入力検証は、形式に誤りがあるイベントまたは予期しないイベントからクエリのメイン ロジックを保護するために使用する手法です。 クエリは、レコードを明示的に処理してチェックするためにアップグレードされるので、アップグレードでメイン ロジックが壊されてはなりません。
入力検証を実装するには、クエリに 2 つの初期手順を追加します。 まず、コア ビジネス ロジックに送信されるスキーマが、予期した内容と一致していることを確認する必要があります。 次に、例外をトリアージし、必要に応じて無効なレコードをセカンダリ出力にルーティングします。
入力検証を使用するクエリは、次のように構成されます。
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
入力検証を含めて設定されたクエリの包括的な例については、「入力検証を使用するクエリの例」セクションを参照してください。
この記事では、この手法を実装する方法について説明します。
Context
Azure Stream Analytics (ASA) ジョブは、ストリームからのデータを処理します。 ストリームは、シリアル化されて送信される生データのシーケンスです (CSV、JSON、AVRO...)。ストリームから読み取るには、使用されている特定のシリアル化形式をアプリケーションが認識している必要があります。 ASA では、ストリーミング入力を構成するときに、イベントのシリアル化形式を定義する必要があります。
データを逆シリアル化したら、スキーマを適用して意味を与える必要があります。 スキーマは、ストリーム内のフィールドの一覧と、それぞれのデータ型を意味します。 ASA では、入力レベルで受信データのスキーマを設定する必要はありません。 代わりに、ASA では動的な入力スキーマがネイティブでサポートされています。 イベント (行) の間でフィールド (列) のリストとそれらの型が変化することが想定されています。 また、ASA では、データ型が明示的に指定されていないときは推定され、必要に応じて型の暗黙的なキャストが試みられます。
動的スキーマ処理は、ストリーム処理のための強力な機能です。 データ ストリームには、多くの場合、それぞれが固有のスキーマを持つ複数のソースからの、複数のイベントの種類のデータが含まれます。 ASA でこのようなストリームのイベントのルーティング、フィルター、処理を行うには、スキーマに関係なくそのすべてを取り込む必要があります。
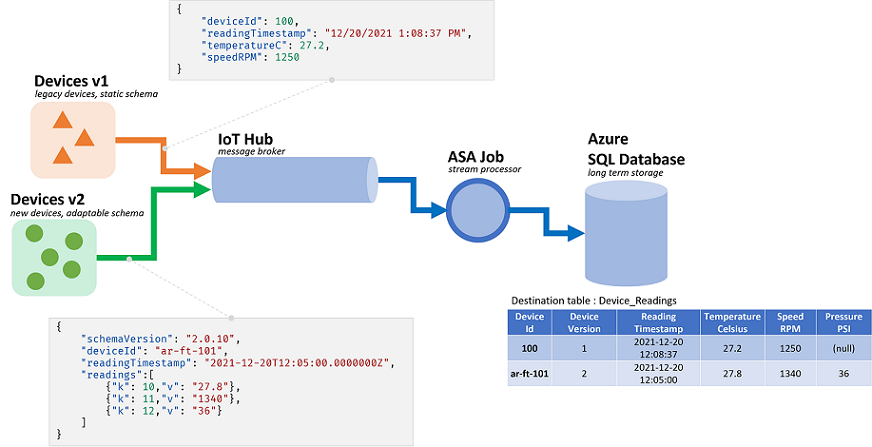
ただし、動的スキーマ処理によって提供される機能には、潜在的な欠点があります。 予期しないイベントがメイン クエリ ロジックを流れて壊す可能性があります。 たとえば、NVARCHAR(MAX) 型のフィールドで ROUND を使用できます。 ASA は、ROUND のシグネチャと一致するように、暗黙的にそれを float にキャストします。 この場合、このフィールドには常に数値が含まれることが想定または期待されます。 それに反して、フィールドが "NaN" に設定されたイベントを受け取った場合、またはフィールドがまったくない場合は、ジョブが失敗する可能性があります。
入力検証により、このような形式に誤りがあるイベントを処理するための予備的な手順がクエリに追加されます。 ここでは、主に WITH と TRY_CAST を使ってそれを実装します。
シナリオ: 信頼性が低いイベント プロデューサーについての入力検証
1 つのイベント ハブからデータを取り込む新しい ASA ジョブを作成します。 ほとんどの場合、データ プロデューサーに対して責任はありません。 ここでのプロデューサーは、複数のハードウェア ベンダーによって販売されている IoT デバイスです。
利害関係者と相談し、シリアル化の形式とスキーマに同意します。 すべてのデバイスにより、ASA ジョブの入力である共通イベント ハブにそのようなメッセージがプッシュされます。
スキーマのコントラクトは次のように定義されます。
| フィールド名 | フィールドの種類 | フィールドの説明 |
|---|---|---|
deviceId |
Integer | デバイスの一意識別子 |
readingTimestamp |
Datetime | 中央ゲートウェイによって生成されるメッセージの日時 |
readingStr |
String | |
readingNum |
数値 | |
readingArray |
文字列の配列 |
これにより、JSON でシリアル化されたサンプル メッセージは次のようになります。
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
スキーマのコントラクトとその実装の間に矛盾があることが既にわかります。 JSON 形式には、datetime に対するデータ型はありません。 それは文字列として転送されます (上の readingTimestamp を参照)。 ASA は問題に簡単に対処できますが、型を検証して明示的にキャストする必要があることが示されます。 データは CSV でシリアル化されるため、すべての値は文字列として送信されます。
もう 1 つの食い違いがあります。 ASA で使用されている独自の型システムは、受信するものと一致しません。 ASA に整数 (bigint)、日時、文字列 (nvarchar (max))、配列の組み込み型がある場合、float の数値のみがサポートされます。 この不一致は、ほとんどのアプリケーションでは問題になりません。 しかし、特定のエッジ ケースでは、精度が少しドリフトする可能性があります。 この例では、数値を新しいフィールドで文字列として変換します。 その後、ダウンストリームの固定小数点数をサポートするシステムを使用して、潜在的なドリフトを検出して修正します。
クエリに戻り、ここでは次のことを行います。
readingStrを JavaScript UDF に渡します- 配列内のレコードの数をカウントします
readingNumを小数点以下 2 桁に丸めます- データを SQL テーブルに挿入します
挿入先の SQL テーブルのスキーマは次のとおりです。
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
各フィールドがジョブを通過するときにどのように処理されるのかを示すとよくわかります。
| フィールド | 入力 (JSON) | 継承された型 (ASA) | 出力 (Azure SQL) | コメント |
|---|---|---|---|---|
deviceId |
number | bigint | 整数 (integer) | |
readingTimestamp |
string | nvarchar(MAX) | datetime2 | |
readingStr |
string | nvarchar(MAX) | nvarchar(200) | UDF によって使用されます |
readingNum |
number | float | decimal(18,2) | 丸められます |
readingArray |
array(string) | nvarchar(MAX) の配列 | 整数 (integer) | カウントされます |
前提条件
ASA ツール拡張機能を使用して Visual Studio Code でクエリを開発します。 このチュートリアルの最初の手順では、必要なコンポーネントをインストールする方法が説明されています。
コストが発生しないようにして、デバッグ ループを高速化するため、VS Code では、ローカル実行とローカル入出力を使用します。 イベントハブまたは Azure SQL Database を設定する必要はありません。
基本クエリ
入力検証を行わない基本的な実装から始めます。 それは次のセクションで追加します。
VS Code で、新しい ASA プロジェクトを作成します
input フォルダーに data_readings.json という名前の新しい JSON ファイルを作成して、次のレコードを追加します。
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
次に、上で作成した JSON ファイルを参照する、readings という名前のローカル入力を定義します。
それを構成すると、次のようになります。
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
プレビュー データを使用して、レコードが正しく読み込まれていることを確認できます。
Functions フォルダーを右クリックして [ASA: Add Function] を選ぶことにより、udfLen という名前の新しい JavaScript UDF を作成します。 使用するコードは次のとおりです。
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
ローカル実行では、出力を定義する必要はありません。 複数の出力がない限り、INTO を使用する必要さえありません。 .asaql ファイルでは、既存のクエリを次のように置き換えることができます。
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
送信したクエリを簡単に確認します。
- 各配列内のレコード数をカウントするには、最初にそれらをアンパックする必要があります。 CROSS APPLY と GetArrayElements() を使用します (その他のサンプルはこちら)
- これにより、クエリで 2 つのデータ セットが明らかになります: 元の入力と配列値。 フィールドが混ざらないようにするため、エイリアス (
AS r) を定義し、それをすべての場所で使用します - 次に、配列の値を実際に
COUNTするため、GROUP BY を使用して集計する必要があります - このためには、時間枠を定義する必要があります。 このロジックには必要ないので、スナップショット ウィンドウが適切な選択です
- これにより、クエリで 2 つのデータ セットが明らかになります: 元の入力と配列値。 フィールドが混ざらないようにするため、エイリアス (
- また、すべてのフィールドに対して
GROUP BYを使用し、SELECTでそれらすべてをプロジェクションする必要があります。SELECT *によってエラーが入力から出力まで流れるので、フィールドを明示的にプロジェクションするのが良い方法です- 時間枠を定義する場合は、TIMESTAMP BY を使用してタイムスタンプを定義できます。 このロジックが機能するためには必要ありません。 ローカル実行では、
TIMESTAMP BYを使用しないと、すべてのレコードが実行開始時刻の 1 つのタイムスタンプで読み込まれます。
- 時間枠を定義する場合は、TIMESTAMP BY を使用してタイムスタンプを定義できます。 このロジックが機能するためには必要ありません。 ローカル実行では、
- UDF を使用して読み取り値をフィルター処理します。
readingStrは 2 文字未満です。 ここでは LEN を使用する必要があります。 UDF はデモンストレーション目的でのみ使用しています
実行を開始し、処理されているデータを確認できます。
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | A String | 1.71 | 2 |
| 2 | 2021-12-10T10:01:00 | Another String | 2.38 | 1 |
| 3 | 2021-12-10T10:01:20 | A Third String | -4.85 | 3 |
| 1 | 2021-12-10T10:02:10 | A Forth String | 1.21 | 2 |
クエリが機能していることがわかったので、より多くのデータに対してテストします。 data_readings.json の内容を次のレコードに置き換えます。
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
ここでは、次の問題を確認できます。
- デバイス #1 ではすべてが正しく行われました
- デバイス #2 では
readingStrが含まれませんでした - デバイス #3 では数字として
NaNが送信されました - デバイス #4 では配列ではなく空のレコードが送信されました
現在はジョブの実行は正常に終了しません。 次のいずれかのエラー メッセージが表示されます。
デバイス 2 では次のように表示されます。
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
デバイス 3 では次のように表示されます。
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
デバイス 4 では次のように表示されます。
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
検証を行わないと、形式に誤りがある各レコードが、入力からメイン クエリ ロジックに流れました。 これで、入力検証の価値がわかります。
入力検証の実装
クエリを拡張して入力を検証します。
入力検証の最初のステップは、コア ビジネス ロジックのスキーマで期待されることを定義することです。 元の要件を振り返ると、メイン ロジックは次の処理を行います。
readingStrを JavaScript UDF に渡してその長さを測定します- 配列内のレコードの数をカウントします
readingNumを小数点以下 2 桁に丸めます- データを SQL テーブルに挿入します
各ポイントで期待されることは次のようになります。
- UDF には、null にできない文字列型 (ここでは nvarchar(max)) の引数が必要です
GetArrayElements()には、配列型の引数または null 値が必要ですRoundには、bigint または float 型の引数、または null 値が必要です- ASA の暗黙的なキャストに依存するのではなく、自分で行い、クエリでの型の競合を処理する必要があります
1 つの方法は、これらの例外を処理するようにメイン ロジックを調整することです。 しかし、この場合は、メイン ロジックが完璧であることがわかっています。 ですから、代わりに受信データを検証します。
まず、WITH を使用して、クエリの最初のステップとして入力検証レイヤーを追加します。 TRY_CAST を使用してフィールドを想定される型に変換し、変換が失敗した場合はそれらを NULL に設定します。
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
最後に使用した入力ファイル (エラーのあるもの) では、このクエリから次のセットが返されます。
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | A String | 1.7145 | ["A","B"] | 1 | 2021-12-10T10:00:00Z | A String | 1.7145 | ["A","B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00Z | NULL | 2.378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | A Third String | NaN | ["D","E","F"] | 3 | 2021-12-10T10:01:20Z | A Third String | NULL | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | A Forth String | 1.2126 | {} | 4 | 2021-12-10T10:02:10Z | A Forth String | 1.2126 | NULL |
既に 2 つのエラーが対処されていることがわかります。 NaN と {} を NULL に変換しました。 これで、これらのレコードは対象の SQL テーブルに正しく挿入されます。
次に、値がない、または無効であるレコードに対処する方法を決定する必要があります。 検討した後、空または無効な readingArray または欠落している readingStr でレコードを拒否することにします。
そのため、検証 1 とメイン ロジックの間でレコードをトリアージする 2 番目のレイヤーを追加します。
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
両方の出力に対して 1 つの WHERE 句を記述し、2 つ目で NOT (...) を使用するのがよい方法です。 そうするば、レコードが両方の出力から除外されて失われる可能性がなくなります。
2 つの出力が得られるようになります。 Debug1 には、メイン ロジックに送信されるレコードが含まれます。
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00Z | A String | 1.7145 | ["A","B"] |
| 3 | 2021-12-10T10:01:20Z | A Third String | NULL | ["D","E","F"] |
Debug2 には、拒否されるレコードが含まれます。
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00Z | NULL | 2.378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | A Forth String | 1.2126 | {} | 4 | 2021-12-10T10:02:10Z | A Forth String | 1.2126 | NULL |
最後のステップは、メイン ロジックを追加して戻すことです。 また、拒否されるものを収集する出力も追加します。 ここでは、ストレージ アカウントなど、厳密な型指定を適用しない出力アダプターを使用するのが最適です。
完全なクエリは、最後のセクションで確認できます。
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
次のような SQLOutput のセットが得られ、エラーの可能性はありません。
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00Z | A String | 1.7145 | 2 |
| 3 | 2021-12-10T10:01:20Z | A Third String | NULL | 3 |
他の 2 つのレコードは、人間によるレビューと後処理のために BlobOutput に送られます。 これでクエリは安全になりました。
入力検証のあるクエリの例
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
入力検証の拡張
GetType を使用して、型を明示的にチェックできます。 これは、プロジェクションの CASE またはセット レベルの WHERE で問題なく動作します。 GetType を使用すると、メタデータ リポジトリに対して受信スキーマを動的にチェックすることもできます。 リポジトリは参照データ セットを使用して読み込むことができます。
単体テストは、クエリに回復性があることを確認するよい方法です。 入力ファイルと想定される出力で構成される一連のテストを作成します。 合格するには、クエリで一致する出力が生成される必要があります。 ASA では、単体テストは asa-streamanalytics-cicd npm モジュールを使用して行われます。 さまざまな形式に誤りがあるイベントを含むテスト ケースを作成し、デプロイ パイプラインでテストする必要があります。
最後に、VS Code でいくつかの簡単な統合テストを実行できます。 ライブ出力へのローカル実行により、SQL テーブルにレコードを挿入できます。
サポートを受ける
詳細については、Azure Stream Analytics に関する Microsoft Q&A 質問ページを参照してください。