チュートリアル: Azure Machine Learning での Azure Synapse ADLS Gen2 データへのアクセス
このチュートリアルでは、Azure Machine Learning (Azure Machine Learning) から Azure Synapse Azure Data Lake Storage Gen2 (ADLS Gen2) の格納データにアクセスするプロセスについて説明します。 Azure Machine Learning で利用できる自動 ML などのツール、統合モデルと実験追跡、または GPU などの特殊なハードウェアを活用して機械学習ワークフローの合理化を目指す場合に、この機能は特に役立ちます。
Azure Machine Learning で ADLS Gen2 データにアクセスするために、Azure Synapse ADLS Gen2 ストレージ アカウントを参照する Azure Machine Learning データストアを作成します。
前提条件
- Azure Synapse Analytics ワークスペース。 Azure Data Lake Storage Gen2 ストレージ アカウントが既定のストレージとして構成されていることを確認します。 必ず、Data Lake Storage Gen2 ファイル システムの Storage Blob データ共同作成者として作業してください。
- Azure Machine Learning ワークスペース。
ライブラリのインストール
最初に、azure-ai-ml パッケージをインストールします。
%pip install azure-ai-ml
データストアを作成する
Azure Machine Learning には、データストアと呼ばれる機能が用意されています。これは既存の Azure ストレージ アカウントへの参照として機能します。 ここでは、Azure Synapse ADLS Gen2 ストレージ アカウントを参照するデータストアを作成します。
この例では、Azure Synapse ADLS Gen2 ストレージにリンクするデータストアを作成します。 MLClient オブジェクトを初期化した後、ADLS Gen2 アカウントへの接続の詳細を指定できます。 最後に、コードを実行してデータストアを作成または更新できます。
from azure.ai.ml.entities import AzureDataLakeGen2Datastore
from azure.ai.ml import MLClient
ml_client = MLClient.from_config()
# Provide the connection details to your Azure Synapse ADLSg2 storage account
store = AzureDataLakeGen2Datastore(
name="",
description="",
account_name="",
filesystem=""
)
ml_client.create_or_update(store)
Azure Machine Learning データストアの作成と管理について詳しくは、こちらの Azure Machine Learning データ ストアに関するチュートリアルを参照してください。
ADLS Gen2 ストレージ アカウントをマウントする
データ ストアを設定したら、ADLSg2 アカウントへのマウントを作成することで、そのデータにアクセスできるようになります。 Azure Machine Learning で ADLS Gen2 アカウントへのマウントを作成するには、ワークスペースとストレージ アカウントの間に直接リンクを確立し、格納データにシームレスにアクセスできるようにする必要があります。 マウントは本質的に、Azure Machine Learning が ADLS Gen2 アカウントのファイルとフォルダーを、ワークスペース内のローカル ファイルシステムの一部であるかのように操作できるようにするための経路として機能します。
ストレージ アカウントのマウント後は、Azure Machine Learning 環境内で直接使い慣れたファイルシステム操作を使って、ADLS Gen2 に格納されているデータの読み取り、書き込み、操作を簡単に実行できます。これにより、データの前処理、モデルのトレーニング、実験のタスクが簡素化されます。
手順は次のとおりです。
コンピューティング エンジンを起動します。
[データ アクション] を選択し、[マウント] を選択します。
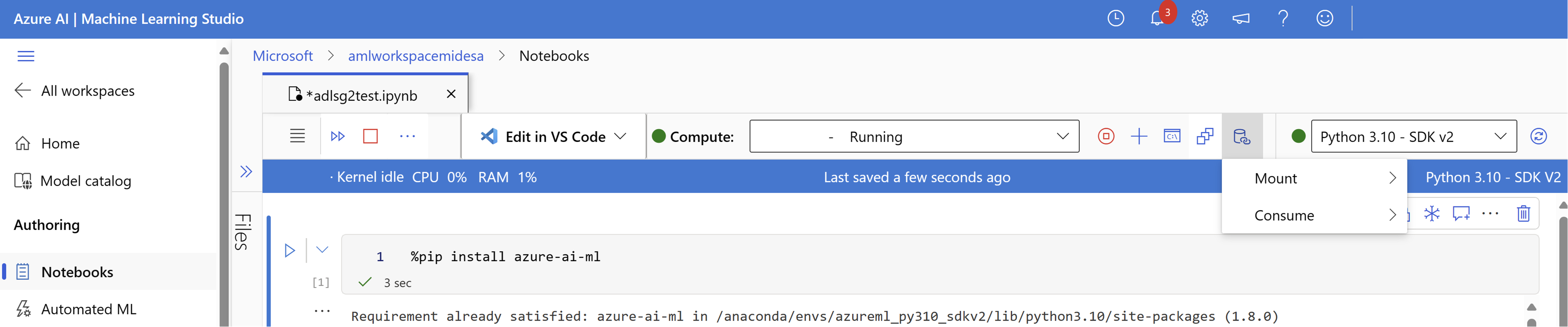
そこから、使用する ADLSg2 ストレージ アカウントの名前を確認して選択します。 マウントが作成されるまでに少し時間がかかる場合があります。
マウントの準備ができたら、[データ アクション] を選択して [使用] を選択できます。 その後、[データ] で、データを使用するマウントを選択できます。
これで、お好みのライブラリを使って、マウントされた Azure Data Lake Storage アカウントから直接データを読み取ることができるようになりました。
ストレージ アカウントからデータを読み取る
import os
# List the files in the mounted path
print(os.listdir("/home/azureuser/cloudfiles/data/datastore/{name of mount}"))
# Get the path of your file and load the data using your preferred libraries
import pandas as pd
df = pd.read_csv("/home/azureuser/cloudfiles/data/datastore/{name of mount}/{file name}")
print(df.head(5))