Azure ストレージ アカウントを使用して Apache Spark アプリケーションのログとメトリックを収集する
Synapse Apache Spark 診断エミッタ拡張機能は、Apache Spark アプリケーションで 1 つ以上の宛先 (Azure Log Analytics、Azure Storage、Azure Event Hubs など) にログ、イベント ログ、メトリックを送信できるようにするライブラリです。
このチュートリアルでは、Synapse Apache Spark 診断エミッタ拡張機能を使用して、Apache Spark アプリケーションのログ、イベント ログ、メトリックを Azure ストレージ アカウントに送信する方法について説明します。
ログとメトリックをストレージ アカウントに収集する
手順 1:ストレージ アカウントの作成
診断ログとメトリックをストレージ アカウントに収集するには、既存の Azure Storage アカウントを使用できます。 または、お持ちでない場合は、Azure BLOB ストレージ アカウントを作成することも、Azure Data Lake Storage Gen2 で使用するストレージ アカウントを作成することもできます。
手順 2: Apache Spark 構成ファイルの作成
diagnostic-emitter-azure-storage-conf.txt を作成し、そのファイルに次の内容をコピーします。 または、Apache Spark プール構成用のサンプル テンプレート ファイルをダウンロードします。
spark.synapse.diagnostic.emitters MyDestination1
spark.synapse.diagnostic.emitter.MyDestination1.type AzureStorage
spark.synapse.diagnostic.emitter.MyDestination1.categories Log,EventLog,Metrics
spark.synapse.diagnostic.emitter.MyDestination1.uri https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>
spark.synapse.diagnostic.emitter.MyDestination1.auth AccessKey
spark.synapse.diagnostic.emitter.MyDestination1.secret <storage-access-key>
構成ファイルで、パラメーター <my-blob-storage>、<container-name>、<folder-name>、<storage-access-key> を入力します。
パラメーターの詳細については、Azure Storage の構成に関するセクションをご覧ください
手順 3: Apache Spark 構成ファイルを Synapse Studio にアップロードして、Spark プールで使用する
- Apache Spark 構成ページ ([管理] -> [Apache Spark 構成]) を開きます。
- [インポート] ボタンをクリックして、Apache Spark 構成ファイルを Synapse Studio にアップロードします。
- Synapse Studio で Apache Spark プールに移動します ([管理] -> [Apache Spark プール])。
- Apache Spark プールの右側にある [...] ボタンをクリックし、[Apache Spark 構成] を選択します。
- アップロードした構成ファイルを、ドロップダウン メニューから選択できます。
- 構成ファイルを選択したら、[適用] をクリックします。
手順 4: Azure ストレージ アカウントのログ ファイルを表示する
構成された Apache Spark プールにジョブを送信すると、宛先のストレージ アカウントにログとメトリックのファイルが表示されるようになります。
ログは、<workspaceName>.<sparkPoolName>.<livySessionId> によって、さまざまなアプリケーションに従って対応するパスに入れられます。
すべてのログ ファイルは、データ処理に便利な JSON 行形式 (改行区切りの JSON である ndjson とも呼ばれます) になります。
利用可能な構成
| 構成 | 説明 |
|---|---|
spark.synapse.diagnostic.emitters |
必須。 診断エミッタのコンマ区切りの宛先名。 たとえば、MyDest1,MyDest2 のように指定します。 |
spark.synapse.diagnostic.emitter.<destination>.type |
必須。 組み込みの宛先の種類。 Azure ストレージの宛先を有効にするには、このフィールドに AzureStorage が含まれている必要があります。 |
spark.synapse.diagnostic.emitter.<destination>.categories |
省略可能。 コンマ区切りの選択されたログ カテゴリ。 指定できる値には、DriverLog、ExecutorLog、EventLog、Metrics が含まれます。 設定しない場合、既定値はすべてのカテゴリです。 |
spark.synapse.diagnostic.emitter.<destination>.auth |
必須。 ストレージ アカウントのアクセス キー承認を使用する場合は AccessKey。 Shared Access Signature 承認の場合は SAS。 |
spark.synapse.diagnostic.emitter.<destination>.uri |
必須。 宛先 BLOB コンテナー フォルダーの URI。 パターン https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name> に一致する必要があります。 |
spark.synapse.diagnostic.emitter.<destination>.secret |
省略可能。 シークレット (AccessKey または SAS) の内容。 |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
.secret が指定されていない場合は必須です。 シークレット (AccessKey または SAS) が格納されている Azure Key Vault の名前。 |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
.secret.keyVault を指定した場合は必須。 シークレット (AccessKey または SAS) が格納されている Azure Key Vault のシークレット名。 |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
省略可能。 Azure Key Vault のリンクされたサービス名。 Synapse パイプラインで有効にした場合、AKV からシークレットを取得するために必要です。 (AKV に対する読み取りアクセス許可が MSI に付与されていることを確認してください)。 |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
省略可能。 コンマ区切りの Spark イベント名。収集するイベントを指定できます。 例: SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
省略可能。 コンマ区切りの log4j ロガー名。収集するログを指定できます。 例: org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
省略可能。 コンマ区切りの Spark メトリック名のサフィックス。収集するメトリックを指定できます。 例: jvm.heap.used |
ログ データの例
JSON 形式のログ レコードの例を次に示します。
{
"timestamp": "2021-01-02T12:34:56.789Z",
"category": "Log|EventLog|Metrics",
"workspaceName": "<my-workspace-name>",
"sparkPool": "<spark-pool-name>",
"livyId": "<livy-session-id>",
"applicationId": "<application-id>",
"applicationName": "<application-name>",
"executorId": "<driver-or-executor-id>",
"properties": {
// The message properties of logs, events and metrics.
"timestamp": "2021-01-02T12:34:56.789Z",
"message": "Registering signal handler for TERM",
"logger_name": "org.apache.spark.util.SignalUtils",
"level": "INFO",
"thread_name": "main"
// ...
}
}
データ流出の防止が有効になっている Synapse ワークスペース
Azure Synapse Analytics ワークスペースでは、ワークスペースのデータ流出の防止を有効化することがサポートされています。 流出の防止を設定すると、ログとメトリックを宛先エンドポイントに直接送信できません。 このシナリオでは、さまざまな宛先エンドポイントに対応するマネージド プライベート エンドポイントを作成するか、IP ファイアウォール規則を作成できます。
[Synapse Studio] > [管理] > [マネージド プライベート エンドポイント] に移動し、[新規] ボタンをクリックし、[Azure Blob Storage] または [Azure Data Lake Storage Gen2] を選択して、[続行] を選択します。
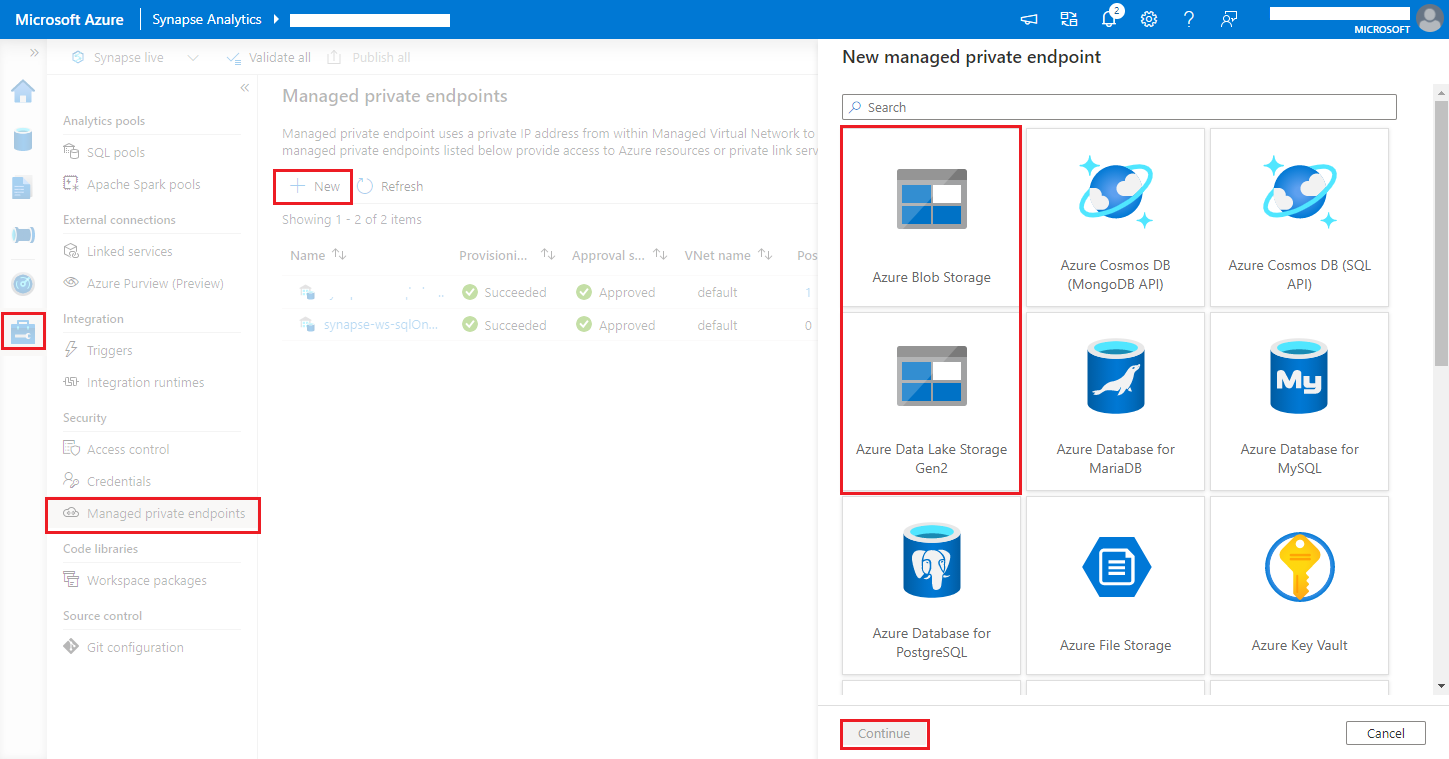
Note
Azure Blob Storage と Azure Data Lake Storage Gen2 のどちらもサポートできます。 ただし、abfss:// 形式は解析できません。 Azure Data Lake Storage Gen2 エンドポイントは、BLOB URL として書式設定する必要があります。
https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>[ストレージ アカウント名] で Azure Storage アカウントを選択し、 [作成] ボタンをクリックします。
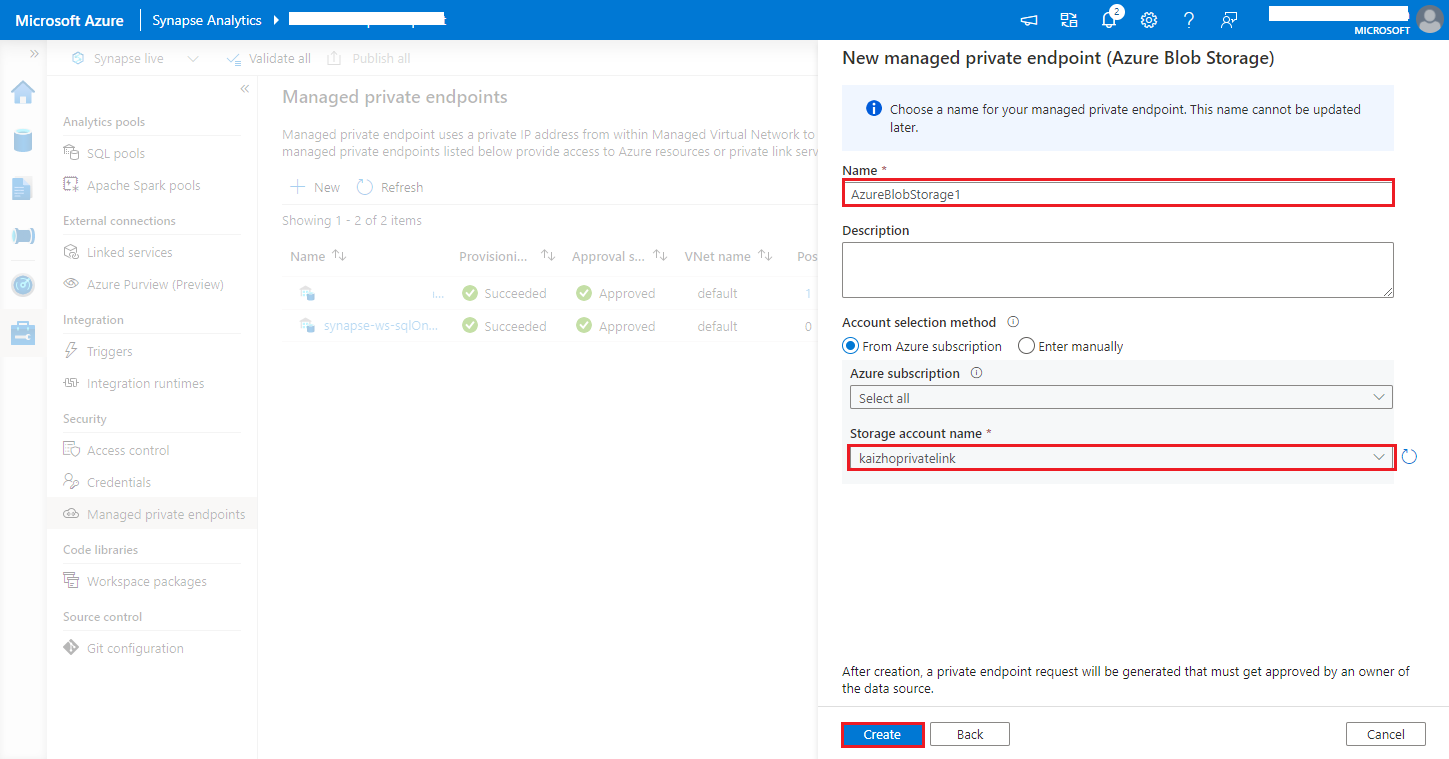
プライベート エンドポイントのプロビジョニングが完了するまで数分待ちます。
Azure portal でご自分のストレージ アカウントに移動し、 [ネットワーク]>[プライベート エンドポイント接続] ページで、プロビジョニングした接続と [許可] を選択します。