MLflow と Azure Machine Learning を使用した Azure Synapse Analytics ML 実験の追跡
この記事では、Azure Synapse Analytics ワークスペースで作業しているときに MLflow が Azure Machine Learning に接続できるようにする方法について説明します。 この構成を、追跡、モデル管理、モデル デプロイに利用できます。
MLflow は、機械学習の実験のライフ サイクルを管理するためのオープンソース ライブラリです。 MLflow Tracking は、トレーニング実行のメトリックとモデル成果物のログ記録と追跡を行う、MLflow のコンポーネントです。 MLflow の詳細については、次を参照してください。
MLflow プロジェクトを Azure Machine Learning でトレーニングする場合は、「MLflow プロジェクトと Azure Machine Learning を使用して ML モデルをトレーニングする (プレビュー)」を参照してください。
前提条件
ライブラリのインストール
Azure Synapse Analytics の専用クラスターにライブラリをインストールするには:
実験に必要なパッケージを含む
requirements.txtファイルを作成しますが、次のパッケージも含まれていることを確認します。requirements.txt
mlflow azureml-mlflow azure-ai-mlAzure Analytics ワークスペース ポータルに移動します。
[管理] タブに移動し、[Apache Spark プール] を選択します。
クラスター名の横にある 3 つのドットをクリックし、[パッケージ] を選択します。
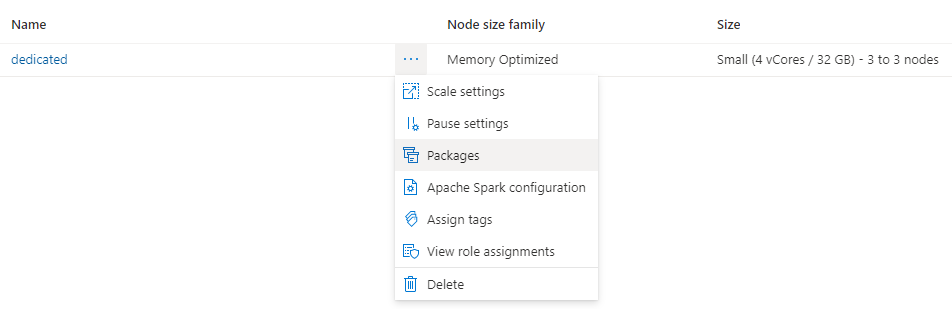
[要件ファイル] セクションで、[アップロード] をクリックします。
requirements.txtファイルをアップロードします。クラスターが再起動するまで待ちます。
MLflow を使用して実験を追跡する
Azure Synapse Analytics は、MLflow を使用して Azure Machine Learning ワークスペースで実験を追跡するように構成できます。 Azure Machine Learning には、実験、モデル、デプロイのライフサイクル全体を管理するための一元化されたリポジトリが用意されています。 これには、Azure Machine Learning のデプロイ オプションを使って、より簡単にデプロイへのパスを有効にするという利点もあります。
Azure Machine Learning に接続された MLflow を使用するようにノートブックを構成する
実験の一元化されたリポジトリとして Azure Machine Learning を使用するには、MLflow を利用できます。 作業している各ノートブックで、使用するワークスペースを指す追跡 URI を構成する必要があります。 次の例では、これが行われる方法を示します。
追跡 URI を構成する
ワークスペースの追跡 URI を取得します。
適用対象:
 Azure CLI ML 拡張機能 v2 (現行)
Azure CLI ML 拡張機能 v2 (現行)ログインとワークスペースの構成:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>az ml workspaceコマンドを使って追跡 URI を取得できます。az ml workspace show --query mlflow_tracking_uri
追跡 URI の構成:
次に、メソッド
set_tracking_uri()では、MLflow 追跡 URI をその URI にポイントします。import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)ヒント
Azure Databricks クラスターや Azure Synapse Analytics クラスターなどの共有環境で作業する場合は、クラスター レベルで環境変数
MLFLOW_TRACKING_URIを設定し、セッションごとに実行するのではなく、クラスターで実行されているすべてのセッションについて Azure Machine Learning を指すように MLflow 追跡 URI を自動的に構成すると便利です。
認証を構成する
追跡を構成したら、関連付けられているワークスペースに対して認証を行う方法も構成する必要があります。 既定では、MLflow 用の Azure Machine Learning プラグインは、既定のブラウザーを開いて資格情報の入力を求める対話型認証を実行します。 Azure Machine Learning ワークスペースで MLflow の認証方法を構成するその他の方法については、「Azure Machine Learning 用に MLflow を構成する」の「認証を構成する」を参照してください。
セッションに接続されているユーザーがいる対話型ジョブの場合は、対話型認証を使用できるため、これ以上の操作は必要ありません。
警告
対話型ブラウザー認証では、資格情報の入力を求めるメッセージが表示されると、コードの実行がブロックされます。 これは、トレーニング ジョブなどの無人環境での認証には適したオプションではありません。 他の認証モードを構成することをお勧めします。
無人実行が必要なシナリオでは、Azure Machine Learning と通信するようにサービス プリンシパルを構成する必要があります。
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
ヒント
共有環境で作業する場合は、コンピューティングでこれらの環境変数を構成することをお勧めします。 ベスト プラクティスとして、可能な限り Azure Key Vault のインスタンスでシークレットとして管理します。 たとえば、Azure Databricks では、クラスター構成で AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}} のようにして環境変数でシークレットを使用できます。 Azure Databricks で行う方法については、「環境変数でシークレットを参照する」を参照するか、お使いのプラットフォームで同様のドキュメントを参照してください。
Azure Machine Learning の実験名
既定では、Azure Machine Learning は Default と呼ばれる既定の実験で実行を追跡します。 通常は、作業する実験を設定することをお勧めします。 実験の名前を設定するには、次の構文を使用します。
mlflow.set_experiment(experiment_name="experiment-name")
パラメーター、メトリック、成果物の追跡
その後、今までと同じように Azure Synapse Analytics で MLflow を使用できます。 詳細については、「メトリックのログと確認およびログ ファイル」を参照してください。
MLflow を使ってレジストリにモデルを登録する
モデルは、ライフサイクルを管理するための一元化されたリポジトリを提供する Azure Machine Learning ワークスペースに登録できます。 次の例では、Spark MLLib でトレーニングされたモデルをログに記録し、レジストリに登録します。
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
名前付きの登録済みモデルが存在しない場合、メソッドにより新しいモデルが登録され、バージョン 1 が作成され、MLflow オブジェクト ModelVersion が返されます。
名前付きの登録済みモデルが既にある場合は、メソッドにより新しいモデル バージョンが作成され、バージョン オブジェクトが返されます。
MLflow を使用して、Azure Machine Learning に登録されたモデルを管理できます。 詳細については、「MLflow を使用して Azure Machine Learning でモデル レジストリを管理する」を参照してください。
Azure Machine Learning に登録したモデルのデプロイと使用
MLflow を使って Azure Machine Learning サービスに登録したモデルは、次のように使用できます。
Azure Machine Learning のエンドポイント (リアルタイムとバッチ): このデプロイでは、Azure Container Instances (ACI)、Azure Kubernetes (AKS) またはマネージド エンドポイントでのリアルタイムとバッチの両方の推論で Azure Machine Learning デプロイの機能を活用できます。
MLFlow モデル オブジェクトまたは Pandas UDF。Azure Synapse Analytics ノートブックでのストリーミングまたはバッチ パイプラインで使用できます。
Azure Machine Learning エンドポイントにモデルをデプロイする
azureml-mlflow プラグインを利用して、Azure Machine Learning ワークスペースにモデルをデプロイできます。 モデルをさまざまなターゲットにデプロイする方法の完全な詳細については、MLflow モデルをデプロイする方法に関する記事を確認します。
重要
モデルをデプロイするには、Azure Machine Learning のレジストリに登録する必要があります。 Azure Machine Learning では、未登録のモデルをデプロイすることはサポートされていません。
UDF を使ったバッチ スコアリングのためにモデルをデプロイする
バッチ スコアリング用に Azure Synapse Analytics クラスターを選択できます。 MLflow モデルが読み込まれ、新しいデータをスコアリングする Spark Pandas UDF として使用されます。
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
リソースをクリーンアップする
お使いの Azure Synapse Analytics ワークスペースを残したいが、Azure Machine Learning ワークスペースが不要になった場合は、Azure Machine Learning ワークスペースを削除できます。 ログに記録されたメトリックと成果物をワークスペースで使用する予定がない場合、それらを個別に削除する機能は現時点では用意されていません。 代わりに、ストレージ アカウントとワークスペースを含むリソース グループを削除すれば、課金は発生しません。
Azure Portal で、左端にある [リソース グループ] を選択します。
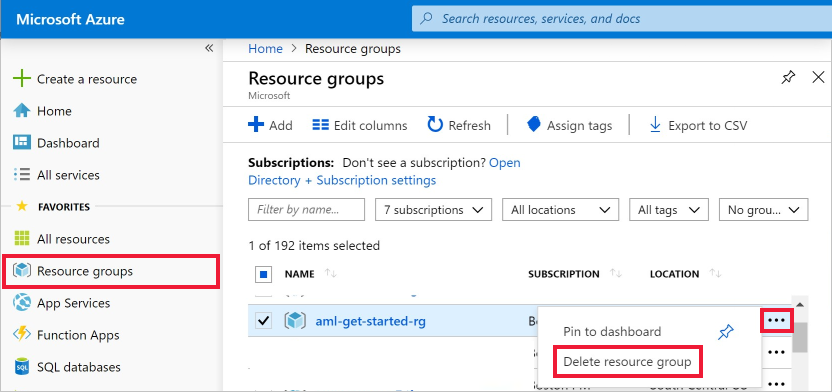
作成したリソース グループを一覧から選択します。
[リソース グループの削除] を選択します。
リソース グループ名を入力します。 次に、 [削除] を選択します。