Tip
Microsoft Fabric Data Warehouse は、将来のアーキテクチャ、組み込みの AI、および新機能を備えた、Data Lake 基盤上のエンタープライズ 規模のリレーショナル ウェアハウスです。 データ ウェアハウスを初めて使用する場合は、Fabric Data Warehouseから始めます。 既存の dedicated SQL プール ワークロードは、Fabric にアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
- Fabric無料試用版を開始します。
- Fabric Data Warehouse 用マイグレーションアシスタント
このセクションでは、ビューを作成および使用して、サーバーレス SQL プール クエリをラップする方法を学習します。 ビューを使用すると、これらのクエリを再利用できます。 ビューは、Power BI などのツールをサーバーレス SQL プールと組み合わせて使用する場合にも必要になります。
前提条件
最初の手順では、ビューが作成されるデータベースを作成し、そのデータベースで設定スクリプトを実行して、Azure Storage での認証に必要なオブジェクトを初期化します。 この記事のクエリはすべて、サンプル データベースで実行されます。
外部データのビュー
ビューは、通常の SQL Server ビューを作成するのと同じ方法で作成できます。 次のクエリによって、population.csv ファイルを読み取るビューが作成されます。
注意
クエリの最初の行 ([mydbname]) は、自分で作成したデータベースを使用するように変更してください。
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
ビューには、EXTERNAL DATA SOURCE としてストレージのルート URL を備えた DATA_SOURCE が使用され、相対ファイル パスがファイルに追加されます。
Delta Lake のビュー
Delta Lake フォルダーでビューを作成する場合、BULK オプションの後ろに、ファイルのパスの代わりにルート フォルダーの場所を指定する必要があります。
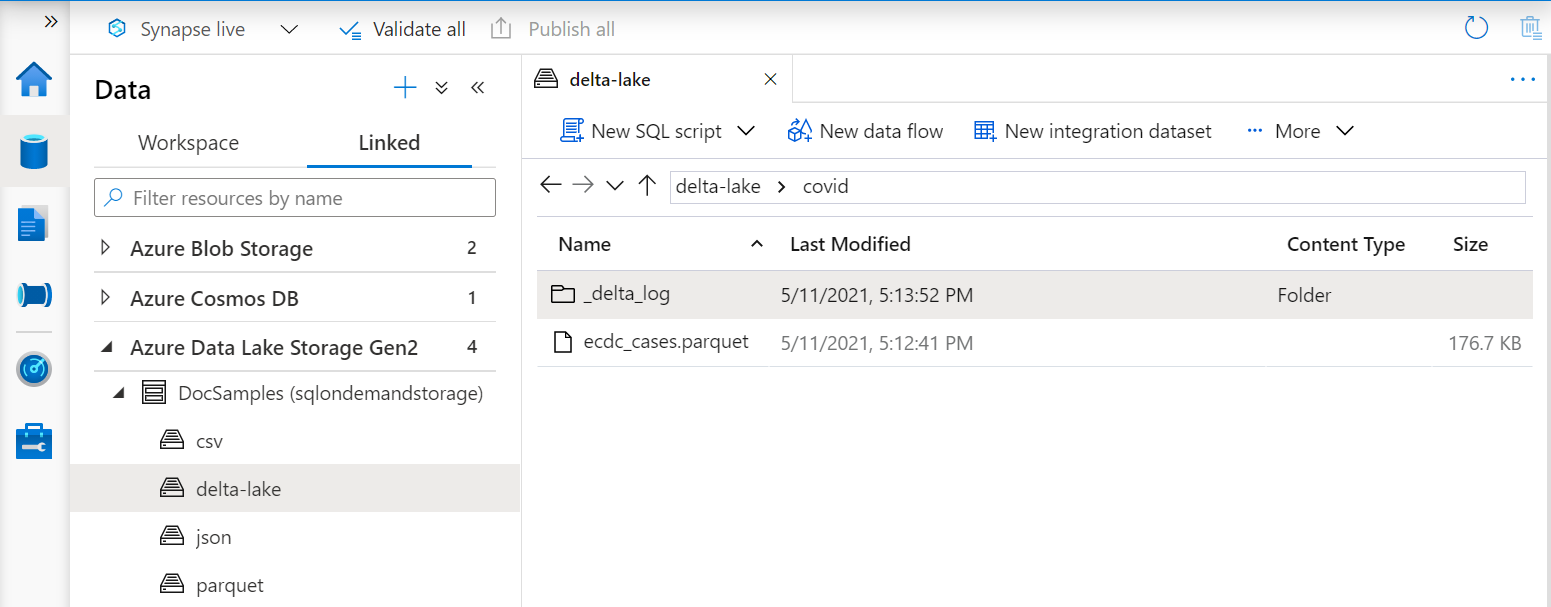
Delta Lake フォルダーからデータを読み取る OPENROWSET 関数では、フォルダーの構造を調べて自動的にファイルの場所を特定します。
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
詳しくは、Synapse サーバーレス SQL プールのセルフヘルプ ページと「Azure Synapse Analytics の既知の問題」をご覧ください。
パーティション ビュー
階層フォルダー構造内にパーティション分割された一連のファイルがある場合は、ファイル パスのワイルドカードを使用してパーティション パターンを記述できます。
FILEPATH 関数を使用して、フォルダー パスの一部をパーティション分割列として公開します。
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
パーティション 分割ビューでは、パーティション分割列のフィルターを使用してクエリを実行するときにパーティションの除外を実行することで、クエリのパフォーマンスを向上させることができます。 ただし、すべてのクエリでパーティションの除外がサポートされているわけではないため、いくつかのベスト プラクティスに従うことが重要です。
パーティションの除外を確実に行うには、フィルターでサブクエリを使用しないようにします。これは、パーティションを除外する機能に干渉する可能性があるためです。 代わりに、サブクエリの結果を変数としてフィルターに渡します。
SQL クエリで JOIN を使用する場合は、フィルター述語を NVARCHAR として宣言して、クエリ プランの複雑さを軽減し、正しいパーティションの除外の確率が高くなるようにします。 通常、パーティション列は NVARCHAR(1024) と推論されるため、述語に同じ型を使用すると、暗黙的なキャストが不要になり、クエリ プランの複雑さが増す可能性があります。
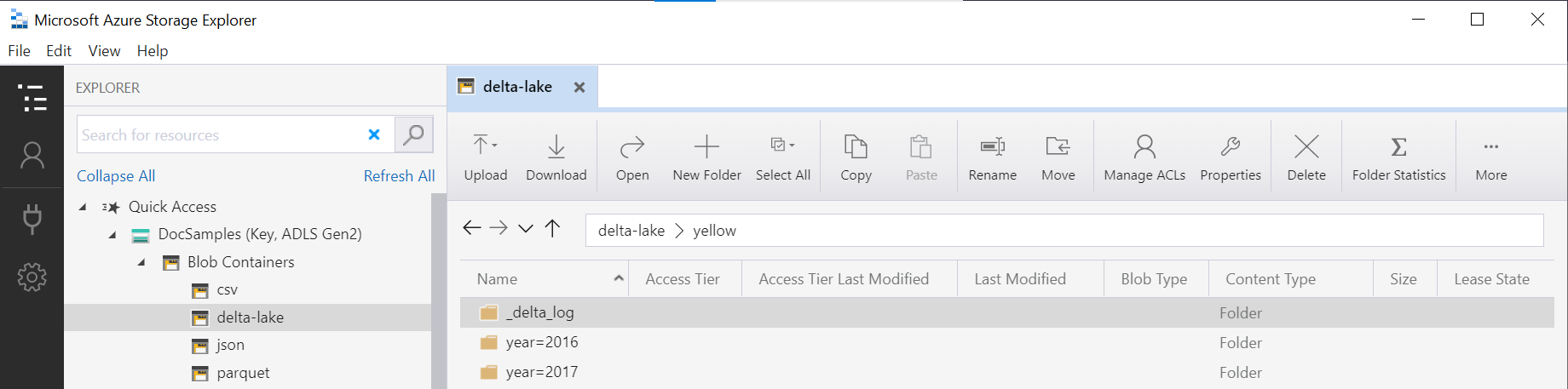
Delta Lake パーティション ビュー
Delta Lake ストレージでパーティション ビューを作成する場合、ルートになる Delta Lake フォルダーを指定するだけでよく、FILEPATH 関数で明示的にパーティション分割列を表示する必要はありません。
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
OPENROWSET 関数では、Delta Lake フォルダーの構造を調べ、パーティション列を自動的に特定します。 クエリの WHERE 句でパーティション分割列を指定した場合、パーティションの除去が自動的に実行されます。
OPENROWSET 関数の中にある、yellow データ ソースに指定された LOCATION URI を連結したフォルダー名 (この例では DeltaLakeStorage) は、_delta_log というサブフォルダーを含むルート Delta Lake フォルダーへの参照となっている必要があります。
詳しくは、Synapse サーバーレス SQL プールのセルフヘルプ ページと「Azure Synapse Analytics の既知の問題」をご覧ください。
JSON ビュー
ファイルからフェッチされた結果セット上で追加の処理を行う必要がある場合は、このビューが最適です。 1 つの例として、JSON ドキュメントから値を抽出するために JSON 関数を適用する必要がある、JSON ファイルの解析があります。
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
OPENJSON 関数により、テキスト形式で 1 行に 1 つの JSON ドキュメントを含む JSONL ファイルから各行が解析されます。
コンテナーでの Azure Cosmos DB ビュー
Azure Cosmos DB 分析ストレージがコンテナーで有効になっている場合は、Azure Cosmos DB コンテナー上にこのビューを作成できます。 Azure Cosmos DB のアカウント名、データベース名、コンテナー名を、ビューの一部として追加する必要があります。また、読み取り専用アクセス キーを、ビューが参照するデータベース スコープ資格情報に配置する必要があります。
このサンプル スクリプトでは、これらの手順に従って設定できるデータベースとコンテナーを使用します。
重要
スクリプトで、これらの値を実際の値に置き換えてください。
- your-cosmosdb - Cosmos DB アカウントの名前
- access-key - ご利用の Cosmos DB アカウント キー
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
詳しくは、「Azure Synapse Link でサーバーレス SQL プールを使用して Azure Cosmos DB データのクエリを実行する」をご覧ください。
ビューの使用
ビューは、SQL Server クエリ内でビューを使用するのと同じ方法でクエリ内で使用できます。
次のクエリは、「ビューの作成」で作成した population_csv ビューの使用方法を示しています。 これにより、国/地域名が 2019 年の人口の降順に返されます。
注意
クエリの最初の行 ([mydbname]) は、自分で作成したデータベースを使用するように変更してください。
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
ビューに対してクエリを実行すると、エラーや予期しない結果が発生する可能性があります。 これはおそらく、ビューが、変更されたか、もはや存在しない列またはオブジェクトを参照していることを意味する可能性があります。 基になるスキーマの変更に合わせてビュー定義を手動で調整する必要があります。
関連するコンテンツ
さまざまな種類のファイルに対するクエリの実行については、単一の CSV ファイルに対するクエリの実行、Parquet ファイルに対するクエリの実行、および JSON ファイルに対するクエリの実行に関するページを参照してください。