MLflow と Azure Machine Learning を使用して Azure Databricks 機械学習実験を追跡する
MLflow は、機械学習の実験のライフ サイクルを管理するためのオープンソース ライブラリです。 MLflow を使用すると、Azure Databricks と Azure Machine Learning を統合して、この両方の製品を確実に最大限に活用することができます。
この記事では、次のことについて説明します。
- MLflow を Azure Databricks と Azure Machine Learning と共に使用するために必要なライブラリ。
- Azure Machine Learning で MLflow を使用して Azure Databricks 実行を追跡する方法。
- MLflow でモデルをログに登録して、それらが Azure Machine Learning に登録されるようにする方法。
- Azure Machine Learning に登録されたモデルをデプロイして使用する方法。
前提条件
azureml-mlflowパッケージ。認証を含む Azure Machine Learning との接続を処理します。- Azure Databricks ワークスペースおよびクラスター。
- Azure Machine Learning ワークスペース。
ワークスペースで MLflow 操作を実行するために必要なアクセス許可を確認します。
サンプルの Notebook
Azure Databricks でのモデルのトレーニングと Azure Machine Learning へのデプロイ リポジトリでは、Azure Databricks でモデルをトレーニングし、Azure Machine Learning にデプロイする方法を示しています。 また、Azure Databricks の MLflow インスタンスを使用して実験とモデルを追跡する方法についても説明します。 Azure Machine Learning をデプロイに使用する方法について説明します。
ライブラリのインストール
クラスターにライブラリをインストールするには:
[ライブラリ] タブに移動し、[新しいインストール] を選択します。
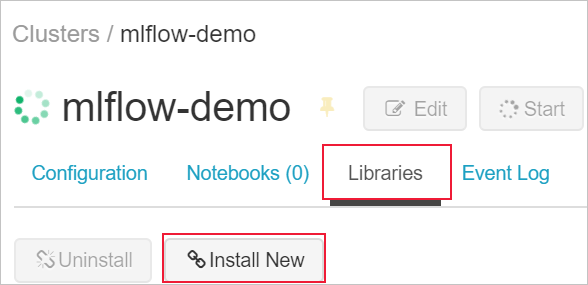
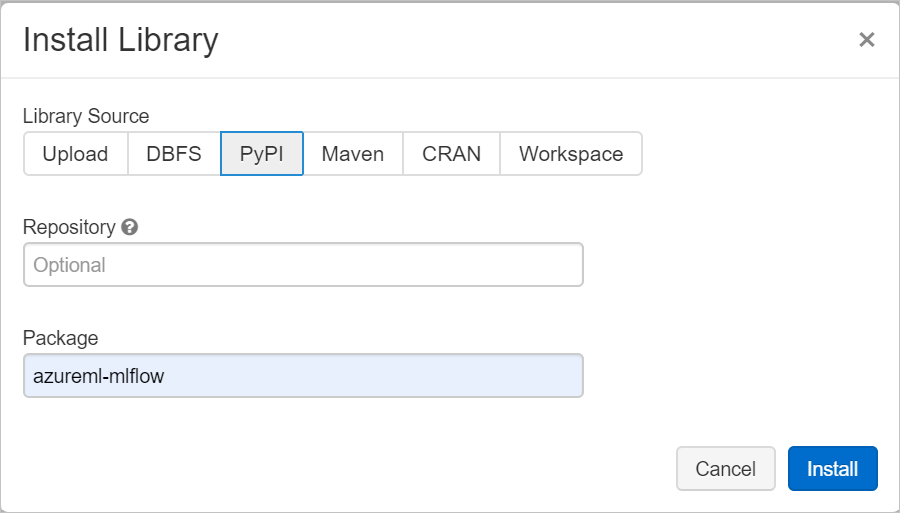
[パッケージ] フィールドに「azureml-mlflow」と入力し、次に [インストール] を選択します。 必要に応じてこの手順を繰り返して、実験のための他のパッケージをクラスターにインストールします。
MLflow を使用して Azure Databricks 実行を追跡する
MLflow を使用して実験を追跡するように Azure Databricks を構成するには、次の 2 つの方法があります。
- Azure Databricks ワークスペースと Azure Machine Learning ワークスペースの両方で追跡する (デュアルトラッキング)
- Azure Machine Learning でのみ追跡する
既定では、Azure Databricks ワークスペースをリンクすると、デュアルトラッキングが構成されます。
Azure Databricks と Azure Machine Learning でのデュアルトラッキング
Azure Databricks ワークスペースを Azure Machine Learning ワークスペースにリンクすると、Azure Machine Learning ワークスペースと Azure Databricks ワークスペースで実験データを同時に追跡できるようになります。 この構成は "デュアルトラッキング" と呼ばれます。
プライベート リンク対応 Azure Machine Learning ワークスペースのデュアルトラッキングは、現在サポートされていません。 代わりに、Azure Machine Learning ワークスペースで排他的追跡を構成してください。
現在、21Vianet が運営する Microsoft Azure では、デュアルトラッキングはサポートされていません。 代わりに、Azure Machine Learning ワークスペースで排他的追跡を構成してください。
Azure Databricks ワークスペースを新規または既存の Azure Machine Learning ワークスペースにリンクするには:
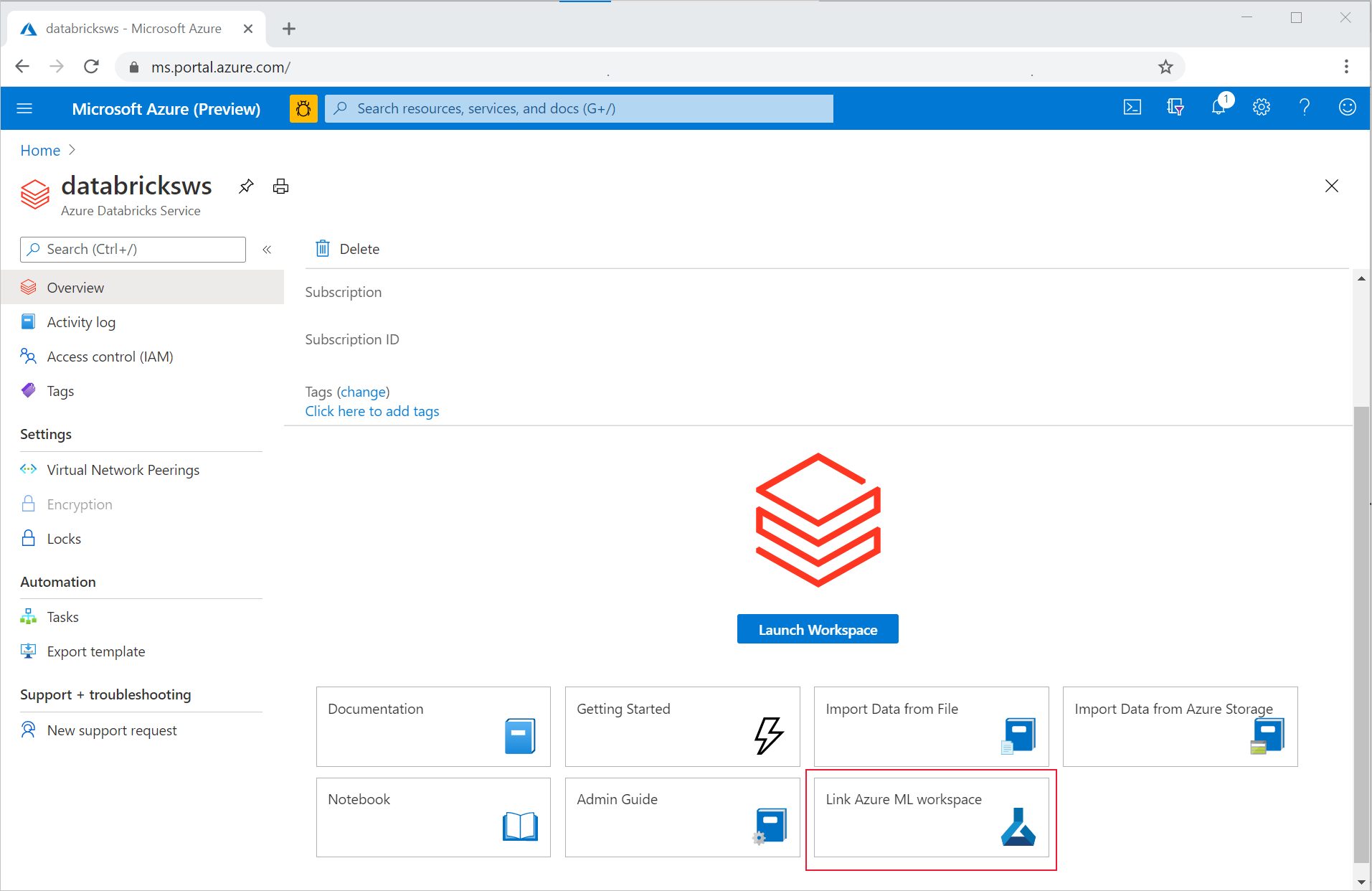
Azure portal にサインインします。
Azure Databricks ワークスペースの [概要] ページに移動します。
[Azure Machine Learning ワークスペースのリンク] を選択します。

Azure Databricks ワークスペースを Azure Machine Learning ワークスペースにリンクすると、MLflow 追跡は次の場所で自動的に追跡されます。
- リンクされた Azure Machine Learning ワークスペース。
- 元の Azure Databricks ワークスペース。
その後は、今までと同じように Azure Databricks で MLflow を使用できます。 次の例では、Azure Databricks で通常行われるように実験名を設定し、一部のパラメーターのログを開始しています。
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Note
追跡とは反対に、モデル レジストリでは、Azure Machine Learning と Azure Databricks の両方で同時にモデルを登録することはサポートしていません。 詳細については、「MLflow を使用してレジストリにモデルを登録する」を参照してください。
Azure Machine Learning ワークスペースでのみ追跡する
追跡対象の実験を 1 か所で管理する場合は、Azure Machine Learning ワークスペースでのみ追跡するように MLflow 追跡を設定できます。 この構成には、Azure Machine Learning のデプロイ オプションを使って、より簡単にデプロイへのパスを有効にするという利点があります。
警告
プライベート リンクが有効になっている Azure Machine Learning ワークスペースの場合は、適切な接続を確保するために、独自のネットワークに Azure Databricks をデプロイする (VNet インジェクション) 必要があります。
次の例で示すように、MLflow 追跡 URI が Azure Machine Learning のみを指すように構成します。
追跡 URI を構成する
ワークスペースの追跡 URI を取得します。
適用対象:
 Azure CLI ml 拡張機能 v2 (現行)
Azure CLI ml 拡張機能 v2 (現行)サインインしてワークスペースを構成します。
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>az ml workspaceコマンドを使って追跡 URI を取得できます。az ml workspace show --query mlflow_tracking_uri
追跡 URI を構成します。
メソッド
set_tracking_uri()を使用して、MLflow 追跡 URI をその URI にポイントします。import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)
ヒント
Azure Databricks クラスター、Azure Synapse Analytics クラスターなどの共有環境で作業する場合、クラスター レベルで環境変数 MLFLOW_TRACKING_URI を設定できます。 このアプローチを使用すると、セッションごとに実行するのではなく、クラスター内で実行されるすべてのセッションに対して Azure Machine Learning を指すように MLflow 追跡 URI を自動的に構成できます。
![Azure Databricks クラスターで環境変数を構成できる [詳細オプション] を示すスクリーンショット。](media/how-to-use-mlflow-azure-databricks/env.png?view=azureml-api-2)
環境変数を構成すると、このようなクラスターで実行されるすべての実験が Azure Machine Learning で追跡されるようになります。
認証の構成
追跡を構成した後、関連付けられたワークスペースの認証を受ける方法を構成します。 既定では、MLflow 用 Azure Machine Learning プラグインによってブラウザーが開かれ、対話形式で資格情報の入力が求められます。 Azure Machine Learning ワークスペースで MLflow の認証を構成するその他の方法については、「Azure Machine Learning 用に MLflow を構成する: 認証を構成する」を参照してください。
セッションに接続されているユーザーがいる対話型ジョブの場合は、対話型認証を使用できるため、これ以上の操作は必要ありません。
警告
"対話型ブラウザー" 認証は資格情報の入力を求める際にコード実行をブロックします。 このアプローチはトレーニング ジョブなどの無人環境での認証には適しません。 別の認証モードを構成することをお勧めします。
無人実行が必要なシナリオでは、Azure Machine Learning と通信するようにサービス プリンシパルを構成する必要があります。
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
ヒント
共有環境で作業する場合は、コンピューティング上でこれらの環境変数を構成することをお勧めします。 ベスト プラクティスとして、それらを Azure Key Vault のインスタンス内のシークレットとして管理します。
たとえば、Azure Databricks では、クラスター構成で AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}} のようにして環境変数でシークレットを使用できます。 Azure Databricks でのこのアプローチの実装について詳しくは、「環境変数でシークレットを参照する」を確認するか、プラットフォームのドキュメントを参照してください。
Azure Machine Learning で実験に名前を付ける
Azure Machine Learning ワークスペース内の実験のみを追跡するように MLflow を構成する場合、実験の名前付け規則は Azure Machine Learning で使われているものに従う必要があります。 Azure Databricks では、実験名には /Users/alice@contoso.com/iris-classifier のように実験が保存されている場所へのパスが付けられます。 ただし、Azure Machine Learning では、実験名を直接指定します。 同じ実験には、iris-classifier という名前がそのまま付けられます。
mlflow.set_experiment(experiment_name="experiment-name")
パラメーター、メトリック、成果物を追跡する
この構成後は、これまでと同じ方法で Azure Databricks で MLflow を使用できるようになります。 詳細については、メトリックとログ ファイルのログと表示に関する記事を参照してください。
MLflow を使用してモデルをログする
モデルのトレーニングが完了したら、mlflow.<model_flavor>.log_model() メソッドを使って追跡サーバーにログを記録します。 <model_flavor> は、モデルに関連付けられているフレームワークを参照します。 サポートされているモデルの種類については、こちらを参照してください。
次の例では、Spark のライブラリ MLLib で作成されたモデルが登録されています。
mlflow.spark.log_model(model, artifact_path = "model")
フレーバー spark は、Spark クラスターでモデルをトレーニングしているという事実に対応するものではありません。 そうではなく、使用されているトレーニング フレームワークに従います。 Spark で TensorFlow を使用してモデルをトレーニングできます。 使用するフレーバーは tensorflow です。
モデルは追跡中の実行の内部でログに記録されます。 つまり、モデルは Azure Databricks と Azure Machine Learning の両方 (既定)、または Azure Machine Learning のみ (追跡 URI が指すように構成した場合) で使用できます。
重要
パラメーター registered_model_name は指定されていません。 このパラメーターとレジストリの詳細については、MLflow を使用してレジストリにモデルを登録する方法に関する記事を参照してください。
MLflow を使用してレジストリにモデルを登録する
追跡とは反対に、モデル レジストリは Azure Databricks と Azure Machine Learning で同時に動作することはできません。 どちらかを使用する必要があります。 既定では、モデル レジストリは Azure Databricks ワークスペースを使用します。 Azure Machine Learning ワークスペース内でのみ追跡するように MLflow 追跡を設定することを選択した場合、モデル レジストリは Azure Machine Learning ワークスペースです。
既定の構成を使用する場合、次のコードにより、Azure Databricks と Azure Machine Learning の両方の対応する実行内でモデルがログされますが、登録されるのは Azure Databricks のみです。
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
- 名前付きの登録済みのモデルが存在しない場合、メソッドにより新しいモデルが登録され、Version 1 が作成され、
ModelVersionMLflow オブジェクトが返されます。 - 名前付きの登録済みモデルが既にある場合は、メソッドにより新しいモデル バージョンが作成され、バージョン オブジェクトが返されます。
MLflow で Azure Machine Learning レジストリを使用する
Azure Databricks ではなく Azure Machine Learning モデル レジストリを使用する場合は、お使いの Azure Machine Learning ワークスペースでのみ追跡するように MLflow 追跡を設定することをお勧めします。 このアプローチにより、モデルが登録される場所のあいまいさがなくなり、構成は簡略化されます。
デュアルトラッキング機能を使い続けたまま、Azure Machine Learning にモデルを登録する場合は、MLflow モデル レジストリ URI を構成することで、モデル登録に Azure Machine Learning を使うよう MLflow に指示することができます。 この URI は、URI を追跡する MLflow と同じ形式と値を持ちます。
mlflow.set_registry_uri(azureml_mlflow_uri)
Note
azureml_mlflow_uri の値は、お使いの Azure Machine Learning ワークスペースでのみ追跡するように MLflow 追跡を設定する方法の記事で説明されているのと同じ方法で取得されました。
このシナリオの完全な例については、Azure Databricks でのモデルのトレーニングと Azure Machine Learning へのデプロイに関する記事を参照してください。
Azure Machine Learning に登録されたモデルをデプロイして使用する
MLflow を使って Azure Machine Learning サービスに登録したモデルは、次のように使用できます。
- Azure Machine Learning エンドポイント (リアルタイムとバッチ)。 このデプロイにより、Azure Container Instances、Azure Kubernetes、またはマネージド推論エンドポイントでのリアルタイム推論とバッチ推論の両方に Azure Machine Learning デプロイ機能を使用できるようになります。
- MLFlow モデル オブジェクトまたは Pandas ユーザー定義関数 (UDF)。Azure Databricks ノートブックでのストリーミングまたはバッチ パイプラインで使用できます。
Azure Machine Learning エンドポイントにモデルをデプロイする
azureml-mlflow プラグインを使用して、Azure Machine Learning ワークスペースにモデルをデプロイできます。 モデルをさまざまなターゲットにデプロイする方法の詳細については、MLflow モデルをデプロイする方法に関する記事を参照してください。
重要
モデルをデプロイするには、Azure Machine Learning のレジストリに登録する必要があります。 Azure Databricks 内の MLflow インスタンスにモデルが登録されている場合は、Azure Machine Learning に再度登録します。 詳細については、Azure Databricks でのモデルのトレーニングと Azure Machine Learning へのデプロイに関する記事を参照してください
UDF を使用したバッチ スコアリングのためにモデルを Azure Databricks にデプロイする
バッチ スコアリング用に Azure Databricks クラスターを選択できます。 Mlflow を使用することにより、接続先のレジストリにあるすべてのモデルを解決できます。 通常は、次のいずれかの方法を使用します。
MLLibなどの Spark ライブラリを使用してモデルがトレーニングおよび構築された場合は、mlflow.pyfunc.spark_udfを使用してモデルを読み込み、それを Spark Pandas UDF として使用して新しいデータをスコア付けします。- モデルが Spark ライブラリを使用してトレーニングまたは構築されなかった場合は、
mlflow.pyfunc.load_modelまたはmlflow.<flavor>.load_modelのどちらかを使用してクラスター ドライバーでモデルを読み込みます。 クラスター内で実行する並列化や作業の配分を調整する必要があります。 モデルの実行に必要なライブラリは MLflow によってインストールされません。 これらのライブラリは、実行する前に、クラスター内にインストールする必要があります。
次の例は、uci-heart-classifier という名前のレジストリからモデルを読み込み、それを Spark Pandas UDF として使用して新しいデータをスコア付けする方法を示しています。
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
レジストリにあるモデルを参照するその他の方法については、「レジストリからのモデルの読み込み」を参照してください。
モデルが読み込まれたら、このコマンドを使用して新しいデータをスコア付けできます。
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
リソースをクリーンアップする
お使いの Azure Databricks ワークスペースを残したいが、Azure Machine Learning ワークスペースが不要になった場合は、Azure Machine Learning ワークスペースを削除できます。 この操作により、お使いの Azure Databricks ワークスペースと Azure Machine Learning ワークスペースのリンクが解除されます。
ログされたメトリックと成果物をワークスペースで使用する予定がない場合は、ストレージ アカウントとワークスペースを含むリソース グループを削除します。
- Azure portal で [リソース グループ] を検索します。 [サービス] で [リソース グループ] を選択します。
- [リソース グループ] 一覧で、作成したリソース グループを見つけて選択し、開きます。
- [概要] ページで、[リソース グループの削除] を選択します。
- 削除を確認するには、リソース グループの名前を入力します。