Azure Machine Learning デザイナーのパイプラインとデータセットのサンプル
Azure Machine Learning デザイナーの組み込みサンプルを使用すると、独自の機械学習パイプラインの構築をすぐに開始できます。 Azure Machine Learning デザイナーの GitHub リポジトリには、一般的な機械学習のシナリオを理解するのに役立つ詳細なドキュメントが含まれています。
前提条件
- Azure サブスクリプション。 Azure サブスクリプションを持っていない場合は無料アカウントを作成する
- Azure Machine Learning ワークスペース
重要
このドキュメントで言及しているグラフィカル要素 (Studio やデザイナーのボタンなど) が表示されない場合は、そのワークスペースに対する適切なレベルのアクセス許可がない可能性があります。 ご自分の Azure サブスクリプションの管理者に連絡して、適切なレベルのアクセス許可があることを確認してください。 詳細については、「ユーザーとロールを管理する」を参照してください。
サンプル パイプラインを使用する
デザイナーによって、サンプル パイプラインのコピーが Studio ワークスペースに保存されます。 ニーズに合うようにパイプラインを編集し、独自のものとして保存できます。 これらをプロジェクトを開始するための出発点として使用します。
デザイナーのサンプルを使用する方法を次に示します。
ml.azure.com にサインインし、使用するワークスペースを選択します。
[デザイナー] を選択します。
[新しいパイプライン] セクションでサンプル パイプラインを選択します。
サンプルの完全な一覧については、 [Show more samples](その他のサンプルを表示する) を選択してください。
パイプラインを実行するには、最初に、パイプラインを実行する既定のコンピューティング先を設定する必要があります。
キャンバスの右側にある [設定] ペインで、 [コンピューティング先を選択] を選択します。
表示されたダイアログで、既存のコンピューティング先を選択するか、新しく作成します。 [保存] を選択します。
キャンバス上部の [送信] を選んで、パイプラインのジョブを送信します。
サンプル パイプラインとコンピューティングの設定によっては、ジョブが完了するまでに時間がかかることがあります。 既定のコンピューティング設定の最小ノード サイズは 0 です。これは、アイドル状態になった後に、デザイナーによってリソースが割り当てられる必要があることを意味します。 コンピューティング リソースが既に割り当てられているため、パイプラインの反復ジョブにかかる時間は短くなります。 さらにデザイナーでは、各コンポーネント用にキャッシュされた結果を使用して、効率を向上させます。
パイプラインの実行が完了したら、パイプラインをレビューし、各コンポーネントの出力を表示して詳細を確認できます。 コンポーネントの出力を表示するには、次の手順を使用します。
- 出力を表示するキャンバス内のコンポーネントを右クリックします。
- [可視化] を選択します。
このサンプルは、最も一般的な機械学習シナリオの一部の出発点として使用してください。
回帰
以下の組み込みの回帰のサンプルを確認します。
| サンプル タイトル | 説明 |
|---|---|
| 回帰 - 自動車価格の予測 (基本) | 線形回帰を使用して自動車の価格を予測します。 |
| 回帰 - 自動車価格の予測 (詳細) | デシジョン フォレストとブースト デシジョンツリー リグレッサーを使用して、自動車の価格を予測します。 モデルを比較して、最適なアルゴリズムを見つけてください。 |
分類
以下の組み込みの分類のサンプルを確認します。 サンプルの詳細については、デザイナーでサンプルを開いて、コンポーネントのコメントをご覧ください。
| サンプル タイトル | 説明 |
|---|---|
| 特徴の選択による二項分類 - 収入の予測 | 2 クラスのブースト デシジョン ツリーを使用して、収入を高または低として予測します。 ピアソンの相関関係を使用して、特徴を選択します。 |
| カスタム Python スクリプトを使用した二項分類 - 信用リスクの予測 | クレジット申込書を高リスクまたは低リスクとして分類します。 Python スクリプトの実行コンポーネントを使用して、データを重み付けします。 |
| 二項分類 - 顧客関係の予測 | 2 クラス ブースト デシジョン ツリーを使用して、顧客離反を予測します。 偏りのあるデータをサンプリングするには、SMOTE を使用します。 |
| テキスト分類 - Wikipedia SP 500 データセット | 多クラス ロジスティック回帰を使用して、Wikipedia の記事から会社の種類を分類します。 |
| 多クラス分類 - 文字認識 | 一連の二項分類器を作成して、手書きの文字を分類します。 |
Computer Vision
以下の組み込みの Computer Vision のサンプルを確認します。 サンプルの詳細については、デザイナーでサンプルを開いて、コンポーネントのコメントをご覧ください。
| サンプル タイトル | 説明 |
|---|---|
| DenseNet を使用した画像の分類 | Computer Vision コンポーネントを使用して、PyTorch DenseNet を基にした画像の分類モデルを構築します。 |
レコメンダー
以下の組み込みのレコメンダーのサンプルを確認します。 サンプルの詳細については、デザイナーでサンプルを開いて、コンポーネントのコメントをご覧ください。
| サンプル タイトル | 説明 |
|---|---|
| ワイド & ディープ ベースの推奨事項 - レストラン評価の予測 | レストランとユーザーの特徴量および評価から、レストラン レコメンダー エンジンを構築します。 |
| レコメンデーション - 映画の評価ツイート | 映画とユーザーの特徴と評価から映画レコメンダー エンジンを作成します。 |
ユーティリティ
機械学習のユーティリティと機能を示すサンプルの詳細を確認します。 サンプルの詳細については、デザイナーでサンプルを開いて、コンポーネントのコメントをご覧ください。
| サンプル タイトル | 説明 |
|---|---|
| Vowpal Wabbit モデルを使用した二項分類 - 成人の収入予測 | Vowpal Wabbit は、オンライン、ハッシュ、allreduce、リダクション、learning2search、アクティブ、対話型学習などの手法を使用した機械学習のフロンティアをプッシュする機械学習システムです。 このサンプルでは、Vowpal Wabbit モデルを使用して二項分類モデルを作成する方法を示します。 |
| カスタム R スクリプトの使用 - フライトの遅延予測 | カスタマイズされた R スクリプトを使用して、予定されている旅客便が 15 分以上遅れるかどうかを予測します。 |
| 二項分類のクロス検証 - 成人の収入予測 | クロス検証を使用して、成人の収入予測のための二項分類器を作成します。 |
| 順列の特徴量の重要度 | 順列の特徴量の重要度を使用して、テスト データセットの重要度スコアを計算します。 |
| 二項分類のパラメーターの調整 - 成人の収入予測 | モデルのハイパーパラメーターの調整を使用して、バイナリ分類器の作成に最適なハイパーパラメーターを見つけます。 |
データセット
Azure Machine Learning デザイナーで新しいパイプラインを作成する場合、さまざまなサンプル データセットが既定で用意されています。 これらのサンプル データセットは、デザイナーのホームページのサンプル パイプラインで使用されます。
サンプル データセットは、 [データセット]-[サンプル] カテゴリの下にあります。 これは、デザイナーのキャンバスの左側にあるコンポーネント パレットにあります。 これらのいずれのデータセットも、キャンバスにドラッグすることにより独自のパイプラインで使用できます。
| データセットの名前 | データセットの説明 |
|---|---|
| 米国国勢調査局提供の、成人収入に関する二項分類データセット | 調整後の所得指数が 100 を超える就労成人男性 (16 歳以上) を対象とした、米国国勢調査局のデータベース (1994 年) のサブセットです。 [使用状況] :人口統計データを使用して対象の人々を分類し、個人が 1 年間に 50,000 ドル以上の年収を得られるかどうかを予測します。 関連の研究: Kohavi, R.、Becker, B. (1996 年)。 UCI Machine Learning リポジトリ。 カリフォルニア州アーバイン:カリフォルニア大学、情報・コンピューター サイエンス学部 |
| 自動車価格データ (生データ) | メーカー/モデル別にまとめた自動車の情報です。価格、シリンダー数、燃費、保険リスク スコアなどの情報が含まれます。 リスク スコアはまず車体価格に関連付けられます。 その後、アクチュアリー (保険数理士) の間でシンボリングと呼ばれるプロセスによって、実際のリスクに対して調整されます。 +3 は自動車のリスクが高く、-3 は高い安全性が見込まれることを示しています。 [使用状況] :回帰または多変量分類を使用して、機能別のリスク スコアを予測します。 関連の研究: Schlimmer, J.C. (1987)。 UCI Machine Learning リポジトリ。 カリフォルニア州アーバイン:カリフォルニア大学、情報・コンピューター サイエンス学部。 |
| CRM 強い欲求ラベルの共有 | KDD Cup 2009 顧客間関係の予測に関する課題のラベル (orange_small_train_appetency.labels)。 |
| CRM 離反ラベルの共有 | KDD Cup 2009 顧客間関係の予測に関する課題のラベル (orange_small_train_churn.labels)。 |
| CRM データセットの共有 | このデータは、KDD Cup 2009 顧客関係の予測に関する課題から取得しています (orange_small_train.data.zip)。 データセットには、French Telecom company Orange の顧客 50,000 人のデータが含まれます。 各顧客には匿名化された特徴が 230 あり、その中の 190 が数値で、40 がカテゴリです。 特徴はきわめて疎です。 |
| CRM アップセリング ラベルの共有 | KDD Cup 2009 顧客間関係の予測に関する課題のラベル (orange_large_train_upselling.labels |
| フライト遅延データ | 米国運輸省の TranStats データ コレクションから取得した旅客機の定時運航データ (定時)。 データセットには、2013 年 4 月から 10 月までの期間のデータが含まれます。 デザイナーにアップロードする前に、データセットは次のように処理されました。 - 米国本土の混雑度が上位 70 までの空港を含めるように、データセットをフィルター処理しました - キャンセルされたフライトは 15 分超の遅延として分類しました - 迂回したフライトをフィルターで除外しました - 次の列が選択されました。Year、Month、DayofMonth、DayOfWeek、Carrier、OriginAirportID、DestAirportID、CRSDepTime、DepDelay、DepDel15、CRSArrTime、ArrDelay、ArrDel15、Cancelled |
| ドイツのクレジット カード UCI データセット | german.data ファイルを使用した、UCI Statlog (ドイツのクレジット カード) データセット (Statlog+German+Credit+Data)。 データセットは、低信用リスクまたは高信用リスクとして属性のセットで表現された人々を分類します。 サンプルはそれぞれ人を表します。 20 の特徴があり、数値とカテゴリの両方と、二項のラベル (信用リスク値) で構成されます。 高信用リスクのエントリにはラベル 2、低信用リスクのエントリにはラベル 1 が付きます。 低信用リスクのサンプルを高信用リスクとして誤って分類した場合のコストは 1 ですが、高信用リスクのサンプルを低信用リスクとして誤って分類した場合のコストは 5 です。 |
| IMDB 映画のタイトル | このデータセットには、X のツイートで評価された映画に関する情報 (IMDB 映画 ID、映画名、ジャンル、制作年) が含まれています。 約 17,000 件の映画の情報があります。 データセットは、S. Dooms, T. De Pessemier and L. Martens による論文 「MovieTweetings: a Movie Rating Dataset Collected From Twitter。 Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013」で紹介されました。 |
| 映画の評価 | このデータセットは、ムービー ツイート データセットの拡張バージョンです。 このデータセットには、X の適切に構造化されたツイートから抽出された 17 万件の映画の評価が含まれています。各インスタンスはツイートを表しており、ユーザー ID、IMDB 映画 ID、評価、タイムスタンプ、このツイートのお気に入りの数、このツイートのリツイート数からなるタプルです。 データセットは、A. Said、S. Dooms、B. Loni、D. Tikk によって Recommender Systems Challenge 2014 のために提供されました。 |
| 天候データセット | NOAA の 1 時間ごとの陸上の気象観測 (2013 年 4 月から 2013 年 10 月までのデータをマージ)。 気象データには、2013 年 4 月から 10 月までの期間の航空気象観測所での観測が含まれます。 デザイナーにアップロードする前に、データセットは次のように処理されました。 - 気象観測所 ID を、対応する空港 ID にマッピングしました - 混雑度が上位 70 の空港に関連付けられていない気象観測所をフィルターで除外しました - Date 列を Year、Month、Day の各列に分割しました - 次の列が選択されました。AirportID、Year、Month、Day、Time、TimeZone、SkyCondition、Visibility、WeatherType、DryBulbFarenheit、DryBulbCelsius、WetBulbFarenheit、WetBulbCelsius、DewPointFarenheit、DewPointCelsius、RelativeHumidity、WindSpeed、WindDirection、ValueForWindCharacter、StationPressure、PressureTendency、PressureChange、SeaLevelPressure、RecordType、HourlyPrecip、Altimeter |
| Wikipedia SP 500 データセット | データは、S&P 500 企業それぞれの記事に基づいて Wikipedia (https://www.wikipedia.org/) から取得され、XML データとして格納されています。 デザイナーにアップロードする前に、データセットは次のように処理されました。 - 特定の各企業のテキスト コンテンツを抽出しました - Wiki の書式設定を削除しました - 英数字以外の文字を削除しました - すべてのテキストを小文字に変換しました - 既知の会社のカテゴリを追加しました いくつかの企業の記事が見つからないため、レコード数は 500 未満であることに注意してください。 |
| レストラン特徴データ | 料理の種類、食事スタイル、場所など、レストランとその特徴に関するメタデータのセットです。 [使用状況] :このデータセットを、レストランに関する他の 2 つのデータセットと組み合わせて使用して、レコメンダー システムの調整とテストを実施します。 関連の研究: Bache, K.、Lichman, M.(2013 年)。 UCI Machine Learning リポジトリ。 カリフォルニア州アーバイン:カリフォルニア大学、情報・コンピューター サイエンス学部。 |
| レストランの評価 | ユーザーによるレストランの評価 (0 ~ 2) が含まれます。 [使用状況] :このデータセットを、レストランに関する他の 2 つのデータセットと組み合わせて使用して、レコメンダー システムの調整とテストを実施します。 関連の研究: Bache, K.、Lichman, M.(2013 年)。 UCI Machine Learning リポジトリ。 カリフォルニア州アーバイン:カリフォルニア大学、情報・コンピューター サイエンス学部。 |
| レストラン顧客データ | 人口統計データや嗜好など、顧客に関するメタデータのセットです。 [使用状況] :このデータセットを、レストランに関する他の 2 つのデータセットと組み合わせて使用して、レコメンダー システムの調整とテストを実施します。 関連の研究: Bache, K.、Lichman, M.(2013 年)。 UCI Machine Learning リポジトリ アービン、CA:カリフォルニア大学、情報・コンピューター サイエンス学部。 |
リソースをクリーンアップする
重要
作成したリソースは、Azure Machine Learning のその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
すべてを削除する
作成したすべてのものを使用する予定がない場合は、料金が発生しないように、リソース グループ全体を削除します。
Azure portal で、ウィンドウの左側にある [リソース グループ] を選択します。
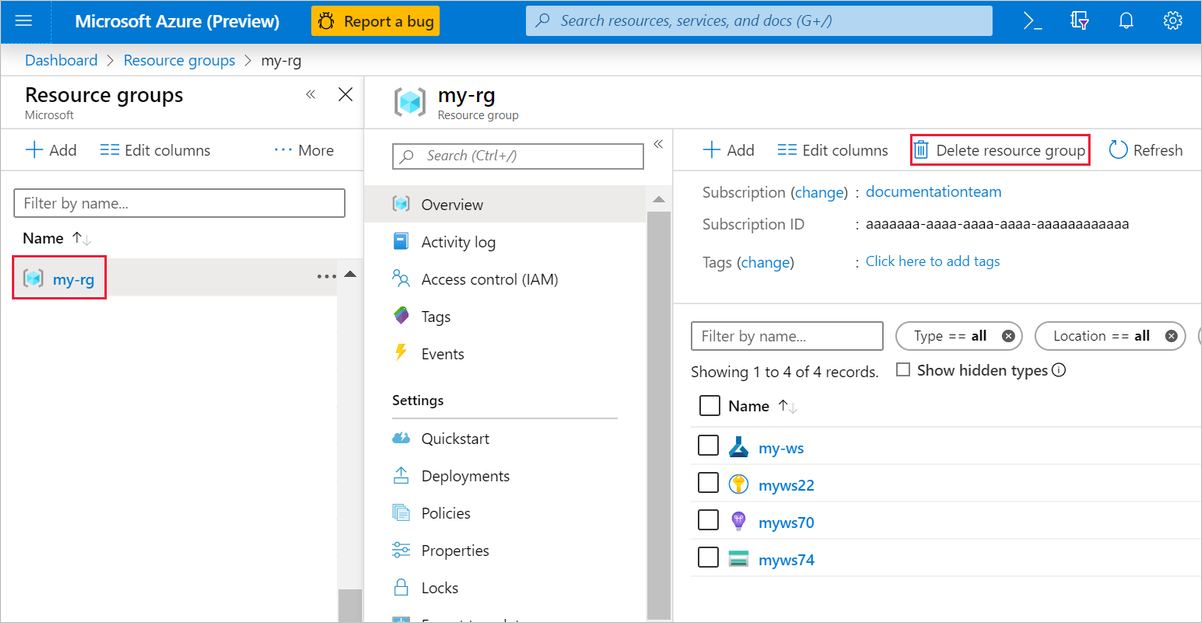
一覧から、作成したリソース グループを選択します。
[リソース グループの削除] を選択します。
リソース グループを削除すると、デザイナーで作成したすべてのリソースも削除されます。
個々の資産を削除する
実験を作成したデザイナーで、個々の資産を選択し、[削除] ボタンを選択してそれらを削除します。
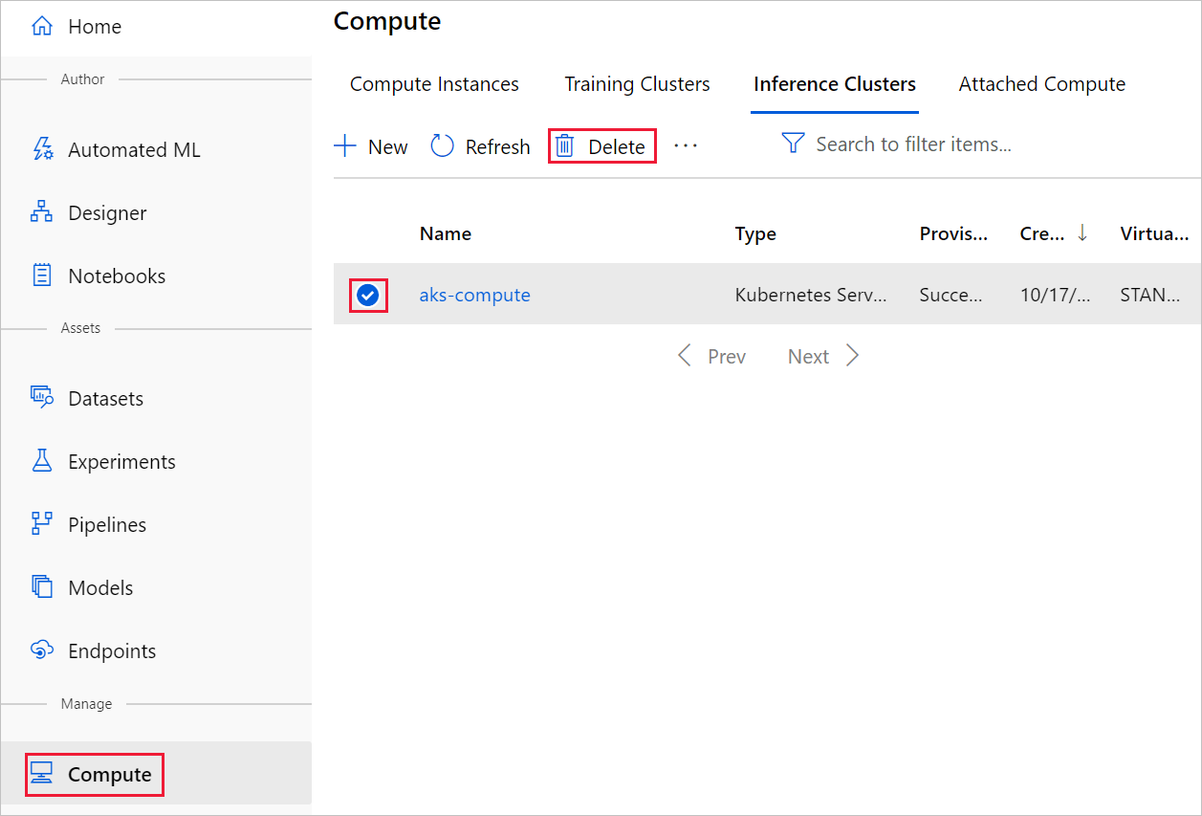
ここで作成したコンピューティング ターゲットは、使用されていない場合、自動的にゼロ ノードに自動スケーリングされます。 このアクションは、料金を最小限に抑えるために実行されます。 コンピューティング ターゲットを削除する場合は、次の手順を実行してください。
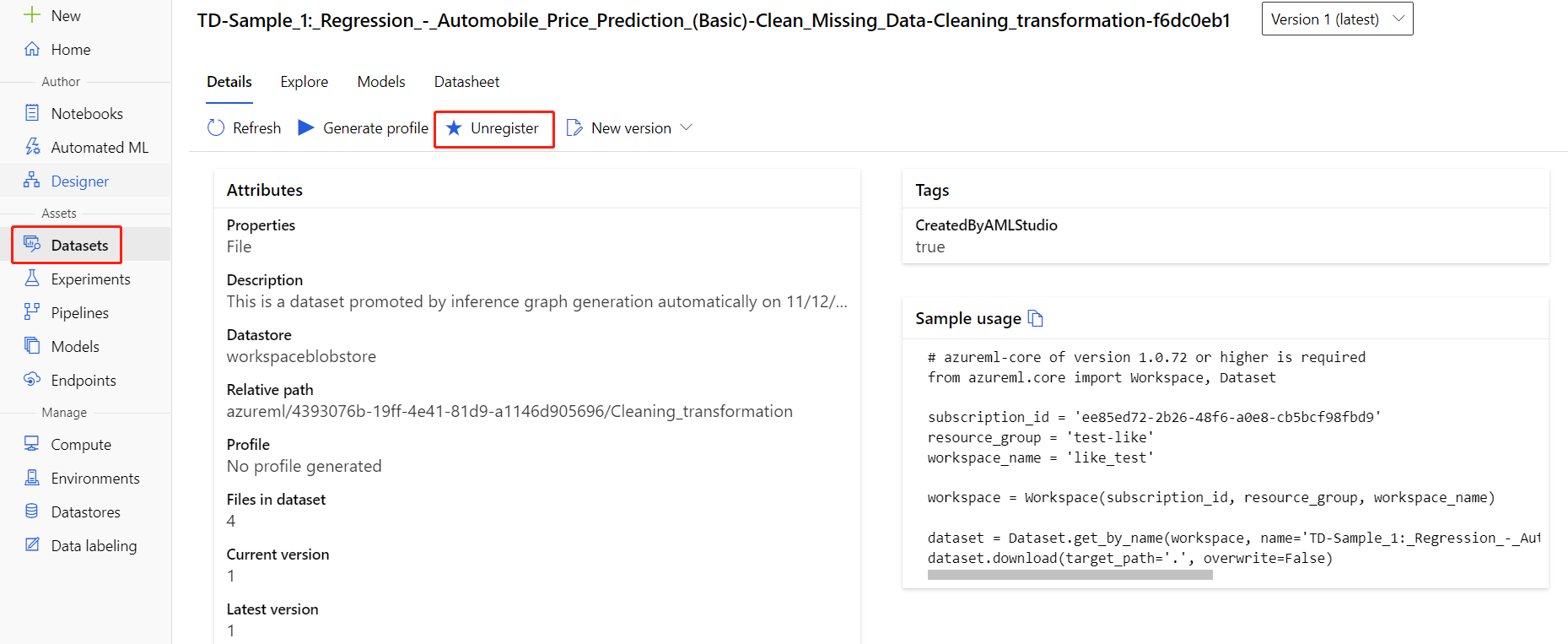
各データセットを選択し、[登録解除] を選択することによって、ワークスペースからデータセットを登録解除できます。
データセットを削除するには、Azure portal または Azure Storage Explorer を使用してストレージ アカウントに移動し、これらのアセットを手動で削除します。
次のステップ
予測分析と機械学習の基本について学習する: チュートリアル: デザイナーを使用して自動車の価格を予測する