適用対象:  Azure Database for PostgreSQL - フレキシブル サーバー
Azure Database for PostgreSQL - フレキシブル サーバー
Azure Database for PostgreSQL フレキシブル サーバーでは、拡張機能を使用してデータベースの機能を拡張することができます。 拡張機能により、関連する複数の SQL オブジェクトを単一のパッケージにバンドルして、単一のコマンドで読み込みやデータベースからの削除を実行できます。 データベースに読み込まれると、拡張機能は組み込み機能と同じように機能します。
PostgreSQL 拡張機能の使用方法
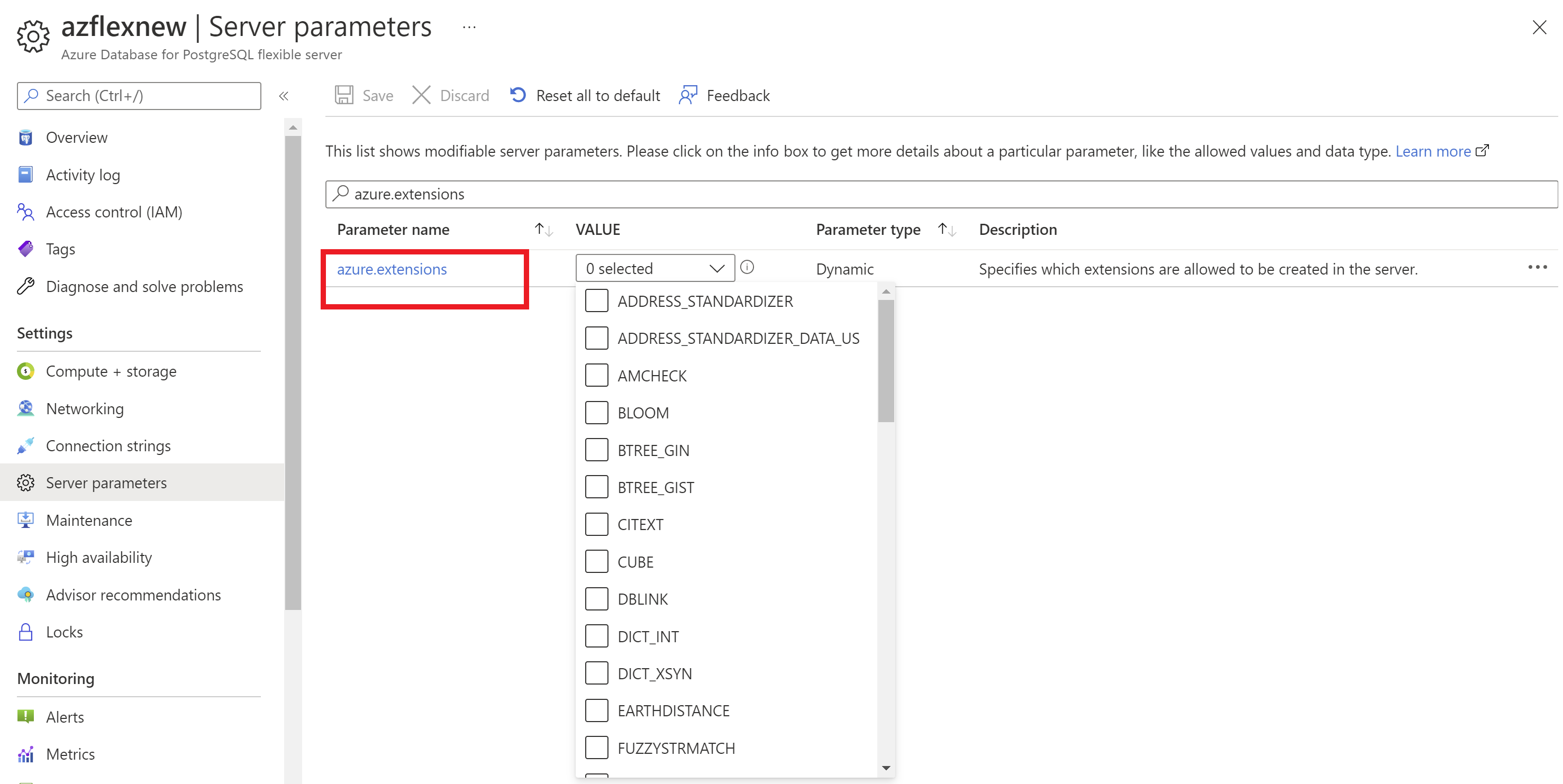
Azure Database for PostgreSQL フレキシブル サーバーに拡張機能をインストールする前に、それらの拡張機能を使用のための許可リストに載せる必要があります。
Azure portal を使用して以下を実行します。
- Azure Database for PostgreSQL フレキシブル サーバー インスタンスを選択します。
- リソース メニューの [設定] セクションで、[サーバー パラメーター] を選択します。
azure.extensionsパラメーターを検索します。- 許可リストに載せる拡張機能を選択します。

Azure CLI を使用:
CLI の parameter set コマンドを使用すると、拡張機能を許可リストに追加できます。
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name azure.extensions --value <extension_name>,<extension_name>
ARM テンプレートの使用: 次の例では、名前が postgres-test-server であるサーバー上の拡張機能 dblink、dict_xsyn、pg_buffercache を許可リストに載せます。
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"flexibleServers_name": {
"defaultValue": "postgres-test-server",
"type": "String"
},
"azure_extensions_set_value": {
"defaultValue": " dblink,dict_xsyn,pg_buffercache",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.DBforPostgreSQL/flexibleServers/configurations",
"apiVersion": "2021-06-01",
"name": "[concat(parameters('flexibleServers_name'), '/azure.extensions')]",
"properties": {
"value": "[parameters('azure_extensions_set_value')]",
"source": "user-override"
}
}
]
}
shared_preload_libraries は、Azure Database for PostgreSQL フレキシブル サーバーの起動時に読み込まれるライブラリを決定するサーバー構成パラメーターです。 共有メモリを使用するライブラリは、このパラメーターを使用して読み込む必要があります。 拡張機能を共有プリロード ライブラリに追加する必要がある場合は、次の手順に従います。
Azure portal を使用して以下を実行します。
- Azure Database for PostgreSQL フレキシブル サーバー インスタンスを選択します。
- リソース メニューの [設定] セクションで、[サーバー パラメーター] を選択します。
shared_preload_librariesパラメーターを検索します。- 追加するライブラリを選択します。
:::image type="content" source="./media/concepts-extensions/shared-libraries.png" alt-text="Screenshot showing Azure Database for PostgreSQL -setting shared preload libraries parameter setting for extensions installation." lightbox="./media/concepts-extensions/shared-libraries.png":::
```Using [Azure CLI](/cli/azure/):
You can set `shared_preload_libraries` via CLI [parameter set](/cli/azure/postgres/flexible-server/parameter?view=azure-cli-latest&preserve-view=true) command.
```azurecli
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name shared_preload_libraries --value <extension_name>,<extension_name>
拡張機能を作成する
拡張機能が許可リストに載せられて読み込まれたら、それらを使用する予定の各データベースにインストールする必要があります。
- 拡張機能を作成するには、ユーザーは
azure_pg_adminロールのメンバーである必要があります。azure_pg_adminロールのメンバーは、他のユーザーに拡張機能を作成する権限を付与できます。 - 特定の拡張機能をインストールするには、CREATE EXTENSION コマンドを実行する必要があります。 このコマンドで、パッケージ化されたオブジェクトがデータベースに読み込まれます。
Note
Azure Database for PostgreSQL フレキシブル サーバーで提供されるサード パーティ拡張機能は、オープン ソース ライセンスのコードです。 現時点では、プレミアムまたは独自のライセンス モデルを使用したサード パーティ拡張機能や拡張機能バージョンは Microsoft から提供されていません。
Azure Database for PostgreSQL フレキシブル サーバー インスタンスは、次の表に示す主要な PostgreSQL 拡張機能のサブセットをサポートしています。 この情報は、SHOW azure.extensions;を実行して確認することもできます。 このドキュメントに記載されていない拡張機能は、Azure Database for PostgreSQL フレキシブル サーバーではサポートされていません。 Azure Database for PostgreSQL フレキシブル サーバーでは、独自の拡張機能を作成したり読み込むことはできません。
拡張機能のバージョン
Azure Database for PostgreSQL フレキシブル サーバーでは、以下の拡張機能を利用できます。
Note
次の表の ✔️ マークが付いた拡張機能では、対応するライブラリが shared_preload_libraries サーバー パラメータで有効になっている必要があります。
| 拡張機能の名前 | 説明 | PostgreSQL 17 | PostgreSQL 16 | PostgreSQL 15 | PostgreSQL 14 | PostgreSQL 13 | PostgreSQL 12 | PostgreSQL 11 |
|---|---|---|---|---|---|---|---|---|
| address_standardizer | 構成要素へのアドレスの解析に使用されます。 通常、ジオコーディング アドレス正規化の手順をサポートするために使用されます。 | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| address_standardizer_data_us | Address Standardizer US データセットの例 | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| age (プレビュー) | グラフ データベース機能を提供する | 該当なし | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | 該当なし | 該当なし |
| amcheck | 関係の整合性を検証するための関数 | 1.4 | 1.3 | 1.3 | 1.3 | 1.2 | 1.2 | 1.1 |
| anon (プレビュー) | データ匿名化ツール | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ |
| azure_ai | PostgreSQL 用の Azure AI と ML サービスの統合 | 該当なし | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | 該当なし |
| azure_storage | PostgreSQL 用の Azure 統合 | 該当なし | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 該当なし |
| bloom | bloom アクセス メソッド - シグネチャ ファイルに基づくインデックス | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| btree_gin | GIN で一般的なデータ型のインデックス作成をサポートします | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| btree_gist | GiST で一般的なデータ型のインデックス作成をサポートします | 1.7 | 1.7 | 1.7 | 1.6 | 1.5 | 1.5 | 1.5 |
| citext | 大文字と小文字を区別しない文字列のデータ型 | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 |
| cube | 多次元キューブのデータ型 | 1.5 | 1.5 | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 |
| dblink | データベース内から他の PostgreSQL データベースに接続します | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| dict_int | 整数のテキスト検索辞書テンプレート | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| dict_xsyn | 拡張されたシノニム処理のためのテキスト検索ディクショナリのテンプレート | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| earthdistance | 地表面上の大圏距離を計算します | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| fuzzystrmatch | 文字列間の類似点と相違点を特定します | 1.2 | 1.2 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| hstore | (キー、値) ペアのセットを格納するためのデータ型 | 1.8 | 1.8 | 1.8 | 1.8 | 1.7 | 1.6 | 1.5 |
| hypopg | PostgreSQL の仮定のインデックス | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 |
| intagg | 整数のアグリゲーターと列挙子 (廃止) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| intarray | 整数の 1 次元配列に対する関数、演算子、インデックスのサポート | 1.5 | 1.5 | 1.5 | 1.5 | 1.3 | 1.2 | 1.2 |
| isn | 国際対応の製品番号規格のデータ型 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| lo | ラージ オブジェクトのメンテナンス | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| login_hook | Login_hook - ログイン時に login_hook.login() を実行するフック | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 |
| ltree | 階層ツリー状の構造体のデータ型 | 1.3 | 1.2 | 1.2 | 1.2 | 1.2 | 1.1 | 1.1 |
| oracle_fdw | Oracle データベースに対する外部データ ラッパー | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 該当なし |
| orafce | Oracle RDBMS の関数とパッケージのサブセットをエミュレートする関数と演算子 | 4.9 | 4.4. | 3.24 | 3.18 | 3.18 | 3.18 | 3.7 |
| pageinspect | 低レベルでデータベース ページの内容を検査します | 1.12 | 1.12 | 1.11 | 1.9 | 1.8 | 1.7 | 1.7 |
| pgaudit | 監査機能を提供します | 16.0 ✔️ | 16.0 ✔️ | 1.7 ✔️ | 1.6.2 ✔️ | 1.5 ✔️ | 1.4.3 ✔️ | 1.3.2 ✔️ |
| pg_buffercache | 共有バッファー キャッシュを確認します | 1.5 | 1.4 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_cron | PostgreSQL のジョブ スケジューラ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.4-1 ✔️ |
| pgcrypto | 暗号化関数 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_freespacemap | 空き領域マップ (FSM) を確認します | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_hint_plan | SQL コメントのいわゆるヒントを使って、PostgreSQL 実行プランを微調整できるようにします。 | 1.7.0 ✔️ | 1.6.0 ✔️ | 1.5 ✔️ | 1.4 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ |
| pglogical | PostgreSQL の論理レプリケーション | 2.4.5 ✔️ | 2.4.4 ✔️ | 2.4.2 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ |
| pg_partman | 時刻または ID によってパーティション テーブルを管理するための拡張機能 | 5.0.1 ✔️ | 5.0.1 ✔️ | 4.7.1 ✔️ | 4.6.1 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ |
| pg_prewarm | 関係データをプレウォームします | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ |
| pg_repack | 最小限のロックで PostgreSQL データベースのテーブルを再編成する | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 |
| pgrouting | PgRouting の拡張機能 | 該当なし | 該当なし | 3.5.0 | 3.3.0 | 3.3.0 | 3.3.0 | 3.3.0 |
| pgrowlocks | 行レベルのロック情報を表示します | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_squeeze | リレーションから未使用のスペースを削除するツール。 | 1.7 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ |
| pg_stat_statements | 実行されたすべての SQL ステートメントの実行統計情報を追跡します | 1.11 ✔️ | 1.10 ✔️ | 1.10 ✔️ | 1.9 ✔️ | 1.8 ✔️ | 1.7 ✔️ | 1.6 ✔️ |
| pgstattuple | タプルレベルの統計情報を表示します | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 |
| pg_trgm | trigram に基づくテキストの類似性の測定とインデックス検索 | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 | 1.4 | 1.4 |
| pg_visibility | 可視性マップ (VM) とページ レベルの可視性情報を調べます | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| plpgsql | PL/pgSQL 手続き型言語 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| plv8 | PL/JavaScript (v8) の信頼された手続き型言語 | 3.1.7 | 3.1.7 | 3.1.7 | 3.0.0 | 3.0.0 | 3.0.0 | 3.0.0 |
| postgis | PostGIS geometry および geography の空間型と関数 | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_raster | PostGIS ラスター型と関数 | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_sfcgal | PostGIS SFCGAL 関数 | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_tiger_geocoder | PostGIS Tiger ジオコーダとリバース ジオコーダ | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_topology | PostGIS トポロジの空間型と関数 | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgres_fdw | リモート PostgreSQL サーバー用の外部データ ラッパー | 1.1 | 1.1 | 1.1 | 1.1 | 1.0 | 1.0 | 1.0 |
| postgres_protobuf | PostgreSQL のプロトコル バッファー | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 該当なし |
| semver | セマンティック バージョンのデータ型 | 0.32.1 | 0.32.1 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 |
| session_variable | Session_variable - セッション変数および定数の登録と操作 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 |
| sslinfo | SSL 証明書に関する情報 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| tablefunc | クロス集計を含む、テーブル全体を操作する関数 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tds_fdw | TDS データベース (Sybase または Microsoft SQL Server) に対してクエリを実行するための外部データ ラッパー | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 |
| timescaledb | 時系列データに対するスケーラブルな挿入と複雑なクエリを可能にします | 該当なし | 2.13.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 1.7.4 ✔️ |
| tsm_system_rows | 行数を制限として受け取る TABLESAMPLE メソッド | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tsm_system_time | ミリ秒単位の時間を制限として受け取る TABLESAMPLE メソッド | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| unaccent | アクセントを削除するテキスト検索辞書 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| uuid-ossp | 汎用一意識別子 (UUID) を生成します | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| vector | ベクター データ型と ivfflat および hnsw アクセス機構 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.5.1 |
PostgreSQL 拡張機能をアップグレードする
データベース拡張機能のインプレース アップグレードは、単純なコマンドを使用して実行できます。 この機能により、お客様はサードパーティの拡張機能を最新バージョンに自動的に更新し、手動で作業せずに最新のセキュリティで保護されたシステムを維持できます。
拡張機能の更新
インストール済みの拡張機能を、Azure でサポートされている利用可能な最新バージョンに更新するには、次の SQL コマンドを使用します。
ALTER EXTENSION <extension_name> UPDATE;
このコマンドを使用すると、ユーザーが Azure で承認された最新バージョンに手動でアップグレードできるため、データベース拡張機能の管理が簡素化され、互換性とセキュリティの両方が強化されます。
制限事項
拡張機能の更新は簡単ですが、特定の制限があります。
- 特定のバージョンの選択: このコマンドは、拡張機能の中間バージョンへの更新をサポートしていません。 常に利用可能な最新バージョンに更新されます。
- ダウングレード: 拡張機能を以前のバージョンにダウングレードすることはできません。 ダウングレードが必要な場合は、サポートの支援が必要になる可能性があります。これは、以前のバージョンの可用性によって異なります。
インストールされている拡張機能
データベースに現在インストールされている拡張機能を一覧表示するには、次の SQL コマンドを使用します。
SELECT * FROM pg_extension;
使用可能な拡張機能とバージョン
現在のデータベース インストールで使用できる拡張機能のバージョンを確認するには、pg_available_extensions システム カタログ ビューにクエリを実行します。 たとえば、azure_ai 拡張機能で使用できるバージョンを確認するには、以下を実行します。
SELECT * FROM pg_available_extensions WHERE name = 'azure_ai';
これらのコマンドは、データベースの拡張機能構成に関する必要な分析情報を提供し、システムを効率的かつ安全に維持するのに役立ちます。 最新の拡張機能バージョンに簡単に更新できるようにすることで、Azure Database for PostgreSQL は、データベース アプリケーションの堅牢で安全で効率的な管理を引き続きサポートします。
Azure Database for PostgreSQL フレキシブル サーバーに固有の考慮事項
Azure Database for PostgreSQL フレキシブル サーバー サービスで使用する場合に特定の考慮事項を必要とする、サポートされている拡張機能の一覧を次に示します。 一覧はアルファベット順に並んでいます。
dblink
dblink を使用すると、1 つの Azure Database for PostgreSQL フレキシブル サーバー インスタンスから別のインスタンスに、または同一サーバー内の別のデータベースに接続することができます。 Azure Database for PostgreSQL フレキシブル サーバーは、任意の PostgreSQL サーバーとの受信接続と送信接続の両方をサポートします。 送信側サーバーでは、受信側サーバーへの送信接続を許可している必要があります。 同様に、受信側サーバーでは、送信側サーバーからの接続を許可している必要があります。
この拡張機能を使用する予定がある場合は、仮想ネットワーク統合でサーバーをデプロイすることをお勧めします。 既定では、仮想ネットワーク統合によって、仮想ネットワーク内のサーバー間の接続が可能になります。 仮想ネットワークのネットワーク セキュリティ グループを使用してアクセスをカスタマイズすることもできます。
pg_buffercache
pg_buffercache を使用して、shared_buffers の内容を調査できます。 この拡張機能を使用すると、特定の関係が (shared_buffers 内) にキャッシュされているかどうかを確認できます。 この拡張機能は、パフォーマンスの問題のトラブルシューティングに役立ちます (キャッシュ関連のパフォーマンスの問題)。
この拡張機能は PostgreSQL のコア インストールと統合されており、簡単にインストールできます。
CREATE EXTENSION pg_buffercache;
pg_cron
pg_cron は、PostgreSQL のための cron ベースの簡単なジョブ スケジューラであり、拡張機能としてデータベース内で実行されます。 PostgreSQL データベース内でメンテナンス作業を定期的に実行する目的で pg_cron 拡張機能を使用できます。 たとえば、テーブルを定期的に消去したり、古いデータ ジョブを削除したりできます。
pg_cron では、複数のジョブを並行して実行できますが、一度に実行できるジョブのインスタンスは 1 つだけです。 2 回目の実行が初回の完了前になった場合、2 回目の実行がキューに入り、初回実行の完了直後に開始されます。 このようにすることで、ジョブ実行が厳密に予定と同じ回数になり、同時に実行されることがありません。
次に例をいくつか示します。
土曜日午前 3:30 (GMT) に古いデータを削除する場合。
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
既定のデータベース postgres で毎日午前 10 時 (GMT) にバキュームを実行する場合。
SELECT cron.schedule('0 10 * * *', 'VACUUM');
pg_cron からの全タスクのスケジュールを解除する場合。
SELECT cron.unschedule(jobid) FROM cron.job;
pg_cron で現在スケジュールされているすべてのジョブを表示する場合。
SELECT * FROM cron.job;
毎日午前 10:00 (GMT) にデータベース 'testcron' で azure_pg_admin ロール アカウントの下でバキュームを実行する場合。
SELECT cron.schedule_in_database('VACUUM','0 10 * * * ','VACUUM','testcron',null,TRUE);
Note
pg_cron 拡張機能は、postgres データベース内のすべての Azure Database for PostgreSQL フレキシブル サーバーの shared_preload_libraries に事前に読み込まれているため、セキュリティを損なうことなく、Azure Database for PostgreSQL フレキシブル サーバー DB インスタンス内の他のデータベースでジョブの実行をスケジュールすることができます。 ただし、セキュリティ上の理由から、引き続き pg_cron 拡張機能を許可リストに載せ、CREATE EXTENSION コマンドを使用してインストールする必要があります。
ただし、pg_cron バージョン 1.4 以降では、cron.schedule_in_database および cron.alter_job 関数を使用して、それぞれ特定のデータベースでジョブをスケジュールし、既存のスケジュールを更新できます。
次に例をいくつか示します。
データベース DBName で土曜日午前 3:30 (GMT) に古いデータを削除する場合。
SELECT cron.schedule_in_database('JobName', '30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$,'DBName');
Note
cron_schedule_in_database 関数では、省略可能なパラメーターとしてユーザー名を使用できます。 ユーザー名を null 以外の値に設定するには PostgreSQL のスーパーユーザー権限が必要であり、これは Azure Database for PostgreSQL フレキシブル サーバーではサポートされていません。 上記の例で示したこの関数の実行では、オプションのユーザー名パラメーターを省略しているか null 値に設定しています。これによってジョブは、ジョブをスケジュールしているユーザーのコンテキストで実行され、このユーザーは azure_pg_admin ロールの特権を持っている必要があります。
既存のスケジュールのデータベース名を更新または変更するには
SELECT cron.alter_job(job_id:=MyJobID,database:='NewDBName');
pg_failover_slots
PG Failover Slots 拡張機能は、論理レプリケーションと高可用性が有効なサーバーの両方で運用している場合に、Azure Database for PostgreSQL フレキシブル サーバーを強化します。 これは、フェールオーバー後に、論理レプリケーション スロットを保持しない標準の PostgreSQL エンジン内の課題に効果的に対処します。 これらのスロットを維持することは、プライマリ サーバーの役割の変更中にレプリケーションの一時停止やデータの不一致を防止し、運用継続性とデータ整合性を確保するために重要です。
この拡張機能は、フェールオーバー プロセスを合理化するために必要な転送、クリーンアップ、およびレプリケーション スロットの同期を管理して、それによりサーバーの役割の変更時にシームレスな移行を提供します。 この拡張機能は、PostgreSQL バージョン 11 から 16 でサポートされます。
PG フェールオーバー スロット拡張機能の詳細と使用方法については、GitHub のページを参照してください。
pg_failover_slots を有効にする
Azure Database for PostgreSQL フレキシブル サーバー インスタンスの PG Failover Slots 拡張機能を有効にするには、サーバーの共有プリロード ライブラリに拡張機能を含めて、特定のサーバー パラメーターを調整することで、サーバーの構成を変更する必要があります。 そのプロセスを次に示します。
shared_preload_librariesパラメーターを更新して、サーバーの共有プリロード ライブラリにpg_failover_slotsを追加します。- サーバー パラメーター
hot_standby_feedbackをonに変更します。
shared_preload_libraries パラメーターの変更を有効にするには、サーバーの再起動が必要です。
Azure portal を使用して以下を実行します。
- Azure Database for PostgreSQL フレキシブル サーバー インスタンスを選択します。
- リソース メニューの [設定] セクションで、[サーバー パラメーター] を選択します。
shared_preload_librariesパラメーターを検索して、pg_failover_slotsを含むように値を編集します。hot_standby_feedbackパラメーターを検索して、その値をonに設定します。- [保存] を選択して、変更内容を保存します。 この時点で、[保存して再起動] のオプションが表示されます。
shared_preload_librariesを変更するにはサーバーの再起動が必要なため、これを選択して変更内容が有効になるようにします。
[保存して再起動] を選択すると、サーバーが自動的に再起動され、変更した内容が適用されます。 サーバーがオンラインに戻ると、PG Failover Slots 拡張機能が有効になって、プライマリの Azure Database for PostgreSQL フレキシブル サーバーで動作するようになり、フェールオーバー中の論理レプリケーション スロットを処理する準備が整います。
pg_hint_plan
pg_hint_plan は、SQL コメントでいわゆる "ヒント" を使って PostgreSQL 実行プランを微調整できるようにします。次はその例です。
/*+ SeqScan(a) */
pg_hint_plan は、ターゲット SQL ステートメントで指定された特別な形式のコメント内のヒント フレーズを読み取ります。 特別な形式は、文字シーケンス "/*+" で始まり、"*/" で終わります。 ヒント フレーズは、ヒント名と、それに続くかっこで囲まれスペースで区切られたパラメーターで構成されます。 それぞれのヒント フレーズは、改行で区切ると読みやすくなります。
例:
/*+
HashJoin(a b)
SeqScan(a)
*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts an ON b.bid = a.bid
ORDER BY a.aid;
先ほどの例では、プランナーは、テーブル a に対する seq scan の結果を、hash join としてテーブル b と組み合わせるために使用します。
pg_hint_plan をインストールするには、許可リストに載せることに加えて、「PostgreSQL 拡張機能の使用方法」に示したように、サーバーの共有プリロード ライブラリに含める必要もあります。 Postgres の shared_preload_libraries パラメーターへの変更を有効にするには、shared_preload_librariesが必要です。 Azure portal または Azure CLI を使用してパラメーターを変更できます。
Azure portal を使用して以下を実行します。
- Azure Database for PostgreSQL フレキシブル サーバー インスタンスを選択します。
- リソース メニューの [設定] セクションで、[サーバー パラメーター] を選択します。
shared_preload_librariesパラメーターを検索して、pg_hint_planを含むように値を編集します。- [保存] を選択して、変更内容を保存します。 この時点で、[保存して再起動] のオプションが表示されます。
shared_preload_librariesを変更するにはサーバーの再起動が必要なため、これを選択して変更内容が有効になるようにします。 これで Azure Database for PostgreSQL フレキシブル サーバー データベースで pg_hint_plan を有効にできるようになりました。 データベースに接続して、以下のコマンドを実行します。
CREATE EXTENSION pg_hint_plan;
pg_prewarm
pg_prewarm 拡張機能により、リレーショナル データがキャッシュに読み込まれます。 キャッシュをプレウォームすると、再起動後に最初に実行したときのクエリの応答時間が向上します。 auto-prewarm 機能は現在、Azure Database for PostgreSQL フレキシブル サーバーでは利用できません。
pg_repack
この拡張機能を初めて使用しようとしたときに尋ねる一般的な質問は、pg_repack は拡張機能なのか、それとも psql や pg_dump などのクライアント側の実行可能ファイルなのか、というものです。
それに対する答えは、実際には両方であるということです。 pg_repack/lib は拡張機能のコードを保持します。これには、拡張機能によって作成されるスキーマおよび SQL 成果物と、それらの複数の関数のコードを実装する C ライブラリが含まれます。 一方、pg_repack/bin にはクライアント アプリケーションのコードが保持されています。このコードは、拡張機能によって作成されたプログラミング成果物と対話する方法を認識します。 このクライアント アプリケーションは、ユーザーにわかりやすいコマンド ライン オプションを提供することで、サーバー側拡張機能によって表示されるさまざまなインターフェイスとの対話の複雑さを軽減することを目的としています。 ポイントされているデータベースに拡張機能が作成されていないクライアント アプリケーションは、有用ではありません。 サーバー側拡張機能はそれ自体で完全に機能しますが、拡張機能によって実装された関数への入力として使用されるデータを取得するためのクエリの実行からなる複雑な対話パターンをユーザーが理解する必要があります。
スキーマ再パックのアクセス許可が拒否される
現時点では、この拡張機能によって作成されたスキーマを再パックするアクセス許可を付与する方法が原因で、azure_pg_admin のコンテキストから pg_repack 機能を実行することのみがサポートされています。
azure_pg_admin でないテーブルの所有者が pg_repack を実行しようとすると、次のようなエラーが表示されることがあります。
NOTICE: Setting up workers.conns
ERROR: pg_repack failed with error: ERROR: permission denied for schema repack
LINE 1: select repack.version(), repack.version_sql()
このエラーを回避するには、azure_pg_admin のコンテキストから pg_repack を実行してください。
pg_stat_statements
pg_stat_statements 拡張機能を使用すると、データベースで実行されているすべてのクエリを表示できます。 これは、実稼働システムでのクエリ ワークロードのパフォーマンスがどのようになるかを理解するのに役立ちます。
pg_stat_statements 拡張機能は、すべての Azure Database for PostgreSQL フレキシブル サーバー インスタンスの shared_preload_libraries にプリロードされます。これにより、SQL ステートメントの実行統計情報を追跡する手段が提供されます。
ただし、セキュリティ上の理由から、pg_stat_statements 拡張機能を許可リストに載せ、CREATE EXTENSION コマンドを使用してインストールする必要があります。
ステートメントをコントロールする設定pg_stat_statements.trackは、拡張機能と既定値によってtopにカウントされ、クライアントが直接発行したすべてのステートメントがすべて追跡されます。 その他の 2 つの追跡レベルはnoneとallです。 この設定は、サーバー パラメーターとして構成できます。
各 SQL ステートメントをログに記録する時は pg_stat_statements が提供するクエリの実行情報とサーバーのパフォーマンスに与える影響にトレードオフがあります。 pg_stat_statements 拡張機能を使用していない場合、pg_stat_statements.track を none に設定することをお勧めします。 一部のサード パーティ監視サービスがクエリ パフォーマンスの分析情報を生成するために pg_stat_statements に依存することがあるため、そのようなケースに該当するかどうかを確認してください。
postgres_fdw
postgres_fdw を使用すると、1 つの Azure Database for PostgreSQL フレキシブル サーバー インスタンスから別のインスタンスに、または同一サーバー内の別のデータベースに接続することができます。 Azure Database for PostgreSQL フレキシブル サーバーは、任意の PostgreSQL サーバーとの受信接続と送信接続の両方をサポートします。 送信側サーバーでは、受信側サーバーへの送信接続を許可している必要があります。 同様に、受信側サーバーでは、送信側サーバーからの接続を許可している必要があります。
この拡張機能を使用する予定がある場合は、仮想ネットワーク統合でサーバーをデプロイすることをお勧めします。 既定では、仮想ネットワーク統合によって、仮想ネットワーク内のサーバー間の接続が可能になります。 仮想ネットワークのネットワーク セキュリティ グループを使用してアクセスをカスタマイズすることもできます。
pgstattuple
Postgres 11 から 13 のバージョンで 'pgstattuple' 拡張機能を使用して pg_toast スキーマに保持されているオブジェクトからタプル統計を取得しようとすると、"スキーマ pg_toast に対するアクセス許可が拒否されました" というエラーが表示されます。
スキーマ pg_toast へのアクセス許可が拒否されました
Azure Database for Flexible Server で PostgreSQL バージョン 11 から 13 を使用しているお客様は、pg_toast スキーマ内のオブジェクトに対して pgstattuple 拡張機能を使用できません。
PostgreSQL 16 および 17 では、pg_read_all_data ロールが自動的に azure_pg_admin に付与され、pgstattuple が正常に機能できるようになります。 PostgreSQL 14 および 15 では、同じ結果を得るために pg_read_all_data ロールを azure_pg_admin に手動で付与できます。 しかし、PostgreSQL 11 から 13 には、pg_read_all_data ロールは存在しません。
お客様は、必要なアクセス許可を直接付与することはできません。 pgstattuple を実行して pg_toast スキーマの下のオブジェクトにアクセスできるようにするには、「Azure サポート リクエストを作成する」に進んでください。
TimescaleDB
TimescaleDB は、PostgreSQL の拡張機能としてパッケージされた時系列データベースです。 TimescaleDB は、時間指向の分析関数、最適化を提供し、時系列ワークロードに合わせて PostgreSQL を拡大縮小します。 Timescale, Inc. の登録商標である TimescaleDB の詳細についてはこちらから確認してください。Azure Database for PostgreSQL フレキシブル サーバーは、TimescaleDB Apache-2 エディションを提供しています。
TimescaleDB のインストール
TimescaleDB をインストールするには、許可リストに追加することに加えて、前述したようにサーバーの共有プリロード ライブラリに含める必要もあります。 Postgres の shared_preload_libraries パラメーターへの変更を有効にするには、shared_preload_librariesが必要です。 Azure portal または Azure CLI を使用してパラメーターを変更できます。
Azure portal を使用して以下を実行します。
- Azure Database for PostgreSQL フレキシブル サーバー インスタンスを選択します。
- リソース メニューの [設定] セクションで、[サーバー パラメーター] を選択します。
shared_preload_librariesパラメーターを検索して、TimescaleDBを含むように値を編集します。- [保存] を選択して、変更内容を保存します。 この時点で、[保存して再起動] のオプションが表示されます。
shared_preload_librariesを変更するにはサーバーの再起動が必要なため、これを選択して変更内容が有効になるようにします。 これで Azure Database for PostgreSQL フレキシブル サーバー データベース内で TimescaleDB を有効にできるようになりました。 データベースに接続して、以下のコマンドを実行します。
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
ヒント
エラーが表示される場合は、shared_preload_libraries を保存した後にサーバーを再起動したことを確認します。
次に、一から TimescaleDB ハイパーテーブルを作成するか、PostgreSQL 内の既存の時系列データを移行することができます。
pg_dump と pg_restore を使用して Timescale データベースを復元する
pg_dump と pg_restore を使用して Timescale データベースを復元するには、次の2つのヘルパー プロシージャを復元先データベースで実行する必要があります:timescaledb_pre_restore() および timescaledb_post restore()。
まず、復元先データベースを指定します。
--create the new database where you want to perform the restore
CREATE DATABASE tutorial;
\c tutorial --connect to the database
CREATE EXTENSION timescaledb;
SELECT timescaledb_pre_restore();
これで、元のデータベースで pg_dump を実行し、pg_restore を実行することができます。 復元後、復元されたデータベースで、必ず次のコマンドを実行します:
SELECT timescaledb_post_restore();
Timescale が有効なデータベースの復元方法の詳細については、Timescale のドキュメントを参照してください。
timescaledb-backup を使用して Timescale データベースを復元する
上記の SELECT timescaledb_post_restore() プロシージャの実行中に、timescaledb.restoring フラグの更新でアクセス許可が拒否されるエラーが発生することがあります。 これは、Cloud PaaS データベース サービスの ALTER DATABASE 権限が限られているためです。 この場合は、timescaledb-backup ツールを使用して、タイムスケール データベースをバックアップおよび復元する別の方法を実行できます。 Timescaledb-backup は、TimescaleDB データベースをダンプおよび復元するためのプログラムであり、よりシンプルで、エラーが発生しにくく、よりパフォーマンスが向上します。
そのために、次の操作を実行する必要があります
- ツールをインストールする (詳細はこちら)
- ターゲットの Azure Database for PostgreSQL フレキシブル サーバー インスタンスとデータベースを作成する
- 上記のように、タイムスケール拡張機能を有効にする
azure_pg_adminロールを、ts-restore によって使用されるユーザーに付与する- ts-restore を実行してデータベースを復元する
これらのユーティリティの詳細については、こちらを参照してください。
拡張機能とメジャー バージョン アップグレード
Azure Database for PostgreSQL フレキシブル サーバーには、クリックするだけで Azure Database for PostgreSQL フレキシブル サーバーのインプレース アップグレードが実行される、インプレース メジャー バージョン アップグレード機能が導入されました。 インプレース メジャー バージョン アップグレードにより、Azure Database for PostgreSQL フレキシブル サーバーのアップグレード プロセスが簡素化され、サーバーにアクセスするユーザーとアプリケーションの中断が最小限に抑えられます。 メジャー バージョンのインプレース アップグレードでは、特定の拡張機能がサポートされません。また、一部の拡張機能のアップグレードには制限あります。 インプレース メジャー バージョン更新機能を使用する場合、拡張機能の anon、Apache AGE、dblink、orafce、pgaudit、postgres_fdw と Timescaledb は Azure Database for PostgreSQL フレキシブル サーバーのどのバージョンでもサポートされません。