Azure Machine Learning での Apache Spark を使用した対話型データ ラングリング
データ ラングリングは、機械学習プロジェクトで最も重要な手順の 1 つになります。 Azure Machine Learning と Azure Synapse Analytics の統合により、Azure Machine Learning Notebooks を使用した対話型のデータ ラングリングのために、Azure Synapse によってサポートされる Apache Spark プールへのアクセスが提供されます。
この記事では、を使用してデータラングリングを実行する方法を学習します
- サーバーレス Spark コンピューティング
- アタッチされた Synapse Spark プール
前提条件
- Azure サブスクリプション。Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
- Azure Machine Learning ワークスペース。 「ワークスペース リソースの作成」 を参照してください。
- Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウント。 「Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウントを作成する」を参照してください。
- (省略可能): Azure Key Vault。 Azure Key Vault の作成を参照してください。
- (省略可能): サービス プリンシパル。 サービス プリンシパルの作成を参照してください。
- (省略可能): Azure Machine Learning ワークスペースにアタッチされた Synapse Spark プール。
データ ラングリング タスクを開始する前に、シークレットを格納するプロセスについて学習します
- Azure BLOB ストレージ アカウント アクセス キー
- アクセス共有シグネチャ (SAS) トークン
- Azure Data Lake Storage (ADLS) Gen 2 サービス プリンシパル情報
Azure Key Vault で。 また、Azure ストレージ アカウントでロールの割り当てを処理する方法についても知っておく必要があります。 次のセクションでは、これらの概念について説明します。 次に、Azure Machine Learning Notebooks の Spark プールを使用して、対話型データ ラングリングの詳細について説明します。
ヒント
Azure ストレージ アカウントのロールの割り当て構成について、またはユーザー ID パススルーを使用してストレージ アカウントのデータにアクセスする場合は、「Azure ストレージ アカウントにロールの割り当てを追加する」を参照してください。
Apache Spark を使用した対話型データ ラングリング
Azure Machine Learning では、Azure Machine Learning Notebooks で、Apache Spark を使用した対話型データ ラングリング用のサーバーレス Spark コンピューティングとアタッチされた Synapse Spark プールが提供されます。 サーバーレス Spark コンピューティングでは、Azure Synapse ワークスペースにリソースを作成する必要はありません。 代わりに、フル マネージドのサーバーレス Spark コンピューティングが Azure Machine Learning Notebooks で直接使用できるようになります。 Azure Machine Learning で Spark クラスターにアクセスするには、サーバーレス Spark コンピューティングを使用するのが最も簡単な方法です。
Azure Machine Learning Notebooks でのサーバーレス Spark コンピューティング
Azure Machine Learning Notebooks では、既定で、サーバーレス Spark コンピューティングを使用できます。 ノートブックでアクセスするには、[コンピューティング] 選択メニューから [Azure Machine Learning サーバーレス Spark] の下にある [サーバーレス Spark コンピューティング] を選択します。
Notebooks UI には、サーバーレス Spark コンピューティング用の Spark セッション構成のオプションも用意されています。 Spark セッションを構成するには、次の手順を実行します。
- 画面の上部にある[セッションの構成] を選択します。
- ドロップダウンメニューから Apache Spark のバージョンを選択します。
重要
Azure Synapse Runtime for Apache Spark: お知らせ
- Azure Synapse Runtime for Apache Spark 3.2:
- EOLA のお知らせ日: 2023 年 7 月 8 日
- サポート終了日: 2024 年 7 月 8 日。 この日付を過ぎると、ランタイムは無効になります。
- 継続的なサポートと最適なパフォーマンスを得るために、Apache Spark 3.3 への移行をお勧めします。
- Azure Synapse Runtime for Apache Spark 3.2:
- ドロップダウン メニューから [インスタンスの種類] を選択します。 現在は、次のインスタンスの種類がサポートされています。
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Spark セッション タイムアウトの値を分単位で入力します。
- Executor を動的に割り当てるかどうかを選択します。
- Spark セッションの Executor の数を選択します。
- ドロップダウンメニューから [Executor サイズ] を選択します。
- ドロップダウンメニューから [ドライバー サイズ] を選択します。
- Conda ファイルを使用してSpark セッションを構成するには、[Conda ファイルをアップロード] チェックボックスをオンにします。 次に、[参照] を選択し、必要な Spark セッション構成を含む Conda ファイルを選びます。
- [構成設定] プロパティを追加し、[プロパティ] ボックスと [値] ボックスに入力値を追加し、[追加] を選択します。
- [適用] を選択します。
- [新しいセッションを構成しますか?] ポップアップで [セッションの停止] を選択します。
セッション構成の変更は保持され、サーバーレス Spark コンピューティングを使用して開始された別のノートブック セッションで使用できるようになります。
ヒント
セッション レベルの Conda パッケージを使用する場合は、構成変数 spark.hadoop.aml.enable_cache を true に設定すると、Spark セッションのコールド スタート時間を短縮できます。 セッション レベルの Conda パッケージを使用したセッション コールド スタートでは、通常、セッションが初めて開始されるときに 10 分から 15 分かかります。 しかし、構成変数が true に設定された以降のセッション コールド スタートにかかる時間は、通常、3 分から 5 分です。
Azure Data Lake Storage (ADLS) Gen 2 からのデータのインポートとラングリング
データ URI を使用して、Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウントabfss://に格納データにアクセスし、ラングルすることができます。次の 2 つのデータ アクセス メカニズムのいずれかに従います。
- ユーザー ID パススルー
- サービス プリンシパルベースのデータ アクセス
ヒント
サーバーレス Spark コンピューティングを使用したデータ ラングリングと、Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウントのデータにアクセスするためのユーザー ID パススルーには、最小限の構成手順が必要です。
ユーザー ID パススルーを使用して対話型データ ラングリングを開始するには:
ユーザー ID の Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウントに共同作成者とストレージ BLOB データ共同作成者ロールの割り当てがあることを確認します。
サーバーレス Spark コンピューティングを使用するには、[コンピューティング] 選択メニューから [Azure Machine Learning サーバーレス Spark] の下にある [サーバーレス Spark コンピューティング] を選択します。
アタッチされた Synapse Spark プールを使用するには、[コンピューティング] 選択メニューから [Synapse Spark プール] の下にあるアタッチされた Synapse Spark プールを選択します。
この Titanic データ ラングリング コード サンプルでは、
pyspark.pandasとpyspark.ml.feature.Imputerを含む形式abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>のデータ URI の使用方法を示します。import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Note
この Python コード サンプルでは、
pyspark.pandasを使用します。 これは、Spark ランタイム バージョン 3.2 以降でのみサポートされます。
サービス プリンシパルを介したアクセスによってデータをラングリングするには:
サービス プリンシパルの Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウントに共同作成者とストレージ BLOB データ共同作成者ロールが割り当てられていることを確認します。
サービス プリンシパルのテナント ID、クライアント ID、クライアント シークレットの値の Azure Key Vault シークレットを作成します。
[コンピューティング] 選択メニューの [Azure Machine Learning サーバーレス Spark] の下にある [サーバーレス Spark コンピューティング] を選択するか、[コンピューティング] 選択メニューの [Synapse Spark プール] の下でアタッチされている Synapse Spark プールを選択します。
構成でサービス プリンシパルのテナント ID、クライアント ID、クライアント シークレットを設定するには、次のコード サンプルを実行します。
コード内の
get_secret()呼び出しは、Azure Key Vault の名前と、サービス プリンシパルのテナント ID、クライアント ID、クライアント シークレットに対して作成された Azure Key Vault シークレットの名前によって異なります。 構成でこれらの対応するプロパティ名/値を設定します。- クライアント ID プロパティ:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - クライアント シークレットのプロパティ:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - テナント ID プロパティ:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - テナント ID の値:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- クライアント ID プロパティ:
Titanic データを使用したコード サンプルに示すように、
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>という形式でデータ URI を使用してデータをインポートしてラングリングします。
Azure BLOB ストレージからのデータのインポートとラングリング
Azure Blob Storage データには、ストレージ アカウント アクセス キーまたは Shared Access Signature (SAS) トークンのいずれかを使用してアクセスできます。 これらの資格情報をシークレットとして Azure Key Vault に格納し、セッション構成のプロパティとして設定する必要があります。
対話型データ ラングリングを開始するには:
Azure Machine Learning スタジオの左側のパネルで、Notebooks を選択します。
[コンピューティング] 選択メニューの [Azure Machine Learning サーバーレス Spark] の下にある [サーバーレス Spark コンピューティング] を選択するか、[コンピューティング] 選択メニューの [Synapse Spark プール] の下でアタッチされている Synapse Spark プールを選択します。
Azure Machine Learning Notebooks でデータ アクセス用のストレージ アカウント アクセス キーまたは Shared Access Signature (SAS) トークンを構成するには:
アクセス キーの場合は、次のコード スニペットに示すようにプロパティ
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netを設定します。from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )SAS トークンの場合は、次のコード スニペットに示すようにプロパティ
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netを設定します。from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Note
上記のコード スニペットの
get_secret()呼び出しには、Azure Key Vault の名前と、Azure BLOB ストレージ アカウントのアクセス キーまたは SAS トークン用に作成されたシークレットの名前が必要です
同じノートブックでデータ ラングリング コードを実行します。 このコード スニペットで示されているものと同様に、データ URI を
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>として書式設定します。import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Note
この Python コード サンプルでは、
pyspark.pandasを使用します。 これは、Spark ランタイム バージョン 3.2 以降でのみサポートされます。
Azure Machine Learning データストアからのデータのインポートとラングリング
Azure Machine Learning データストアからデータにアクセスするには、URI 形式azureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>を使用してデータストア上のデータへのパスを定義します。 ノートブック セッションで Azure Machine Learning データストアからデータを対話形式でラングリングするには:
[コンピューティング] 選択メニューの [Azure Machine Learning サーバーレス Spark] の下にある [サーバーレス Spark コンピューティング] を選択するか、[コンピューティング] 選択メニューの [Synapse Spark プール] の下でアタッチされている Synapse Spark プールを選択します。
このコード サンプルでは、
azureml://データストアの URI、pyspark.pandasとpyspark.ml.feature.Imputerを使用して、Azure Machine Learning データストアから Titanic データを読み取ってラングリングする方法を示します。import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Note
この Python コード サンプルでは、
pyspark.pandasを使用します。 これは、Spark ランタイム バージョン 3.2 以降でのみサポートされます。
Azure Machine Learning データストアは、Azure ストレージ アカウントの資格情報を使用してデータにアクセスできます
- アクセス キー
- SAS トークン
- サービス プリンシパル (service principal)
または、資格情報のないデータ アクセスを提供します。 データストアの種類と基になる Azure Storage アカウントの種類に応じて、適切な認証メカニズムを選んでデータ アクセスを確保します。 次の表は、Azure Machine Learning データストア内のデータにアクセスするための認証メカニズムをまとめたものです。
| ストレージ アカウントの種類 | 資格情報のないデータ アクセス | データ アクセス メカニズム | ロールの割り当て |
|---|---|---|---|
| Azure BLOB | いいえ | アクセス キーまたは SAS トークン | ロールの割り当ては必要ありません |
| Azure BLOB | はい | ユーザー ID パススルー* | ユーザー ID には、Azure Blob Storage アカウントで適切なロールの割り当てが必要です |
| Azure Data Lake Storage (ADLS) Gen 2 | いいえ | サービス プリンシパル | サービス プリンシパルには、Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウントに 適切なロールの割り当て が必要です |
| Azure Data Lake Storage (ADLS) Gen 2 | はい | ユーザー ID パススルー | ユーザー ID には、Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウントに適切なロールの割り当てが必要です |
* ユーザー ID パススルーは、論理的な削除が有効になっていない場合にのみ、Azure Blob Storage アカウントを指す資格情報のないデータストアに対して機能します。
既定のファイル共有上のデータへのアクセス
既定のファイル共有は、サーバーレス Spark コンピューティング プールとアタッチされた Synapse Spark プールの両方にマウントされます。
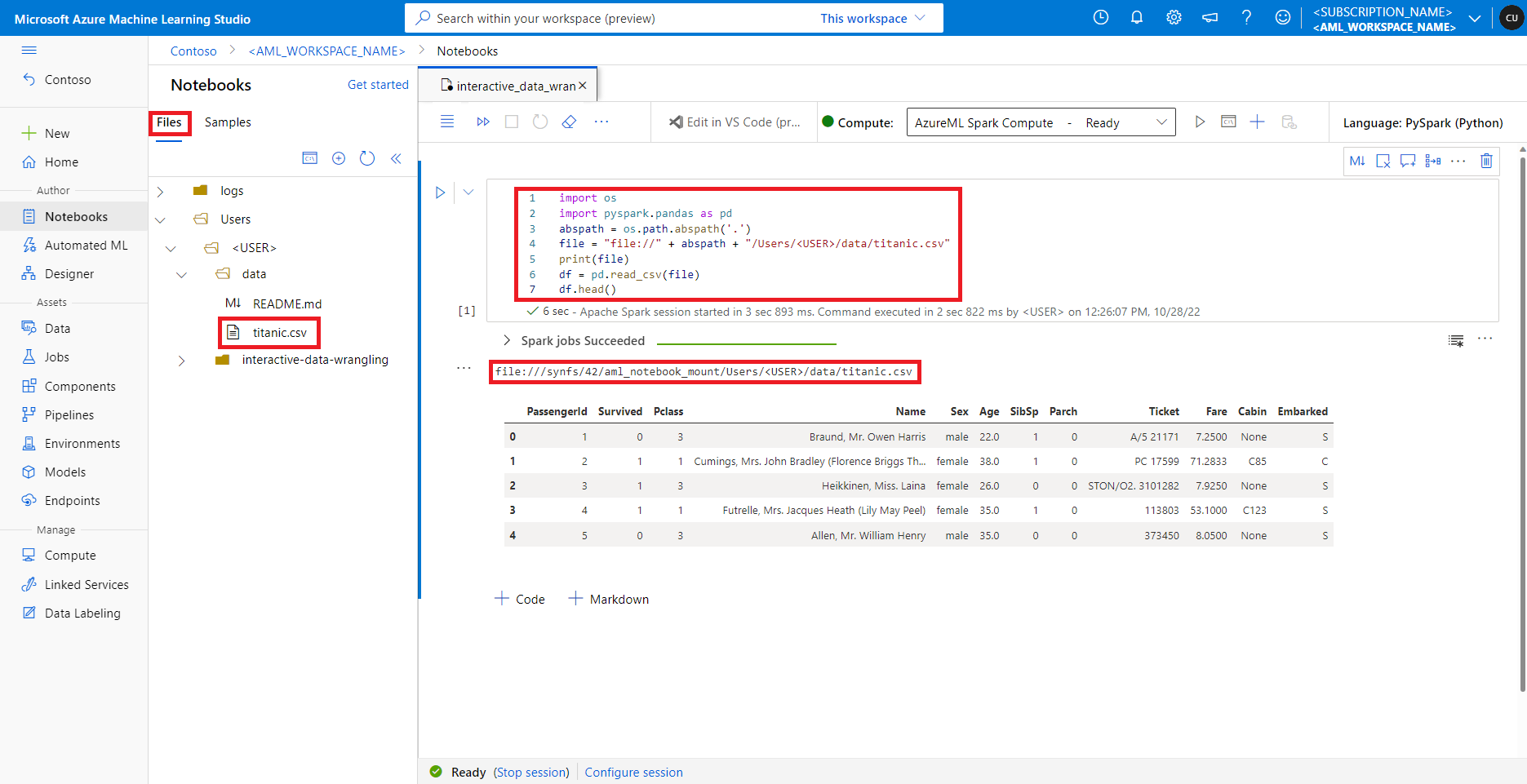
Azure Machine Learning スタジオでは、既定のファイル共有内のファイルがディレクトリ ツリーの [ファイル] タブに表示されます。ノートブック コードは、file:// プロトコルを使用して、このファイル共有に格納されているファイルに、追加の構成なしでファイルの絶対パスと共に直接アクセスできます。 次のコード スニペットは、既定のファイル共有に格納されているファイルにアクセスする方法を示しています。
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Note
この Python コード サンプルでは、pyspark.pandas を使用します。 これは、Spark ランタイム バージョン 3.2 以降でのみサポートされます。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示