Azure Synapse Analytics での専用 SQL プール (旧称 SQL DW) のアーキテクチャ
Azure Synapse Analytics は、エンタープライズ データ ウェアハウスとビッグ データ分析がまとめられた分析サービスです。 これにより、条件に基づいてデータのクエリを自由に行うことができます。
注意
Azure Synapse Analytics の詳細については、データ移動の機能強化に関するこちらの動画を視聴してください。
Synapse SQL アーキテクチャのコンポーネント
専用 SQL プール (旧称 SQL DW) では、スケールアウト アーキテクチャを活用して、複数のノードにデータの計算処理を分散します。 スケール単位は、データ ウェアハウス ユニットと呼ばれるコンピューティング能力の抽象化です。 コンピューティングをストレージから切り離すことで、システム内のデータとは無関係に、コンピューティングをスケーリングできるようになります。
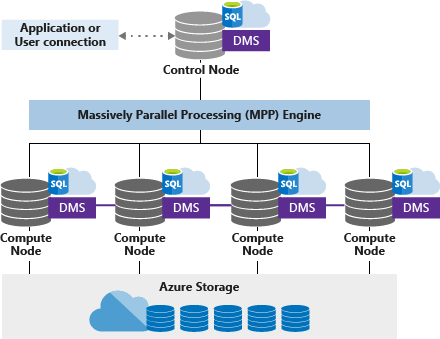
専用 SQL プール (旧称 SQL DW) は、ノードに基づくアーキテクチャを使用します。 アプリケーションは、制御ノードに接続して、T-SQL コマンドを発行します。 制御ノードでは、分散クエリ エンジンがホストされ、それによって並列処理のためにクエリが最適化された後、作業を並行して行うために操作がコンピューティング ノードに渡されます。
コンピューティング ノードはすべてのユーザー データを Azure Storage に保存し、並行クエリを実行します。 データ移動サービス (DMS) はシステム レベルの内部サービスで、必要に応じて複数のノードにデータを移動し、クエリを並列に実行して、正確な結果を返します。
分離されたストレージとコンピューティングでは、専用 SQL プール (旧称 SQL DW) を使用する場合、次のことが可能です。
- 記憶域のニーズに関係なく、コンピューティング能力を計算する。
- データを移動することなく、専用 SQL プール (旧称 SQL DW) 内でコンピューティング能力を拡大または縮小する。
- データをそのままの状態で保持しながら、コンピューティング能力を一時停止するため、支払いがストレージの分だけで済む。
- 稼働時間中にコンピューティング能力を再開する。
Azure Storage
専用 SQL プール (旧称 SQL DW) は、Azure Storage を活用して、ユーザー データを安全に保ちます。 データは Azure Storage によって保存、管理されるため、ストレージの使用量が別途課金されます。 データは、システムのパフォーマンスの最適化のため、ディストリビューションにシャード化されます。 どのシャーディング パターンを使用して、テーブルを定義するときにデータを分散するかを選択できます。 次のシャーディング パターンがサポートされています。
- ハッシュ インデックス
- ラウンド ロビン
- レプリケート
制御ノード
制御ノードは、アーキテクチャの脳です。 すべてのアプリケーションおよび接続と対話するフロントエンドです。 制御ノードで分散クエリ エンジンが実行され、並列クエリのための最適化と調整が行われます。 T-SQL クエリを送信すると、それが制御ノードによって、各ディストリビューションに対して並列で実行されるクエリに変換されます。
コンピューティング ノード
コンピューティング ノードは計算能力を提供します。 ディストリビューションは、処理のためにコンピューティング ノードにマップされます。 追加のコンピューティング リソースの料金を支払うと、ディストリビューションが使用可能なコンピューティング ノードに再マップされます。 コンピューティング ノード数の範囲は 1 から 60 までで、Synapse SQL のサービス レベルによって決定されます。
各コンピューティング ノードにはノード ID があり、システム ビューで確認できます。 名前が sys.pdw_nodes で始まるシステム ビューで node_id 列を検索することにより、コンピューティング ノード ID を見ることができます。 これらのシステム ビューの一覧については、Synapse SQL のシステム ビューに関する記事をご覧ください。
データ移動サービス
データ移動サービス (DMS) は、コンピューティング ノード間のデータ移動を調整するデータ転送テクノロジです。 一部のクエリでは、並列クエリで正確な結果が返されるためにデータ移動が必要です。 データ移動が必要な場合は、DMS により、適切なデータが適切な場所に移動する必要があります。
ディストリビューション
ディストリビューションは、分散データで実行される並列クエリの保存および処理の基本的な単位です。 Synapse SQL でクエリを実行する場合、作業は並列で実行される 60 の小さなクエリに分割されます。
60 の小さいクエリそれぞれは、いずれかのデータ ディストリビューションで実行されます。 各コンピューティング ノードでは、60 ディストリビューションの 1 つまたは複数が管理されます。 コンピューティング リソースの数が最大の専用 SQL プール (旧称 SQL DW) では、コンピューティング ノードごとに 1 つのディストリビューションがあります。 コンピューティング リソースの数が最小の専用 SQL プール (旧称 SQL DW) では、1 つのコンピューティング ノードにすべてのディストリビューションがあります。
注意
実際のワークロードに基づいて推奨される最適なテーブル分散戦略については、Azure Synapse SQL Distribution Advisor を参照してください。
ハッシュ分散テーブル
ハッシュ分散テーブルでは、大きなテーブルでの結合と集計用に最高のクエリ パフォーマンスを実現できます。
ハッシュ分散テーブルにデータをシャードするために、ハッシュ関数を使用して各行が 1 つのディストリビューションに確実に割り当てられます。 テーブルの定義では、1 つの列をディストリビューション列として指定します。 ハッシュ関数は、ディストリビューション列の値を使用してディストリビューションに各行を割り当てます。
次の図は、完全な (分散していない) テーブルがハッシュ分散テーブルとして保存されるしくみを示したものです。

- 各行は、1 つのディストリビューションに属しています。
- 確定ハッシュ アルゴリズムが、各行を 1 つのディストリビューションに割り当てます。
- ディストリビューションごとのテーブル行の数は、異なるテーブル サイズによって示されるように異なります。
ディストリビューション列の選択については、差異性、データ スキュー、およびシステムで実行されるクエリの種類など、パフォーマンスに関する考慮事項があります。
ラウンドロビン分散テーブル
ラウンド ロビン テーブルは作成が最も簡単なテーブルで、読み込み用のステージング テーブルとして使用した場合、高速なパフォーマンスを実現します。
ラウンドロビン分散テーブルでは、テーブル間にデータが均等に配布されますが、最適化は行われません。 1 つのディストリビューションがまずランダムに選択されたら、行のバッファーが順次ディストリビューションに割り当てられます。 ラウンド ロビン テーブルではデータは素早く読み込まれますが、通常、ハッシュ分散テーブルの方が高いクエリ パフォーマンスが見込まれます。 ラウンド ロビン テーブルの結合では、データの再シャッフルが必要になり、追加の時間がかかります。
レプリケート テーブル
レプリケート テーブルは、小さなテーブル用に最も高速なクエリ パフォーマンスを実現します。
レプリケートされたテーブルは、各コンピューティング ノードにテーブルの完全なコピーをキャッシュします。 その結果、テーブルをレプリケートすると、結合または集計の前に、コンピューティング ノード間にデータを転送する必要がなくなります。 レプリケート テーブルは小さいテーブルに最適です。 大きいテーブルの使用が非現実的なデータを書き込む際には、追加ストレージが必要になり、追加のオーバーヘッドが発生します。
次の図は、各コンピューティング ノードの最初のディストリビューションにキャッシュされたレプリケート テーブルを示しています。

次のステップ
Azure Synapse の概要について学習したので、次は、すばやく専用 SQL プール (旧称 SQL DW) を作成し、サンプル データを読み込む方法について学習します。 Azure に慣れていない場合に新しい用語を調べるには、 Azure 用語集 が役立ちます。 または、次の Azure Synapse リソースも確認できます。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示