このチュートリアルでは、Azure Blob Storage インベントリと Azure Databricks を使用してコンテナーに関する統計情報を収集する方法について説明します。
このチュートリアルでは、以下の内容を学習します。
- インベントリ レポートを生成する
- Azure Databricks ワークスペースとノートブックを作成する
- BLOB インベントリ ファイルを読み取る
- BLOB、スナップショット、バージョンの数と合計サイズを取得する
- BLOB の種類とコンテンツ タイプ別に BLOB の数を取得する
前提条件
Azure サブスクリプション - 無料のアカウントを作成する
Azure Storage アカウント - ストレージ アカウントを作成する
ユーザー ID にストレージ BLOB データ共同作成者ロールが割り当てられていることを確認します。
インベントリ レポートを生成する
ストレージ アカウントの BLOB インベントリ レポートを有効にします。 「Azure Storage BLOB のインベントリ レポートを有効にする」を参照してください。
次の構成設定を使用します。
| 設定 | 値 |
|---|---|
| 規則の名前 | blobinventory |
| コンテナー | <コンテナーの名前> |
| インベントリを行うオブジェクトの種類 | BLOB |
| BLOB の種類 | ブロック BLOB、ページ BLOB、追加 BLOB |
| サブタイプ | BLOB のバージョンを含める、スナップショットを含める、削除された BLOB を含める |
| BLOB インベントリ フィールド | All |
| インベントリの頻度 | 毎日 |
| エクスポート形式 | CSV |
インベントリ レポートを有効にしてから、最初のレポートを生成するには、最大で 24 時間待機することが必要な場合があります。
Azure Databricks を構成する
このセクションでは、Azure Databricks ワークスペースとノートブックを作成します。 このチュートリアルの後半では、コード スニペットをノートブック セルに貼り付け、それらを実行してコンテナーの統計情報を収集します。
Azure Databricks ワークスペースを作成する。 「Azure Databricks ワークスペースを作成する」をご覧ください。
新しいノートブックを作成します。 「ノートブックを作成する」を参照してください。
ノートブックの既定の言語として Python を選択します。
BLOB インベントリ ファイルを読み取る
次のコード ブロックをコピーして最初のセルに貼り付けます。ただし、このコードはまだ実行しないでください。
from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pyspark.sql.functions as F storage_account_name = "<storage-account-name>" storage_account_key = "<storage-account-key>" container = "<container-name>" blob_inventory_file = "<blob-inventory-file-name>" hierarchial_namespace_enabled = False if hierarchial_namespace_enabled == False: spark.conf.set("fs.azure.account.key.{0}.blob.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("wasbs://{0}@{1}.blob.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true') else: spark.conf.set("fs.azure.account.key.{0}.dfs.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("abfss://{0}@{1}.dfs.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true')このコード ブロックで、次の値を置き換えます。
<storage-account-name>プレースホルダーの値は、実際のストレージ アカウントの名前に置き換えます。<storage-account-key>プレースホルダーの値を、実際のストレージ アカウントのアカウント キーに置き換えます。<container-name>プレースホルダーの値を、インベントリ レポートを保持するコンテナーに置き換えます。<blob-inventory-file-name>プレースホルダーを、インベントリ ファイルの完全修飾名に置き換えます (例:2023/02/02/02-16-17/blobinventory/blobinventory_1000000_0.csv)。アカウントに階層型名前空間がある場合は、
hierarchical_namespace_enabled変数をTrueに設定します。
[実行] ボタンを押して、このセル内のコードを実行します。
BLOB の数とサイズを取得する
新しいセルに次のコードを貼り付けます。
print("Number of blobs in the container:", df.count()) print("Number of bytes occupied by blobs in the container:", df.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])[実行] ボタンを押してセルを実行します。
ノートブックには、コンテナー内の BLOB の数と、コンテナー内の BLOB によって占有されているバイト数が表示されます。

スナップショットの数とサイズを取得する
新しいセルに次のコードを貼り付けます。
from pyspark.sql.functions import * print("Number of snapshots in the container:", df.where(~(col("Snapshot")).like("Null")).count()) dfT = df.where(~(col("Snapshot")).like("Null")) print("Number of bytes occupied by snapshots in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])[実行] ボタンを押してセルを実行します。
ノートブックには、スナップショットの数と BLOB スナップショットによって占有される合計バイト数が表示されます。

バージョン数とサイズを取得する
新しいセルに次のコードを貼り付けます。
from pyspark.sql.functions import * print("Number of versions in the container:", df.where(~(col("VersionId")).like("Null")).count()) dfT = df.where(~(col("VersionId")).like("Null")) print("Number of bytes occupied by versions in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])セルを実行するには、Shift + Enter キーを押します。
ノートブックには、BLOB バージョンの数と BLOB バージョンによって占有される合計バイト数が表示されます。

BLOB の種類別に BLOB 数を取得する
新しいセルに次のコードを貼り付けます。
display(df.groupBy('BlobType').count().withColumnRenamed("count", "Total number of blobs in the container by BlobType"))セルを実行するには、Shift + Enter キーを押します。
ノートブックには、種類別に BLOB の種類の数が表示されます。

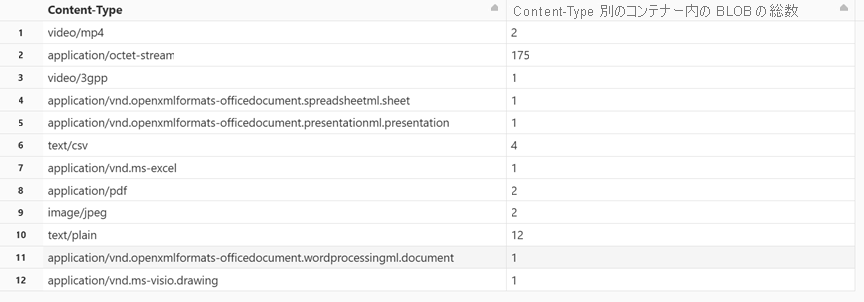
コンテンツ タイプ別に BLOB 数を取得する
新しいセルに次のコードを貼り付けます。
display(df.groupBy('Content-Type').count().withColumnRenamed("count", "Total number of blobs in the container by Content-Type"))セルを実行するには、Shift + Enter キーを押します。
ノートブックには、各コンテンツ タイプに関連付けられている BLOB の数が表示されます。
クラスターを終了する
不要な課金を回避するために、コンピューティング リソースを終了します。 コンピューティングの終了に関する記事を参照してください。
次のステップ
Azure Synapse を使用して、コンテナーごとの BLOB の数と BLOB の合計サイズを計算する方法について説明します。 「Azure Storage インベントリを使用してコンテナーあたりの BLOB の数と合計サイズを計算する」を参照してください。
コンテナーと BLOB を表す統計を生成して視覚化する方法について説明します。 「チュートリアル: BLOB インベントリ レポートを分析する」を参照してください。
BLOB とコンテナーの分析に基づいて、コストを最適化する方法を確認してください。 次の記事を参照してください。