データ インジェスト パイプラインの DevOps
ほとんどのシナリオで、データ インジェスト ソリューションは、すべてのアクティビティを調整するスクリプト、サービス呼び出し、およびパイプラインを構成したものです。 この記事では、機械学習モデルのトレーニング用にデータを準備する一般的なデータ インジェスト パイプラインの開発ライフサイクルに DevOps プラクティスを適用する方法について説明します。 このパイプラインの構築には、次の Azure サービスを使用しています。
- Azure Data Factory: 生データを読み取り、データ準備を調整します。
- Azure Databricks:データを変換する Python ノートブックを実行します。
- Azure Pipelines:継続的インテグレーションと開発プロセスを自動化します。
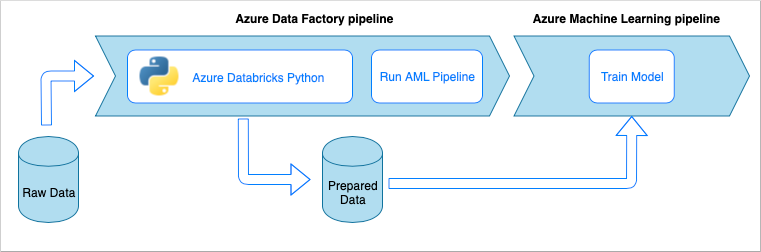
データ インジェスト パイプライン ワークフロー
データ インジェスト パイプラインでは、次のワークフローが実装されます。
- 生データが Azure Data Factory (ADF) パイプラインに読み込まれます。
- ADF パイプラインが Azure Databricks クラスターにデータを送信し、Python ノートブックが実行されてデータが変換されます。
- データが BLOB コンテナーに格納され、それを使用して Azure Machine Learning でモデルがトレーニングされます。
継続的インテグレーションとデリバリーの概要
多くのソフトウェア ソリューションと同様に、担当するチーム (たとえば、データ エンジニア) があります。 ここで Azure Data Factory、Azure Databricks、Azure Storage アカウントなどの同じ Azure リソースについて共同で作業し、共有しています。 こうしたリソースをまとめたものが開発環境です。 データ エンジニアは同じソース コード ベースを編集します。
継続的インテグレーションとデリバリー システムにより、ソリューションの構築、テスト、およびデリバリー (配置) のプロセスが自動化されます。 継続的インテグレーション (CI) プロセスでは、次のタスクが実行されます。
- コードをアセンブルする
- コード品質テストを使用してチェックする
- 単体テストを実行する
- テストされたコードや Azure Resource Manager テンプレートなどの成果物を生成する
継続的デリバリー (CD) プロセスでは、ダウンストリーム環境に成果物が配置されます。
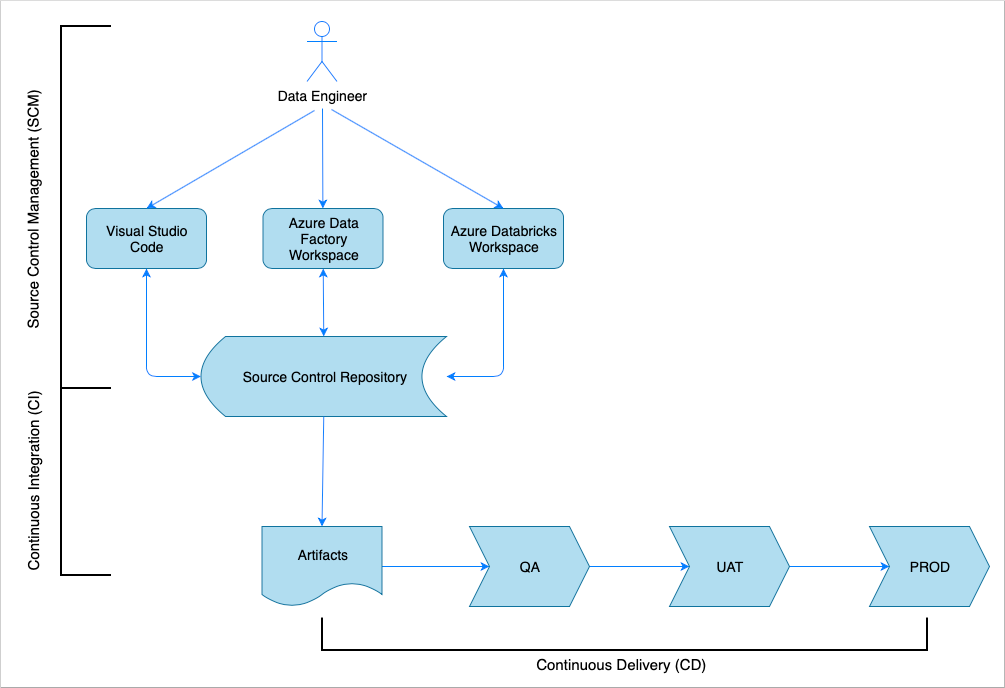
この記事では、Azure Pipelines で CI および CD プロセスを自動化する方法について説明します。
ソース コントロール管理
変更を追跡し、チーム メンバー間の共同作業を可能にするには、ソース コード管理が必要になります。 たとえば、Azure DevOps、GitHub、または GitLab リポジトリにコードを格納します。 コラボレーション ワークフローは、ブランチ モデルに基づいています。
Python ノートブックのソース コード
データ エンジニアは、IDE (たとえば、Visual Studio Code) 内のローカルで、または Databricks ワークスペースで、Python ノートブックのソース コードを編集します。 コードの変更が完了すると、ブランチ ポリシーに従ってリポジトリにマージされます。
ヒント
.ipynb Jupyter Notebook 形式ではなく .py ファイルでコードを格納することをお勧めします。 こうすることで、コードが読みやすくなり、CI プロセスでの自動コード品質チェックが可能になります。
Azure Data Factory ソース コード
Azure Data Factory パイプラインのソース コードは、Azure Data Factory ワークスペースによって生成された JSON ファイルのコレクションです。 通常、データ エンジニアは、ソース コード ファイルを直接使用するのではなく、Azure Data Factory ワークスペースでビジュアル デザイナーを使用します。
ソース コード管理リポジトリを使用するようにワークスペースを構成するには、「Azure Repos Git 統合を使用した作成」を参照してください。
継続的インテグレーション (CI)
継続的インテグレーション プロセスの最終的な目標は、ソース コードから共同チームの作業を収集し、ダウンストリーム環境への配置のために準備することです。 ソース コード管理と同様に、このプロセスは Python ノートブックと Azure Data Factory パイプラインとで異なります。
Python ノートブックの CI
Python ノートブックの CI プロセスでは、コラボレーション ブランチ (たとえば、master、develop) からコードを取得し、次のアクティビティを実行します。
- コードのリンティング
- 単体テスト
- コードを成果物として保存する
次のコード スニペットは、Azure DevOps yaml パイプラインでこれらの手順を実装する方法を示しています。
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
このパイプラインでは、Python コードの実行に flake8 を使用しています。 これを使って、ソース コードに定義されている単体テストを実行し、リンティングとテストの結果を発行して、Azure Pipelines 実行画面で使用できるようにします。
リンティングと単体テストが成功すると、パイプラインによってソース コードが成果物のリポジトリにコピーされ、以降の配置手順で使用されます。
Azure Data Factory の CI
Azure Data Factory パイプラインの CI プロセスは、データ インジェスト パイプラインのボトルネックになります。 継続的インテグレーションはありません。 Azure Data Factory の配置可能な成果物は、Azure Resource Manager テンプレートのコレクションです。 そのようなテンプレートを生成する唯一の方法は、Azure Data Factory ワークスペースの [発行] ボタンをクリックすることです。
- データ エンジニアによって、機能ブランチのソース コードがコラボレーション ブランチ (たとえば、master または develop) にマージされます。
- アクセス許可を持つ担当者が [発行] ボタンをクリックし、コラボレーション ブランチのソース コードから Azure Resource Manager テンプレートを生成します。
- ワークスペースによってパイプラインが検証され (リンティングと単体テストの時点と考えます)、Azure Resource Manager テンプレートが生成され (ビルドの時点と考えます)、生成されたテンプレートが同じコード リポジトリ内のテクニカル ブランチ adf_publish に保存されます (成果物の発行の時点と考えます)。 このブランチは、Azure Data Factory ワークスペースによって自動的に作成されます。
このプロセスの詳細については、「Azure Data Factory における継続的インテグレーションとデリバリー」を参照してください。
生成される Azure Resource Manager テンプレートが環境に依存しないようにすることが重要です。 つまり、環境によって異なる可能性があるすべての値をパラメーター化します。 Azure Data Factory は高機能なので、このような値の大部分をパラメーターとして公開することができます。 たとえば、次のテンプレートでは、Azure Machine Learning ワークスペースへの接続プロパティがパラメーターとして公開されています。
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
ただし、既定では Azure Data Factory ワークスペースで処理されないカスタム プロパティを公開することもできます。 この記事のシナリオでは、Azure Data Factory パイプラインから、データを処理する Python ノートブックが呼び出されます。 このノートブックでは、入力データ ファイルの名前をパラメーターとして受け取ります。
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
この名前は、Dev、QA、UAT、PROD の各環境で異なります。 複数のアクティビティがある複雑なパイプラインでは、いくつかのカスタム プロパティを使用できます。 1 つの場所でこれらのすべての値を収集し、パイプライン "変数" として定義することをお勧めします。
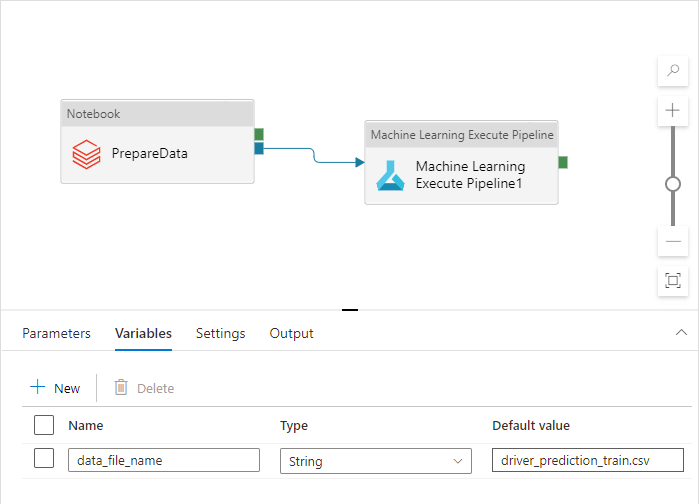
パイプライン アクティビティでは、実際に使用するときに、パイプライン変数を参照する場合があります。
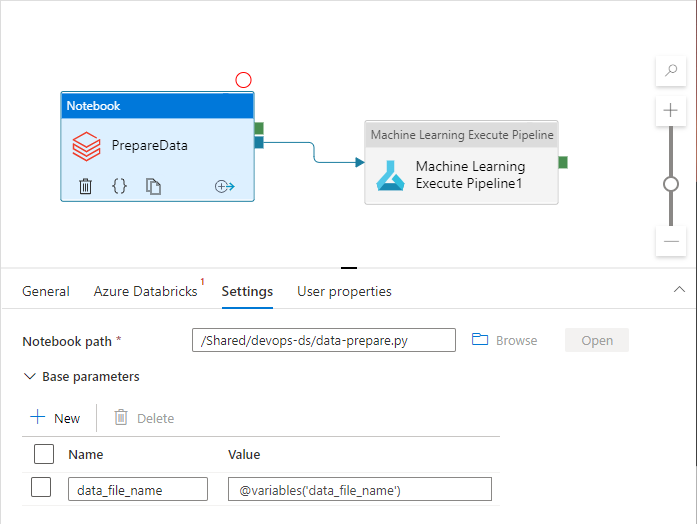
既定では、Azure Data Factory ワークスペースによって Azure Resource Manager テンプレート パラメーターとしてパイプライン変数が公開されることは "ありません"。 このワークスペースでは、Default Parameterization を使用して、Azure Resource Manager テンプレート パラメーターとして公開するパイプライン プロパティを指定します。 パイプライン変数を一覧に追加するには、既定のパラメーター化テンプレートの "Microsoft.DataFactory/factories/pipelines" セクションを次のスニペットで更新し、結果の JSON ファイルをソース フォルダーのルートに配置します。
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
これを行うと、[発行] ボタンがクリックされたときに、Azure Data Factory ワークスペースによってパラメーター一覧に変数が強制的に追加されます。
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
JSON ファイルの値は、パイプライン定義に構成されている既定値です。 Azure Resource Manager テンプレートの配置時に、ターゲット環境の値で上書きされることが想定されています。
継続的デリバリー (CD)
継続的デリバリー プロセスでは、成果物を受け取り、それを最初のターゲット環境に配置します。 ソリューションが機能することを確認するために、テストを実行します。 成功した場合は、次の環境に進みます。
CD Azure Pipelines は、環境を表す複数のステージで構成されています。 各ステージには、次の手順を実行する配置とジョブが含まれています。
- Python ノートブックを Azure Databricks ワークスペースに配置する
- Azure Data Factory パイプラインを配置する
- パイプラインを実行する
- データ インジェストの結果を確認する
パイプライン ステージは、承認とゲートを使用して構成できます。これにより、環境のチェーンの中で配置プロセスがどのように進化するかをさらに制御できます。
Python ノートブックを配置する
次のコード スニペットでは、Python ノートブックを Databricks クラスターにコピーする Azure パイプラインの配置を定義しています。
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
CI によって生成された成果物は自動的に配置エージェントにコピーされ、$(Pipeline.Workspace) フォルダーから利用できます。 この場合、配置タスクは、Python ノートブックを含む di-notebooks 成果物を参照します。 この配置では、Databricks Azure DevOps 拡張機能を使用してノートブック ファイルを Databricks ワークスペースにコピーします。
Deploy_to_QA ステージには、Azure DevOps プロジェクトで定義されている devops-ds-qa-vg 変数グループへの参照が含まれています。 このステージの手順では、この変数グループの変数を参照します (たとえば、$(DATABRICKS_URL) と $(DATABRICKS_TOKEN))。 次のステージ (たとえば、Deploy_to_UAT) は、独自の UAT スコープの変数グループに定義されているものと同じ変数名で動作するという考え方です。
Azure Data Factory パイプラインを配置する
Azure Data Factory の配置可能な成果物は、Azure Resource Manager テンプレートです。 次のスニペットに示すように、"Azure リソース グループのデプロイ" タスクと共にデプロイされます。
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
データ ファイル名パラメーターの値は、QA ステージ変数グループに定義されている $(DATA_FILE_NAME) 変数に由来します。 同様に、ARMTemplateForFactory.json で定義されているすべてのパラメーターはオーバーライドできます。 指定されていない場合は、既定値が使用されます。
パイプラインを実行し、データ インジェストの結果を確認する
次の手順では、配置したソリューションが動作していることを確認します。 次のジョブ定義では、PowerShell スクリプトを使って Azure Data Factory パイプラインを実行し、Azure Databricks クラスター上で Python ノートブックを実行します。 このノートブックでは、データが正しく取り込まれたかどうかが確認され、$(bin_FILE_NAME) という名前を持つ結果のデータ ファイルが検証されます。
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
ジョブの最後のタスクでは、ノートブックの実行結果を確認します。 エラーが返された場合は、パイプラインの実行状態が失敗に設定されます。
まとめ
CI/CD Azure パイプライン全体は、次のステージで構成されています。
- CI
- QA への配置
- Databricks への配置 + ADF への配置
- 統合テスト
お持ちのターゲット環境数と同数の "配置" ステージ数があります。 各 "配置" ステージには、並列で実行される 2 つのデプロイと、デプロイ後にその環境でソリューションをテストするために実行されるジョブが含まれています。
パイプラインのサンプル実装は、次の yaml スニペットにまとめられています。
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'