クラウドとAzure IoT Edgeの両方で利用できるAzure Stream Analyticsには、機械学習ベースの異常検出機能が組み込まれており、最も一般的に発生する 2 つの異常 (一時的な異常と永続的な異常) を監視するために使用できます。 AnomalyDetection_SpikeAndDip関数とAnomalyDetection_ChangePoint関数を使用すると、Stream Analytics ジョブで異常検出を直接実行できます。
機械学習モデルは、一様にサンプリングされた時系列を前提としています。 時系列が一様でない場合は、異常検出を呼び出す前にタンブリング ウィンドウを含む集計ステップを挿入します。
機械学習の操作では、現時点では季節性の傾向や多変量の相関関係はサポートされていません。
Azure Stream Analyticsでの機械学習を使用した異常検出
次のビデオでは、Azure Stream Analyticsの機械学習関数を使用して、リアルタイムで異常を検出する方法を示します。
モデルの動作
一般に、モデルの精度は、スライディング ウィンドウ内のデータが多いほど向上します。 指定されたスライディング ウィンドウ内のデータは、その時間枠の通常の値範囲の一部として扱われます。 このモデルは、現在のイベントが異常であるかどうかを確認するために、スライディング ウィンドウ上のイベント履歴のみを考慮します。 スライディング ウィンドウが移動すると、古い値はモデルのトレーニングから削除されます。
関数は、これまでに見たものに基づいて特定の基準を確立することによって動作します。 外れ値は、信頼水準内で確立された正規値と比較することによって識別されます。 ウィンドウ サイズは、異常が発生したときにそれを認識できるように、モデルを正常な動作にトレーニングするために必要な最小イベントに基づいている必要があります。
モデルの応答時間は、過去の多数のイベントと比較する必要があるため、履歴サイズとともに長くなります。 パフォーマンスを向上させるには、必要な数のイベントのみを含めます。
時系列のギャップは、モデルが特定の時点でイベントを受信しない場合に発生する可能性があります。 Stream Analytics は、補完ロジックを使用してこの状況を処理します。 履歴サイズと、同じスライディング ウィンドウの期間を使用して、イベントが到着すると予想される平均レートを計算します。
anomaly ジェネレーターを使用して、さまざまな異常パターンを含むデータをIoT Hubにフィードできます。 これらの異常検出関数を使用してこのIoT Hubから読み取り、異常を検出することで、Azure Stream Analytics ジョブを設定できます。
急上昇と急降下
時系列イベント ストリームの一時的な異常は、スパイクとディップと呼ばれます。 Machine Learning ベースの演算子 AnomalyDetection_SpikeAndDip を使用して異常なピークとディップを監視できます。
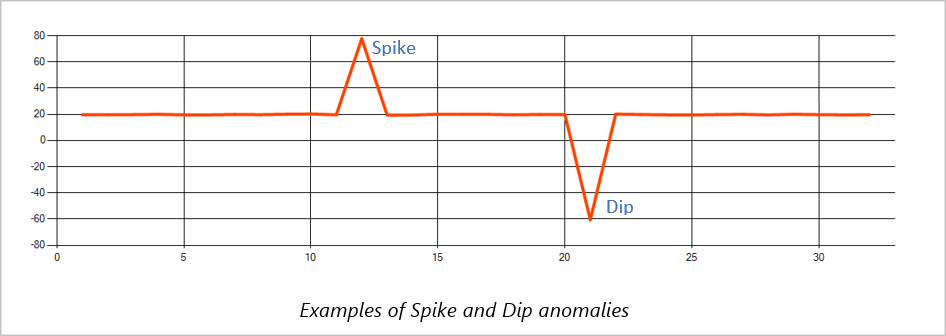
同じスライディング ウィンドウで、2 番目のスパイクが最初のスパイクよりも小さい場合、小さいスパイクの計算スコアは、指定された信頼度レベル内の最初のスパイクのスコアと比較して十分に有意でない可能性があります。 モデルの信頼度を下げてみて、このような異常を検出できます。 ただし、アラートが多くなりすぎる場合は、より高い信頼区間を使用します。
次のクエリ例では、120 イベントの履歴を持つ 2 分間のスライディング ウィンドウで 1 秒あたり 1 イベントの均一な入力レートを想定しています。 最後の SELECT ステートメントは、スコアと異常ステータスを 95%の信頼度で抽出して出力します。
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
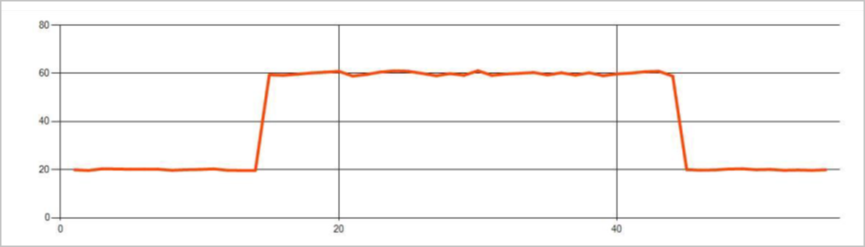
変更点
時系列イベント ストリームの永続的な異常は、レベルの変化や傾向など、イベント ストリーム内の値の分布の変化です。 Stream Analytics では、Machine Learning ベースの AnomalyDetection_ChangePoint 演算子はこれらの異常を検出します。
持続的な変化は、急上昇や急降下よりもはるかに長く続き、壊滅的なイベントを示している可能性があります。 永続的な変更は通常、肉眼では見えませんが、 AnomalyDetection_ChangePoint オペレーターはそれらを検出できます。
次の図は、レベル変更の例です。
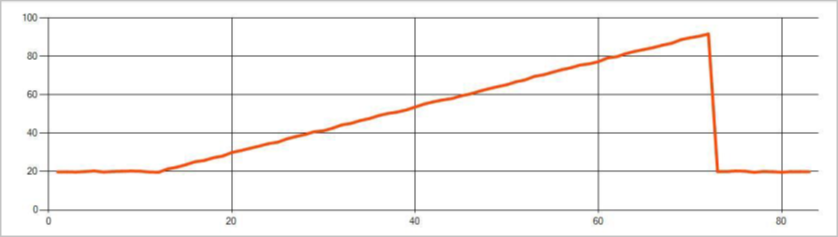
次の図は、トレンドの変化の例です。
次のクエリ例では、履歴サイズが 1,200 イベントの 20 分間のスライディング ウィンドウで 1 秒あたり 1 イベントの均一な入力レートを想定しています。 最後の SELECT ステートメントは、スコアと異常ステータスを 80%の信頼度で抽出して出力します。
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
パフォーマンス特性
これらのモデルのパフォーマンスは、履歴サイズ、ウィンドウ期間、イベント負荷、および関数レベルのパーティション分割が使用されているかどうかによって異なります。 このセクションでは、これらの構成について説明し、1 K、5 K、および 10 K イベント/秒のインジェスト率を維持する方法のサンプルを提供します。
- 履歴サイズ - これらのモデルは 履歴サイズと共に直線的に実行されます。 履歴サイズが長いほど、モデルが新しいイベントをスコアリングするのにかかる時間が長くなります。 モデルは、新しいイベントを履歴バッファー内の過去の各イベントと比較します。
- ウィンドウ期間 - ウィンドウ 期間は、履歴サイズで指定された数のイベントを受信するのにかかる時間を反映する必要があります。 ウィンドウに十分なイベントがない場合、Azure Stream Analyticsは欠損値を補完することで対処します。 したがって、CPU 消費量は履歴サイズの関数です。
- イベントの負荷 - イベントの負荷が大きいほど、モデルが実行する作業が多くなり、CPU の消費に影響します。 ビジネス ロジックで入力パーティションを増やせると仮定すれば、ジョブを驚異的並列にすることでスケール アウトできます。
-
関数レベルのパーティション分割 - 異常検出関数呼び出し内の
PARTITION BYを使用して 、関数レベルのパーティション分割を実行します。 この種類のパーティション分割は、ジョブが複数のモデルの状態を同時に維持する必要がある場合にオーバーヘッドを増やします。 デバイス レベルのパーティション分割などのシナリオでは、関数レベルのパーティション分割を使用します。
リレーションシップ
履歴サイズ、ウィンドウ期間、および合計イベント負荷は、次のように関連しています。
windowDuration (ミリ秒単位) = 1000 * historySize / (1 秒あたりの合計入力イベント / 入力パーティション数)
deviceId で関数を分割する場合は、異常検出関数呼び出しに "PARTITION BY deviceId" を追加します。
所見
次の表は、パーティション分割されていない場合の単一ノード (6 SU) のスループットの観測値を示しています。
| 履歴サイズ(イベント) | ウィンドウ期間 (ミリ秒) | 1 秒あたりの合計入力イベント |
|---|---|---|
| 六十 | 55 | 2,200 |
| 600 | 728 | 1,650 |
| 6,000 | 10,910 | 1,100 |
次の表は、パーティション分割されたケースの単一ノード (6 SU) のスループットの観察結果を示しています。
| 履歴サイズ(イベント) | ウィンドウ期間 (ミリ秒) | 1 秒あたりの合計入力イベント | デバイス数 |
|---|---|---|---|
| 六十 | 1,091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6,000 | 218,182 | <550 | 10 |
| 六十 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6,000 | 2,181,819 | <550 | 100 |
非パーティション構成を実行するサンプル コードは、Azure サンプルの Streaming At Scale リポジトリにあります。 このコードでは、Event Hubs を入力と出力として使用する関数レベルのパーティション分割を使用しない Stream Analytics ジョブを作成します。 テスト クライアントによって入力負荷が生成されます。 各入力イベントは 1 KB の JSON ドキュメントです。 このイベントは、JSON データを送信する IoT デバイスをシミュレートします (最大 1 K デバイス)。 履歴のサイズ、ウィンドウの期間、イベントの合計負荷は、2 つの入力パーティションによって異なります。
注
見積もりの精度を高めるには、ご使用のシナリオに合わせてサンプルをカスタマイズしてください。
ボトルネックの特定
パイプラインのボトルネックを特定するには、Azure Stream Analytics ジョブの [メトリック] ウィンドウを使用します。 スループットと "基準値の遅延" またはバックログイベントの入力/出力イベントを確認して、ジョブが入力レートに追いついているかどうかを確認します。 Event Hubs メトリックについては、抑制された要求を探し、それに応じてしきい値ユニットを設定します。 Azure Cosmos DBメトリックの場合は、スループットの下で各パーティション キー範囲における最大消費 RU/秒を確認し、パーティション キー範囲が均一に消費されていることを確認します。 Azure SQL DB の場合は、Log IO および CPU を監視します。