チュートリアル: SynapseML と Azure AI Search を使用して Apache Spark からの大規模データのインデックスを作成する
この Azure AI Search チュートリアルでは、Spark クラスターから読み込まれた大規模データのインデックスを作成してクエリを実行する方法について説明します。 次のアクションを実行する Jupyter Notebook を設定します。
- Apache Spark セッションのデータ フレームにさまざまなフォーム (請求書) を読み込む
- それらを分析して特徴を特定する
- 結果の出力を組み立てて表形式のデータ構造にする
- Azure AI Search でホストされている検索インデックスに出力を書き込む
- 作成したコンテンツを探索してクエリを実行する
このチュートリアルは、ビッグ データに対する超並列機械学習をサポートするオープンソース ライブラリである SynapseML と依存関係があります。 SynapseML では、特殊なタスクを実行する "トランスフォーマー" を介して検索インデックスと機械学習が公開されます。 トランスフォーマーは、幅広い AI 機能を利用します。 この演習では、解析と AI エンリッチメントに AzureSearchWriter API を使用します。
Azure AI Search にはネイティブ AI エンリッチメントがありますが、このチュートリアルでは Azure AI Search の外部で AI 機能にアクセスする方法について説明します。 インデクサーやスキルの代わりに SynapseML を使用すると、それらのオブジェクトに関連付けられているデータ制限や他の制約を受けません。
ヒント
https://www.youtube.com/watch?v=iXnBLwp7f88 で、このデモの短いビデオをご覧ください。 このビデオでは、より多くの手順とビジュアルを使用して、このチュートリアルが展開されています。
前提条件
synapseml ライブラリといくつかの Azure リソースが必要です。 可能であれば、Azure リソースに同じサブスクリプションとリージョンを使用し、後で簡単にクリーンアップできるようにすべてを 1 つのリソース グループに配置します。 ポータル インストール用のリンクを次に示します。 サンプル データはパブリック サイトからインポートされます。
- SynapseML パッケージ 1
- Azure AI Search (任意のレベル) 2
- Azure AI サービス (任意のレベル) 3
- Azure Databricks (任意のレベル) 4
1 このリンクは、パッケージを読み込むためのチュートリアルに解決されます。
2 サンプル データのインデックス作成には無料検索レベルを使用できますが、データ ボリュームが大きい場合は、より高いレベルを選んでください。 課金対象レベルでは、後の「依存関係の設定」のステップで検索 API キーを指定する必要があります。
3 このチュートリアルでは、Azure AI Document Intelligence と Azure AI 翻訳を使用します。 以下の手順では、マルチサービス キーとリージョンを指定します。 同じキーが両方のサービスで機能します。
4 このチュートリアルでは、Azure Databricks が Spark コンピューティング プラットフォームを提供します。 ポータルの手順を使用してワークスペースを設定しました。
Note
上記のすべての Azure リソースでは、Microsoft ID プラットフォームのセキュリティ機能がサポートされています。 わかりやすくするために、このチュートリアルでは、各サービスのポータル ページからコピーされたエンドポイントとキーを使用する、キーベースの認証を想定しています。 このワークフローを運用環境で実装する場合、またはソリューションを他のユーザーと共有する場合は、ハードコーディングされたキーを統合セキュリティ キーまたは暗号化キーに置き換えることを忘れないでください。
手順 1: Spark クラスターとノートブックを作成する
このセクションでは、クラスターを作成し、synapseml ライブラリをインストールし、コードを実行するノートブックを作成します。
Azure portal で、自分の Azure Databricks ワークスペースを見つけ、[ワークスペースの起動] を選択します。
左側のメニューで、[計算する] を選択します。
[コンピューティングの作成] を選択します。
既定の構成を使用します。 クラスターの作成には数分かかります。
クラスターの作成後に
synapsemlライブラリをインストールします。クラスターのページの上部にあるタブから [ライブラリ] を選択します。
[新規インストール] を選択します。
[Maven] を選択します。
[座標] に「
com.microsoft.azure:synapseml_2.12:1.0.4」と入力します。[インストール] を選択します。
左側のメニューで、[作成]>[ノートブック] を選択します。
ノートブックに名前を付け、既定の言語として [Python] を選んで、
synapsemlライブラリーを持つクラスターを選びます。連続する 7 つのセルを作成します。 それぞれにコードを貼り付けます。
手順 2: 依存関係を設定する
次のコードをノートブックの最初のセルに貼り付けます。
プレースホルダーを各リソースのエンドポイントとアクセス キーに置き換えます。 新しい検索インデックスの名前を指定します。 その他の変更は必要ないため、準備ができたらコードを実行します。
このコードでは、複数のパッケージがインポートされ、このワークフローで使用される Azure リソースへのアクセスが設定されます。
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
手順 3: Spark にデータを読み込む
次のコードを 2 番目のセルに貼り付けます。 変更は必要ないため、準備ができたらコードを実行します。
このコードでは、Azure ストレージ アカウントからいくつかの外部ファイルが読み込まれます。 ファイルはさまざまな請求書であり、データ フレームに読み込まれます。
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
手順 4: Document Intelligence を追加する
次のコードを 3 番目のセルに貼り付けます。 変更は必要ないため、準備ができたらコードを実行します。
このコードでは、AnalyzeInvoices トランスフォーマー が読み込まれ、請求書を含むデータ フレームへの参照が渡されます。 Azure AI Document Intelligence の事前構築済み請求書モデルを呼び出して、請求書から情報を抽出します。
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
この手順の出力は、次のスクリーンショットのようになります。 フォーム分析が密な構造の 1 列に詰め込まれていることに注目してください。これでは操作が困難です。 次の変換では、この問題を解決するために、この列を複数の行と列に解析しています。
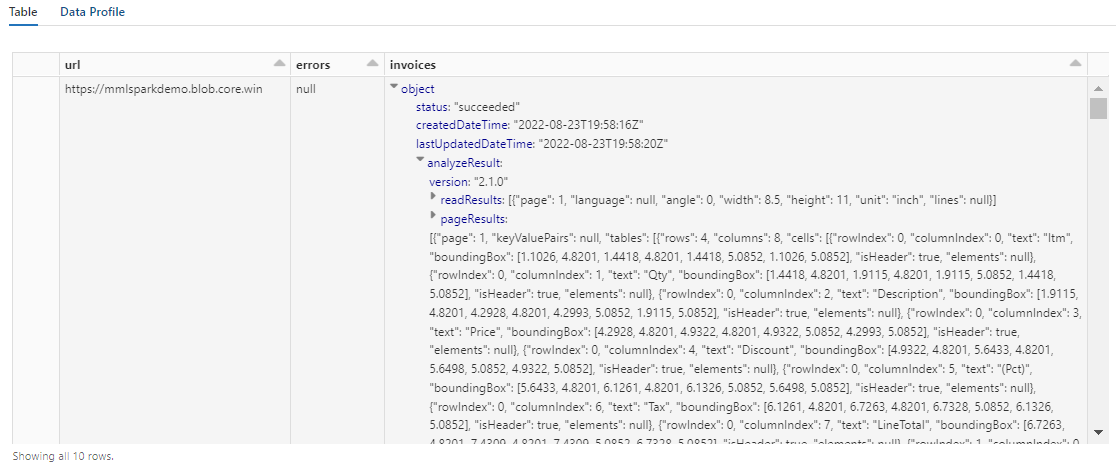
手順 5: Document Intelligence 出力を再構築する
次のコードを 4 番目のセルに貼り付けて実行します。 変更は必要ありません。
このコードでは、Document Intelligence トランスフォーマーの出力を分析し、表形式のデータ構造を推論するトランスフォーマーである FormOntologyLearner が読み込まれます。 AnalyzeInvoices の出力は動的であり、コンテンツで検出された機能によって異なります。 さらに、トランスフォーマーは出力を 1 つの列に統合します。 出力は動的で統合されているため、より多くの構造を必要とするダウンストリーム変換で使用するのは困難です。
FormOntologyLearner では、表形式のデータ構造を作成するために使用できるパターンを探すことによって、AnalyzeInvoices トランスフォーマーのユーティリティが拡張されます。 出力を複数の列と行に整理することで、AzureSearchWriter などの他のトランスフォーマーでコンテンツが使用できるようになります。
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
この変換により、入れ子になったフィールドが 1 つのテーブルに再キャストされることに注目してください。この結果、次の 2 つの変換が可能になります。 わかりやすくするために、このスクリーンショットはトリミングされています。 自分のノートブックでこの手順を実行している場合は、19 列と 26 行があります。
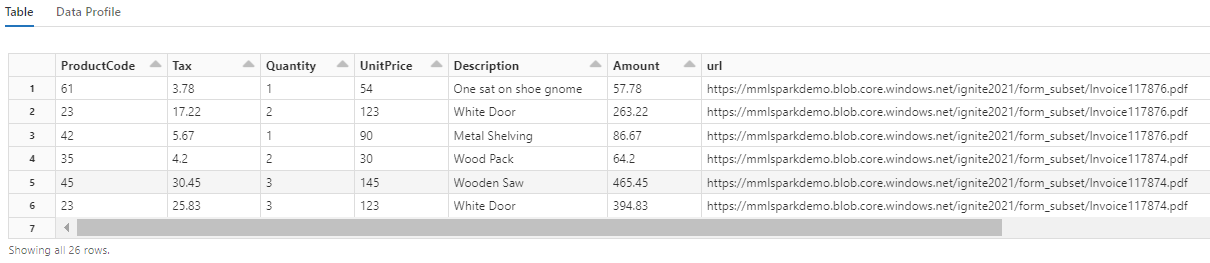
手順 6: 翻訳を追加する
次のコードを 5 番目のセルに貼り付けます。 変更は必要ないため、準備ができたらコードを実行します。
このコードでは、Azure AI サービスで Azure AI Translator サービスを呼び出すトランスフォーマーである Translate が読み込まれます。 英語では "Description" 列である元のテキストが、さまざまな言語に機械翻訳されます。 すべての出力が "output.translations" 配列に統合されます。
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
ヒント
翻訳された文字列を確認するには、行の末尾までスクロールします。
![[Translations] 列を示す表出力のスクリーンショット。](media/search-synapseml-cognitive-services/translated-strings.png)
手順 7: AzureSearchWriter を使って検索インデックスを追加する
次のコードを 6 番目のセルに貼り付けて実行します。 変更は必要ありません。
このコードでは、AzureSearchWriter が読み込まれます。 これにより、表形式データセットが使用され、列ごとに 1 つのフィールドを定義する検索インデックス スキーマが推論されます。 translations 構造体は配列であるため、各言語翻訳のサブフィールドを含む複合コレクションとしてインデックスに示されます。 生成されたインデックスにはドキュメント キーがあり、Create Index REST API を使用して作成されたフィールドの既定値が使用されます。
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Azure portal の検索サービス ページを確認すると、AzureSearchWriter で作成したインデックス定義を調べることができます。
注意
既定の検索インデックスを使用できない場合は、JSON で外部カスタム定義を指定し、その URI を "indexJson" プロパティの文字列として渡すことができます。 既定のインデックスを最初に生成して、指定するフィールドを把握し、その後、たとえば特定のアナライザーが必要な場合は、カスタマイズされたプロパティに従います。
手順 8: インデックスのクエリを実行する
次のコードを 7 番目のセルに貼り付けて実行します。 構文を変更する場合、または他の例を試してコンテンツをさらに調べる場合を除き、変更は必要ありません。
クエリを発行するトランスフォーマーまたはモジュールはありません。 このセルは、ドキュメントの検索 REST API の単純な呼び出しです。
この特定の例では、"door" という単語を検索します ("search": "door")。 また、一致するドキュメント数の "count" を返し、結果の "Description" と "Translations" フィールドのコンテンツのみを選びます。 フィールドの完全な一覧を表示する場合は、"select" パラメーターを削除します。
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
次のスクリーンショットは、サンプル スクリプトのセル出力を示しています。
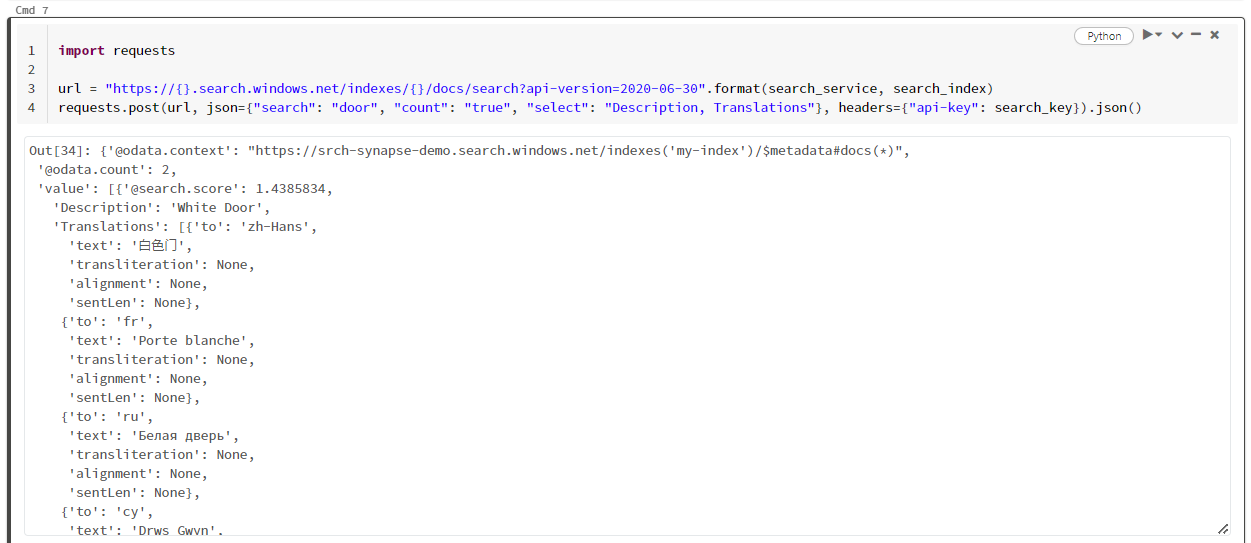
リソースをクリーンアップする
所有するサブスクリプションを使用している場合は、プロジェクトの終了時に、不要になったリソースを削除することをお勧めします。 リソースを実行したままにすると、お金がかかる場合があります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
ポータルの左側のナビゲーション ウィンドウにある [すべてのリソース] または [リソース グループ] リンクを使って、リソースを検索および管理できます。
次のステップ
このチュートリアルでは、SynapseML の AzureSearchWriter トランスフォーマーについて学習しました。これは、Azure AI Search で検索インデックスを作成して読み込むための新しい方法です。 トランスフォーマーでは、構造化された JSON が入力として受け取られます。 FormOntologyLearner によって、SynapseML の Document Intelligence トランスフォーマーによって生成される出力に必要な構造を提供できます。
次の手順として、Azure AI Search で探索する変換されたコンテンツを生成する他の SynapseML チュートリアルを確認します。