Azure Stream Analytics ジョブの geo 冗長性を実現する
Azure Stream Analytics では自動 geo フェールオーバーは提供されませんが、同じ Stream Analytics ジョブを複数の Azure リージョンにデプロイすることで、geo 冗長性を実現できます。 各ジョブは、ローカル入力ソースとローカル出力ソースに接続されます。 2 つのリージョン入力への入力データの送信と、2 つのリージョン出力の間の調整は、どちらもアプリケーションで行う必要があります。 Stream Analytics ジョブは、2 つの独立したエンティティです。
次の図は、イベント ハブを入力とし、Azure データベースを出力とする、geo 冗長 Stream Analytics ジョブのデプロイの例を示したものです。
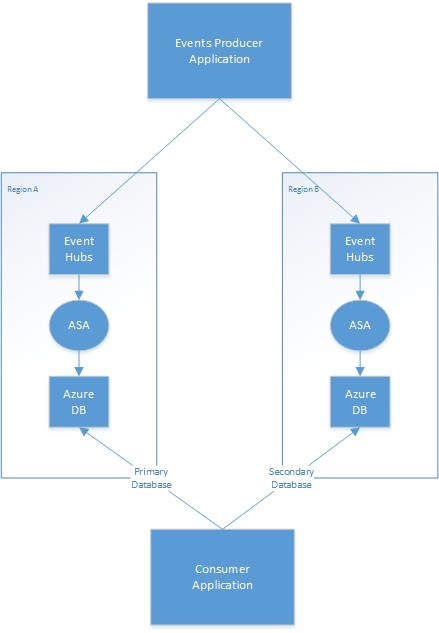
プライマリとセカンダリの戦略
アプリケーションでは、どのリージョンの出力データベースをプライマリと見なし、どれをセカンダリと見なすかを、管理する必要があります。 プライマリ リージョンで障害が発生した場合、アプリケーションではセカンダリ データベースに切り替えて、そのデータベースからの更新の読み取りを開始します。 読み取りの重複が最小限になる実際のメカニズムは、アプリケーションによって異なります。 出力に追加情報を書き込むことで、このプロセスを簡略化できます。 たとえば、各出力にタイムスタンプまたはシーケンス ID を追加することで、重複する行のスキップを簡単な操作にできます。 プライマリ リージョンが復元された後、同様のメカニズムを使用してセカンダリ データベースに追いつくことができます。
入力と出力の種類が異なると、異なる geo レプリケーション オプションを使用できますが、この記事で説明されているパターンを使用して、geo 冗長性を実現することをお勧めします。このようにすれば、イベント プロデューサーとイベント コンシューマーの両方を柔軟に制御できます。