チュートリアル: サンプルの Jupyter Notebook を使用して画像分類モデルをトレーニングおよびデプロイする
適用対象:  Python SDK azureml v1
Python SDK azureml v1
このチュートリアルでは、機械学習モデルのトレーニングをリモートのコンピューティング リソース上で行います。 Python Jupyter Notebook 内の Azure Machine Learning に関するトレーニングとデプロイのワークフローを使用します。 それからノートブックをテンプレートとして使用し、独自のデータで独自の機械学習モデルをトレーニングできます。
このチュートリアルでは、Azure Machine Learning で MNIST データセットや scikit-learn を使用して、単純なロジスティック回帰をトレーニングします。 MNIST は、70,000 ものグレースケールのイメージから成る、人気のあるデータセットです。 各イメージは、0 から 9 までの数値を表す 28 x 28 ピクセルの手書き数字です。 多クラス分類子を作成して、特定のイメージが表す数字を識別することが目標です。
次の操作の実行方法を確認してください。
- データセットをダウンロードしてデータを確認する。
- MLflow を使用して、画像分類モデルをトレーニングし、メトリックをログに記録する。
- モデルをデプロイして、リアルタイム推論を行う。
前提条件
- Azure Machine Learning の利用開始に関するクイックスタートで次の作業を完了します。
- ワークスペースを作成します。
- 開発環境に使用するクラウドベースのコンピューティング インスタンスを作成します。
ワークスペースからノートブックを実行する
Azure Machine Learning では、インストール不要であらかじめ構成されたエクスペリエンスを実現するために、お使いのワークスペースにクラウド ノートブック サーバーが含まれています。 お使いの環境、パッケージ、および依存関係を制御したい場合は、独自の環境を使用してください。
ノートブック フォルダーを複製する
次の実験の設定を完了し、Azure Machine Learning スタジオで手順を実行します。 この統合インターフェイスには、あらゆるスキル レベルのデータ サイエンス実務者がデータ サイエンス シナリオを実行するための機械学習ツールが含まれています。
Azure Machine Learning Studio にサインインします。
お使いのサブスクリプションと、作成したワークスペースを選択します。
左側で [ノートブック] を選択します。
上部で [サンプル] タブを選択します。
SDK v1 フォルダーを開きます。
tutorials フォルダーの右側にある [...] ボタンを選択し、 [Clone](複製) を選択します。
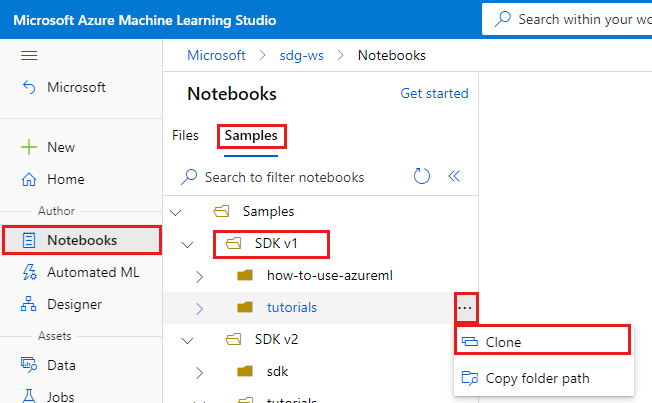
フォルダーの一覧には、ワークスペースにアクセスする各ユーザーが表示されます。 自分のフォルダーを選択して tutorials フォルダーをそこに複製します。
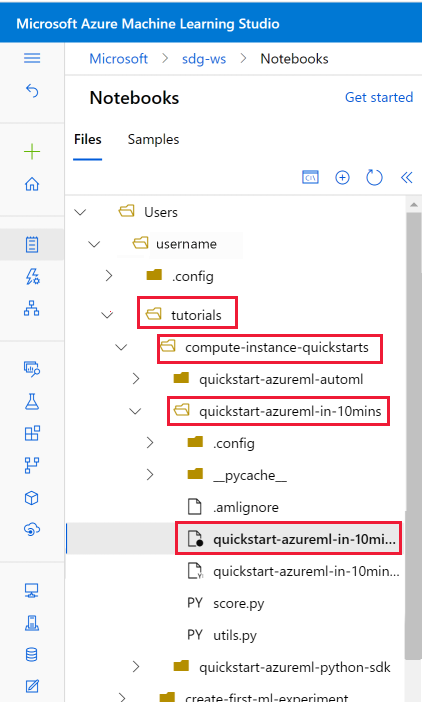
複製されたノートブックを開く
[User files](ユーザー ファイル) セクションに複製された tutorials フォルダーを開きます。
tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins フォルダーから quickstart-azureml-in-10mins.ipynb ファイルを選択します。
パッケージをインストールする
コンピューティング インスタンスが実行され、カーネルが表示されたら、このチュートリアルに必要なパッケージをインストールする新しいコード セルを追加します。
ノートブックの上部に、コード セルを追加します。
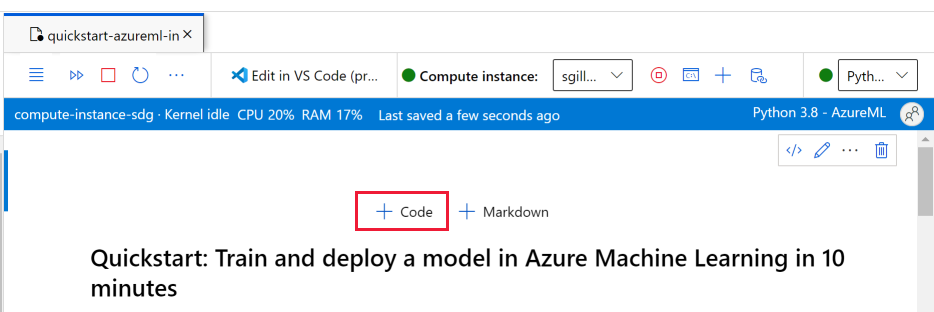
以下をセルに追加し、実行ツールまたは Shift + Enter キーのいずれかを使用して、そのセルを実行します。
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
インストールに関するいくつかの警告が表示される場合があります。 このエラーは無視してかまいません。
ノートブックを実行する
チュートリアルと付随する utils.py ファイルは、独自のローカル環境で使用する場合、GitHub から入手することもできます。 コンピューティング インスタンスを使用していない場合は、上記のインストールに %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib を追加します。
重要
以降この記事には、ノートブックと同じ内容が記載されています。
読みながらコードを実行したい方は、ここで Jupyter Notebook に切り替えてください。 ノートブックで単一のコード セルを実行するには、そのコード セルをクリックして Shift + Enter キーを押します。 または、上部のツール バーから [すべて実行] を選択して、ノートブック全体を実行します。
データのインポート
モデルのトレーニングの前に、トレーニングに使用するデータを理解する必要があります。 このセクションでは、次のことを行う方法について説明します。
- MNIST データセットのダウンロード
- 複数のサンプル イメージの表示
Azure Open Datasets を使用して、未加工の MNIST データ ファイルを取得します。 Azure Open Datasets は選別されたパブリック データセットであり、機械学習ソリューションにシナリオ固有の機能を追加してより良いモデルにするために使用できます。 各データセットには、異なる方法でデータを取得するための対応するクラスがあります (ここでは MNIST)。
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
データを確認する
圧縮されたファイルを numpy 配列内に読み込みます。 それから matplotlib を使用して、ラベルがあるデータセットから 30 個のランダムなイメージをプロットします。
この手順には、utils.py ファイルに含まれている load_data 関数が必要になることにご注意ください。 このファイルをこのノートブックと同じフォルダーに配置します。 load_data 関数は、圧縮ファイルを numpy 配列に解析するだけのものです。
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
このコードでは、次のようなラベルを持つ画像のランダムなセットが表示されます。

MLflow を使用してモデルをトレーニングしてメトリックをログに記録する
次のコードを使用してモデルをトレーニングします。 このコードでは、MLflow の自動ログ記録を使用して、メトリックを追跡し、モデルの成果物をログに記録します。
SciKit Learn フレームワークの LogisticRegression 分類子を使用して、データを分類します。
Note
モデルのトレーニングが完了するまでに約 2 分かかります。
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
実験を表示する
Azure Machine Learning スタジオの左側のメニューで、[ジョブ] を選択し、ジョブ (azure-ml-in10-mins-tutorial) を選択します。 ジョブは、指定されたスクリプトやコードから多数の実行をグループ化したものです。 複数のジョブを実験としてグループ化できます。
実行に関する情報は、そのジョブに格納されます。 ジョブを送信するときに名前が存在しない場合は、実行を選択すると、メトリック、ログ、説明などを含むさまざまなタブが表示されます。
モデル レジストリを使用してモデルをバージョン管理する
モデルの登録を使用すると、ワークスペース内にモデルを格納して、バージョンを管理できます。 登録されたモデルは、名前とバージョンによって識別されます。 モデルを登録するたびに、既存のモデルと同じ名前で登録され、レジストリによってバージョンがインクリメントされます。 次のコードでは、上記でトレーニングしたモデルを登録してバージョン管理します。 次のコード セルを実行したら、Azure Machine Learning スタジオの左側のメニューで [モデル] を選択すると、レジストリ内のモデルが表示されます。
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
リアルタイム推論のためにモデルをデプロイする
このセクションでは、アプリケーションで REST を介してモデルを使用 (推論) できるように、モデルをデプロイする方法について説明します。
デプロイ構成を作成する
このコード セルでは、モデルをホストするために必要なすべての依存関係 (scikit-learn のようなパッケージなど) を指定する "キュレーションされた環境" を取得します。 また、モデルをホストするために必要なコンピューティングの量を指定する "デプロイ構成" を作成します。 この場合、コンピューティングには 1 つの CPU と 1 GB のメモリが与えられます。
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
モデルのデプロイ
次のコード セルでは、モデルを Azure Container Instance にデプロイします。
Note
デプロイが完了するまでに約 3 分かかります。 ただし、使用できるようになるまで、おそらく 15 分ほどかかる場合があります。**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
前述のコードで参照されているスコアリング スクリプト ファイルは、このノートブックと同じフォルダーにあり、次の 2 つの関数が含まれています。
- サービスの開始時に 1 回実行される
init関数。この関数では、通常、レジストリからモデルを取得し、グローバル変数を設定します - サービスに対して呼び出しが行われるたびに実行される
run(data)関数。 この関数では、通常、入力データの書式を設定し、予測を実行して、予測結果を出力します。
エンドポイントを表示する
モデルが正常にデプロイされたら、Azure Machine Learning スタジオの左側のメニューで [エンドポイント] に移動して、エンドポイントを表示できます。 エンドポイントの状態 (正常または異常)、ログ、使用状況 (アプリケーションでモデルを使用する方法) が表示されます。
モデルのサービスをテストする
このモデルをテストするには、生の HTTP 要求を送信して Web サービスをテストします。
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
リソースをクリーンアップする
このモデルを引き続き使用しない場合は、次のコードを使用してモデル サービスを削除します。
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
さらにコストを制御する場合は、[コンピューティング] ドロップダウンの横にある [コンピューティングの停止] ボタンを選択して、コンピューティング インスタンスを停止します。 次回必要になったときは、再度コンピューティング インスタンスを起動します。
すべてを削除する
Azure Machine Learning ワークスペースとすべてのコンピューティング リソースを削除するには、次の手順を使用します。
重要
作成したリソースは、Azure Machine Learning に関連したその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
作成したどのリソースも今後使用する予定がない場合は、課金が発生しないように削除します。
Azure portal の検索ボックスに「リソース グループ」と入力し、それを結果から選択します。
一覧から、作成したリソース グループを選択します。
[概要] ページで、[リソース グループの削除] を選択します。
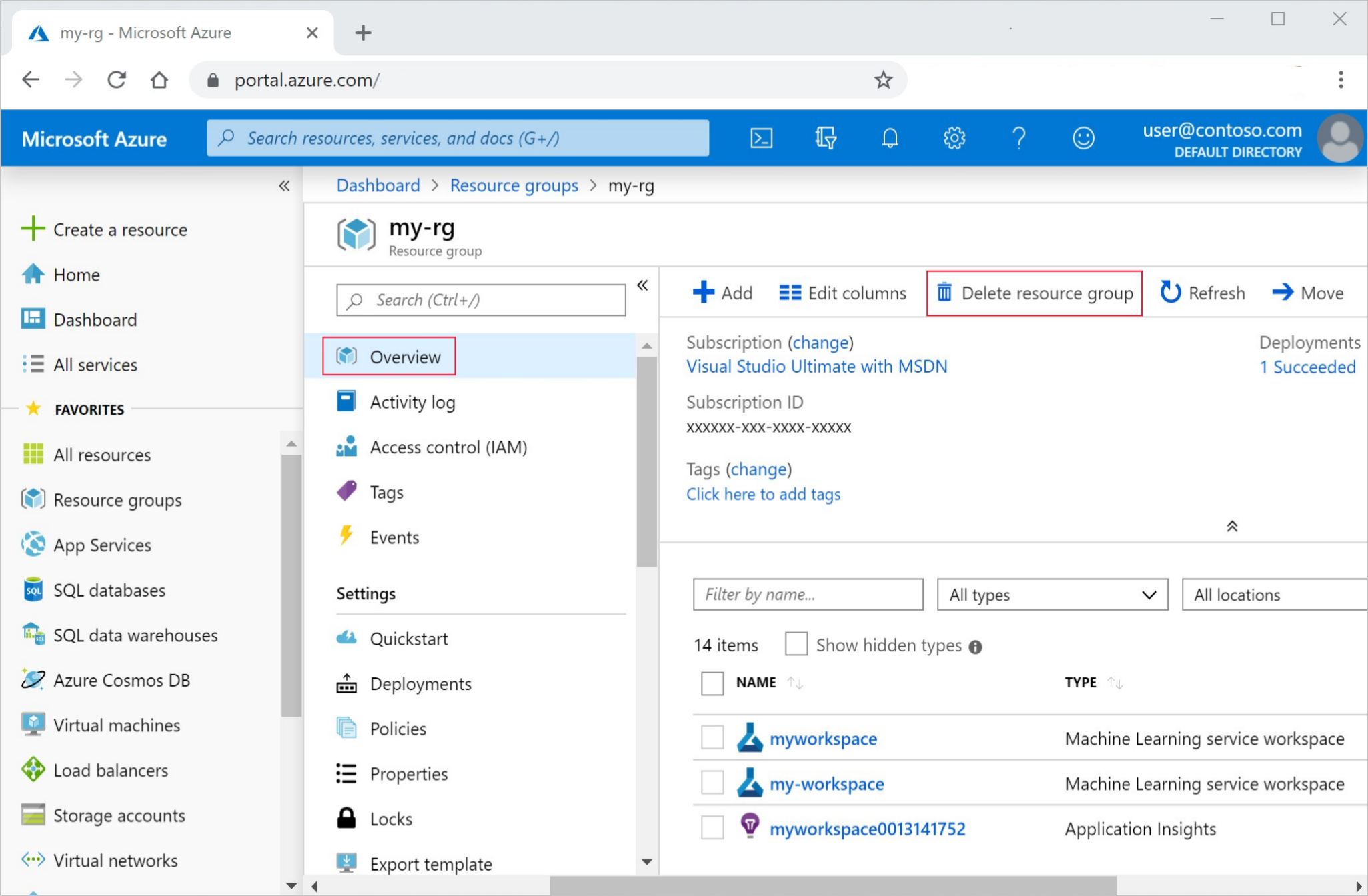
リソース グループ名を入力します。 次に、 [削除] を選択します。
関連リソース
- Azure Machine Learning のすべてのデプロイ オプションについて学習します。
- デプロイされたモデルに対して認証する方法について説明します。
- 大量のデータの予測を非同期的に行います。
- Application Insights を使用して Azure Machine Learning のモデルを監視します。