Azure AI Search でのベクトル検索ソリューション用の大きなドキュメントをチャンクする
大きなドキュメントをより小さなチャンクにパーティション分割すると、埋め込みモデルの最大トークン入力制限を超えないようにするのに役立つ場合があります。 たとえば、 Azure OpenAI 埋め込みモデルの入力テキストの最大長は 8,191 トークンです。 各トークンが一般的な OpenAI モデルのテキストの約 4 文字であることを考えると、この上限は約 6,000 語のテキストに相当します。 これらのモデルを使用して埋め込みを生成する場合は、入力テキストが制限を超えないようにすることが重要です。 コンテンツをチャンクにパーティション分割することで、ベクトル ストアの設定やテキストからベクトルへのクエリ変換に使用される埋め込みモデルで、お使いのデータを処理できるようになります。
この記事では、データのチャンク分割方法をいくつか取り上げて説明します。 チャンクは、ソース ドキュメントがモデルによって課される最大入力サイズに対して大きすぎる場合にのみ必要です。
Note
ベクトル検索の一般提供バージョンを使用している場合、データのチャンク分割と埋め込みには、ライブラリやカスタム スキルなどの外部コードが必要です。 垂直統合と呼ばれる現在プレビュー段階の新機能では、内部データのチャンク分割と埋め込みを提供しています。 垂直統合は、インデクサー、スキルセット、テキスト分割スキル、および AzureOpenAiEmbedding スキル (カスタム スキル) に依存します。 プレビュー機能を使用できない場合は、この記事の例で示されている別の方法で作業を進めることができます。
一般的なチャンク手法
最も広く使用されているメソッドから始まる、いくつかの一般的なチャンク手法を次に示します:
固定サイズのチャンク: 意味的に意味のある段落 (200 単語など) に十分な固定サイズを定義し、一部の重複 (コンテンツの 10 ~ 15% など) を許可すると、ベクター ジェネレーターを埋め込むための入力として適切なチャンクを生成できます。
コンテンツに基づく可変サイズのチャンク: 文末句読点、行末マーカー、自然言語処理 (NLP) ライブラリの機能の使用など、コンテンツフィーチャーに基づいてデータをパーティション分割します。 Markdown 言語構造を使用して、データを分割することもできます。
上記のいずれかの手法をカスタマイズまたは反復処理します。 たとえば、大きなドキュメントを扱う場合は、可変サイズのチャンクを使用しますが、コンテキストの損失を防ぐために、ドキュメントの中央からチャンクにドキュメント タイトルを追加することもできます。
コンテンツの重複に関する考慮事項
データをチャンクする場合、チャンク間で少量のテキストを重複させると、コンテキストを維持するのに役立ちます。 まず、約 10% の重複から始めるのをお勧めします。 たとえば、256 個のトークンの固定チャンク サイズを指定すると、25 個のトークンの重複でテストを開始します。 実際の重複の量は、データの種類と特定のユース ケースによって異なりますが、多くのシナリオで 10 ~ 15% が機能することがわかりました。
データチャンクの考慮すべき要素
データのチャンクに関しては、次の考慮すべき要素について考えてください:
ドキュメントの形状と密度。 そのままのテキストや通路が必要な場合は、文の構造を保持する大きなチャンクと変数チャンクを使用すると、より良い結果が得られる可能性があります。
ユーザー クエリ: チャンクが大きく、戦略が重複すると、特定の情報をターゲットとするクエリのコンテキストとセマンティックの豊かさを維持できます。
大規模言語モデル (LLM) には、チャンク サイズのパフォーマンス ガイドラインがあります。 使用しているすべてのモデルに最適に作用するチャンク サイズを設定する必要があります。 たとえば、要約と埋め込みにモデルを使用する場合は、両方に適したチャンク サイズを選択します。
チャンク化がワークフローにどのように適合するか
大きなドキュメントがある場合は、大きなテキストを分割するチャンク分割手順を、インデックス作成とクエリのワークフローに挿入する必要があります。 垂直統合 (プレビュー) を使用する場合は、テキスト分割スキルを使用した既定のチャンク分割戦略が適用されます。 カスタム スキルを使用して、カスタム チャンク分割戦略を適用することもできます。 チャンクを提供するライブラリには、次のようなものがあります:
ライブラリのほとんどに、固定サイズ、可変サイズ、または組み合わせの一般的なチャンク分割手法が用意されています。 また、コンテキストを保持するために、各チャンク内の少量のコンテンツを複製する重複を指定することもできます。
チャンク分割の例
次の例は、チャンク分割戦略が NASA の電子書籍『夜の地球』の PDF ファイルにどのように適用されるかを示しています。
テキスト分割スキルの例
テキスト分割スキル による統合データ チャンク分割は、パブリック プレビュー段階にあります。 このシナリオでは、プレビュー REST API または Azure SDK ベータ パッケージを使用します。
このセクションでは、スキル ドリブン アプローチとテキスト分割スキル パラメーターを使用した組み込みのデータ チャンク分割について説明します。
この例のサンプル ノートブックは、azure-search-vector-samples リポジトリにあります。
textSplitMode を設定して、コンテンツをより小さなチャンクに分割します。
pages(既定値)。 チャンクは複数の文で構成されます。sentencesチャンクは 1 つの文で構成されます。 どのようなものが "文" になるかは言語によって異なります。 英語の場合、標準的な文の終わりには.や!などのの句読点が使用されます。 言語はdefaultLanguageCodeパラメーターで制御されます。
pages パラメーターによって、追加のパラメーターが追加されます。
maximumPageLengthでは、各チャンクの最大文字数1 が定義されます。 テキスト スプリッターによって文が分割されないようになるため、実際の文字数はコンテンツによって異なります。pageOverlapLengthでは、前のページの末尾から次のページの先頭までの間に含まれる文字数が定義されます。 設定する場合、これは最大ページ長の半分以下にする必要があります。maximumPagesToTakeでは、ドキュメントから取得するページ/チャンク数が定義されます。 既定値は 0 です。この場合、ドキュメントからすべてのページまたはチャンクが取得されます。
1 文字とトークンの定義は一致しません。 LLM によって測定されるトークンの数は、テキスト分割スキルによって測定される文字サイズと異なる場合があります。
次の表は、パラメーターの選択が、電子書籍『夜の地球』の合計チャンク数にどのように影響するかを示しています。
textSplitMode |
maximumPageLength |
pageOverlapLength |
合計チャンク数 |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
該当なし | 該当なし | 13361 |
textSplitMode に pages を使用すると、チャンクの大部分の合計文字数が maximumPageLength に近くなります。 チャンクの文字数は、チャンク内で文の境界がどこにあるかの違いによって変わってきます。 チャンク トークンの長さは、チャンクのコンテンツの違いによって変わってきます。
次のヒストグラムは、電子書籍『夜の地球』で textSplitMode を pages、maximumPageLength を 2000、pageOverlapLength を 500 にした場合、gpt-35-turbo では、チャンクの文字長が、チャンクのトークン長と比較してどのように分布しているかを示しています。
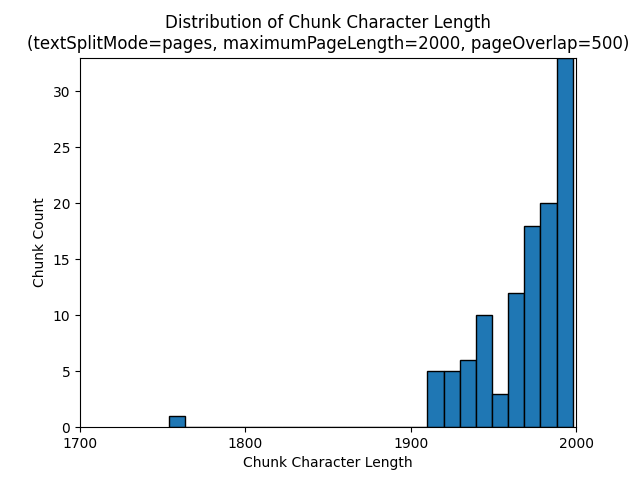
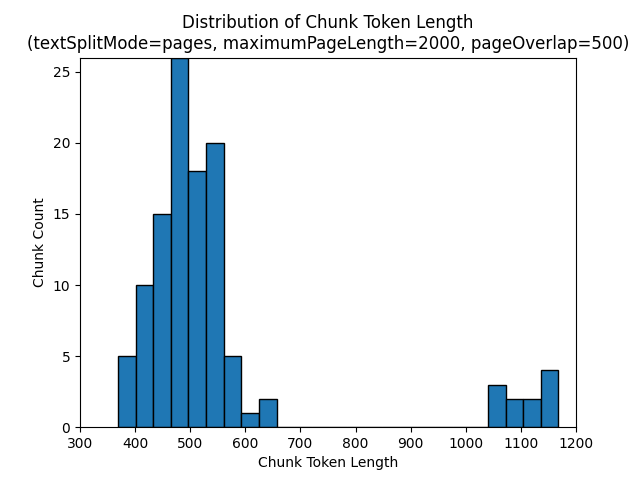
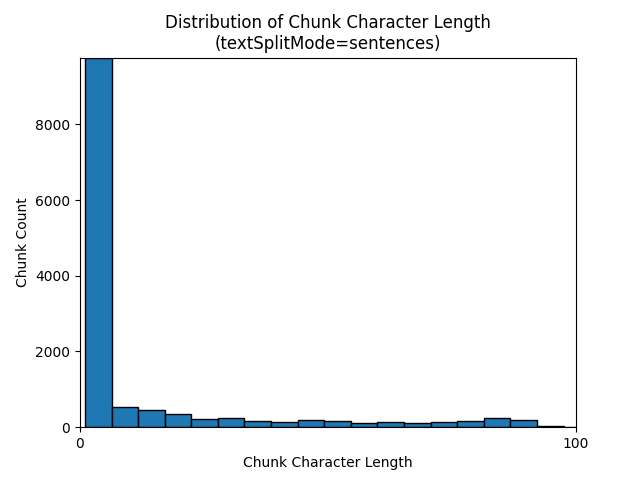
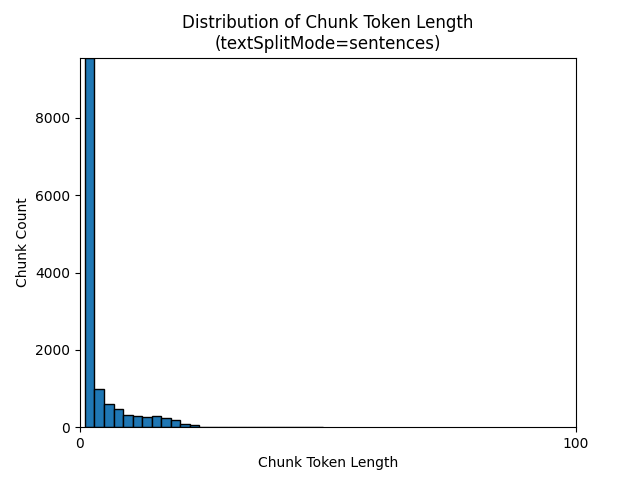
textSplitMode を sentences にすると、個別の文で構成されるチャンクが多数作成されます。 これらのチャンクは、pages で生成されるものよりもかなり小さく、チャンクのトークン数は文字数にさらに近いものになります。
次のヒストグラムは、電子書籍『夜の地球』で textSplitMode を sentences にした場合、gpt-35-turbo では、チャンクの文字長が、チャンクのトークン長と比較してどのように分布しているかを示しています。
パラメーターの最適な選択は、チャンクがどのように使用されるかによって異なります。 ほとんどのアプリケーションで、次の既定のパラメーターから開始することをお勧めします。
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
LangChain データ チャンク分割の例
LangChain には、ドキュメント ローダーとテキスト スプリッターが用意されています。 この例は、PDF を読み込み、トークン数を取得し、テキスト スプリッターを設定する方法を示しています。 トークン数を取得すると、チャンクのサイズ設定について、情報に基づいて判断することができます。
この例のサンプル ノートブックは、azure-search-vector-samples リポジトリにあります。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
出力は、PDF 内に 200 個のドキュメントまたはページがあることを示しています。
これらのページの推定トークン数を取得するには、TikToken を使用します。
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
出力は、トークンがゼロのページは存在しないこと、また、ページあたりの平均トークン長が 189 トークンで、ページの最大トークン数が 1,583 であることを示しています。
トークンの平均サイズと最大サイズを把握すると、チャンクのサイズ設定に関する分析情報を得られます。 500 文字を重複させて、標準のレコメンデーションである 2000 文字を使用することもできますが、この場合は、サンプル ドキュメントのトークン数を減らす方が理にかなっています。 実際、重複の値が大きすぎると、重複がまったく表示されない可能性があります。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
連続する 2 つのチャンクの出力は、最初のチャンクのテキストが 2 番目のチャンクに重なって表示されます。 出力は読みやすくするために軽く編集されています。
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
カスタム スキル
固定サイズのチャンクと埋め込み生成のサンプル では、 Azure OpenAI 埋め込みモデルを使用したチャンクとベクター埋め込みの生成の両方を示します。 このサンプルでは、Power Skills リポジトリの Azure AI Search カスタム スキルを使用して、チャンク分割手順をラップします。
関連項目
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示