Synapse Spark プールに外部 Hive メタストアを使用する
Note
外部 Hive メタストアは、Azure Synapse Runtime for Apache Spark 3.4 以降のバージョンの Synapse ではサポートされなくなります。
Azure Synapse Analytics では、同じワークスペース上の Apache Spark プール間で、マネージド HMS (Hive メタストア) 互換メタストアをカタログとして共有できます。 お客様が Hive カタログ メタデータをワークスペースの外部に保持し、カタログ オブジェクトをワークスペース外の他の計算エンジン (HDInsight や Azure Databricks など) と共有したい場合は、外部 Hive メタストアに接続できます。 この記事では、Synapse Spark を外部 Apache Hive メタストアに接続する方法を学ぶことができます。
サポートされている Hive メタストアのバージョン
この機能は Spark 3.1 で動作します。 次のテーブルに、Spark の各バージョンでサポートされている Hive メタストアのバージョンを記載します。
| Spark バージョン | HMS 2.3.x | HMS 3.1.X |
|---|---|---|
| 3.3 | はい | はい |
リンク サービスを Hive メタストアに設定する
注意
外部 Hive メタストアとしてサポートされているのは、Azure SQL Database と Azure Database for MySQL だけです。 また、現時点で、ユーザー/パスワード認証のみがサポートされています。 指定されたデータベースが空の場合は、Hive スキーマ ツールを介してそれをプロビジョニングし、データベース スキーマを作成してください。
次の手順に従って、Synapse ワークスペースで外部 Hive メタストアへのリンク サービスを設定します。
Synapse Studio を開き、左側の [Manage](管理) > [Linked services](リンク サービス) に移動し、[New](新規) をクリックして新しいリンク サービスを作成します。
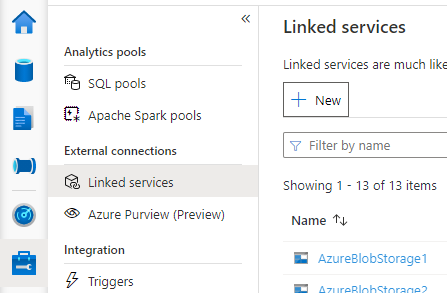
お使いのデータベースの種類に基づいて、[Azure SQL Database] または [Azure Database for MySQL] を選択し、[Continue](続行) をクリックします。
リンク サービスの [Name](名前) を入力します。 リンク サービスの名前を控えます。この情報はすぐ後で Spark の構成に使用します。
Azure サブスクリプションの一覧から、外部 Hive メタストアとして [Azure SQL Database]/[Azure Database for MySQL] を選択するか、この情報を手動で入力します。
[User name](ユーザー名) と [Password](パスワード) を入力して接続をセットアップします。
接続をテスト (Test connection) して、ユーザー名とパスワードが有効であることを確認します。
[Create](作成) をクリックしてリンク サービスを作成します。
接続をテストし、ノートブックでメタストアのバージョンを取得する
ネットワークによっては、Spark プールから外部 Hive メタストア DB へのアクセスを遮断するよう、セキュリティ規則を設定している場合があります。 Spark プールを設定する前に、任意の Spark プール ノートブックで下のコードを実行して、外部 Hive メタストア DB への接続をテストします。
その出力結果から Hive メタストアのバージョンも取得できます。 Hive メタストアのバージョンは Spark の構成で使用します。
Azure SQL の接続テスト コード
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure SQL database > Connection strings > JDBC **/
val url = s"jdbc:sqlserver://{your_servername_here}.database.windows.net:1433;database={your_database_here};user={your_username_here};password={your_password_here};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"
try {
val connection = DriverManager.getConnection(url)
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
Azure Database for MySQL の接続テスト コード
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure Database for MySQL > Connection strings > JDBC **/
val url = s"jdbc:mysql://{your_servername_here}.mysql.database.azure.com:3306/{your_database_here}?useSSL=true"
try {
val connection = DriverManager.getConnection(url, "{your_username_here}", "{your_password_here}");
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
外部 Hive メタストアを使用するように Spark を構成する
外部 Hive メタストアへのリンク サービスを正常に作成したら、その外部 Hive メタストアを使用するために、いくつかの Spark 構成を設定する必要があります。 Spark プール単位でも、Spark セッション単位でも、構成を設定できます。
以下は、構成とその説明です。
注意
Synapse は、HDI からのコンピューティングとスムーズに連携することを目的としています。 ただし、HDI 4.0 の HMS 3.1 は、OSS HMS 3.1 と完全な互換性があるわけではありません。 OSS HMS 3.1 については、こちらを確認してください。
| Spark の構成 | 説明 |
|---|---|
spark.sql.hive.metastore.version |
サポート対象のバージョン:
|
spark.sql.hive.metastore.jars |
|
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name |
リンク サービスの名前 |
spark.sql.hive.metastore.sharedPrefixes |
com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas |
Spark プール レベルで構成する
Spark プールを作成するときは、 [Additional Settings](追加設定) タブの [Apache Spark configuration](Apache Spark の構成) セクションで、下の構成を書き込んだテキスト ファイルをアップロードします。 既存の Spark プールのコンテキスト メニューでも、Apache Spark の構成を選択してこれらの構成に追加できます。
メタストアのバージョンとリンク サービスの名前を更新し、Spark プールの構成に使用するテキスト ファイルに下の構成を書き込んで保存します。
spark.sql.hive.metastore.version <your hms version, Make sure you use the first 2 parts without the 3rd part>
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name <your linked service name>
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas
メタストア バージョン 2.3 を、HiveCatalog21 という名前のリンク サービスとともに使用する例を次に示します。
spark.sql.hive.metastore.version 2.3
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name HiveCatalog21
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas
Spark セッション レベルで構成する
ノートブック セッションでは、%%configure マジック コマンドを使用して、ノートブックで Spark セッションを構成することもできます。 次にコードを示します。
%%configure -f
{
"conf":{
"spark.sql.hive.metastore.version":"<your hms version, 2 parts>",
"spark.hadoop.hive.synapse.externalmetastore.linkedservice.name":"<your linked service name>",
"spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*",
"spark.sql.hive.metastore.sharedPrefixes":"com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas"
}
}
バッチ ジョブでは、SparkConf を介して同じ構成を適用することもできます。
クエリを実行して接続を確認する
これらすべての設定を終えたら、Spark ノートブックで下のクエリを実行してカタログ オブジェクトのリストを取得し、外部 Hive Metastore への接続を確認してみてください。
spark.sql("show databases").show()
ストレージの接続をセットアップする
Hive メタストア データベースへのリンク サービスでは、Hive カタログ メタデータへのアクセスだけが提供されます。 既存のテーブルに対するクエリを実行するには、Hive テーブルのデータ本体を保存しているストレージ アカウントへの接続をセットアップする必要があります。
Azure Data Lake Storage Gen 2 への接続を設定する
ワークスペース プライマリ ストレージ アカウント
Hive テーブルの基になるデータがワークスペース プライマリ ストレージ アカウントに格納されている場合、追加の設定を行う必要はありません。 ワークスペース作成時に、説明どおりストレージをセットアップすれば、問題なく機能します。
その他の ADLS Gen 2 アカウント
Hive カタログのデータ本体を他の ADLS Gen 2 アカウントに保存している場合は、Spark クエリを実行するユーザーが、ADLS Gen2 ストレージ アカウントで Storage Blob Data Contributer ロールを持っている必要があります。
Blob Storage への接続をセットアップする
Hive テーブルのデータの本体を Azure Blob ストレージ アカウントに保存している場合は、下の手順で接続をセットアップします。
Synapse Studio を開き、[Data](データ) > [Linked](リンク) タブ > [Add](追加) ボタン >[Connect to external data](外部データへの接続) の順に移動します。
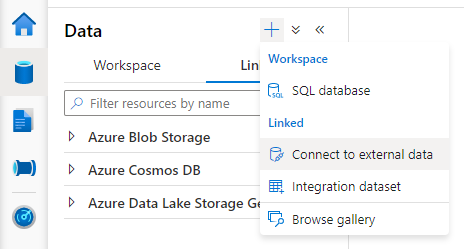
[Azure Blob Storage] を選択して [Continue](続行) をクリックします。
リンク サービスの [Name](名前) を入力します。 リンク サービスの名前をメモします。この情報は、すぐ後の Spark 構成で使用されます。
Azure Blob Storage アカウントを選択します。 認証方法を [Account key](アカウント キー) に設定します。 現在 Spark プールでは、アカウント キーでのみ Blob Storage アカウントにアクセスできます。
接続をテスト (Test connection) して、 [Create](作成) をクリックします。
Blob Storage アカウントのリンク サービスを作成した後、Spark クエリを実行するときは、ノートブックで下の Spark コードを実行し、Spark セッションを使用する Blob Storage アカウントへのアクセス権を取得してください。 この手順が必要な理由をここで説明しています。
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
ストレージの接続をセットアップしたら、Hive Metastore の既存のテーブルに対するクエリを実行できます。
既知の制限事項
- Synapse Studio オブジェクト エクスプローラーでは当面、外部 HMS の代わりにマネージド Synapse メタストアのオブジェクトを表示します。
- SQL <-> Spark 同期は、外部 HMS の使用中は機能しません。
- 外部 Hive メタストア データベースとしてサポートされているのは、Azure SQL Database と Azure Database for MySQL だけです。 認証には、SQL 認証だけをサポートしています。
- 現時点では、Spark は、外部 Hive テーブルと、非トランザクション/非 ACID マネージド Hive テーブルでのみ動作します。 Hive の ACID テーブルとトランザクション テーブルはサポートされていません。
- Apache Ranger との連携機能は実装していません。
トラブルシューティング
Blob Storage に保存したデータを取得するクエリを Hive テーブルに対して実行すると、下のエラーが発生する
No credentials found for account xxxxx.blob.core.windows.net in the configuration, and its container xxxxx is not accessible using anonymous credentials. Please check if the container exists first. If it is not publicly available, you have to provide account credentials.
リンク サービスを通じてストレージ アカウントにキー認証を使用する場合は、Spark セッションのトークンを取得する追加手順が必要です。 下のコードを実行して Spark セッションを設定してから、クエリを実行します。 この手順が必要な理由をここで説明しています。
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
ADLS Gen2 アカウントに保存したテーブルに対してクエリを実行すると、下のエラーが発生する
Operation failed: "This request is not authorized to perform this operation using this permission.", 403, HEAD
これは、Spark クエリを実行するユーザーが、基になるストレージ アカウントへの十分なアクセス権を持っていないために発生することがあります。 Spark クエリを実行するユーザーが、ADLS Gen2 ストレージ アカウントで Storage Blob Data Contributor ロールを持っていることを確認してください。 このステップは、リンク サービスの作成後に実行できます。
HMS スキーマに関する設定
HMS のバックエンド スキーマおよびバージョンが変更されることを避けるため、次の hive 構成がシステムによって既定で設定されます。
spark.hadoop.hive.metastore.schema.verification true
spark.hadoop.hive.metastore.schema.verification.record.version false
spark.hadoop.datanucleus.fixedDatastore true
spark.hadoop.datanucleus.schema.autoCreateAll false
HMS のバージョンが 1.2.1 または 1.2.2 の場合は、spark.hadoop.hive.metastore.schema.verification を true に変更すると、Hive で 1.2.0 のみが要求される問題が発生します。 回避策として、HMS のバージョンを 1.2.0 に変更するか、次の 2 つの構成を上書きできます。
spark.hadoop.hive.metastore.schema.verification false
spark.hadoop.hive.synapse.externalmetastore.schema.usedefault false
HMS バージョンを変更する必要がある場合は、hive スキーマ ツールの使用をお勧めします。 また、HMS を HDInsight クラスターで使用している場合は、HDI に対応しているバージョンの使用をお勧めします。
OSS HMS 3.1 の HMS スキーマの変更
Synapse は、HDI からのコンピューティングとスムーズに連携することを目的としています。 ただし、HDI 4.0 の HMS 3.1 は、OSS HMS 3.1 と完全な互換性があるわけではありません。 そのため、HDI によってプロビジョニングされていない場合は、HMS 3.1 に次のコードを手動で適用してください。
-- HIVE-19416
ALTER TABLE TBLS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
ALTER TABLE PARTITIONS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
メタストアを HDInsight 4.0 Spark クラスターで共有したときに、テーブルが表示されない
Hive カタログを HDInsiht 4.0 の spark クラスターで共有する場合は、Synapse spark の spark.hadoop.metastore.catalog.default プロパティが HDInsight spark の値に正しく対応していることを確認してください。 HDI Spark の既定値は spark、Synapse Spark の既定値は hive です。
Hive メタストアを HDInsight 4.0 Hive クラスターで共有したときに、テーブルのリストは正常に表示されるが、テーブルに対するクエリを実行すると空の結果しか取得できない
制限事項で説明したように、Synapse Spark プールでは、外部 Hive テーブルと、トランザクション以外の ACID マネージド以外のテーブルのみがサポートされ、Hive の ACID テーブルとトランザクション テーブルは現在サポートされていません。 HDInsight 4.0 Hive クラスターでは、既定ですべてのマネージド テーブルが ACID テーブルまたはトランザクション テーブルとして作成されます。それらのテーブルに対してクエリを実行すると空の結果が得られるのはそのためです。
次のインテリジェント キャッシュが有効になっているときに外部メタストアが使用される場合のエラーを参照してください
java.lang.ClassNotFoundException: Class com.microsoft.vegas.vfs.SecureVegasFileSystem not found
/usr/hdp/current/hadoop-client/* を spark.sql.hive.metastore.jars に追加することで、簡単にこの問題を修正できます。
Eg:
spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-client/*