この記事では、Azure Stream Analytics の互換性レベル オプションについて説明します。
Stream Analytics は管理サービスであり、定期的に機能が更新され、常にパフォーマンスが向上しています。 サービスのほとんどのランタイム更新は、互換性レベルとは無関係に、自動的にエンド ユーザーが使用できるようになります。 ただし、新しい機能によって既存のジョブの動作に変更が生じる場合や、実行中のジョブでデータが消費される方法に変更が生じる場合は、この変更を新しい互換性レベルで導入します。 互換性レベルの設定を下げたままにすることで、大幅な変更を取り入れずに既存の Stream Analytics ジョブの実行を保持することができます。 最新のランタイム動作への準備ができたら、互換性レベルを上げることでオプトインできます。
互換性レベルを選択する
互換性レベルは、ストリーム分析ジョブの実行時の動作を制御します。
Azure Stream Analytics では現在、次の 3 つの互換性レベルがサポートされています。
- 1.2 - 最近の改善による最新の動作
- 1.1 - 以前の動作
- 1.0 - 元の互換性レベル。数年前の Azure Stream Analytics の一般提供時に導入されました。
新しい Stream Analytics ジョブを作成する場合は、最新の互換性レベルを使用して作成することをお勧めします。 その後に追加される変更や複雑さを避けるために、最新の動作に基づいてジョブの設計を開始ししてください。
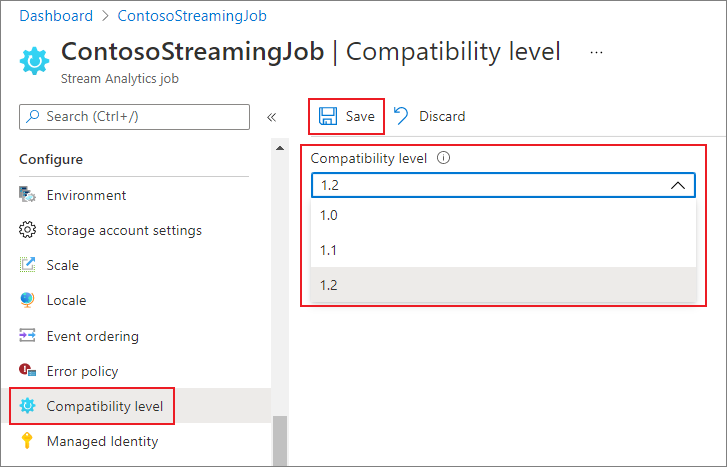
互換性レベルの設定
Stream Analytics ジョブの互換性レベルは、Azure portal または create job REST API 呼び出しを使用して設定できます。
Azure portal でジョブの互換性レベルを更新するには:
- Azure portal を使用して、Stream Analytics ジョブを見つけます。
- 互換性レベルを更新する前に、ジョブを停止します。 ジョブが実行状態の場合は、互換性レベルを更新できません。
- [構成] 見出しで、 [互換性レベル] を選択します。
- 必要な互換性レベルの値を選択します。
- ページの下部にある [保存] を選択します。
互換性レベルを更新すると、T コンパイラが、選択された互換性レベルに対応する構文を使用してジョブを検証します。
互換性レベル 1.2
互換性レベル 1.2 では、以下の大きな変更が導入されました。
AMQP メッセージングプロトコル
1.2 レベル:Azure Stream Analytics では Advanced Message Queuing Protocol (AMQP) メッセージングプロトコルを使用して Service Bus キューおよびトピックに書き込みます。 AMQP を使用すると、オープンな標準プロトコルを使用したクロス プラットフォームのハイブリッド アプリケーションをビルドできます。
地理空間の関数
以前のレベル: Azure Stream Analytics では地理計算が使われていました。
1.2 レベル: Azure Stream Analytics では、幾何射影された地理座標を計算できます。 地理空間関数のシグネチャの変更はありません。 ただし、これまでより正確に計算できるよう、セマンティクスは若干異なります。
Azure Stream Analytics では、地理空間参照データのインデックス作成がサポートされています。 高速の結合演算のため、地理空間要素を含む参照データにインデックスを作成できます。
更新された地理空間関数は、Well Known Text (WKT) 地理空間形式の完全な表現力を備えています。 以前の GeoJson ではサポートされていなかったその他の地理空間コンポーネントを指定できます。
詳しくは、「Azure Stream Analytics の地理空間機能を更新 – クラウドと Azure IoT Edge で使用可能」をご覧ください。
複数のパーティションを持つ入力ソースの並列クエリ実行
以前のレベル: Azure Stream Analytics クエリでは、入力ソースのパーティションをまたいでクエリの処理を並列化するには、PARTITION BY 句を使う必要がありました。
1.2 レベル: クエリ ロジックを入力ソースのパーティションをまたいで並列化できる場合は、Azure Stream Analytics で個別にクエリ インスタンスが作成されて計算が並列に実行されます。
Azure Cosmos DB 出力でのネイティブ Bulk API 統合
以前のレベル: アップサート動作は "挿入またはマージ" でした。
1.2 レベル: Azure Cosmos DB 出力でのネイティブ Bulk API 統合により、スループットが最大になり、スロットリング要求の処理が効率的に行われます。 詳細については、Azure Cosmos DB ページへの Azure Stream Analytics の出力に関する記事を参照してください。
アップサート動作は "挿入または置換" です。
SQL 出力に書き込むときの DateTimeOffset
以前のレベル:DateTimeOffset 型は UTC に調整されました。
1.2 レベル: DateTimeOffset は調整されなくなりました。
SQL 出力に書き込むときの Long
以前のレベル: 値はターゲットの型に基づいて切り捨てられました。
1.2 レベル: ターゲットの型に適合しない値は、出力エラー ポリシーに従って処理されます。
SQL 出力への書き込み時のレコードと配列のシリアル化
以前のレベル: レコードは "Record" として書き込まれ、配列は "Array" として書き込まれました。
1.2 レベル: レコードと配列は JSON 形式でシリアル化されます。
関数のプレフィックスの厳密な検証
以前のレベル: 関数のプレフィックスの厳密な検証はありませんでした。
1.2 レベル: Azure Stream Analytics では、関数のプレフィックスの厳密な検証が行われます。 組み込み関数にプレフィックスを追加すると、エラーが発生します。 たとえば、myprefix.ABS(…) はサポートされていません。
組み込み集計にプレフィックスを追加しても、エラーになります。 たとえば、myprefix.SUM(…) はサポートされていません。
どのようなユーザー定義関数でも、プレフィックス "System" を使用するとエラーになります。
Azure Cosmos DB 出力アダプターのキー プロパティとして Array と Object が許可されない
以前のレベル: Array 型と Object 型は、キー プロパティとしてサポートされていました。
1.2 レベル: Array 型と Object 型は、キー プロパティとしてサポートされなくなりました。
JSON、AVRO、PARQUET でのブール型の逆シリアル化
以前のレベル: Azure Stream Analytics では、ブール値は BIGINT 型に逆シリアル化されます。false は 0 に、true は 1 にマップされます。 出力でブール値が JSON、AVRO、PARQUET に作成されるのは、イベントを BIT に明示的に変換した場合のみです。
たとえば、SELECT value INTO output1 FROM input1 のような input1 から JSON { "value": true } を読み取るパススルー クエリでは、output1 に JSON 値 { "value": 1 } が書き込まれます。
1.2 レベル: Azure Stream Analytics では、ブール値は BIT 型に逆シリアル化されます。 False は 0 にマップされ、true は 1 にマップされます。
SELECT value INTO output1 FROM input1 のような input1 から JSON { "value": true } を読み取るパススルー クエリでは、output1 に JSON 値 { "value": true } が書き込まれます。 出力で true と false がブール型をサポートする形式で表示されるように、クエリで BIT 型に値をキャストできます。
互換性レベル 1.1
互換性レベル 1.1 では、以下の大きな変更が導入されました。
Service Bus XML 形式
1.0 レベル: Azure Stream Analytics が DataContractSerializer を使用していたため、メッセージのコンテンツに XML タグが含まれていました。 次に例を示します。
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
1.1 レベル: メッセージのコンテンツにはストリームが直接含まれていて、追加のタグは含まれていません。 例: { "SensorId":"1", "Temperature":64}
フィールド名の大文字と小文字の区別の保持
1.0 レベル: Azure Stream Analytics エンジンによる処理で、フィールド名が小文字に変更されました。
1.1 レベル: Azure Stream Analytics エンジンによる処理の際に、フィールド名の大文字と小文字の区別が保持されます。
Note
大文字と小文字の区別の保持は、Edge 環境を使用してホストされている Stream Analytic ジョブではまだ利用できません。 その結果、ジョブが Edge にホストされている場合は、すべてのフィールド名が小文字に変換されます。
FloatNaNDeserializationDisabled
1.0 レベル: CREATE TABLE コマンドは、FLOAT 型の列ではこれらの数値についてドキュメント化された範囲を超えているため、NaN (非数。無限大、-無限大など) のイベントをフィルター処理しませんでした。
1.1 レベル: CREATE TABLE で、強力なスキーマを指定することができます。 Stream Analytics エンジンによって、データがこのスキーマに準拠していることが検証されます。 このモデルでは、NaN 値を持つイベントをコマンドがフィルター処理できます。
JSON のイングレス時の datetime 文字列から DateTime 型への自動変換を無効にする
1.0 レベル: JSON パーサーは、日付/時刻/ゾーン情報を含む文字列値を、イングレス時に DateTime 型に自動変換します。これにより、値は直ちに元の形式とタイムゾーン情報を失います。 これはイングレス時に行われるため、そのフィールドがクエリで使用されていない場合でも、UTC DateTime に変換されます。
1.1 レベル: 日付/時刻/ゾーン情報を持つ文字列値の DateTime 型への自動変換は行われません。 その結果、タイムゾーン情報と元の形式は保持されます。 ただし、NVARCHAR(MAX) フィールドは、DATETIME 式 (DATEADD 関数など) の一部としてクエリで使用されている場合、計算を実行するために DateTime 型に変換され、元の形式を失います。