HC シリーズの仮想マシンのサイズ
適用対象: ✔️ Linux VM ✔️ Windows VM ✔️ フレキシブル スケール セット ✔️ 均一スケール セット
HC シリーズのサイズについては、いくつかのパフォーマンス テストが実行されています。 このパフォーマンス テストの結果の一部を次に示します。
| ワークロード | HB |
|---|---|
| STREAM Triad | 190 GB/秒 (Intel MLC AVX-512) |
| High-Performance Linpack (HPL) | 3520 GigaFLOPS (Rpeak)、2970 GigaFLOPS (Rmax) |
| RDMA の待機時間と帯域幅 | 1.05 マイクロ秒、96.8 Gb/秒 |
| ローカル NVMe SSD 上の FIO | 1.3 GB/秒の読み取り、900 MB/秒の書き込み |
| 4 枚の Azure Premium SSD 上の IOR (P30 マネージド ディスク、RAID0)** | 780 MB/秒の読み取り、780 MB/秒の書き込み |
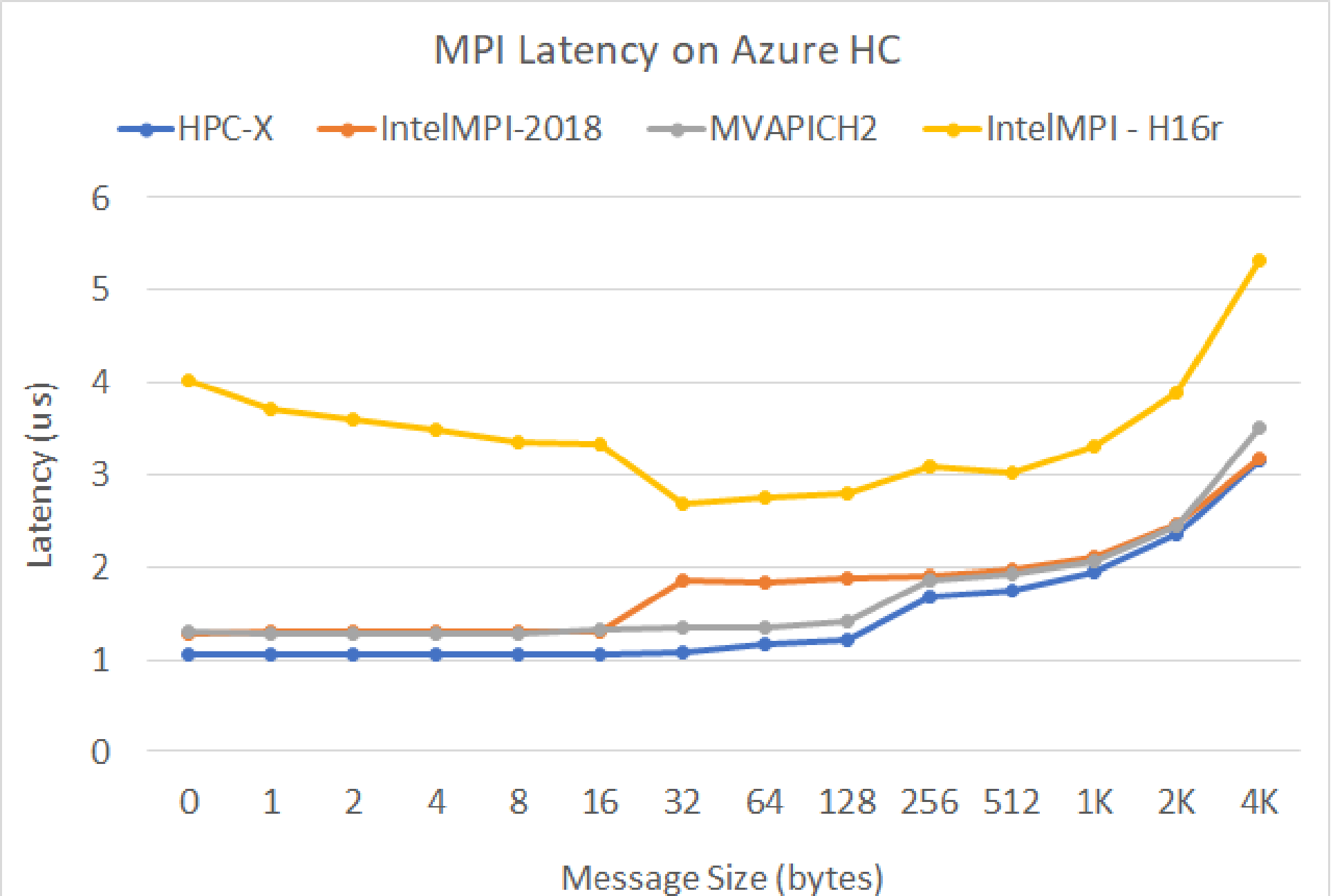
MPI 待機時間
OSU マイクロベンチマーク スイートからの MPI 待機時間テストが実行されます。 サンプル スクリプトは GitHub にあります
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
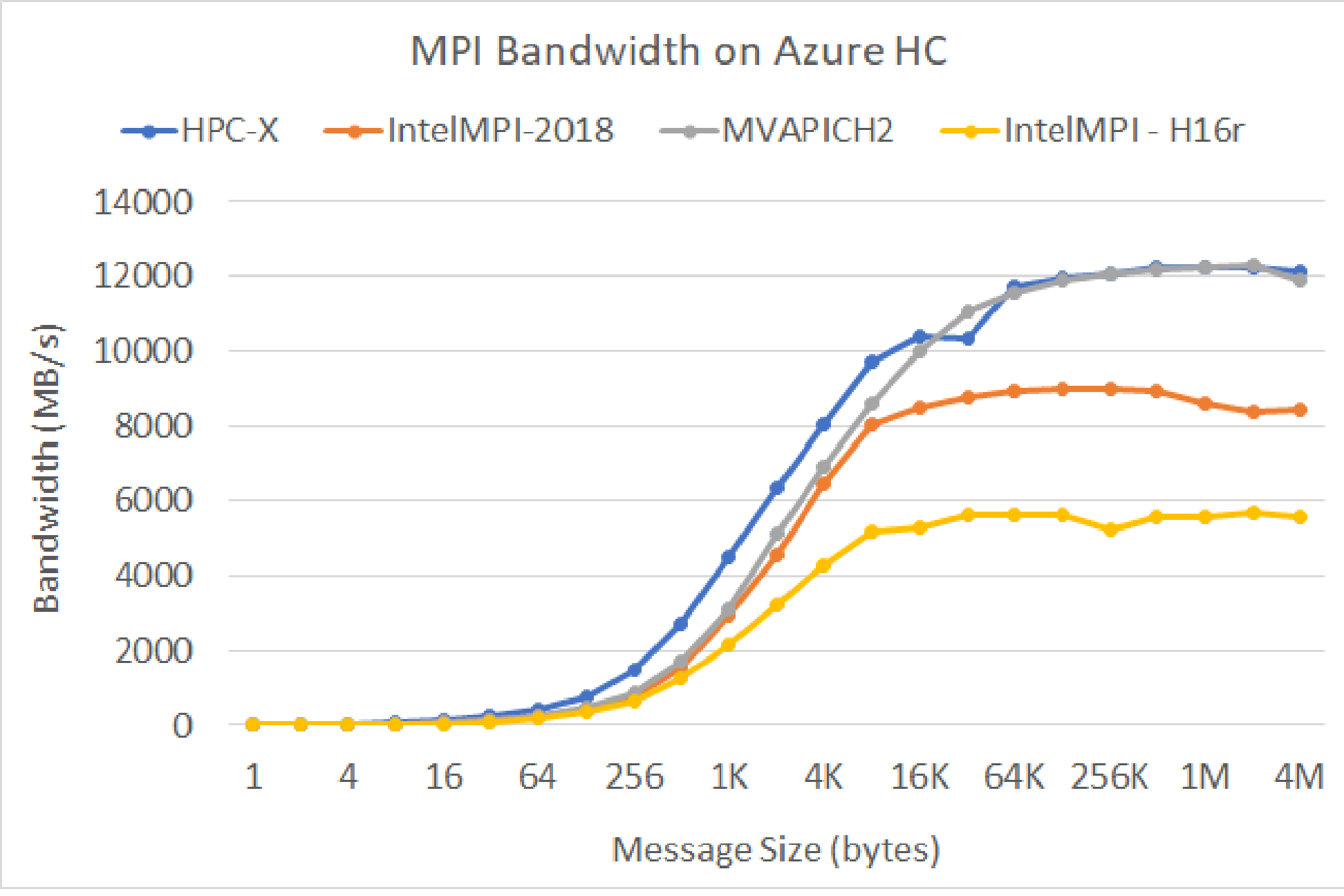
MPI 帯域幅
OSU マイクロベンチマーク スイートからの MPI 帯域幅テストが実行されます。 サンプル スクリプトは GitHub にあります
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
Mellanox Perftest パッケージには、待機時間 (ib_send_lat) や帯域幅 (ib_send_bw) などの多くの InfiniBand テストがあります。 コマンドの例を次に示します。
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
次の手順
- Azure Compute Tech Community のブログで、最新の発表、HPC ワークロードの例、およびパフォーマンスの結果について参照します。
- アーキテクチャの面から見た HPC ワークロードの実行の概要については、「Azure でのハイ パフォーマンス コンピューティング (HPC)」を参照してください。