この記事では、拡張された Apache Spark History Server を使用して、完成して実行されている Spark アプリケーションのデバッグおよび診断を行う方法に関するガイダンスを提供します。
拡張機能には、[データ] タブ、[グラフ] タブ、[診断] タブが含まれています。 [データ] タブを使用して、Spark ジョブの入力データと出力データをチェックします。 [グラフ] タブでは、ジョブ グラフのデータ フローと再生が示されます。 [診断] タブには、[データ スキュー]、[Time Skew](時間のずれ)、および [Executor Usage Analysis](実行プログラムの使用状況の分析) が含まれます。
Apache Spark History Server へのアクセス
Apache Spark History Server は、完了および実行中の Spark アプリケーションの Web ユーザー インターフェイスです。 Apache Spark History Server Web インターフェイスは、Azure Synapse Analytics から開くことができます。
Spark History Server Web UI を Apache Spark アプリケーション ノードから開く
Azure Synapse Analytics を開きます。
[モニター] を選択し、次に [Apache Spark アプリケーション] を選択します。
アプリケーションを選択し、 [ログ クエリ] を選択して開きます。
Spark History Server を選択すると、Spark History Server Web UI が表示されます。 実行中の Spark アプリケーションの場合、ボタンは [Spark UI] です。
Spark History Server Web UI をデータ ノードから開く
Synapse Studio ノートブックで、ジョブ実行出力セルから、またはノートブック ドキュメントの下部にある状態パネルから、 [Spark History Server] を選択します。 [セッション詳細] を選択します。

スライドアウト パネルから [Spark History Server] を選択します。

Apache Spark History Server の [グラフ] タブ
表示するジョブのジョブ ID を選択します。 ツール メニューの [グラフ] を選択して、ジョブ グラフ ビューを取得します。
概要
生成されたジョブ グラフで、ジョブの概要を表示できます。 既定で、グラフにはすべてのジョブが表示されます。 ジョブ IDで、このビューをフィルター処理できます。
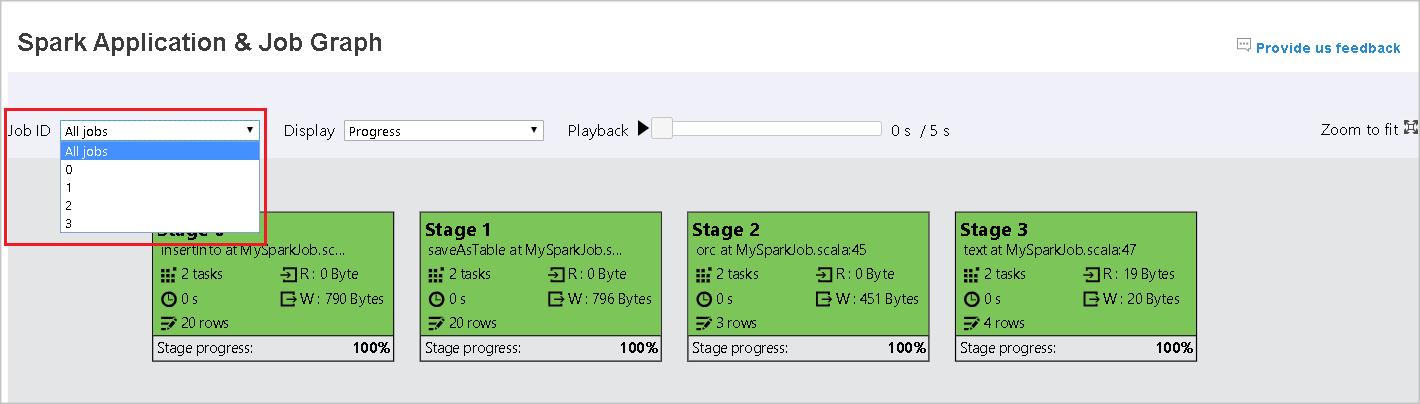
表示
既定で、 [進行状況] 表示が選択されています。 [表示] ドロップダウン リストで [読み取り] または [書き込み] を選択して、データ フローを確認できます。
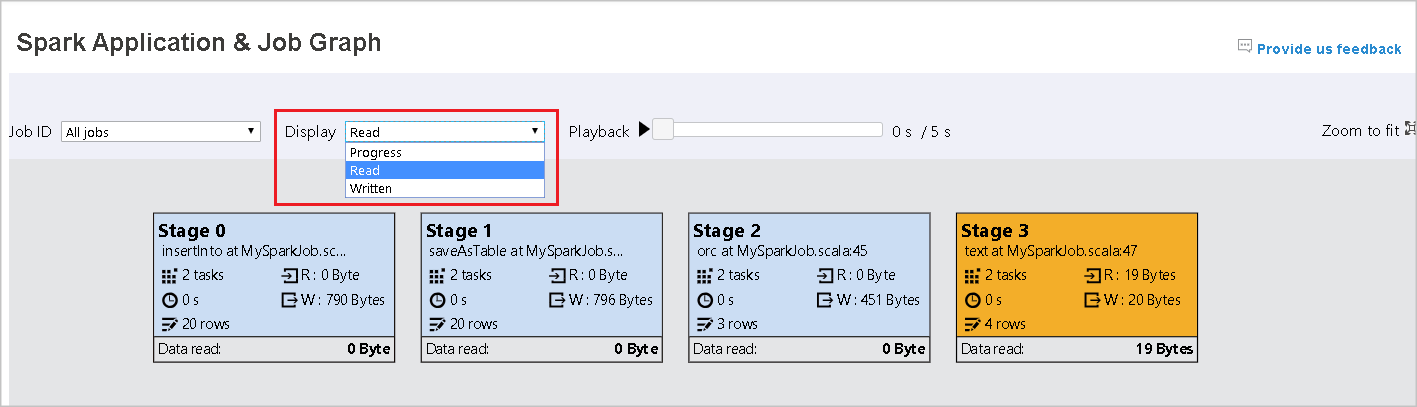
グラフ ノードに、ヒートマップの凡例に表示される色が表示されます。

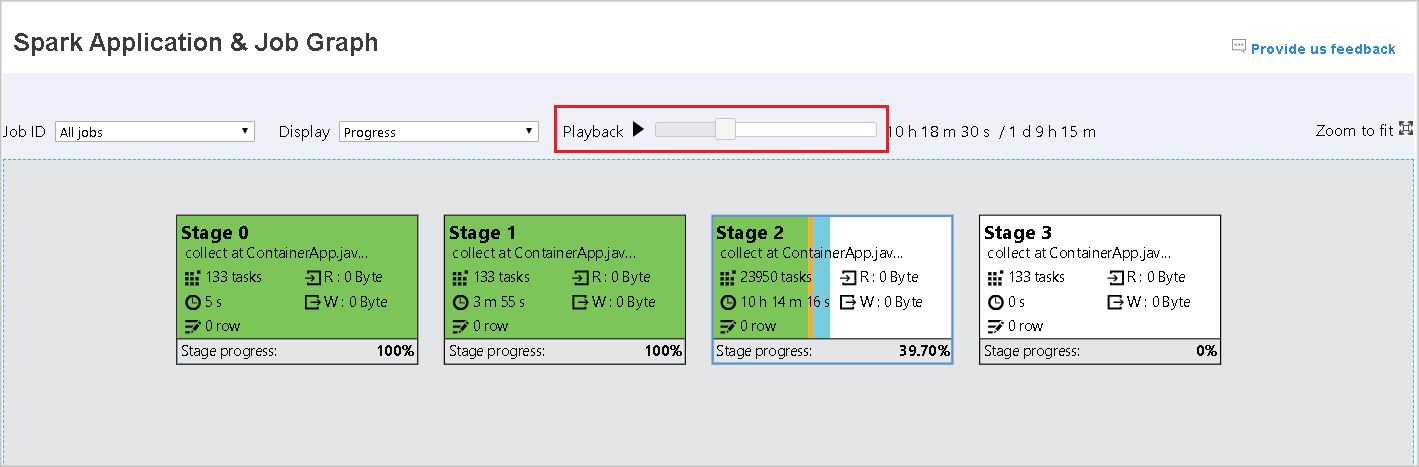
再生
ジョブを再生するには、 [再生] を選択します。 いつでも [停止] を選択して停止できます。 タスクの色は、再生時にさまざまな状態を示します。
| Color | 意味 |
|---|---|
| [緑] | Succeeded (成功):ジョブは正常に完了しました。 |
| オレンジ | 再試行:失敗しましたが、ジョブの最終結果には影響しないタスクのインスタンス。 このようなタスクには、後で成功する可能性がある重複するインスタンスまたは再試行インスタンスがあります。 |
| 青 | Running (実行中):タスクは実行中です。 |
| White | 待機中またはスキップ:タスクは実行を待機しているか、ステージがスキップされました。 |
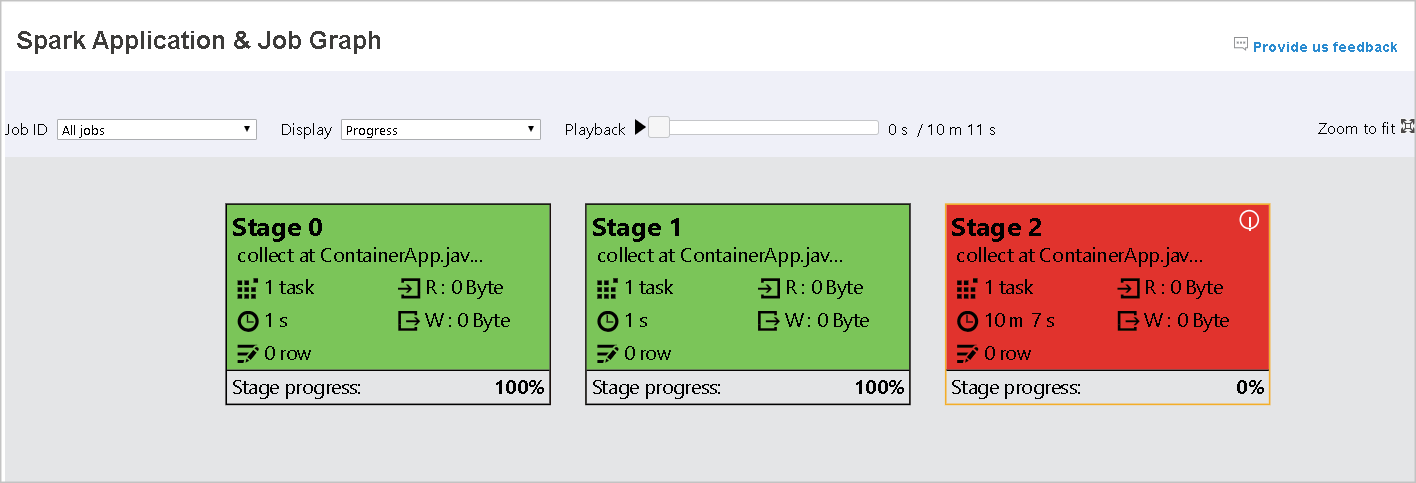
| [赤] | 失敗:タスクは失敗しました。 |
次の図に、緑、オレンジ色、青の状態の色を示しています。
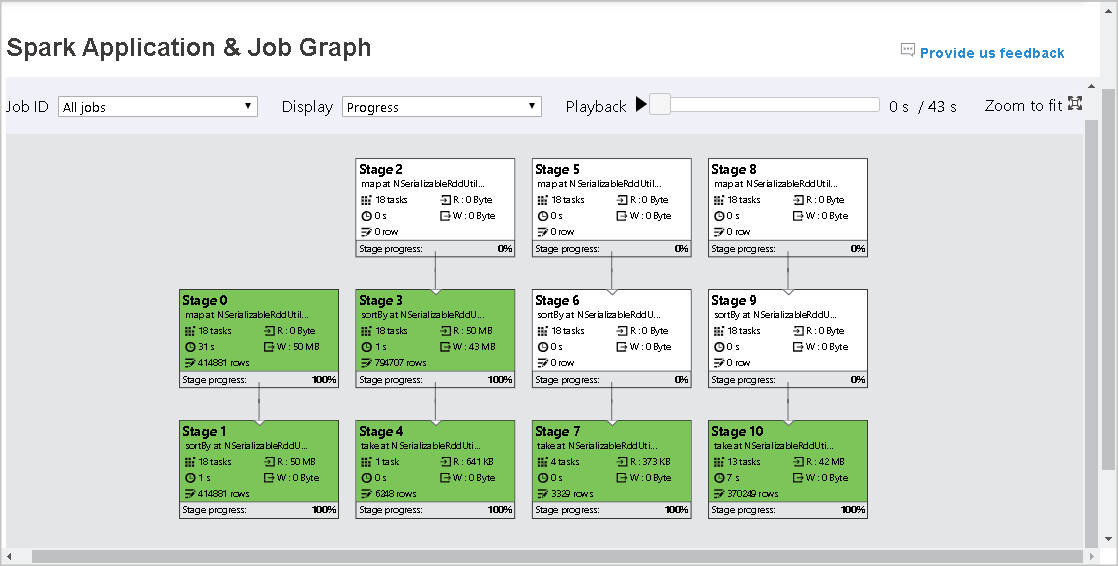
次の図に、緑と白の状態の色を示しています。
次の図に、赤と緑の状態の色を示しています。
注意
各ジョブを再生できます。 不完全なジョブでは、再生はサポートされていません。
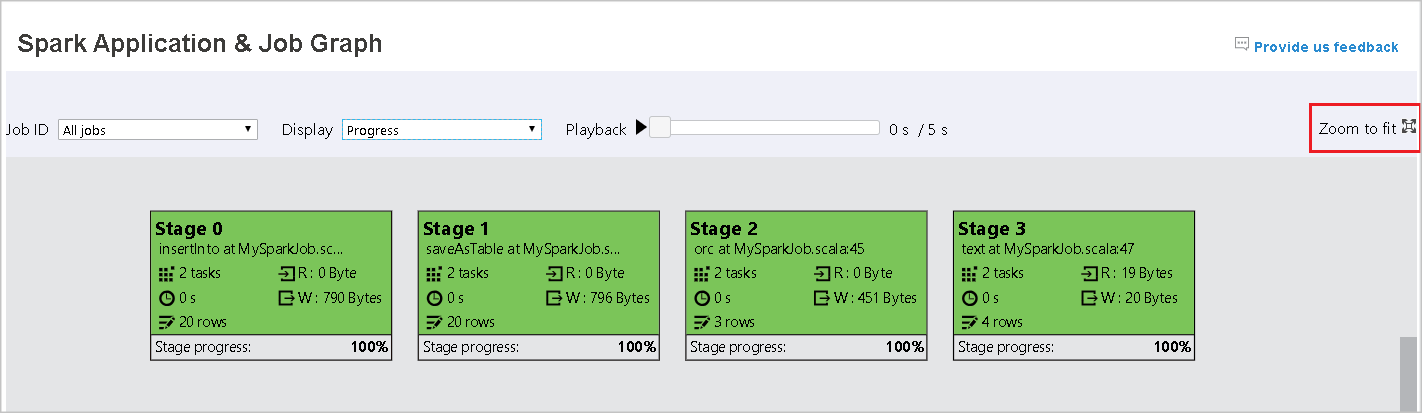
Zoom
ジョブ グラフを拡大または縮小するために、マウス スクロールを使用するか、画面に合わせるために、 [ウィンドウのサイズに合わせて大きさを変更] を選択します。
ツールヒント
失敗したタスクがある場合にツールヒントを表示するには、グラフ ノードをポイントし、ステージを選択して、そのステージ ページを開きます。
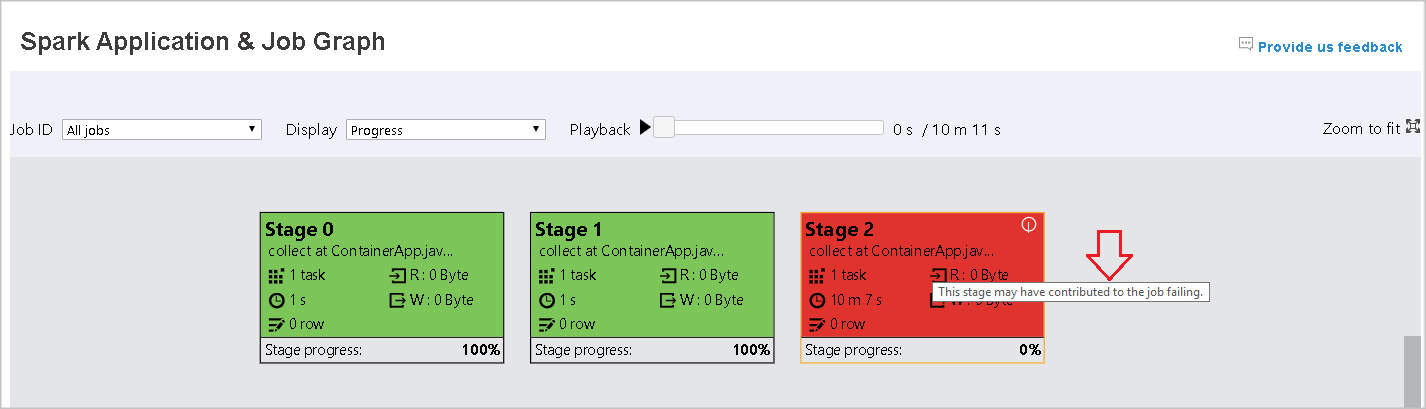
ジョブ グラフ タブで、次の条件を満たすタスクがある場合、ステージにはツールヒントと小さいアイコンが表示されます。
| 条件 | 説明 |
|---|---|
| データ スキュー | データの読み取りサイズ > このステージ内のすべてのタスクの平均データ読み取りサイズ * 2 かつデータ読み取りサイズ > 10 MB |
| 時間のずれ | 実行時間 > このステージ内のすべてのタスクの平均実行時間 * 2 かつ実行時間 > 2 分 |
![]()
グラフ ノードの説明
ジョブ グラフ ノードには、各ステージの次の情報が表示されます。
ID。
名前または説明。
合計タスク数。
データの読み取り: 入力サイズとシャッフル読み取りサイズの合計。
データ書き込み: 出力サイズとシャッフル書き込みサイズの合計。
実行時間: 最初の試行の開始時刻と最後の試行の完了時刻の間の時間。
行数: 入力レコード、出力レコード、シャッフル読み取りレコード、シャッフル書き込みレコードの合計。
進行状況。
注意
既定で、ジョブ グラフ ノードには各ステージの最後の試行の情報が表示されます (ステージの実行時間を除く)。 ただし、再生中は、グラフ ノードに各試行の情報が表示されます。
読み取りと書き込みのデータ サイズは、1 MB = 1000 KB = 1000 * 1000 バイトです。
フィードバックの提供
[フィードバックをお寄せください] を選択することで、問題のフィードバックを送信できます。
ステージ数の制限
パフォーマンスを考慮して、既定では、Spark アプリケーションのステージ数が 500 未満の場合にのみ、グラフを使用できます。 ステージが多すぎると、次のようなエラーで失敗します。
The number of stages in this application exceeds limit (500), graph page is disabled in this case.
これを回避するには、Spark アプリケーションを開始する前に、次の Spark 構成を適用して制限を引き上げてください。
spark.ui.enhancement.maxGraphStages 1000
ただし、このようにすると、ブラウザーでフェッチしてレンダリングするにはコンテンツが大きくなりすぎる場合があり、ページと API のパフォーマンスが低下する可能性があることに注意してください。
Apache Spark History Server の [診断] タブの探索
[診断] タブにアクセスするには、ジョブ ID を選択します。 次に、[ツール] メニューの [診断] を選択すると、ジョブの [診断] ビューが表示されます。 [Diagnosis](診断) タブには、 [Data Skew](データ スキュー) 、 [Time Skew](時間のずれ) 、および [Executor Usage Analysis](実行プログラムの使用状況の分析) が含まれます。
[Data Skew](データ スキュー) 、 [Time Skew](時間のずれ) 、および [Executor Usage Analysis](実行プログラムの使用状況の分析) を確認するには、各タブを選択します。
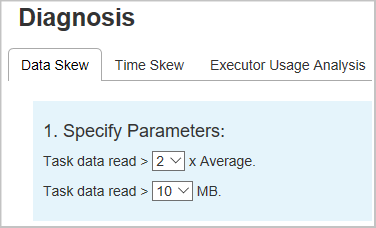
[Data Skew](データ スキュー)
[データ スキュー] タブを選択すると、指定されたパラメーターに基づいて、対応する偏りのあるタスクが表示されます。
[パラメーターの指定] - 最初のセクションには、データ スキューの検出に使用するパラメーターが表示されます。 既定の規則は次のとおりです。読み取られたタスク データが、読み取られたタスク データの平均量の 3 倍を超えており、なおかつ 10 MB を超えていることが指定されています。 傾斜したタスクに独自の規則を定義する場合は、パラメーターを選択できます。 [傾斜したステージ] と [スキュー グラフ] セクションは、それに応じて更新されます。
[傾斜したステージ] - 2 番目のセクションには、上記で指定した条件を満たす偏りのあるタスクがあるステージが表示されます。 ステージに偏りのあるタスクが複数ある場合、偏りのあるステージ テーブルには、最も偏りの大きなタスク (たとえば、データ スキューの最大データ) のみが表示されます。
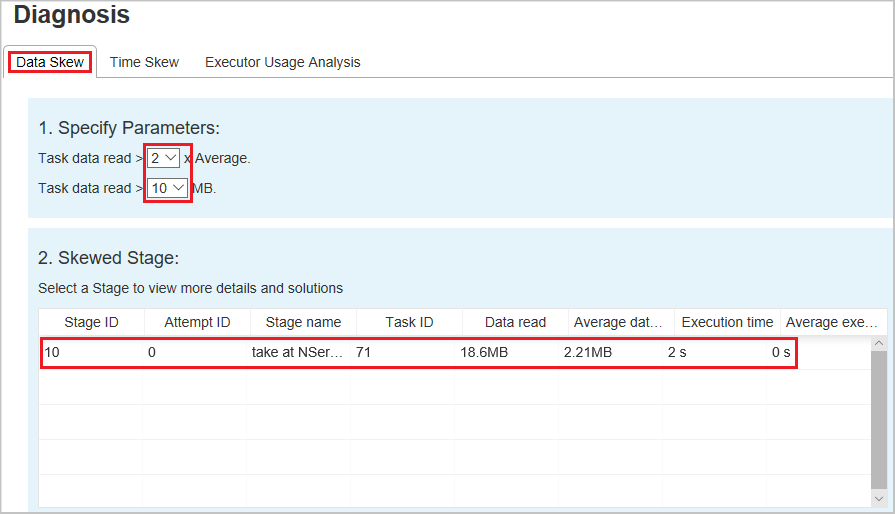
[Skew Chart](スキュー グラフ) - スキュー ステージ テーブルの行を選択すると、データの読み取りと実行時間に基づいて、スキュー グラフにさらに多くのタスク分布の詳細が表示されます。 偏りのあるタスクは赤でマークされ、通常のタスクは青でマークされます。 グラフには最大 100 個のサンプル タスクが表示され、タスクの詳細が右下のパネルに表示されます。
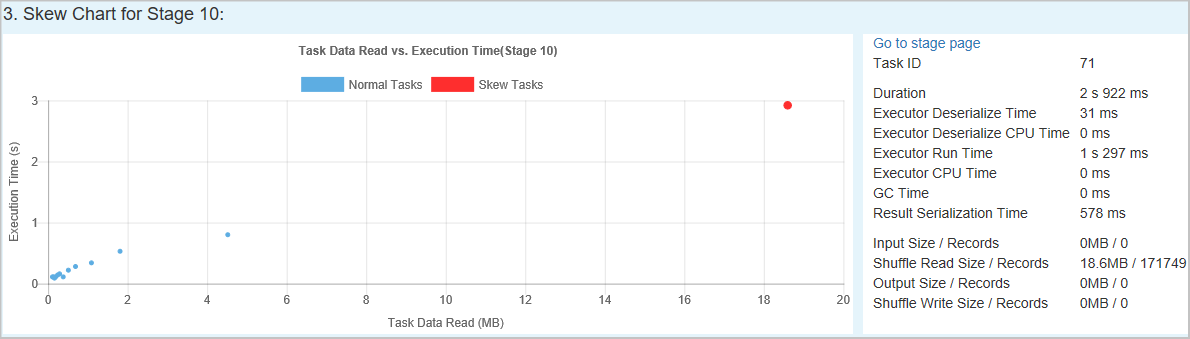
[Time Skew](時間のずれ)
[Time Skew](時間のずれ) タブには、タスクの実行時間に基づいて偏りのあるタスクが表示されます。
[パラメーターの指定] - 最初のセクションには、時間のずれの検出に使用するパラメーターが表示されます。 時間のずれを検出する既定の条件は、タスクの実行時間が平均実行時間の 3 倍を超えており、なおかつ 30 秒を超えていることです。 必要に応じてパラメーターを変更できます。 [Skewed Stage](偏りのあるステージ) と [Skew Chart](スキュー グラフ) には、上の [Data Skew](データ スキュー) タブと同様に対応するステージとタスクの情報が表示されます。
[時間のずれ] を選択すると、 [パラメーターの指定] セクションで設定されたパラメーターに従って、フィルター処理された結果が [傾斜したステージ] セクションに表示されます。 [傾斜したステージ] セクションで項目を選択すると、対応するグラフの下書きがセクション 3 に表示され、タスクの詳細が右下のパネルに表示されます。
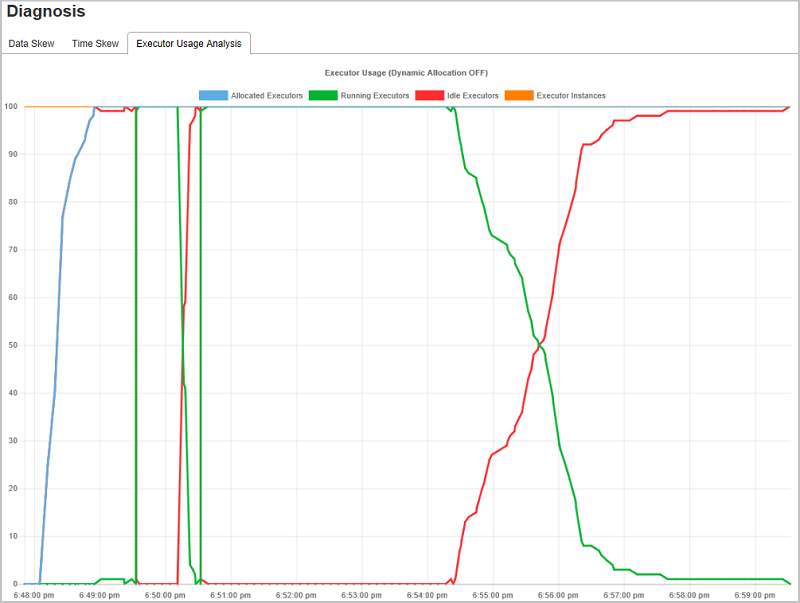
実行プログラムの使用状況の分析
[Executor Usage Graph](実行プログラムの使用状況グラフ) には、Spark ジョブの実行プログラムの割り当てと実行状態が視覚化されます。
[Executor Usage Analysis](Executor 利用状況分析) を選択すると、Executor の利用状況に関する 4 種類の曲線 ( [Allocated Executors](割り当て済みの Executor 数) 、 [Running Executors](実行中の Executor 数) 、 [idle Executors](アイドル状態の Executor 数) 、 [Max Executor Instances](Executor インスタンスの最大数) ) が表示されます。 割り当て済みの実行プログラムについては、"Executor added" (実行プログラムの追加) イベントまたは "Executor removed" (実行プログラムの削除) イベントごとに割り当て済み実行プログラムが増減します。 詳細な比較については、[Jobs](ジョブ) タブの [Event Timeline](イベントのタイムライン) を確認します。
色のアイコンを選択すると、すべての下書きの対応する内容が選択または選択解除されます。
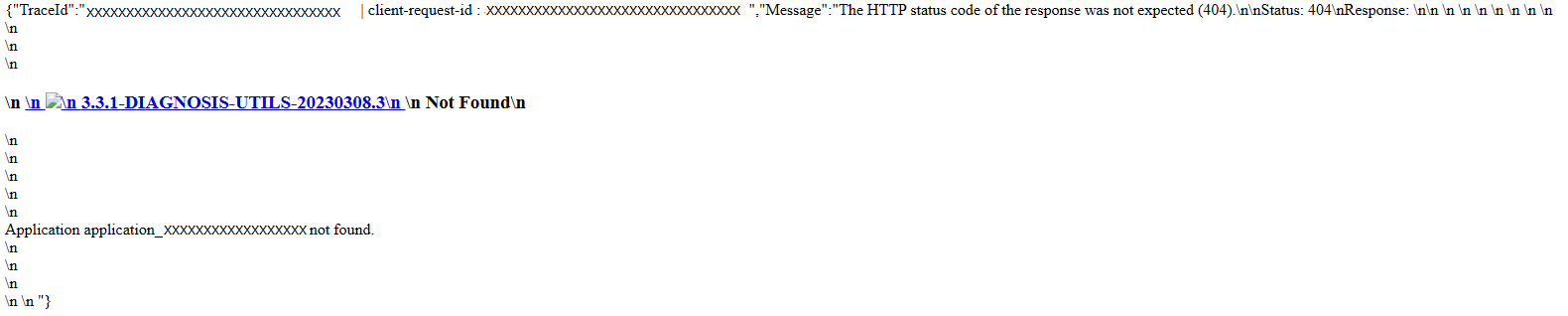
Spark UI での 404 のトラブルシューティング ガイド
場合によっては、膨大なジョブとステージを含む実行時間の長い Spark アプリケーションで、Spark UI を開いたときに、次のページが表示されて失敗することがあります。
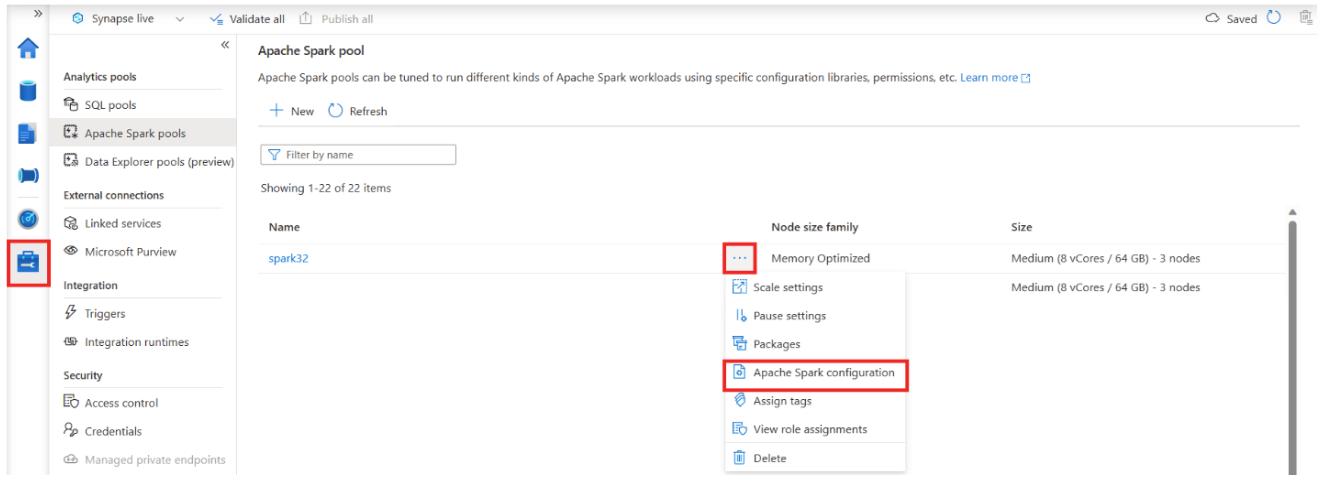
回避策として、Spark プールに追加の Spark 構成を適用できます。
spark.synapse.history.rpc.memoryNeeded 1g
実行中の既存の Spark アプリケーションの場合は、Spark UI ページで、ブラウザーのアドレス バーの末尾に次のクエリ文字列を追加します。?feature.enableStandaloneHS=false

既知の問題
Resilient Distributed Datasets (RDD) を使用した入力/出力データは、[データ] タブに表示されません。