メトリックとディメンションを使用した Stream Analytics ジョブのパフォーマンスの分析
Stream Analytics ジョブの正常性を把握するには、ジョブのメトリックとディメンションの活用方法に関する知識が重要となります。 Azure portal、Visual Studio Code Stream Analytics 拡張機能、または SDK を使用して、関心のあるメトリックとディメンションを取得できます。
この記事では、Stream Analytics ジョブのメトリックとディメンションを使用して、Azure portal からジョブのパフォーマンスを分析する方法を紹介します。
透かしの遅延とバックログされた入力イベントは、Stream Analytics ジョブのパフォーマンスを決定するための主要なメトリックです。 ジョブの透かしの遅延が増え続け、入力イベントがバックログとしてたまっている場合、入力イベントの速度にジョブが追い付かず、適切なタイミングで出力を生成できていないことを意味します。
いくつかの例を見て、ジョブのパフォーマンスを分析してみましょう。最初は、透かしの遅延のメトリック データを使用します。
特定のパーティションに入力がないためにジョブの透かしの遅延が増加する
驚異的並列ジョブの透かしの遅延が着々と増加している場合は、メトリックに移動します。 次に、以下の手順を使用して、根本原因が入力ソースのパーティションの一部でデータが欠けていることであるかどうかを確認します。
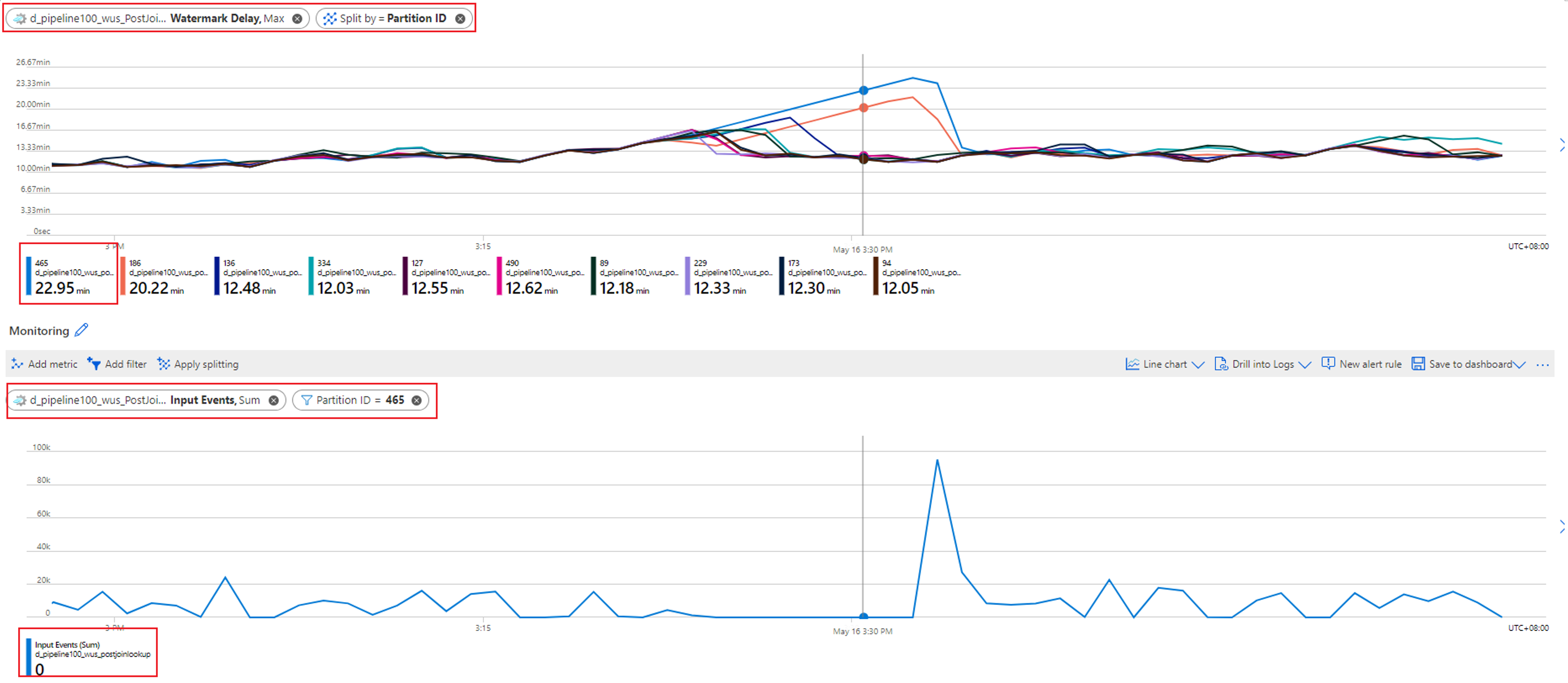
透かしの遅延が増加しているパーティションを確認します。 透かしの遅延メトリックを選択し、パーティション ID ディメンションで分割します。 次の例では、パーティション 465 に高い透かしの遅延があります。

このパーティションの入力データが欠落していないかどうか確認します。 この特定のパーティション ID に対し、入力イベント メトリックを選択してフィルター処理します。


他にどのようなアクションを実行できますか?
このパーティションの透かしの遅延が増加しています。このパーティションに入力イベントが流れ込んでいないためです。 到着遅延に関するジョブの許容期間が数時間で、なおかつ入力データがパーティションに到達しない場合、その到着遅延期間に達するまで、そのパーティションの透かしの遅延は増え続けると予想されます。
たとえば到着遅延期間が 6 時間で、入力データが入力パーティション 1 に到達しない場合、6 時間が経過するまで、出力パーティション 1 の透かしの遅延は増え続けます。 入力ソースから適切にデータが生成されているかどうかをチェックしましょう。
入力データ スキューは透かしの遅延増加の原因となる
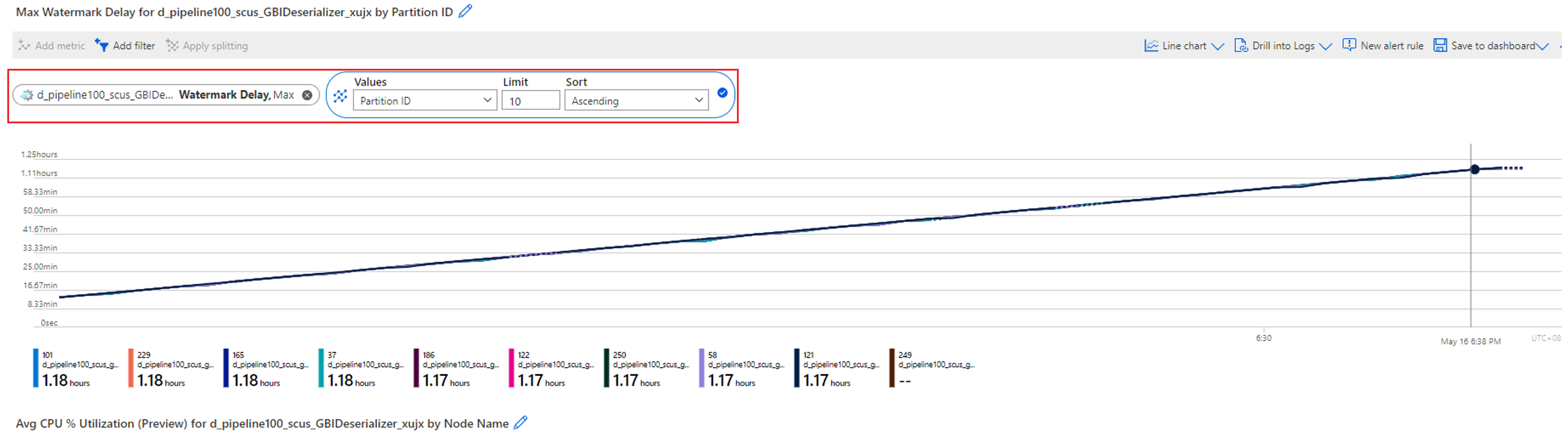
前の例で説明したように、驚異的並列ジョブの透かしの遅延が高い場合は、最初に、透かしの遅延 メトリックを パーティション ID ディメンションで分割します。 その後、すべてのパーティションの透かしの遅延が高いか、一部だけなのかを特定できます。
次の例では、パーティション 0 と 1 の透かしの遅延 (約 20 から 30 秒) は、他の 8 つのパーティションよりも高くなります。 他のパーティションは、透かしの遅延が常に 8 秒から 10 秒で安定しています。

入力イベント メトリックを パーティション ID で分割して、これらすべてのパーティションの入力データがどうなっているかを確認してみましょう。

他にどのようなアクションを実行できますか?
例に示すように、透かしの遅延が増加しているパーティション (0 と 1) の入力データは、他のパーティションと比べ圧倒的に多いことがわかります。 これを "データ スキュー" と呼びます。 次のスクリーンショットに示すように、データ スキューを使用してパーティションを処理しているストリーミング ノードは、他のノードよりも多くの CPU リソースとメモリ リソースを消費してしまいます。

データ スキューが大きいパーティションを処理するストリーミング ノードでは、CPU 使用率やストリーミング ユニット (SU) 使用率が高くなります。 この使用率は、ジョブのパフォーマンスに影響し、透かしの遅延が増加します。 これを軽減するには、入力データをより均等に再分割する必要があります。
物理ジョブ ダイアグラムでこの問題をデバッグすることもできます。「物理ジョブ ダイアグラム: 不均等な分散入力イベント (データ スキュー) を特定する」を参照してください。
CPU またはメモリの過負荷により、透かしの遅延が増加する
驚異的並列ジョブで透かしの遅延が増加している場合、1、2 個のパーティションではなく、すべてのパーティションで遅延が生じている可能性があります。 このケースにジョブが該当することを確認するにはどうすればよいですか?
透かしの遅延 メトリックを パーティション ID で分割します。 次に例を示します。
各パーティションの入力データにデータ スキューが生じているかどうかを確認するために、入力イベント メトリックを パーティション ID で分割します。
CPU と SU 使用率をチェックして、すべてのストリーミング ノードの使用率が極端に上昇しているかどうかを確認します。
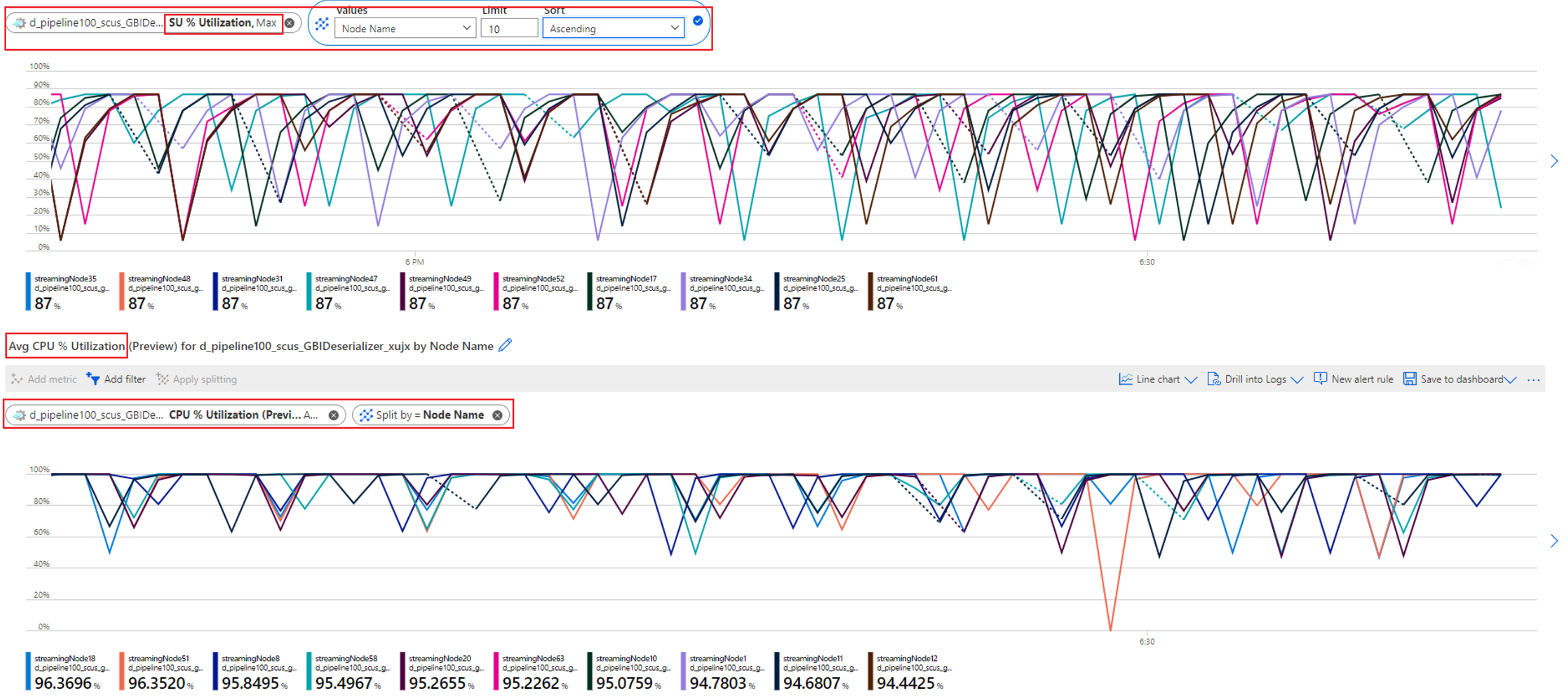
すべてのストリーミング ノードで CPU と SU の使用率が非常に高い (80% を超える) 場合、このジョブには各ストリーミング ノード内でデータが大量に処理されていると結論付けることができます。
さらに、入力イベント メトリックを確認することで、1 つのストリーミング ノードに割り当てられているパーティションの数を確認できます。 ノード名 ディメンションを使用してストリーミング ノード ID をフィルター処理し、パーティション ID で分割します。
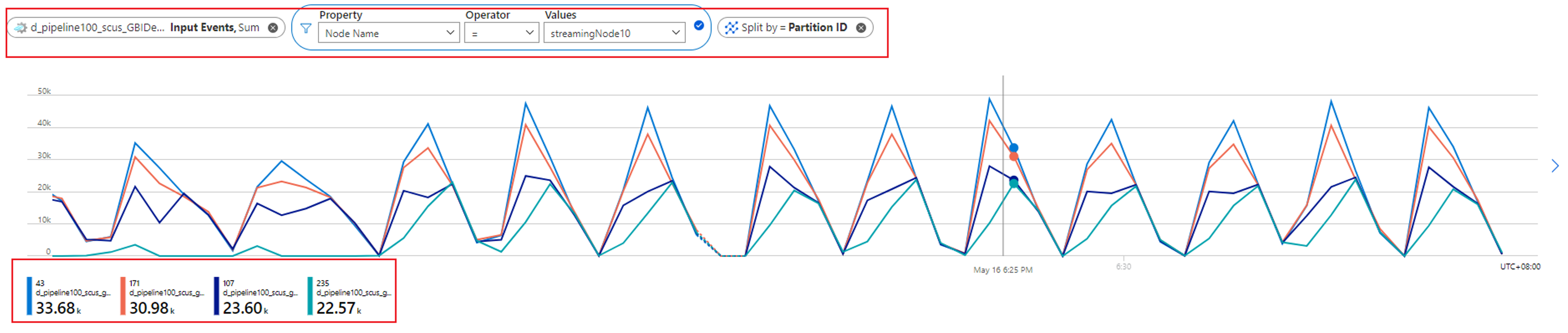
先のスクリーンショットは、ストリーミング ノード リソースの約 90 から 100% を占める、あるストリーミング ノードに 4 つのパーティションが割り当てられていることを示しています。 他のストリーミング ノードも同様のアプローチでチェックし、それらが 4 つのパーティションからのデータも処理していることを確認できます。



他にどのようなアクションを実行できますか?
各ストリーミング ノードのパーティション数を減らして、各ストリーミング ノードの入力データを減らしたい場合があります。 これを実現するには、SU を 2 倍にして、各ストリーミング ノードが 2 つのパーティションからのデータを処理するようにします。 または、SU を 4 倍にして、各ストリーミング ノードで 1 つのパーティションのデータを処理することもできます。 SU の割り当てとストリーミング ノード数の関係については、「ストリーミング ユニットの理解と調整」を参照してください。
1 つのストリーミング ノードが 1 つのパーティションからのデータを処理しているにもかかわらず、透かしの遅延が増加する場合はどうすればよいのでしょうか。 パーティション数を増やして入力を再分割することにより、パーティションあたりのデータ量を減らします。 詳しくは、「再分割を使用して Azure Stream Analytics ジョブを最適化する」を参照してください。
物理ジョブ ダイアグラムでこの問題をデバッグすることもできます。「物理ジョブ ダイアグラム: オーバーロードされた CPU またはメモリの原因を特定する」を参照してください。
次の手順
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示