このチュートリアルでは、Azure Data Lake Storage 対応の Azure Storage アカウント内の格納データに Azure Synapse サーバーレス SQL プールを接続する方法を説明します。 この接続を使用すると、Azure Storage 内のデータに対して SQL言語を使用して SQL クエリと分析をネイティブに実行できます。
このチュートリアルでは、次の作業を行います。
- ストレージ アカウントへのデータの取り込み
- Synapse Analytics ワークスペースを作成します (ない場合)。
- Blob Storage 内のデータに対して分析を実行する
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
階層型名前空間 (Azure Data Lake Storage) を持つストレージ アカウントを作成します。
ユーザー アカウントにストレージ BLOB データ共同作成者ロールが割り当てられていることを確認します。
重要
ストレージ アカウントの範囲内のロールを割り当てるようにしてください。 親リソース グループまたはサブスクリプションにロールを割り当てることはできますが、それらのロール割り当てがストレージ アカウントに伝達されるまで、アクセス許可関連のエラーが発生します。
フライト データのダウンロード
このチュートリアルでは、運輸統計局からのフライト データを使用します。 チュートリアルを完了するには、このデータをダウンロードする必要があります。
On_Time_Reporting_Carrier_On_Time_Performance_1987_present_2016_1.zip ファイルをダウンロードします。 このファイルには、フライト データが含まれています。
ZIP ファイルの内容を解凍し、ファイル名とファイル パスをメモします。 この情報は後の手順で必要になります。
ソース データをストレージ アカウントにコピーする
Azure Portal で新しいストレージ アカウントに移動します。
[ストレージ ブラウザー]->[BLOB コンテナー]->[コンテナーの追加] の順に選択し、data という名前の新しいコンテナーを作成します。
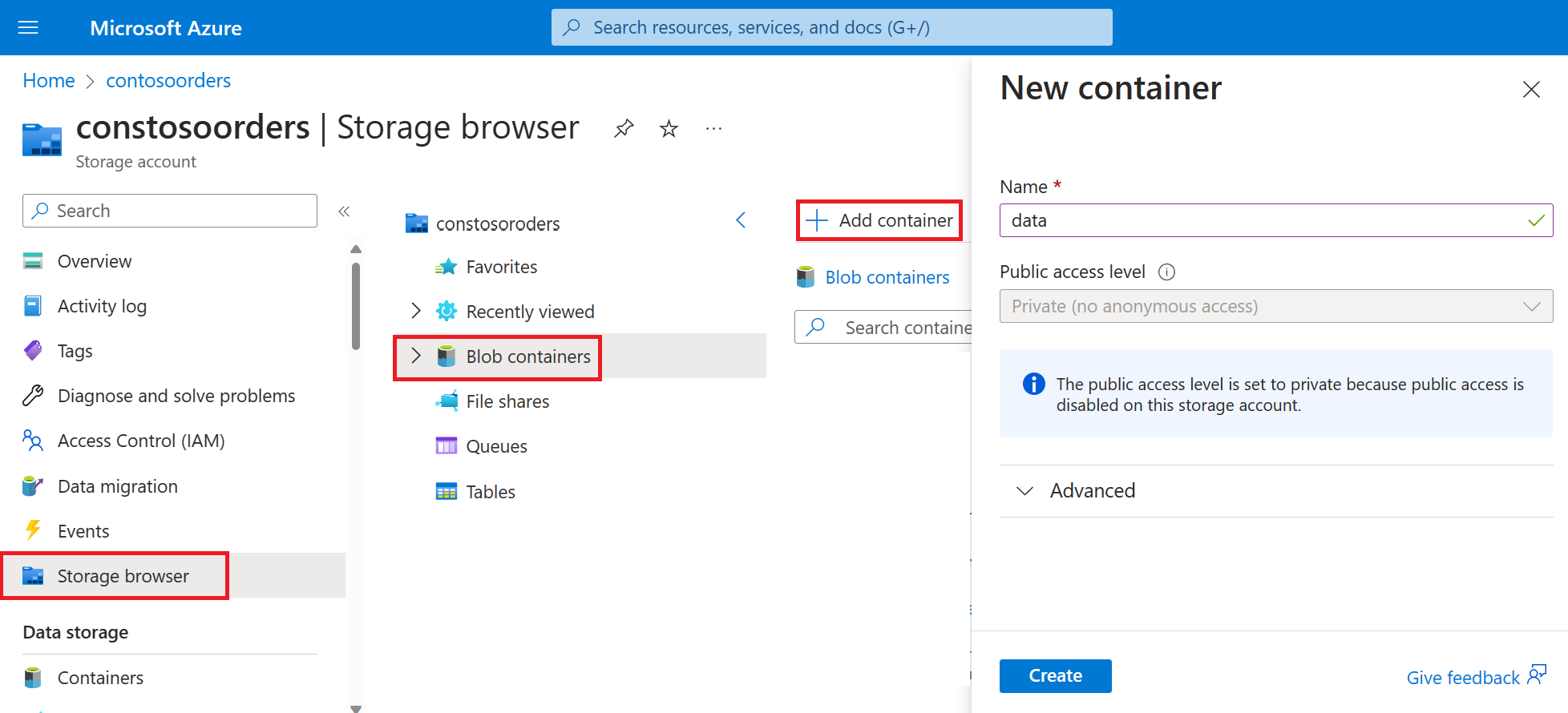
ストレージ ブラウザーで、
On_Time_Reporting_Carrier_On_Time_Performance_1987_present_2016_1.csvファイルを data フォルダーにアップロードします。
Azure Synapse ワークスペースを作成する
Azure portal で Synapse ワークスペースを作成します。 ワークスペースを作成するときは、次の値を使用します。
- サブスクリプション: ストレージ アカウントに関連付けられた Azure サブスクリプションを選択します。
- リソース グループ: ストレージ アカウントを配置したリソース グループを選択します。
-
リージョン: ストレージ アカウントのリージョンを選択します (例:
Central US)。 - 名前: Synapse ワークスペースの名前を入力します。
- SQL 管理者のログイン : SQL Server の管理者のユーザー名を入力します。
- SQL 管理者のパスワード : SQL Server の管理者のパスワードを入力します。
- タグ値 : 既定値のままにします。
Synapse SQL エンドポイント名を見つける (オプション)
サーバーレス SQL エンドポイント ネーム サーバー名を使用すると、SQL Server または Azure SQL データベース (SQL Server Management Studio、 Visual Studio Code の MSSQL 拡張機能、 Power BI など) で T-SQL クエリを実行できる任意のツールに接続できます。
完全修飾サーバー名を検索するには、次の手順に従います。
- 接続先のワークスペースを選択します。
- [概要] に移動します。
- サーバーの完全名を見つけます。
- 専用 SQL プールの場合は、SQL エンドポイントを使用します。
- サーバーレス SQL プールの場合は、SQL オンデマンド エンドポイントを使用します。
このチュートリアルでは、Synapse Studio を使用して、ストレージ アカウントにアップロードした CSV ファイルのデータに対してクエリを実行します。
Synapse Studio を使用してデータを探索する
Synapse Studio を開きます。 「Synapse Studio を開く」を参照してください
SQL スクリプトを作成し、このクエリを実行してファイルの内容を表示します。
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://<storage-account-name>.dfs.core.windows.net/<container-name>/folder1/On_Time.csv', FORMAT='CSV', PARSER_VERSION='2.0' ) AS [result]Synapse Studio で SQL スクリプトを作成する方法については、「Azure Synapse Analytics での Synapse Studio SQL スクリプト」を参照してください
リソースをクリーンアップする
リソース グループおよび関連するすべてのリソースは、不要になったら削除します。 これを行うには、ストレージ アカウントとワークスペースのリソース グループを選択し、[削除] を選択します。