Service Fabric Reliable Services のパーティション分割
この記事では、Azure Service Fabric Reliable Services のパーティション分割の基本概念について説明します。 パーティション分割により、ローカル コンピューターでデータ ストレージが有効にされるため、データとコンピューティングを一緒にスケーリングできます。
ヒント
この記事にあるコードの完全なサンプルは、GitHub で入手できます。
パーティション分割
パーティション分割は Service Fabric に固有のものではありません。 それは、スケーラブルなサービスの構築の中心的なパターンです。 パーティション分割とは、広義では状態 (データ) の分割に関する概念と考えることができます。計算してアクセスしやすい小さな単位に分割することで、スケーラビリティとパフォーマンスを改善できます。 よく知られているパーティション分割の形式として、シャーディングとも呼ばれるデータのパーティション分割があります。
Service Fabric ステートレス サービスのパーティション分割
ステートレス サービスの場合、パーティション分割は、1 つ以上のサービス インスタンスを含む論理単位と考えることができます。 図 1 は、1 つのパーティションを使用するクラスター全体に分散する 5 つのインスタンスがあるステートレス サービスです。
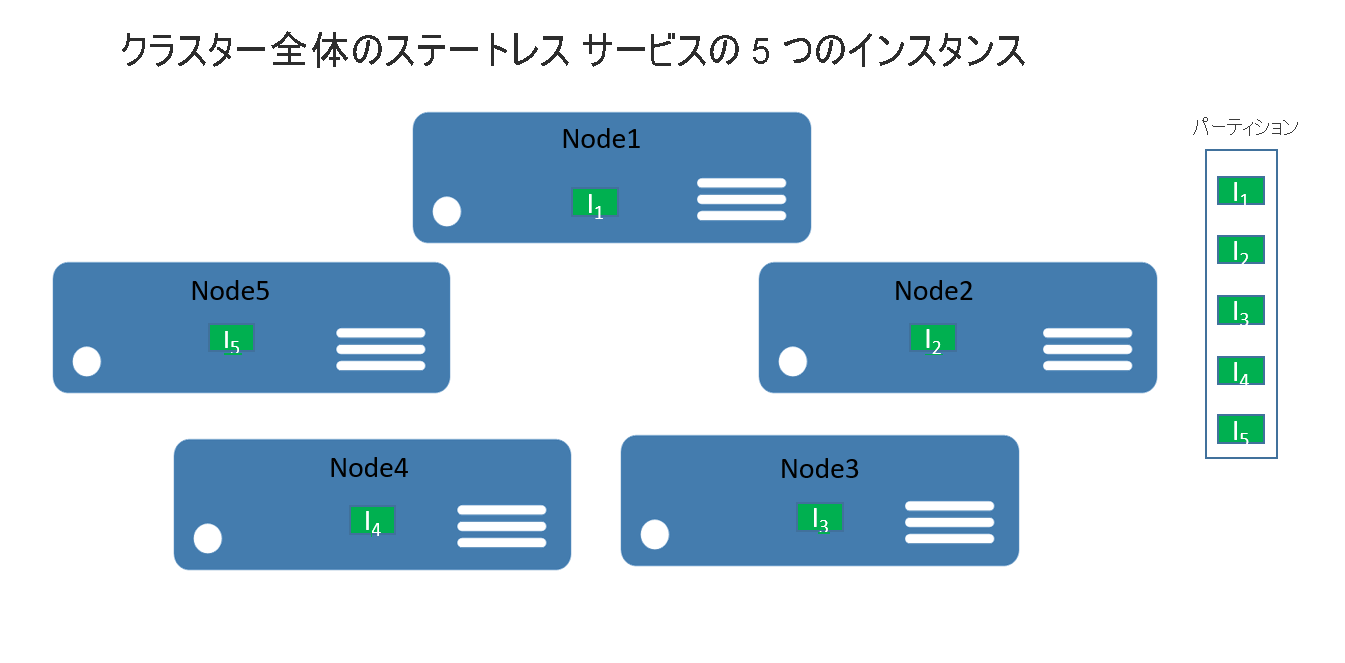
実際には、2 種類のステートレス サービス ソリューションがあります。 1 つ目は、Azure SQL Database のデータベースなどの、外部で状態を保持するサービスです (セッション情報とデータを格納する Web サイトのようなサービス)。 2 つ目は、永続的な状態を管理しない計算のみのサービスです (計算機や画像のサムネイル処理などのサービス)。
いずれの場合でも、ステートレス サービスのパーティション分割はほとんど見られないシナリオです。通常、スケーラビリティと可用性を向上するためには、インスタンスが追加されます。 ステートレス サービス インスタンスに複数のパーティション分割を検討するのは、特殊なルーティング要求を満たす必要がある場合に限られます。
たとえば、特定の範囲の ID を持つユーザーにのみ、特定のサービス インスタンスを提供する場合があります。 ステートレス サービスをパーティション分割するもう 1 つの例として、実際にパーティション分割されたバックエンド (SQL Database のシャード化されたデータベースなど) があり、そのデータベース シャードに書き込むことができるサービス インスタンスを制御したり、バックエンドと同じパーティション分割情報が必要なステートレス サービス内でその他の準備作業を実行したりする場合があります。 このようなシナリオの場合、さまざまな方法で解決することができるので、サービスをパーティション分割する必要はありません。
以降、このチュートリアルでは、ステートフル サービスを中心に説明します。
Service Fabric ステートフル サービスのパーティション分割
Service Fabric には状態 (データ) をパーティション分割する高度な機能があるので、スケーラブルなステートフル サービスを簡単に開発できます。 概念として、ステートフル サービスのパーティション分割は、クラスター内の複数のノードに分散され、バランスが保たれた レプリカ を使用する、信頼性が高いスケール ユニットと考えることができます。
Service Fabric ステートフル サービスのコンテキストでのパーティション分割とは、特定のサービス パーティションが、サービスの完全な状態の一部を担当することを判断するプロセスのことです。 (前述のように、パーティションとは一連の レプリカです)。 Service Fabric のメリットは、複数のノードにパーティションを配置することです。 これにより、パーティションをノードのリソース上限まで拡大できます。 データ ニーズの拡大に応じて、パーティションが拡大し、Service Fabric はノード間でパーティションのバランスを再調整します。 これにより、ハードウェア リソースが継続して効率的に使用されます。
たとえば、5 ノードのクラスターと、10 個のパーティションおよび 3 つのレプリカのターゲットで構成されたサービスから始めるとします。 この場合、Service Fabric はクラスター全体でレプリカのバランスを調整して分散します。最終的には、1 つのノードにつき 2 つのプライマリ レプリカになります。 ここで、クラスターを 10 ノードまでスケールアウトする必要がある場合、Service Fabric は、10 ノードすべてに分散するようにプライマリ レプリカのバランスを再調整します。 同様に 5 ノードに縮小する場合、Service Fabric は 5 ノードすべてに分散するようにバランスを再調整します。
図 2 は、クラスターのスケーリング前と後の 10 パーティションの分散を示しています。
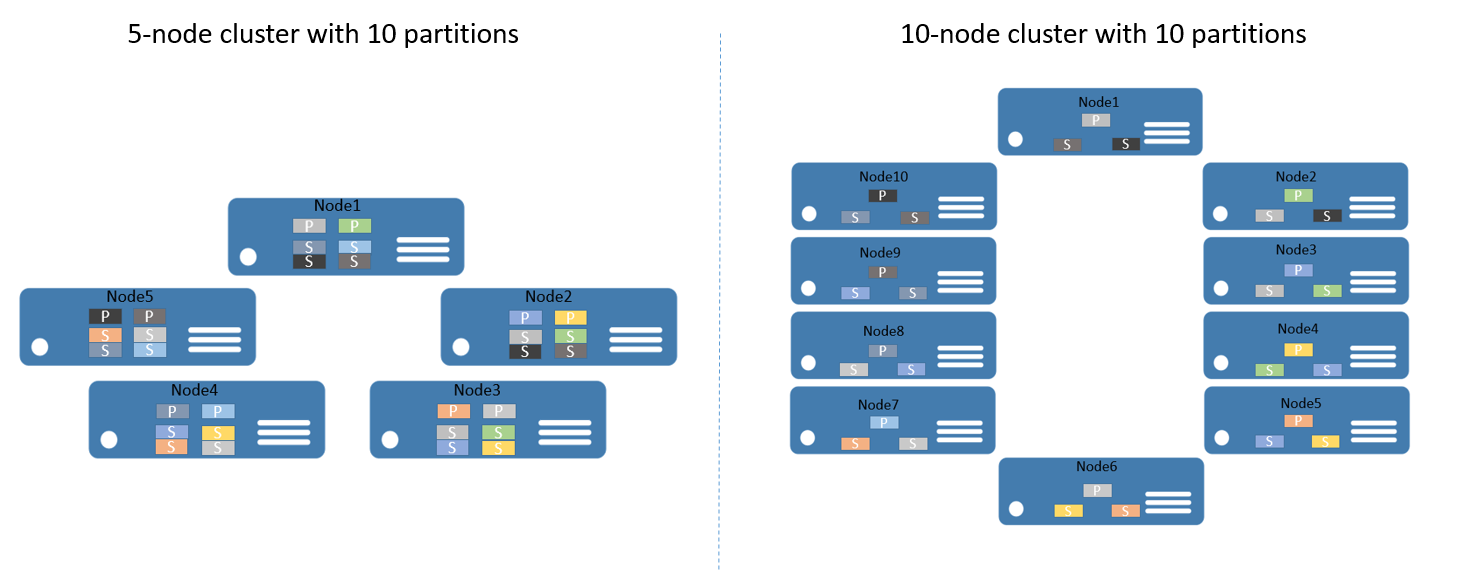
クライアントからの要求は複数のコンピューターに分散され、アプリケーションの全体的なパフォーマンスが改善され、データ チャンクへのアクセスの競合が軽減されるので、結果としてスケールアウトが達成されます。
パーティション分割の計画
サービスを実装する前に、スケールアウトに必要なパーティション分割戦略を考えておく必要があります。さまざまな方法がありますが、どの方法でも、アプリケーションで達成する必要があることを中心に考えます。 この記事では、重要度が高いいくつかの側面について検討してみましょう。
最初の手順として、パーティション分割する必要がある状態の構造について考えることをお勧めします。
簡単な例を見てみましょう。 郡全体の投票のサービスを構築する場合、郡の都市ごとにパーティションを作成できます。 次に、都市の各個人の投票をその都市に対応するパーティションに格納できます。 図 3 は、ユーザーと、ユーザーが住んでいる市町村のセットを示します。
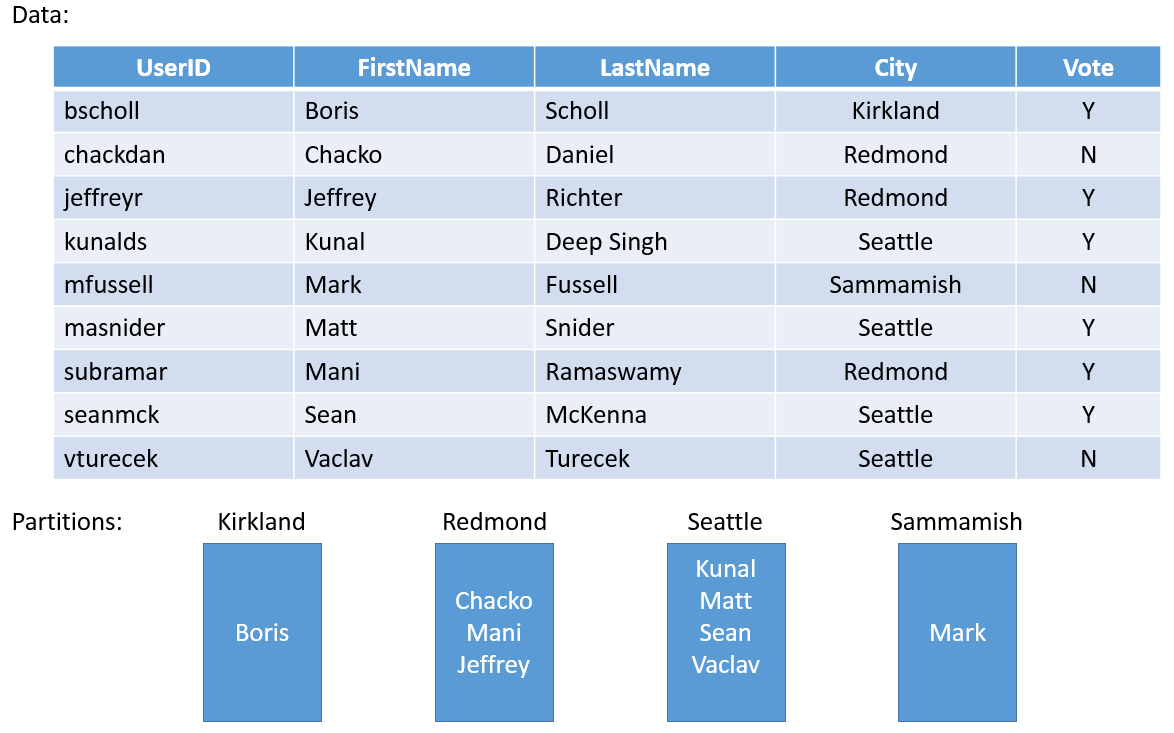
市町村の人口はさまざまなので、大量のデータを含むパーティション (シアトルなど) と、あまり状態がないパーティション (カークランドなど) ができあがります。 このように状態数が不均衡なパーティションがあると、どのような影響があるでしょうか。
この例について考えてみると、シアトルの投票を含むパーティションは、カークランドのパーティションよりもトラフィック数が多くなることはすぐにわかります。 既定で、Service Fabric は、各ノードに約同数のプライマリ レプリカとセカンダリ レプリカがあることを確認します。 そのため、ノードに多くのトラフィックを処理するレプリカと、少ないトラフィックを処理するレプリカが存在することになる可能性があります。 できれば、クラスター内にこのような落差ができないようにしたいところです。
この問題を回避するために、パーティション分割の点で次の 2 つの手順を実行する必要があります。
- すべてのパーティションに均等に分散されるように状態をパーティション分割します。
- サービスの各レプリカの負荷をレポートします。 (詳細については、メトリックスと負荷に関する記事を参照してください)。 Service Fabric には、メモリ量やレコード数など、サービスに使用される負荷をレポートする機能があります。 Service Fabric では、レポートされたメトリックに基づいて一部のパーティションが他のパーティションよりも負荷が高いことが検出され、レプリカをより適切なノードに移動してクラスターのバランスが再調整されます。そのため、全体としては過負荷になるノードはありません。
場合によっては、特定のパーティションのデータ量がどのくらいになるかわからないことがあります。 そのため、一般的な推奨として、まずパーティション全体に均等に分散するパーティション分割戦略を採用してから、負荷をレポートするという、両方の方法を実行してみてください。 1 つ目の方法で投票の例で説明されている状況を防ぎ、2 つ目の方法で長期間にわたるアクセスまたは負荷の一時的な差異を均等にすることができます。
パーティション分割計画のもう 1 つの側面は、正しいパーティション数から始めるということです。 Service Fabric では、シナリオで想定されるパーティション数よりも多い数から始めることができます。 実際のところ、パーティションの最大数を予想することは有効なアプローチです。
まれなケースではありますが、最初に選択した数よりも多いパーティションが必要になることもあります。 パーティション分割後にパーティション数を変更することはできないので、何らかの高度なパーティション アプローチ (同じサービス タイプの新しいサービス インスタンスを作成するなど) を適用する必要がある場合があります。 さらに、クライアント コードで保守する必要があるクライアント側情報に基づいて、正しいサービス インスタンスに要求をルーティングする何らかのクライアント側ロジックを実装する必要がある場合もあります。
パーティション分割計画のもう 1 つの考慮事項は、使用可能なコンピューター リソースです。 状態にアクセスし、状態を保存する必要があるので、次の制限が必要です。
- ネットワーク帯域幅の制限
- システム メモリの制限
- ディスク記憶域の制限
実行中のクラスターでリソースの上限に達した場合はどうなるでしょうか。 クラスターをスケールアウトするだけで、この新しい要件に対応できます。
容量計画ガイド では、クラスターに必要なノード数を決定する方法に関するガイダンスを説明しています。
パーティション分割の使用
ここでは、サービスをパーティション分割する基本的な方法について説明します。
Service Fabric には、3 つのパーティション スキーマが用意されています。
- 範囲パーティション分割 (UniformInt64Partition とも呼ばれます)。
- 名前付きパーティション分割。 通常、このモデルを使用するアプリケーションには、上限のあるセット内でバケット化可能なデータがあります。 名前付きパーティション分割キーとして使用されるデータ フィールドの一般的な例として、地域、郵便番号、顧客グループ、その他のビジネスの境界などがあります。
- 単一パーティション分割。 通常、単一パーティションは、サービスに追加のルーティングが必要ない場合に使用されます。 たとえば、ステートレス サービスは、既定でこのパーティション構成を使用します。
名前付きパーティション分割構成と単一パーティション分割構成は、範囲パーティションの特殊な形式です。 Service Fabric の Visual Studio テンプレートの既定では、最も一般的で便利な範囲パーティション分割が使用されています。 以降、この記事では、範囲パーティション分割構成を中心に説明します。
範囲パーティション分割構成
これは、整数の範囲 (最低値と最高値のキーで識別される) と、パーティションの数 (n) を指定するために使用されます。 全体のパーティション キー範囲内の重複しないサブ範囲を担当する n 個のパーティションを作成します。 たとえば、範囲パーティション分割構成で、最低値キー 0、最高値キー 99、数値 4 が指定されると、次に示すとおり 4 つのパーティションが作成されます。
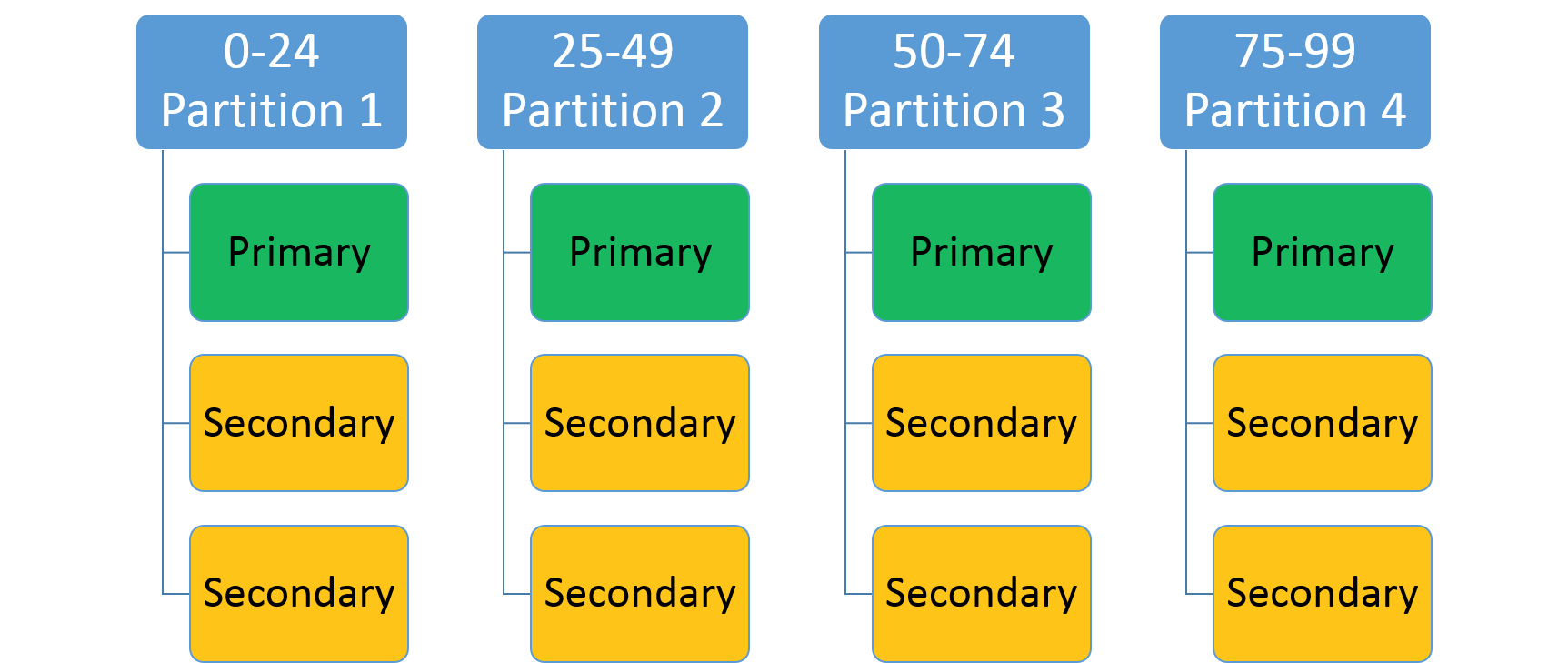
データセット内の一意のキーに基づいてハッシュを作成するのが一般的なアプローチです。 キーの一般的な例としては、車両識別番号 (VIN)、従業員 ID、または一意の文字列などがあります。 この一意キーを使用すると、キーの範囲を法とする剰余類により、キーとして使用できるハッシュ コードが生成されます。 許可されるキー範囲の上限と下限の境界を指定することができます。
ハッシュ アルゴリズムの選択
ハッシュで重要なのは、ハッシュ アルゴリズムの選択です。 類似するキーを近接してグループ化することが目標か (局所性鋭敏型ハッシュ)、またはアクティビティをパーティション全体に広範に分散することが必要か (分散ハッシュ) という点を検討します。
適切な分散ハッシュ アルゴリズムの特徴は、計算が簡単で、競合がほとんどなく、キーが均等に分散されることです。 効率的なハッシュ アルゴリズムのよい例として、 FNV-1 ハッシュ アルゴリズムがあります。
Wikipedia のハッシュ関数のページは、ハッシュ コードのアルゴリズム選択全般に関する優れたリソースです。
複数のパーティションがあるステートフル サービスの構築
まず、複数のパーティションがある信頼性の高いステートフル サービスを作成してみましょう。 この例では、同じパーティション内に同じアルファベットから始まる姓をすべて格納するという、ごく単純なアプリケーションを構築します。
コードを作成する前に、パーティションとパーティション キーについて考える必要があります。 アルファベットの各文字に 1 つ、合計 26 個のパーティションが必要ですが、最低値と最高値のキーはどうなるでしょうか。 文字どおり、1 文字につき 1 つのパーティションを作成し、各文字に独自のキーがあるので、最低値キーには 0、最高値キーには 25 を使用します。
Note
実際には分散は不均等なので、このシナリオは単純化しています。 文字 "S" または "M" から始まる姓は、"X" や "Y" から始まる姓よりも一般的です。
Visual Studio で、>[ファイル]>[新規作成]>[プロジェクト] の順に開きます。
[新しいプロジェクト] ダイアログ ボックスで、Service Fabric アプリケーションを選択します
プロジェクトに "AlphabetPartitions" と名前を付けます
[Create a Service] (サービスの作成) ダイアログ ボックスで、 [ステートフル サービス] を選択して "Alphabet.Processing" と名前を付けます。
パーティション数を設定します。 AlphabetPartitions プロジェクトの ApplicationPackageRoot フォルダーにある ApplicationManifest.xml ファイルを開き、下図のようにパラメーター Processing_PartitionCount を 26 に更新します。
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />また、次のように ApplicationManifest.xml の StatefulService 要素の LowKey と HighKey プロパティも更新する必要があります。
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>サービスにアクセスできるようにするために、次のように、Alphabet.Processing サービスの ServiceManifest.xml (PackageRoot フォルダーにあります) のエンドポイント要素を追加して、ポートのエンドポイントを開きます。
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />以上の手順で、26 個のパーティションがある内部エンドポイントをリッスンするようにサービスが構成されました。
次に、Processing クラスの
CreateServiceReplicaListeners()メソッドをオーバーライドする必要があります。Note
この例では、単純な HttpCommunicationListener を使用しているという想定です。 Reliable Service 通信の詳細については、「 Reliable Service 通信モデル」を参照してください。
レプリカがリッスンする URL の推奨されるパターンの形式は
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}です。 そのため、正しいエンドポイントでこのパターンでリッスンするように、通信リスナーを構成する必要があります。このサービスの複数のレプリカは同じコンピューターでホストされる可能性があるので、レプリカに対するこのアドレスを一意にする必要があります。 そのため、パーティション ID + レプリカ ID を URL に含めています。 URL プレフィックスが一意であれば、HttpListener は同じポートでも複数のドレスをリッスンできます。
セカンダリ レプリカも読み取り専用要求をリッスンするような高度な場合に備えて、追加の GUID があります。 この場合、プライマリからセカンダリに移行するときに新しい一意のアドレスを使用して、クライアントがアドレスを強制的に再解決するようにします。 ここでは、レプリカがすべての使用可能なホスト (IP、FQDN、localhost など) でリッスンするように、 '+' がアドレスとして使用されていますコード例を次に示します。
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }また、公開される URL が、リッスンする URL プレフィックスと一部が異なる点に注目してください。 リッスンする URL は HttpListener に渡されます。 公開される URL は、Service Fabric Naming Service に公開される URL です。サービスの検出に使用されます。 クライアントは検出サービスを介してこのアドレスを要求します。 接続するには、クライアントが取得するアドレスにノードの実際の IP または FQDN が含まれる必要があります。 そのため、上のように '+' をノードの IP または FQDN に置き換える必要があります。
最後の手順は、次のように処理ロジックをサービスに追加する処理です。
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestは、パーティションの呼び出しに使用するクエリ文字列パラメーターの値を読み取り、AddUserAsyncを呼び出して、信頼性の高い辞書dictionaryに姓を追加します。プロジェクトにステートレス サービスを追加して、特定のパーティションを呼び出す方法を見てみましょう。
このサービスは、姓をクエリ文字列パラメーターとして受け取り、パーティション キーを決定し、Alphabet.Processing サービスに送信して処理するという、単純な Web インターフェイスとして機能します。
次のように、 [Create a Service] (サービスの作成) ダイアログ ボックスで [ステートレス サービス] を選択し、"Alphabet.Web" と名前を付けます。
Alphabet.WebApi サービスの ServiceManifest.xml のエンドポイント情報を更新し、次のようにポートを開きます。
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>クラス Web で ServiceInstanceListeners のコレクションを返す必要があります。 ここでも、単純な HttpCommunicationListener を実装することができます。
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }次に、処理ロジックを実装する必要があります。 HttpCommunicationListener は要求を受信すると
ProcessInputRequestを呼び出します。 次のコードを追加してみましょう。private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }このコードを詳しく見ていきましょう。 このコードは、クエリ文字列パラメーター
lastnameの最初の文字を char 型で読み取ります。 その後、姓の最初の文字の 16 進数値からAの 16 進数値を引くことで、この文字のパーティション キーが決まります。string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');この例では、1 パーティションに 1 つのパーティション キーがある 26 個のパーティションを使用しています。 次に、
servicePartitionResolverオブジェクトに対してResolveAsyncメソッドを使用して、このキーのサービス パーティションpartitionを取得します。servicePartitionResolverは次のように定義されます。private readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();ResolveAsyncメソッドには、サービス URI、パーティション キー、キャンセル トークンのパラメーターがあります。 処理サービスのサービス URI はfabric:/AlphabetPartitions/Processingです。 次に、パーティションのエンドポイントを取得します。ResolvedServiceEndpoint ep = partition.GetEndpoint()最後に、エンドポイントの URL とクエリ文字列を構築し、処理サービスを呼び出します。
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);処理が完了したら、出力を書き戻します。
最後の手順は、サービスのテストです。 Visual Studio では、ローカル デプロイとクラウド デプロイにアプリケーション パラメーターを使用します。 ローカルに 26 個のパーティションがあるサービスをテストする場合、次のように、AlphabetPartitions プロジェクトの ApplicationParameters フォルダーにある
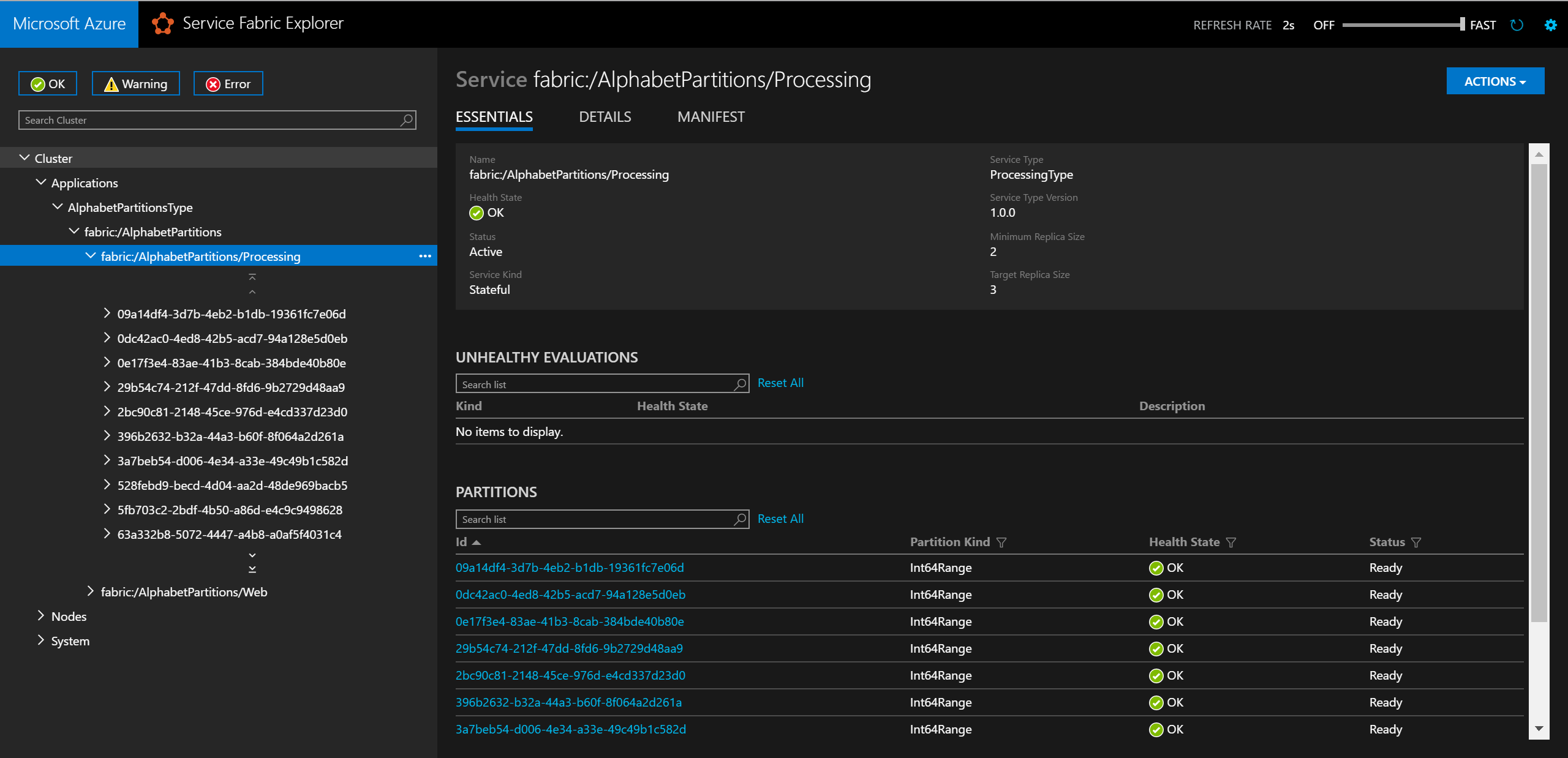
Local.xmlファイルを更新する必要があります。<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>デプロイが完了したら、Service Fabric Explorer でサービスとそのすべてのパーティションを確認できます。
ブラウザーで
http://localhost:8081/?lastname=somenameを入力してパーティション分割ロジックをテストできます。 同じ文字で始まる各姓が同じパーティションに格納されていることがわかります。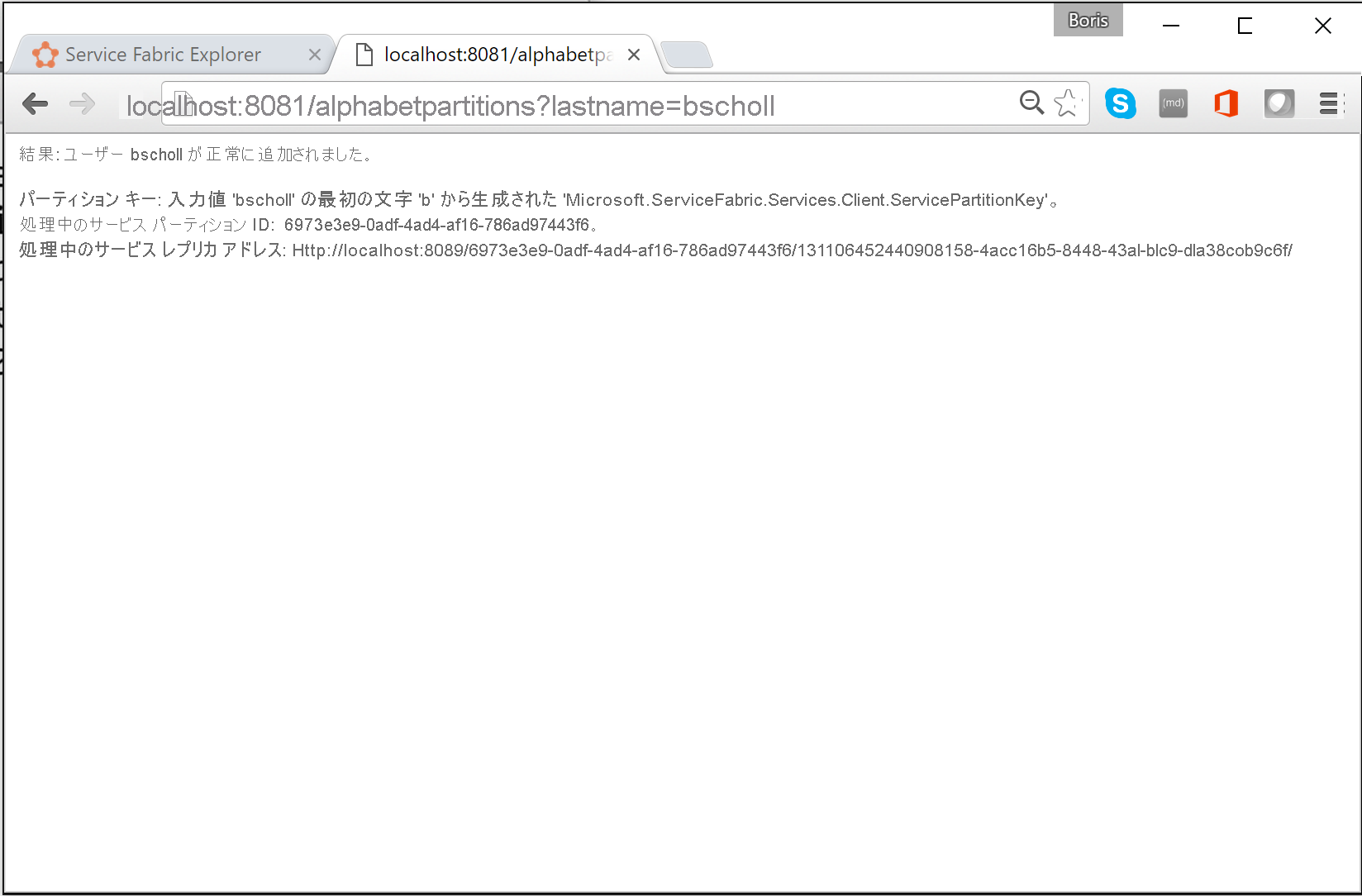
この記事で使用されているコードの完全なソリューションは、こちらで入手できます: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions 。
次のステップ
Service Fabric サービスの詳細については、以下を参照してください。