning モデルを実行する
適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
この記事では、Microsoft Fabric から Azure Machine Learning バッチ デプロイを使用する方法について説明します。 ワークフローはバッチ エンドポイントにデプロイされたモデルを使用しますが、Fabric からのバッチ パイプライン デプロイの使用もサポートしています。
重要
現在、この機能はパブリック プレビュー段階にあります。 このプレビュー バージョンはサービス レベル アグリーメントなしで提供されており、運用環境のワークロードに使用することは推奨されません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。
詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
前提条件
- Microsoft Fabric サブスクリプションを取得します。 または、無料の Microsoft Fabric 試用版にサインアップします。
- Microsoft Fabric にサインインします。
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
- Azure Machine Learning ワークスペース。 準備できていない場合は、ワークスペースの管理方法に関するページの手順を使用して作成します。
- ワークスペースに次のアクセス許可があることを確認します。
- バッチ エンドポイントとバッチ デプロイを作成または管理する: 所有者または共同作成者のロール、あるいは
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*を許可するカスタム ロールを使用します。 - ワークスペース リソース グループに ARM デプロイを作成する: 所有者または共同作成者のロール、あるいはワークスペースがデプロイされているリソース グループで
Microsoft.Resources/deployments/writeを許可するカスタム ロールを使用します。
- バッチ エンドポイントとバッチ デプロイを作成または管理する: 所有者または共同作成者のロール、あるいは
- ワークスペースに次のアクセス許可があることを確認します。
- バッチ エンドポイントにデプロイされたモデル。 持っていない場合は、「バッチ エンドポイントにスコアリング用のモデルをデプロイする」の手順を使用して作成します。
- スコアリングに使用する heart-unlabeled.csv サンプル データセットをダウンロードします。
アーキテクチャ
Azure Machine Learning を使用して、Fabric の OneLake に格納されているデータに直接アクセスします。 しかし、OneLake の機能を使って Lakehouse 内にショートカットを作成し、Azure Data Lake Gen2 に格納されたデータを読み書きすることができます。 Azure Machine Learning は Azure Data Lake Gen2 ストレージをサポートするため、このセットアップにより、Fabric および Azure Machine Learning を一緒に使用できるようになります。 データ アーキテクチャは次のとおりです。

データ アクセスを構成する
Fabric および Azure Machine Learning が同じデータをコピーしなくても読み取りと書き込みを行えるようにするには、OneLake のショートカットと Azure Machine Learning データストアを活用します。 OneLake のショートカットとデータストアを同じストレージ アカウントに指定することで、Fabric および Azure Machine Learning の両方が基になる同じデータから読み取り、基になる同じデータに書き込むことを保証できます。
このセクションでは、バッチ エンドポイントが使用し、OneLake で Fabric ユーザーに表示される情報を保存するために使用するストレージ アカウントを作成または特定します。 Fabric は、Azure Data Lake Gen2 など、階層名が有効になっているストレージ アカウントのみをサポートします。
ストレージ アカウントへの OneLake ショートカットを作成する
Fabric で、Synapse Data Engineering エクスペリエンスを開きます。
左側のパネルで、Fabric ワークスペースを選択して開きます。
接続を構成するために使用するレイクハウスを開きます。 レイクハウスをまだお持ちでない場合は、Data Engineering エクスペリエンスに移動して、レイクハウスを作成します。 この例では、trusted というレイクハウスを使用します。
左側のナビゲーション バーで、[ファイル] の [その他のオプション] を開き、[新しいショートカット] を選択してウィザードを表示します。
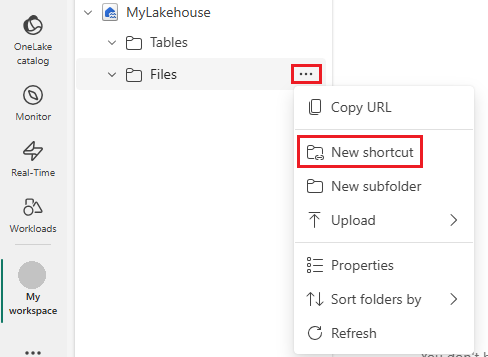
Azure Data Lake Storage Gen2 オプションを選択します。

[接続設定] セクションで、Azure Data Lake Gen2 ストレージ アカウントに関連付けられた URL を貼り付けます。
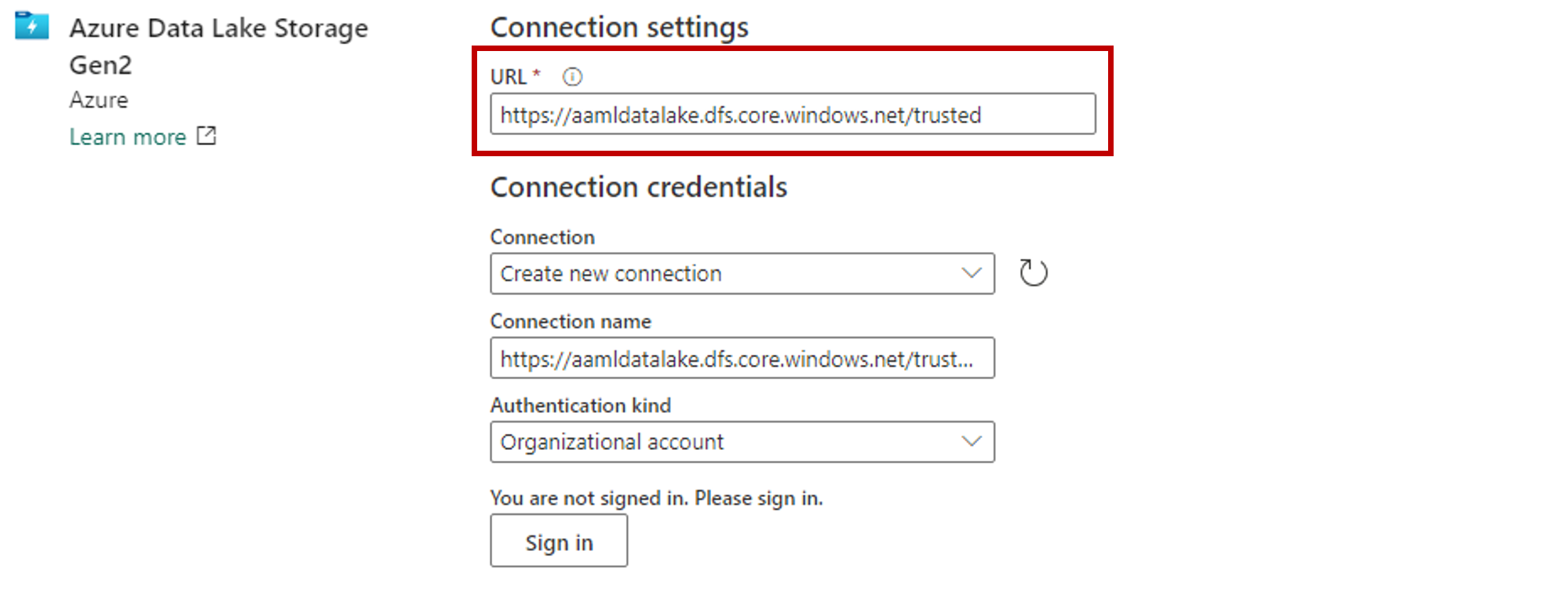
[接続の資格情報] セクションで、次の操作を行います。
- [接続] の場合、[新しい接続を作成する] を選択します。
- [接続名] の場合、既定の自動設定値のままにします。
- [認証の種類] で [組織アカウント] を選択し、OAuth 2.0 経由で接続されたユーザーの認証情報を使用します。
- [サインイン] を選択してサインインします。
[次へ] を選択します。
必要に応じて、ストレージ アカウントに相対的なショートカットへのパスを構成します。 この設定を使用して、ショートカットがポイントするフォルダーを構成します。
ショートカットの名前を構成します。 この名前は lakehouse 内のパスになります。 この例では、ショートカットに datasets という名前を付けます。
変更を保存します。



ストレージ アカウントを指すデータストアを作成する
Azure Machine Learning ワークスペースに移動します。
[データ] セクションに移動します。
[データストア] タブを選択します。
[作成] を選択します
次のようにデータストアを構成します。
[データストア名] には「trusted_blob」と入力します。
[接続の種類] には [Azure Blob Storage] を選択します。
ヒント
Azure Data Lake Gen2 ではなく Azure Blob Storage を構成する必要がある理由 バッチ エンドポイントは、Blob Storage アカウントに予測のみを書き込むことができます。 ただし、すべての Azure Data Lake Gen2 ストレージ アカウントは BLOB ストレージ アカウントでもあります。そのため、これらは置き換えて使用できます。
サブスクリプション ID、ストレージ アカウント、および Blob コンテナー (ファイル システム) を使用して、ウィザードからストレージ アカウントを選択します。
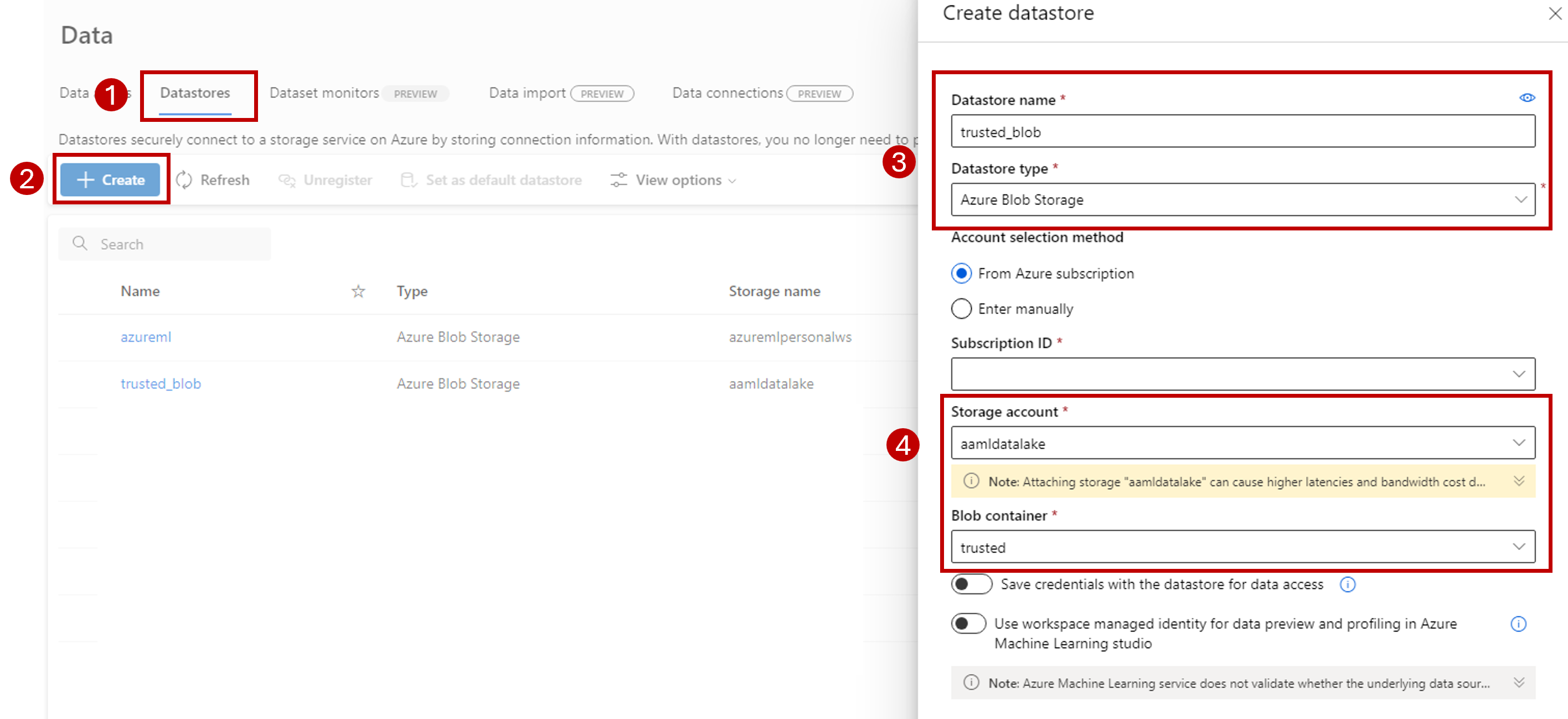
[作成] を選択します
バッチ エンドポイントが実行されているコンピューティングで、このストレージ アカウントにデータをマウントするための権限があることを確認します。 アクセスはエンドポイントを呼び出す ID によって許可されますが、バッチ エンドポイントを実行するコンピューティングには、提供するストレージ アカウントをマウントするための権限が必要です。 詳細については、ストレージ サービスへのアクセスに関する記事を参照してください。
サンプル データセットのアップロード
エンドポイントが入力として使用するサンプル データをアップロードします。
Fabric ワークスペースに移動します。
ショートカットを作成したレイクハウスを選択します。
[データセット] ショートカットに移動します。
スコア付けするサンプル データセットを保存するフォルダーを作成します。 フォルダーの名前を「uci-heart-unlabeled」にします。
[データを取得] オプションを使用し、[ファイルをアップロードする] を選択してサンプル データセット heart-unlabeled.csv をアップロードします。
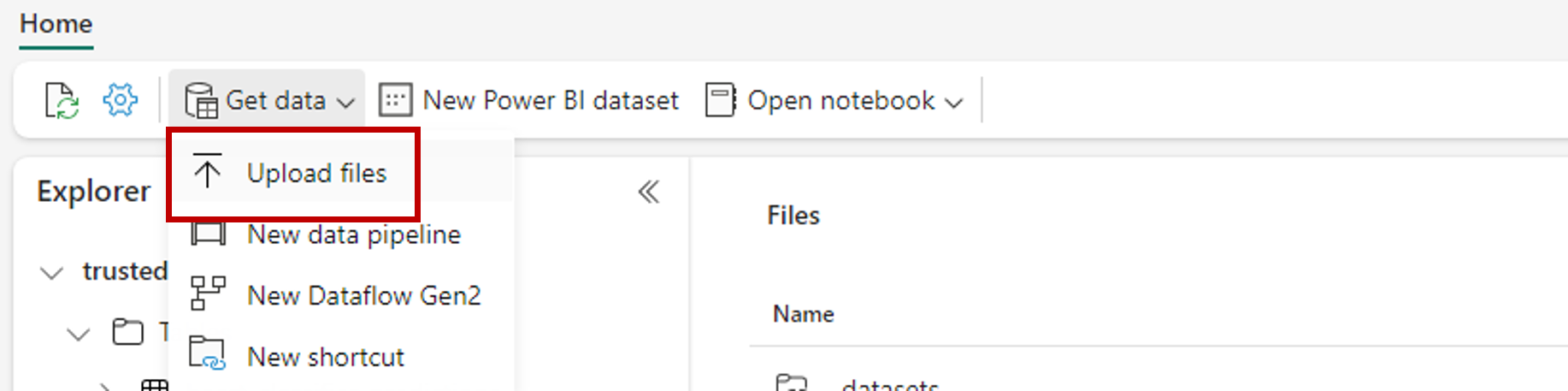
サンプル データセットをアップロードします。

サンプル ファイルを使用する準備ができました。 ファイルを保存した場所のパスを書き留めます。


バッチ推論パイプラインに Fabric を作成する
このセクションでは、既存の Fabric ワークスペースに Fabric からバッチへの推論パイプラインを作成し、バッチ エンドポイントを呼び出します。
ホームページの左下隅にあるエクスペリエンス セレクター アイコンを使用して、Data Engineering エクスペリエンスに戻ります。
Fabric ワークスペースを開きます。
ホームページの [新規] セクションから [データ パイプライン] を選択します。
パイプラインに名前を付け、[作成] を選択します。
デザイナー キャンバスのツール バーで、[アクティビティ] タブを選択します。
タブの最後にあるその他のオプションを選択し、[Azure Machine Learning] を選択します。
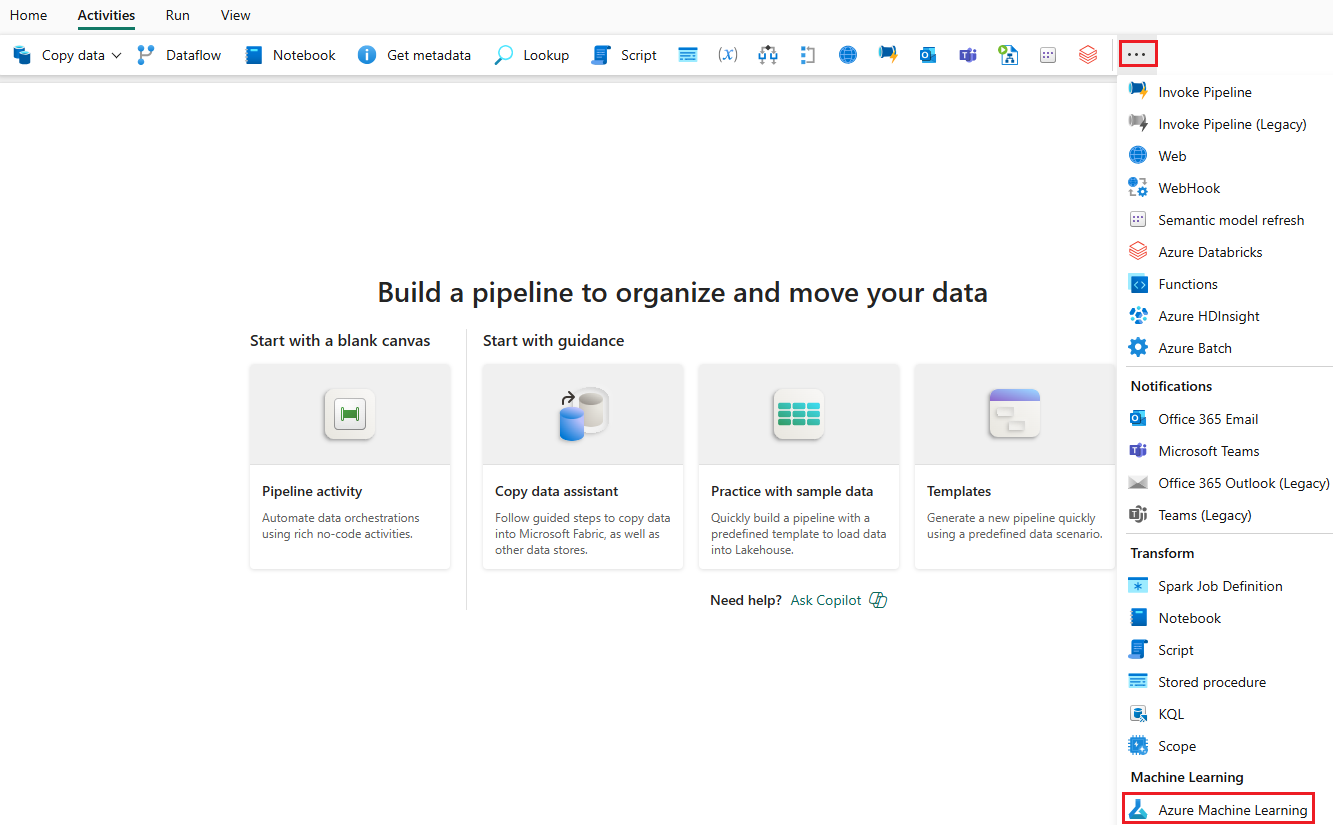
[設定] タブに移動し、次のようにアクティビティを構成します。
Azure Machine Learning 接続の横にある [新規] を選択して、デプロイを含む Azure Machine Learning ワークスペースへの新しい接続を作成します。
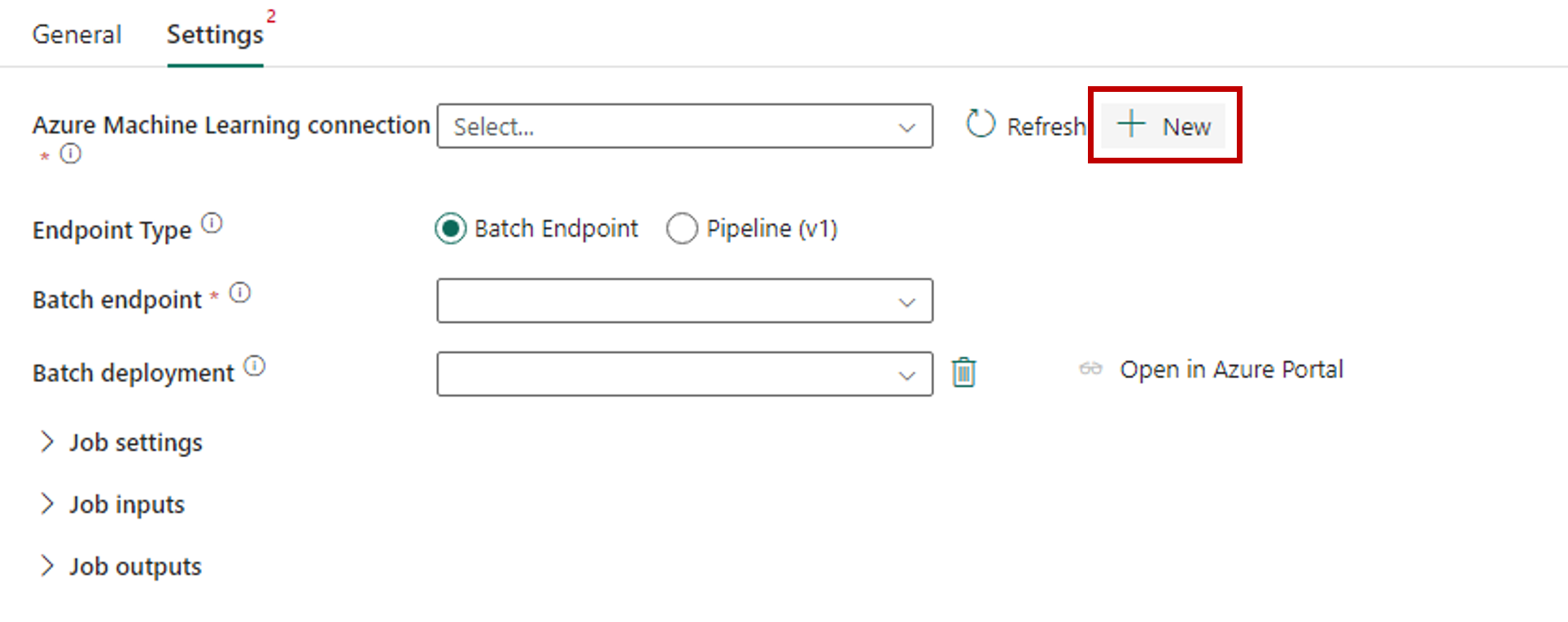
作成ウィザードの [接続の設定] セクションで、エンドポイントを配置する [サブスクリプション ID]、[リソース グループ名]、[ワークスペース名] の値を指定します。
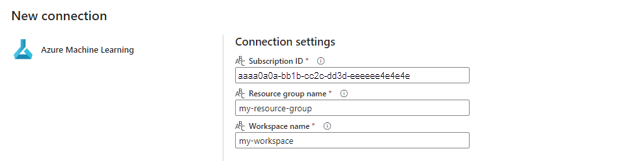
[接続の資格情報] セクションで、接続の [認証の種類] の値として [組織アカウント] を選択します。 [組織アカウント] は、接続されたユーザーの認証情報を使用します。 代わりに、サービス プリンシパルを使用することもできます。 運用設定では、サービス プリンシパルを使用することをお勧めします。 認証の種類に関係なく、接続に関連付けられた ID が、デプロイしたバッチ エンドポイントを呼び出す権限を持っていることを確認します。
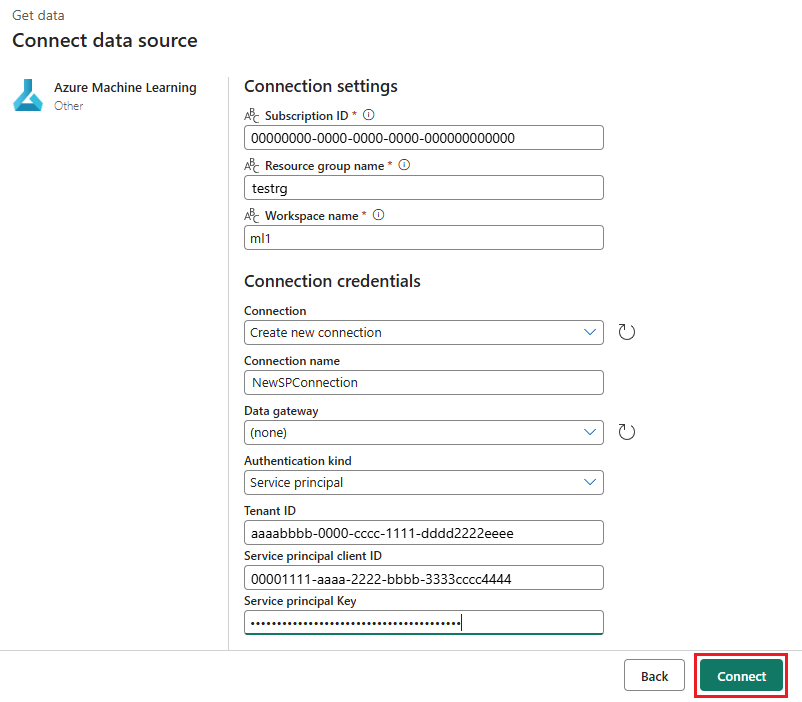
接続を保存します。 接続を選択すると、Fabric は選択したワークスペースで使用可能なバッチ エンドポイントを自動的に設定します。
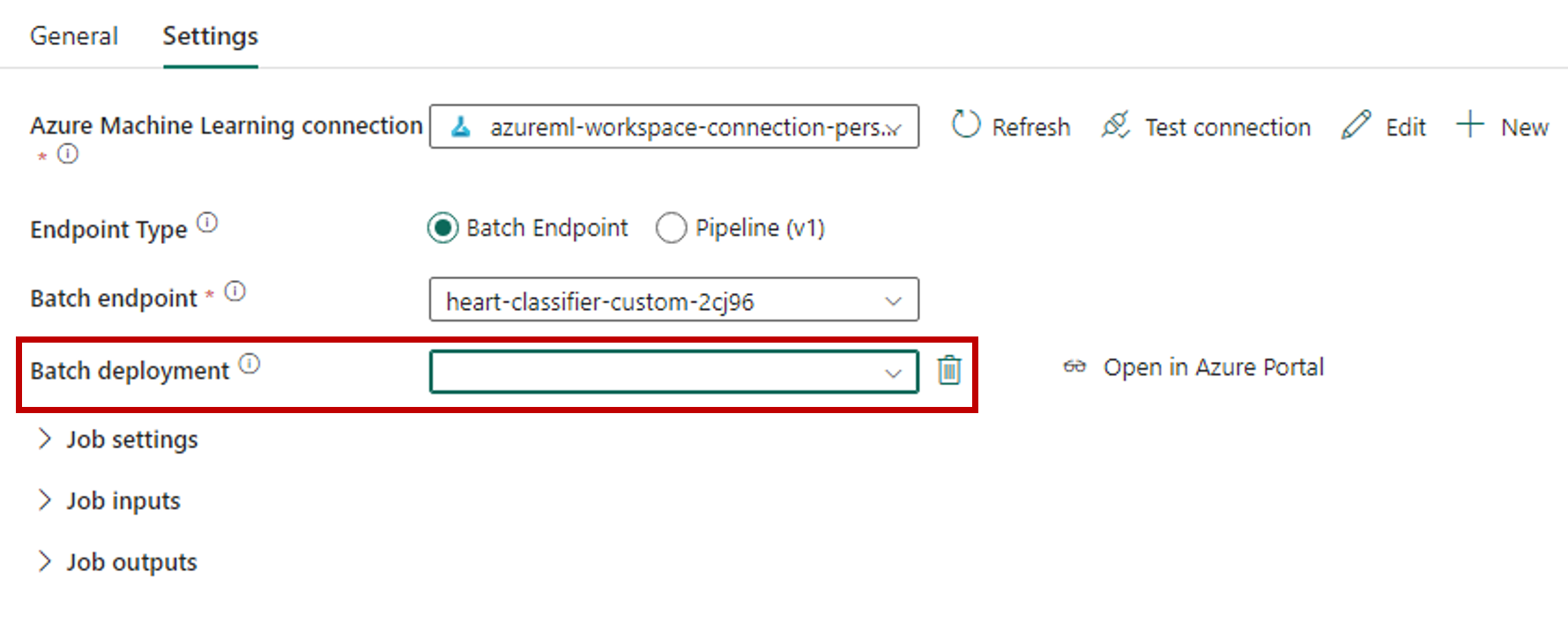
[バッチ エンドポイント] で、呼び出すバッチ エンドポイントを選択します。 この例では、heart-classifier-... を選択します。

[バッチ デプロイ] セクションには、エンドポイントの利用可能なデプロイが自動的に入力されます。
[バッチ デプロイ] の場合、必要に応じてリストから特定のデプロイを選択します。 デプロイを選択しなかった場合、Fablic はエンドポイントで既定のデプロイを呼び出し、バッチ エンドポイント作成者がどのデプロイを呼び出すかを決定できるようにします。 ほとんどのシナリオでは、既定の動作がそのまま使用されます。







バッチ エンドポイントの入出力を構成する
このセクションでは、バッチ エンドポイントでの入出力を構成します。 バッチ エンドポイントへの入力では、プロセスの実行に必要なデータとパラメーターが提供されます。 Fabric の Azure Machine Learning バッチ パイプラインでは、モデル デプロイとパイプライン デプロイの両方がサポートされています。 指定する入力の数と種類は、デプロイの種類によって異なります。 この例では、入力を 1 つだけ必要とし、1 つの出力を生成するモデル デプロイを使用します。
バッチ エンドポイントの入出力の詳細については、「バッチ エンドポイントでの入力および出力」を参照してください。
入力セクションの構成
[ジョブの入力] セクションを次のように構成します。
[ジョブの入力] セクションを展開します。
[新規] を選択して、新しい入力をエンドポイントに追加します。
入力に
input_dataという名前を付けます。 モデル デプロイを使用しているため、任意の名前を使用できます。 ただし、パイプライン デプロイの場合は、モデルで期待されている入力の正確な名前を指定する必要があります。追加したばかりの入力の横にあるドロップダウン メニューを選択して、入力のプロパティ (名前と値フィールド) を開きます。
[名前] フィールドに「
JobInputType」と入力して、作成する入力の種類を示します。[値]フィールドに「
UriFolder」と入力して、入力がフォルダー パスであることを示します。 このフィールドでサポートされているその他の値は、UriFile (ファイル パス) または Literal (文字列や整数などの任意のリテラル値) です。 デプロイで期待される適切な種類を使用する必要があります。プロパティの横にあるプラス記号を選択して、この入力に別のプロパティを追加します。
[名前] フィールドに「
Uri」と入力して、データへのパスを示します。[値] フィールドに、データを見つけるパスである
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeledを入力します。 ここでは、Fabric の OneLake と Azure Machine Learning の両方にリンクされているストレージ アカウントにつながるパスを使用します。 azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled は、バッチ エンドポイントにデプロイされるモデルの予期される入力データが含まれる CSV ファイルへのパスです。https://<storage-account>.dfs.azure.comなど、ストレージ アカウントへの直接パスを使うこともできます。
ヒント
入力が Literal 型の場合、プロパティ
Uriを「Value」に置き換えます。
エンドポイントでさらに多くの入力が必要な場合は、それぞれについて前の手順を繰り返します。 この例では、モデル デプロイには入力が 1 つだけ必要です。
出力セクションを構成する
[ジョブの出力] セクションを次のように構成します。
[ジョブの出力] セクションを展開します。
[新規] を選択して、新しい出力をエンドポイントに追加します。
出力に
output_dataという名前を付けます。 モデル デプロイを使用しているため、任意の名前を使用できます。 ただし、パイプライン デプロイの場合は、モデルで生成されている出力の正確な名前を指定する必要があります。追加したばかりの出力の横にあるドロップダウン メニューを選択して、出力のプロパティ (名前と値フィールド) を開きます。
[名前] フィールドに「
JobOutputType」と入力して、作成する出力の種類を示します。[値]フィールドに「
UriFile」と入力して、出力がファイル パスであることを示します。 このフィールドでサポートされているもう 1 つの値は、UriFolder (フォルダー パス) です。 ジョブ入力セクションとは異なり、Literal (文字列や整数などの任意のリテラル値) は出力としてサポートされていません。プロパティの横にあるプラス記号を選択して、この出力に別のプロパティを追加します。
[名前] フィールドに「
Uri」と入力して、データへのパスを示します。[値] フィールドに、出力を配置するパス
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')を入力します。 Azure Machine Learning バッチ エンドポイントでは、出力としてのデータ ストア パスの使用のみがサポートされます。 競合を回避するには出力は一意でなければならないため、動的な式 (@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')) を使用してパスを構築しました。
エンドポイントでさらに多くの出力が返される場合は、それぞれについて前の手順を繰り返します。 この例では、モデル デプロイには出力が 1 つだけ必要です。
(オプション) ジョブの設定を構成する
次のプロパティを追加して、ジョブの設定を構成することもできます。
モデル デプロイの場合:
| 設定 | 説明 |
|---|---|
MiniBatchSize |
バッチのサイズ。 |
ComputeInstanceCount |
デプロイから要求するコンピューティング インスタンスの数。 |
パイプライン デプロイの場合:
| 設定 | 説明 |
|---|---|
ContinueOnStepFailure |
障害が発生した後、パイプラインでノードの処理を停止する必要があるかどうかを示します。 |
DefaultDatastore |
出力に使用する既定のデータ ストアを示します。 |
ForceRun |
パイプラインが、前の実行から出力が推測できる場合でも、すべてのコンポーネントを強制的に実行するかどうかを示します。 |
構成したら、パイプラインをテストできます。