Azure Synapse Data Explorer のデータ インジェストの概要 (プレビュー)
データ インジェストとは、Azure Synapse Data Explorer プールで 1 つまたは複数のソースからデータ レコードを読み込んで、テーブルにデータをインポートするプロセスのことです。 取り込まれたデータは、クエリに使用できるようになります。
データ インジェストを担当する Azure Synapse Data Explorer のデータ管理サービスは、次のプロセスを実行します。
- 外部ソースからバッチまたはストリーミングでデータをプルし、保留中の Azure キューから要求を読み取ります。
- 同じデータベースおよびテーブルに送られるバッチ データは、インジェストのスループット向けに最適化されます。
- 初期データが検証され、必要に応じて形式が変換されます。
- スキーマの照合、データの整理、インデックス付け、エンコード、圧縮など、その他のデータ操作。
- データは、設定されたアイテム保持ポリシーに従ってストレージに保存されます。
- 取り込まれたデータは、エンジンにコミットされます。このエンジンで、クエリのためにそのデータを使用できます。
サポートされるデータ形式、プロパティ、およびアクセス許可
インジェストのプロパティ :データの取り込まれる方法に影響を与えるプロパティ (タグ付け、マッピング、作成時間など)。
アクセス許可:データを取り込むプロセスでは、データベース インジェスター レベルのアクセス許可が必要です。 クエリなどの他の操作では、データベース管理者、データベース ユーザー、またはテーブル管理者のアクセス許可が必要になる場合があります。
バッチ処理とストリーミングのインジェスト
バッチ処理インジェストでは、データのバッチ処理が行われ、高インジェスト スループットのために最適化されます。 この方法は、推奨される、最もパフォーマンスの高い種類のインジェストです。 データはインジェスト プロパティに従ってバッチ処理されます。 データの小さなバッチはマージされ、高速クエリの結果用に最適化されます。 インジェスト バッチ ポリシーは、データベースまたはテーブルに対して設定できます。 既定では、バッチ処理の最大値は、5 分、1000 項目、または合計サイズ1 GB です。 バッチ インジェスト コマンドのデータ サイズ制限は 4 GB です。
ストリーミング インジェスト は、ストリーミング ソースからの継続的なデータ インジェストです。 ストリーミング インジェストを使用すると、テーブルごとに少量のデータ セットに対してほぼリアルタイムの待機時間を実現できます。 データは最初に行ストアに取り込まれ、次に列ストアのエクステントに移動されます。
インジェストの方法とツール
Azure Synapse Data Explorer では複数のインジェスト方法がサポートされており、それぞれに固有のターゲット シナリオがあります。 これらの方法には、インジェスト ツール、さまざまなサービスへのコネクタとプラグイン、マネージド パイプライン、SDK を使用したプログラムによる取り込み、インジェストへの直接アクセスなどがあります。
マネージド パイプラインを使用したインジェスト
外部サービスによって実行される管理 (調整、再試行、監視、アラートなど) を必要とする組織では、コネクタを使用するのが最も適切なソリューションである可能性があります。 キューによるインジェストは、大量のデータに適しています。 Azure Synapse Data Explorer では、次の Azure Pipelines がサポートされています。
- イベント ハブ : サービスから Azure Synapse Data Explorer にイベントを転送するパイプライン。 詳しくは、「イベント ハブから Azure Synapse Data Explorer にデータを取り込む」を参照してください。
- Synapse パイプライン: Synapse パイプラインの分析ワークロード用のフル マネージド データ統合サービスは、90 を超えるサポートされるソースに接続して、効率的で回復性があるデータ転送を提供します。 Synapse パイプラインでは、さまざまな方法で監視できる分析情報を提供するために、データが準備、変換、強化されます。 このサービスは、1 回限りのソリューションとして、または定期的なタイムラインで使用したり、特定のイベントによってトリガーしたりすることができます。
SDK を使用したプログラムによるインジェスト
Azure Synapse Data Explorer では、クエリとデータ インジェストに使用できる SDK が提供されています。 プログラムによるインジェストは、インジェスト プロセスの最中および後のストレージ トランザクションを最小限に抑えることによって、インジェスト コスト (COG) を削減するように最適化されています。
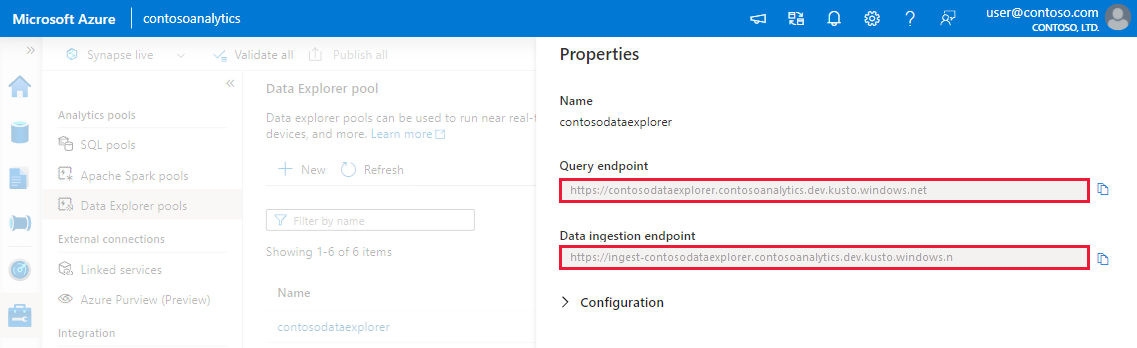
開始する前に、次の手順を使用して、プログラムによるインジェストを構成するための Data Explorer プール エンドポイントを取得します。
Synapse Studio の左側のペインで、 [管理]>[Data Explorer プール] を選びます。
詳細を表示する データ エクスプローラー プールを選択します。
![既存のプールの一覧が表示されている [Data Explorer プール] 画面のスクリーンショット。](../media/ingest-data-pipeline/select-data-explorer-pool.png)
クエリとデータ インジェストのエンドポイントをメモします。 データ エクスプローラー プールへの接続を構成するときに、クラスターとしてクエリ エンドポイントを使用します。 データ インジェスト用に SDK を構成する場合は、データ インジェスト エンドポイントを使用します。
使用可能な SDK とオープン ソース プロジェクト
ツール
- ワンクリック インジェスト : さまざまな種類のソースからテーブルを作成および調整することにより、データを迅速に取り込むことができます。 ワンクリック インジェストでは、Azure Synapse Data Explorer 内のデータ ソースに基づいて、テーブルとマッピングの構造が自動的に提案されます。 ワンクリック インジェストは、1 回限りのインジェストに使用できます。また、データが取り込まれたコンテナーで Event Grid を使用した継続的インジェストを定義するために使用できます。
Kusto クエリ言語の取り込み制御コマンド
Kusto クエリ言語 (KQL) のコマンドを使用してデータをエンジンに直接取り込む方法は多数あります。 この方法ではデータ管理サービスがバイパスされるため、これは探索およびプロトタイプにのみ適しています。 運用環境または大規模なシナリオでは、この方法を使用しないでください。
インライン インジェスト: 取り込まれるデータをコマンド テキスト自体の一部として、制御コマンド .ingest inline がエンジンに送信されます。 この方法は、即席のテストを目的としたものです。
クエリからの取り込み:クエリまたはコマンドの結果としてデータを間接的に指定し、制御コマンド .set、.append、.set-or-append、または .set-or-replace がエンジンに送信されます。
ストレージからの取り込み (プル) :エンジンによってアクセス可能であり、コマンドで指定された外部ストレージ (Azure Blob Storage など) にデータを格納して、制御コマンド .ingest into がエンジンに送信されます。
取り込み制御コマンドの使用例については、「Data Explorer を使用して分析する」を参照してください。
インジェスト プロセス
ニーズに最も適したインジェスト方法を選択したら、次の手順を実行します。
保持ポリシーを設定する
Azure Synapse Data Explorer のテーブルに取り込まれたデータは、テーブルの有効な保持ポリシーの対象となります。 テーブルに明示的に設定しない限り、有効な保持ポリシーはデータベースの保持ポリシーから取得されます。 ホット リテンションは、クラスター サイズと保持ポリシーの機能です。 使用可能な領域よりも多くのデータを取り込むと、最初のデータにコールド リテンションが適用されます。
データベースの保持ポリシーがご自分のニーズに適していることを確認してください。 適していない場合は、テーブル レベルで明示的にオーバーライドします。 詳細については、「保持ポリシー」を参照してください。
テーブルの作成
データを取り込むためには、事前にテーブルを作成する必要があります。 次のいずれかのオプションを使用します。
コマンドを使用してテーブルを作成します。 テーブルの作成コマンドの使用例については、「Data Explorer を使用して分析する」を参照してください。
ワンクリック インジェストを使用してテーブルを作成します。
注意
レコードが不完全な場合、またはフィールドを必要なデータ型として解析できない場合は、対応するテーブル列に null 値が設定されます。
スキーマ マッピングの作成
スキーマ マッピングは、ソースのデータ フィールドをターゲットのテーブル列にバインドするのに役立ちます。 マッピングを使用すると、定義された属性に基づいて、異なるソースから同じテーブルにデータを取り込むことができます。 行指向 (CSV、JSON、AVRO) と列指向 (Parquet) の両方で、さまざまな種類のマッピングがサポートされています。 ほとんどの方法では、マッピングをテーブルで事前に作成して、取り込みコマンドのパラメーターから参照することもできます。
更新ポリシーの設定 (省略可能)
一部のデータ形式マッピング (Parquet、JSON、Avro) では、簡単で便利な取り込み時の変換がサポートされています。 取り込み時により複雑な処理を必要とするシナリオでは、更新ポリシーを使用します。これにより、Kusto クエリ言語コマンドを使用した簡易処理が可能になります。 更新ポリシーでは、元のテーブルの取り込まれたデータに対して抽出と変換が自動的に実行され、結果のデータが 1 つ以上の宛先テーブルに取り込まれます。 更新ポリシーを設定します。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示