チュートリアル 1: マネージド Feature Store を使用して特徴量セットの開発と登録を行う
このチュートリアル シリーズでは、プロトタイプ作成、トレーニング、運用という機械学習ライフサイクルのすべてのフェーズを、特徴量によってシームレスに統合する方法について説明します。
Azure Machine Learning のマネージド Feature Store を使用して、特徴量の検出、作成、運用化を行うことができます。 機械学習のライフサイクルには、さまざまな特徴量を実験するプロトタイプ作成フェーズが含まれます。 また、モデルがデプロイされ、推論ステップによって特徴量データが探索される運用化フェーズも含まれます。 特徴量は、機械学習ライフサイクルにおける結合組織として機能します。 特徴量ストアの基本的な概念の詳細については、「マネージド Feature Store とは」および「マネージド Feature Store の最上位エンティティについて」を参照してください。
このチュートリアルでは、カスタム変換を使って特徴量セットの仕様を作成する方法を説明しました。 次に、その特徴量セットを使用してトレーニング データを生成し、具体化を有効にし、バックフィルを実行します。 具体化では、特徴ウィンドウの特徴値を計算し、これらの値を具体化ストアに格納します。 すべての特徴クエリで、具体化ストアからの値を使用できます。
具体化しない場合、特徴セット クエリでは、変換がソースに即座に適用され、値を返す前に特徴量が計算されます。 これは、プロトタイプ作成フェーズで適切に機能します。 ただし、運用環境でトレーニングおよび推論操作を実行する場合は、信頼性と可用性を高めるために特徴を具体化することをお勧めします。
このチュートリアルは、マネージド Feature Store のチュートリアル シリーズの最初のパートです。 ここでは、次の方法を学習します。
- 最小限の Feature Store リソースを新しく作成する。
- 特徴量変換機能を使用して特徴量セットを開発し、ローカルでテストする。
- Feature Store エンティティを Feature Store に登録する。
- 開発した特徴量セットを Feature Store に登録する。
- 作成した特徴量を使用してサンプル トレーニング データフレームを生成する。
- 特徴セットでオフライン具体化を有効にし、特徴データをバックフィルします。
このチュートリアル シリーズには、次の 2 つのトラックがあります。
- SDK のみのトラックでは、Python SDK のみを使用します。 純粋な Python ベースの開発とデプロイの場合は、このトラックを選択します。
- SDK および CLI トラックでは、特徴量セットの開発とテストにのみ Python SDK を使用し、CRUD (作成、読み取り、更新、削除) 操作には CLI を使用します。 このトラックは、CLI/YAML が推奨される継続的インテグレーションと継続的デリバリー (CI/CD) または GitOps シナリオで役立ちます。
前提条件
このチュートリアルを進める前に、次の前提条件を満たしていることを確認してください。
Azure Machine Learning ワークスペース。 ワークスペースの作成の詳細については、ワークスペース リソースの作成に関するクイックスタートのページを参照してください。
ユーザー アカウントで、特徴量ストアが作成されるリソース グループに対する所有者ロール。
このチュートリアルで新しいリソース グループを使用する場合は、リソース グループを削除すると、すべてのリソースを簡単に削除できます。
ノートブック環境を準備する
このチュートリアルでは、開発用に Azure Machine Learning Spark ノートブックを使います。
Azure Machine Learning スタジオ環境の左側のペインで [ノートブック] を選び、[サンプル] タブを選びます。
featurestore_sample ディレクトリを参照し ([サンプル]>[SDK v2]>[sdk]>[python]>[featurestore_sample] の順に選びます)、[複製] を選びます。
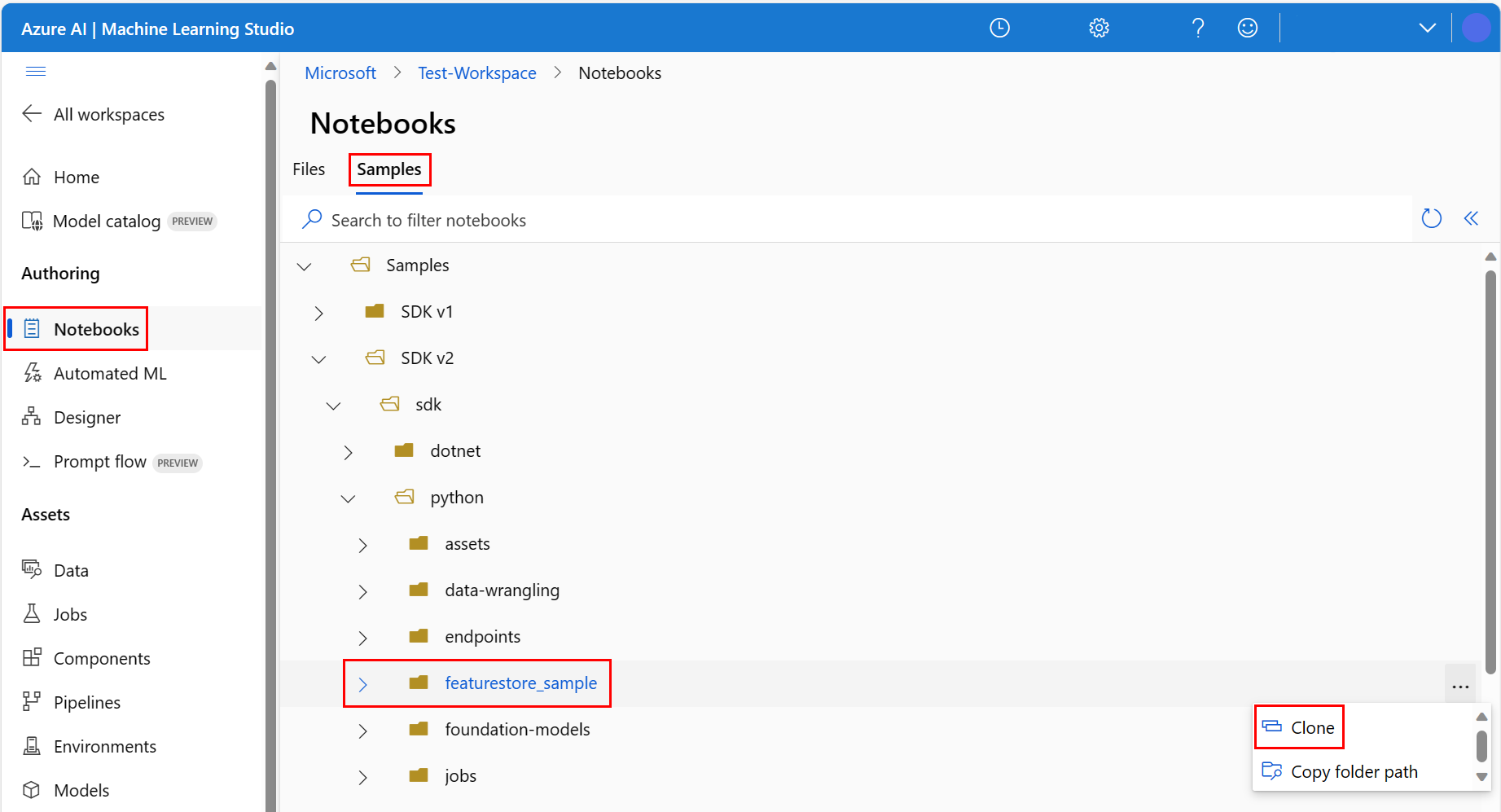
[ターゲット ディレクトリの選択] パネルが開きます。 [ユーザー] ディレクトリを選んでから、"自分のユーザー名" を選び、最後に [複製] を選びます。
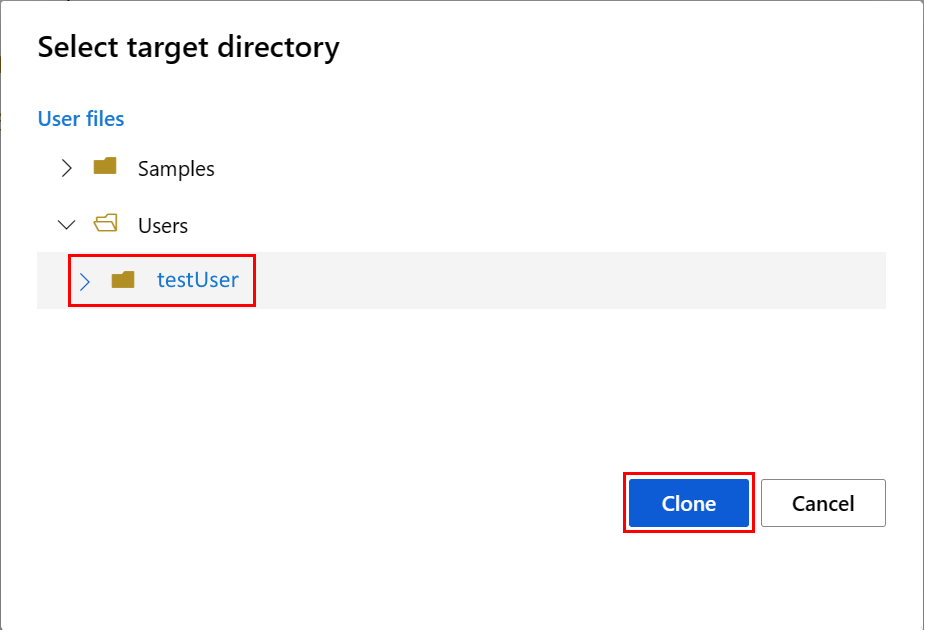
ノートブック環境を構成するには、conda.yml ファイルをアップロードする必要があります。
- 左側のペインで [ノートブック] を選び、[ファイル] タブを選びます。
- env ディレクトリを参照し ([ユーザー]><自分のユーザー名>>[featurestore_sample]>[project]>[env] の順に選択)、conda.yml ファイルを選びます。
- [Download] を選択します。

- 上部のナビゲーションにある [コンピューティング] ドロップダウンで、[サーバーレス Spark コンピューティング] を選択します。 この操作には 1 分から 2 分かかる場合があります。 上部のステータス バーに [セッションの構成] と表示されるまで待ちます。
- 上部のステータス バーで [セッションの構成] を選びます。
- [Python パッケージ] を選びます。
- [Conda ファイルをアップロード] を選びます。
- ローカル デバイスにダウンロードした
conda.ymlファイルを選びます。 - (省略可能) サーバーレス Spark クラスターの起動時間を短縮するには、セッション タイムアウト値 (アイドル時間 (分単位)) を増やします。
Azure Machine Learning 環境で、ノートブックを開き、[セッションの構成] を選びます。

[セッションの構成] パネルで、[Python パッケージ] を選びます。
Conda ファイルをアップロードします。
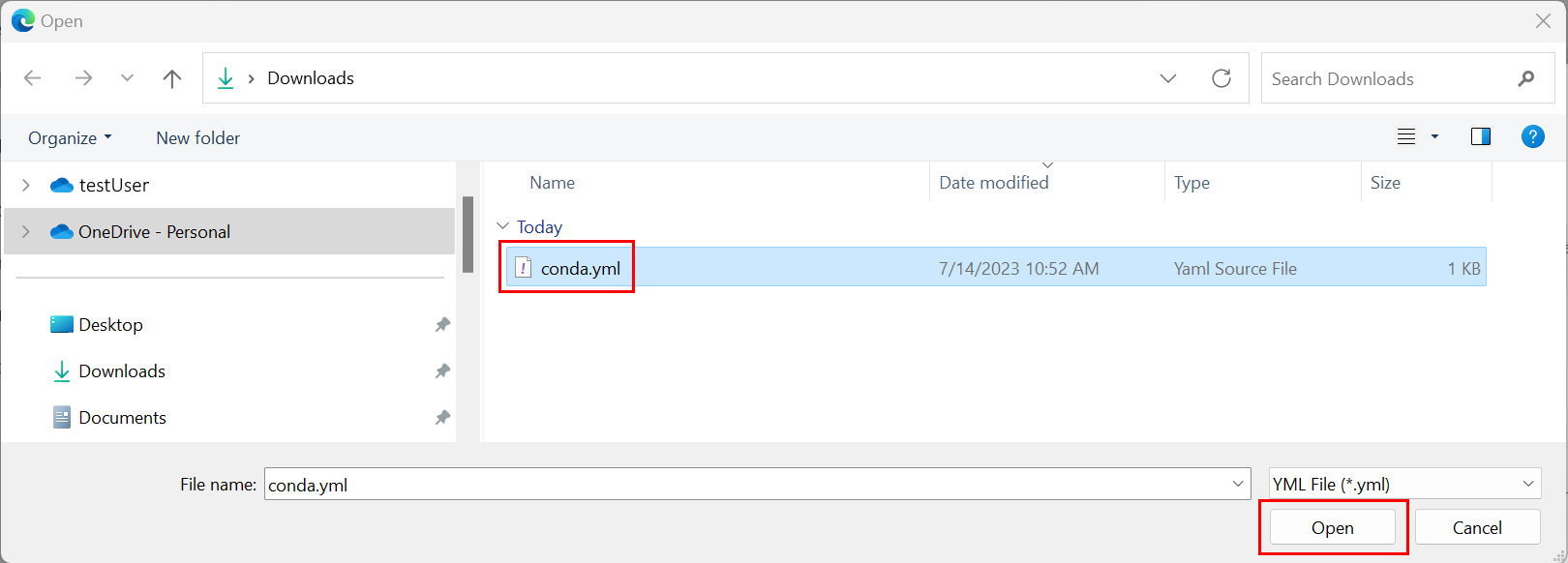
- [Python パッケージ] タブで、[Conda ファイルのアップロード] を選びます。
- Conda ファイルをホストするディレクトリを参照します。
- [conda.yml] を選び、[開く] を選びます。
適用を選択します。







Spark セッションを開始する
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")サンプル用のルート ディレクトリを設定する
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")CLI を設定する
該当なし。
Note
プロジェクト間で特徴量を再利用するには、特徴量ストアを使用します。 特徴量ストアの特徴量を利用し、プロジェクト ワークスペース (Azure Machine Learning ワークスペース) を使用して推論モデルのトレーニングを行います。 多くのプロジェクト ワークスペースで、同じ Feature Store を共有および再利用できます。
このチュートリアルでは、次の 2 つの SDK を使います。
Feature store CRUD SDK
Azure Machine Learning ワークスペースで使用するものと同じ
MLClient(パッケージ名azure-ai-ml) SDK を使用します。 Feature Store は、ワークスペースの種類として実装されます。 その結果、この SDK は、特徴量ストア、特徴量セット、特徴量ストア エンティティの CRUD 操作に使用されます。Feature store core SDK
この SDK (
azureml-featurestore) は、特徴量セットの開発と使用を目的としています。 このチュートリアルの後の手順では、次の操作について説明します。- 特徴量セット仕様を開発する。
- 特徴量データを取得する。
- 登録済み特徴量セットを一覧表示または取得する。
- 特徴量取得仕様を生成および解決する。
- ポイントインタイム結合を使用してトレーニングおよび推論のデータを生成する。
このチュートリアルでは、前の conda.yml の手順でこのステップが説明されているため、これらの SDK を明示的にインストールする必要はありません。
最小限の Feature Store を作成する
名前、場所、その他の値など、特徴量ストアのパラメーターを設定します。
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]特徴量ストアを作成します。
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Azure Machine Learning 用の Feature store core SDK クライアントを初期化します。
このチュートリアルで前に説明したように、Feature store core SDK クライアントは特徴量の開発と使用に使用されます。
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Feature Store の "Azure Machine Learning データ科学者" ロールをユーザー ID に付与します。 「ユーザー オブジェクト ID を検索する」で説明するように、Azure portal から Microsoft Entra オブジェクト ID の値を取得します。
AzureML データ科学者ロールをユーザー ID に割り当てて、Feature Store ワークスペースにリソースを作成できるようにします。 アクセス許可が反映されるまでに時間が必要な場合があります。
アクセス制御の詳細については、「マネージド Feature Store のアクセス制御を管理する」を参照してください。
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
特徴量セットのプロトタイプ作成と開発
次の手順では、ローリング ウィンドウ集計ベースの特徴量を持つ transactions という名前の特徴量セットを作成します。
transactionsソース データを調べます。このノートブックでは、パブリックにアクセスできる BLOB コンテナーでホストされているサンプル データを使用します。 これは、
wasbsドライバーを使用して Spark にのみ読み込むことができます。 独自のソース データを使用して特徴量セットを作成する場合は、その特徴量セットを Azure Data Lake Storage Gen2 アカウントでホストし、データ パスでabfssドライバーを使用します。# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueローカルで特徴量セットを開発します。
特徴量セット仕様は、ローカルで開発してテストできる特徴量セットの自己完結型定義です。 ここでは、次のローリング ウィンドウ集計特徴量を作成します。
transactions three-day counttransactions amount three-day sumtransactions amount three-day avgtransactions seven-day counttransactions amount seven-day sumtransactions amount seven-day avg
特徴量変換コード ファイル (featurestore/featuresets/transactions/transformation_code/transaction_transform.py) を確認します。 特徴量に対して定義されているローリング集計に注意してください。 これは Spark トランスフォーマーです。
特徴量セットと変換の詳細については、「マネージド Feature Store とは」を参照してください。
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )特徴量セット仕様としてエクスポートします。
特徴量セット仕様を特徴量ストアに登録するには、その仕様を特定の形式で保存する必要があります。
生成された
transactions特徴量セット仕様を確認します。 仕様を表示するには、ファイル ツリーから featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml を開きます。仕様には、次の要素が含まれています。
source: ストレージ リソースへの参照。 この場合は、BLOB ストレージ リソース内の Parquet ファイルです。features: 特徴量とそのデータ型の一覧。 変換コードを提供する場合は、コードから特徴量とデータ型に対応するデータフレームを返す必要があります。index_columns: 特徴量セットから値にアクセスするために必要な結合キー。
仕様の詳細については、「マネージド Feature Store の最上位エンティティについて」および「CLI (v2) 特徴量セット YAML スキーマ」を参照してください。
特徴量セット仕様を永続化すると、特徴量セット仕様をソース管理できるというもう 1 つの利点があります。
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
特徴量ストア エンティティを登録する
ベスト プラクティスとして、エンティティは、同じ論理エンティティを使う複数の特徴量セットの間で同じ結合キー定義の使用を強制するのに役立ちます。 エンティティの例としては、アカウントと顧客があります。 エンティティは通常、1 回作成され、特徴量セット間で再利用されます。 詳細については、「マネージド Feature Store の最上位エンティティについて」を参照してください。
Feature Store CRUD クライアントを初期化します。
このチュートリアルで前に説明したように、
MLClientは特徴量資産の CRUD (作成、読み取り、更新、削除) に使用されます。 ここに示すノートブック コード セルのサンプルでは、前のステップで作成した特徴量ストアを検索します。 ここでは、スコープがリソース グループ レベルで設定されているため、このチュートリアルの前半で使用したものと同じml_client値を再利用することはできません。 適切なスコープは、Feature Store の作成に関する前提条件です。このコード サンプルでは、クライアントのスコープは Feature Store レベルです。
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )accountエンティティを特徴量ストアに登録します。string型の結合キーaccountIDが含まれるaccountエンティティを作成します。from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
トランザクション特徴量セットを Feature Store に登録する
次のコードを使用して、特徴量セット資産を Feature Store に登録します。 その後、その資産を再利用し、簡単に共有できます。 特徴量セット資産の登録では、バージョン管理や具体化などの管理機能が提供されます。 このチュートリアル シリーズの後の手順では、管理機能について説明します。
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())Feature Store UI について調べる
Feature Store 資産の作成と更新は、SDK と CLI を介してのみ行うことができます。 特徴量ストアの検索と参照には、UI を使用できます。
- Azure Machine Learning のグローバル ランディング ページを開きます。
- 左側のペインで、[特徴量ストア] を選びます。
- このアクセス可能な特徴量ストアの一覧から、このチュートリアルで先ほど作成した特徴量ストアを選びます。
オフライン ストアのユーザー アカウントにストレージ BLOB データ閲覧者ロールを付与する
オフライン ストアのユーザー アカウントにストレージ BLOB データ閲覧者ロールを割り当てる必要があります。 これにより、ユーザー アカウントは、オフライン具体化ストアから具体化された特徴データを読み取ることができます。
「ユーザー オブジェクト ID を検索する」で説明するように、Azure portal から Microsoft Entra オブジェクト ID の値を取得します。
Feature Store UI の Feature Store [概要] ページから、オフライン具体化ストアに関する情報を取得します。 オフライン具体化ストアのストレージ アカウント サブスクリプション ID、ストレージ アカウント リソース グループ名、ストレージ アカウント名の値は、オフライン具体化ストア カードにあります。
![Feature Store の [概要] ページのオフライン ストア アカウント情報を示すスクリーンショット。](media/tutorial-get-started-with-feature-store/offline-store-information.png?view=azureml-api-2)
アクセス制御の詳細については、「マネージド Feature Store のアクセス制御を管理する」を参照してください。
ロールの割り当てにこのコード セルを実行します。 アクセス許可が反映されるまでに時間が必要な場合があります。
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )
![Feature Store の [概要] ページのオフライン ストア アカウント情報を示すスクリーンショット。](media/tutorial-get-started-with-feature-store/offline-store-information.png?view=azureml-api-2#lightbox)
登録済みの特徴量セットを使用してトレーニング データのデータフレームを生成する
観測データを読み込みます。
観測データには、通常、トレーニングと推論に使われるコア データが含まれます。 このデータを特徴量データと結合して、完全なトレーニング データ リソースを作成します。
観測データは、イベント自体の発生時にキャプチャされたデータです。 ここでは、トランザクション ID、アカウント ID、トランザクション金額値を含むコア トランザクション データがあります。 このデータをトレーニングに使用するので、ターゲット変数 (is_fraud) も追加されています。
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted value登録済みの特徴量セットを取得し、その特徴量を一覧表示します。
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))トレーニング データに含める特徴量を選びます。 次に、feature store SDK を使用してトレーニング データ自体を生成します。
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueポイントインタイム結合によって、特徴量がトレーニング データに追加されます。
transactions 特徴量セットでオフライン具体化を有効にする
特徴量セットの具体化が有効になった後、バックフィルを実行できます。 また、定期的な具体化ジョブをスケジュールすることもできます。 詳細については、「シリーズの 3 番目のチュートリアル」をご覧ください。
特徴量データのサイズに応じて、yaml ファイルの spark.sql.shuffle.partitions を設定する
Spark の構成の spark.sql.shuffle.partitions は省略可能なパラメーターであり、特徴量セットがオフライン ストアに具体化されるときに生成される (1 日あたりの) Parquet ファイルの数に影響を与える可能性があります。 このパラメーターの既定値は 200 です。 ベスト プラクティスとして、多数の小さな Parquet ファイルを生成することは避けてください。 特徴量セットの具体化後にオフラインの特徴量取得が遅くなった場合は、オフライン ストアの対応するフォルダーに移動し、小さな Parquet ファイルが (1 日あたりで) 多すぎることに関係する問題かどうかを調べ、それに応じてこのパラメーターの値を調整します。
Note
このノートブックで使われるサンプル データは小さなものです。 したがって、featureset_asset_offline_enabled.yaml ファイルでこのパラメーターは 1 に設定されています。
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())また、特徴量セット資産を YAML リソースとして保存することもできます。
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)transactions 特徴量セットのデータをバックフィルします。
前に説明したように、具体化では、特徴ウィンドウの特徴値を計算し、計算したそれらの値を具体化ストアに格納します。 特徴量の具体化により、計算値の信頼性と可用性が向上します。 すべての特徴クエリで、具体化ストアの値が使用されるようになります。 この手順では、18 か月の特徴ウィンドウに対して 1 回限りのバックフィルを実行します。
Note
バックフィル データ ウィンドウの値を決定することが必要な場合があります。 このウィンドウは、トレーニング データのウィンドウと一致している必要があります。 たとえば、トレーニングに 18 か月間のデータを使用するには、18 か月間の特徴を取得する必要があります。 つまり、18 か月分のウィンドウをバックフィルする必要があります。
このコード セルは、定義された特徴ウィンドウの現在の状態 [なし] または [未完了] によってデータを具体化します。
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])ヒント
timestamp列はyyyy-MM-ddTHH:mm:ss.fffZ形式に従う必要があります。feature_window_start_timeとfeature_window_end_timeの粒度は秒に制限されます。datetimeオブジェクトで指定されたミリ秒数は無視されます。- 具体化ジョブは、特徴ウィンドウ内のデータが、バックフィル ジョブの送信中に定義された
data_statusと一致する場合にのみ送信されます。
特徴量セットからサンプル データを出力します。 出力情報は、データが具体化ストアから取得されたことを示しています。 get_offline_features() メソッドでトレーニング データと推論データを取得しました。 また、既定で具体化ストアも使用します。
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))オフラインの特徴量具体化についてさらに詳しく調べる
具体化ジョブ UI で、特徴量セットの特徴量具体化の状態を調べることができます。
左側のペインで、[特徴量ストア] を選びます。
アクセス可能な Feature Store の一覧から、バックフィルを実行した Feature Store を選びます。
[Materialization jobs]\(具体化ジョブ\) タブを選択します。
![特徴量セットの [具体化ジョブ] UI を示すスクリーンショット。](media/tutorial-get-started-with-feature-store/feature-set-materialization-ui.png?view=azureml-api-2)
![特徴量セットの [具体化ジョブ] UI を示すスクリーンショット。](media/tutorial-get-started-with-feature-store/feature-set-materialization-ui.png?view=azureml-api-2#lightbox)
データ具体化の状態は、次の場合があります。
- 完了 (緑)
- 未完了 (赤)
- 保留中 (青)
- なし (灰色)
"データ間隔" は、同じデータ具体化状態であるデータの連続した部分を表します。 たとえば、以前のスナップショットには、オフライン具体化ストアに 16 個の "データ間隔" があります。
データには、最大 2,000 個の "データ間隔" を含めることができます。 データに 2,000 個を超える "データ間隔" が含まれる場合は、新しいバージョンの特徴量セットを作成します。
1 つのバックフィル ジョブで、複数のデータ状態 (たとえば、
["None", "Incomplete"]) の一覧を指定できます。バックフィル中に、定義された特徴ウィンドウ内にある "データ間隔" ごとに新しい具体化ジョブが送信されます。
具体化ジョブが保留中の場合、またはそのジョブがまだバックフィルされていない "データ間隔" で実行されている場合、その "データ間隔" に対して新しいジョブは送信されません。
失敗した具体化ジョブを再試行できます。
Note
失敗した具体化ジョブのジョブ ID を取得するには、次のようにします。
- 特徴量セットの具体化ジョブ UI に移動します。
- [状態] が [失敗] である特定のジョブの [表示名] を選択します。
- ジョブの [概要] ページにある [名前] プロパティの下で ジョブ ID を見つけます。 これは
Featurestore-Materialization-で始まります。
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
オフライン具体化ストアの更新
- オフライン具体化ストアを Feature Store レベルで更新する必要がある場合、Feature Store 内のすべての特徴量セットでオフライン具体化が無効になっている必要があります。
- 特徴量セットでオフライン具体化が無効になっている場合、オフライン具体化ストアで既に具体化されているデータの具体化状態がリセットされます。 リセットにより、既に具体化されているデータが使用できなくなります。 オフライン具体化を有効にした後、具体化ジョブを再送信する必要があります。
このチュートリアルでは、Feature Store からの特徴を使用してトレーニング データを構築し、オフライン Feature Store に対して具体化を有効にして、バックフィルを実行しました。 次に、これらの特徴を使用してモデル トレーニングを実行します。
クリーンアップ
このシリーズの 5 番目のチュートリアルでは、リソースを削除する方法について説明します。
次のステップ
- シリーズの次のチュートリアル「特徴量を使用してモデルの実験とトレーニングを行う」を参照してください。
- 特徴量ストアの概念およびマネージド Feature Store の最上位エンティティの詳細。
- マネージド Feature Store の ID とアクセス制御に関する記事をご覧ください。
- マネージド Feature Store のトラブルシューティング ガイドを参照してください。
- YAML リファレンスを参照してください。