フェンス デバイスを使用した SUSE での高可用性セットアップ
この記事では、SUSE オペレーティング システムでフェンス デバイスを使用して、HANA L インスタンスの高可用性 (HA) を設定する手順を説明します。
注意
このガイドは、Microsoft HANA L インスタンス環境の設定を適切にテストすることで得られたものです。 HANA L インスタンスの Microsoft サービス管理チームは、このオペレーティング システムをサポートしていません。 オペレーティング システム レイヤーに関するトラブルシューティングと説明については、SUSE にお問い合わせください。
Microsoft サービス管理チームは、フェンス デバイスの設定とフル サポートを担当しています。 フェンス デバイスに関する問題のトラブルシューティングについても支援します。
必須コンポーネント
SUSE のクラスタリングを使用して高可用性を設定するには、次のことを行う必要があります。
- HANA L インスタンスをプロビジョニングする。
- 最新のパッチを適用したオペレーティング システムをインストールして登録する。
- HANA L インスタンス サーバーを SMT サーバーに接続し、パッチとパッケージを取得する。
- ネットワーク タイム プロトコル (NTP タイム サーバー) を設定する。
- 最新の SUSE のドキュメントで HA のセットアップに関する情報を読み、理解する。
セットアップの詳細
このガイドでは、次のセットアップを使用します。
- オペレーティング システム: SLES 12 SP1 for SAP
- HANA L インスタンス:2xS192 (4 ソケット、2 TB)
- HANA のバージョン: HANA 2.0 SP1
- サーバー名: sapprdhdb95 (node1) および sapprdhdb96 (node2)
- フェンス デバイス: iSCSI ベース
- HANA L インスタンス ノードのいずれかでの NTP
HANA システム レプリケーションを有効にして HANA L インスタンスを設定するときは、Microsoft サービス管理チームにフェンス デバイスの設定を依頼できます。 これは、プロビジョニング時に行います。
既に HANA L インスタンスのプロビジョニングを行った方も、フェンス デバイスをセットアップできます。 サービス依頼フォーム (SRF) に次の情報を入力して Microsoft サービス管理チームに渡します。 SRF は、テクニカル アカウント マネージャーか、HANA Large Instances のオンボーディングを担当する Microsoft の連絡先に連絡して取得できます。
- サーバー名とサーバーの IP アドレス (例: myhanaserver1、10.35.0.1)
- 場所 (例: 米国東部)
- 顧客名 (例: Microsoft)
- HANA システム識別子 (SID) (例: H11)
フェンス デバイスの設定が終わったら、Microsoft サービス管理チームから、SBD 名と iSCSI ストレージの IP アドレスが提供されます。 この情報を使用してフェンスのセットアップの設定ができます。
次のセクションの手順に従い、フェンス デバイスを使用して HA を設定します。
SBD デバイスを識別する
注意
このセクションの内容は既存のお客様にのみ当てはまります。 新規顧客には Microsoft サービス管理チームから SBD デバイス名を提供しますので、このセクションは飛ばしてください。
/etc/iscsi/initiatorname.isci を次のように変更します。
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Microsoft サービス管理からこの文字列を受け取ります。 両ノードのファイルを変更します。 ただし、ノード番号はノードによって異なります。
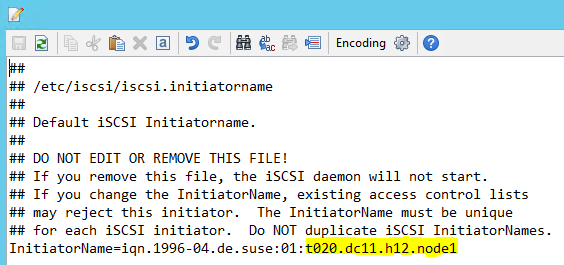
node.session.timeo.replacement_timeout=5とnode.startup = automaticを設定して、 /etc/iscsi/iscsid.conf を変更します。 両ノードのファイルを変更します。"両方" のノード上で次の discovery コマンドを実行します。
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260結果には 4 つのセッションが表示されます。
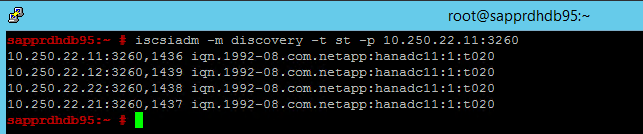
"両方" のノード上で次のコマンドを実行し、iSCSI デバイスにサインインします。
iscsiadm -m node -l結果には 4 つのセッションが表示されます。

次のコマンドを使用して、rescan-scsi-bus.sh rescan スクリプトを実行します。 自動的に作成された新しいディスクが表示されます。 両ノードでこれを実行します。
rescan-scsi-bus.sh結果には、0 より大きい LUN 番号が表示されます (例: 1、2 など)。
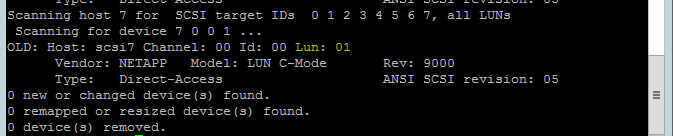
デバイス名を取得するには、"両方" のノード上で次のコマンドを実行します。
fdisk –l結果で、178 MiB のサイズのデバイスを選択します。

SBD デバイスを初期化する
"両方" のノード上で次のコマンドを使用して、SBD デバイスを初期化します。
sbd -d <SBD Device Name> create
"両方" のノード上で次のコマンドを使用して、デバイスに書き込まれた内容を確認します。
sbd -d <SBD Device Name> dump
SUSE HA クラスターを構成する
"両方" のノード上で次のコマンドを使用して、ha_sles と SAPHanaSR-doc パターンがインストールされているかどうかを確認します。 インストールされていない場合はインストールします。
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
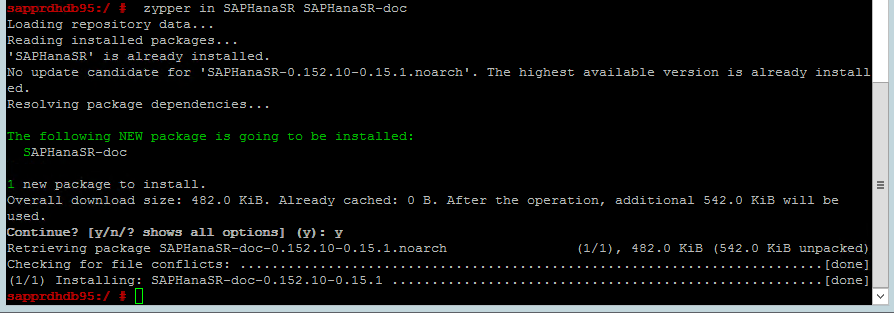
ha-cluster-initコマンドまたは yast2 ウィザードのいずれかを使用してクラスターを設定します。 この例では、yast2 ウィザードを使用しています。 この手順は "プライマリ ノード" でのみ実施します。[yast2]>[High Availability](高可用性)>[Cluster](クラスター) に移動します
![YaST Control Center のスクリーンショット。[High Availability]\(高可用性\) と [Cluster]\(クラスター\) が選択されている。](media/howtohli/hasetupwithfencing/yast-control-center.png)
halk2 パッケージは既にインストールされているため、表示される hawk パッケージのインストールに関するダイアログで [キャンセル] を選択します。
![[Install]\(インストール\) と [Cancel]\(キャンセル\) ボタンが存在するダイアログを示すスクリーンショット。](media/howtohli/hasetupwithfencing/yast-hawk-install.png)
表示される続行に関するダイアログで、 [Continue](続行) を選択します。
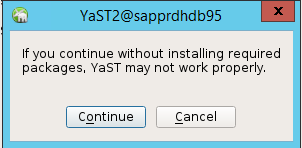
予期される値は、デプロイされたノード数 (この場合は 2) です。 [次へ] を選択します。
ノード名を追加し、 [Add suggested files](示されたファイルを追加する) を選択します。
![[Sync Host]\(同期ホスト\) と [Sync File]\(同期ファイル\) 一覧が表示されたクラスターの構成ウィンドウを示すスクリーンショット。](media/howtohli/hasetupwithfencing/yast-cluster-configure-csync2.png)
[Turn csync2 ON](csync2 をオンにする) を選択します。
[Generate Pre-Shared-Keys](事前共有キーを生成する) を選択します。
表示されるポップアップ メッセージで、 [OK] を選択します。
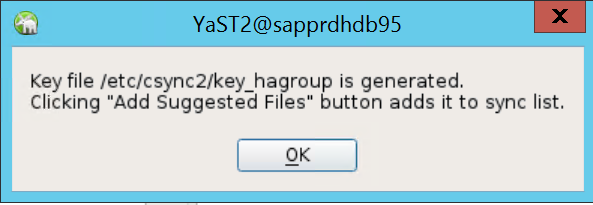
Csync2 で IP アドレスと事前共有キーを使って認証が実行されます。 キー ファイルは、
csync2 -k /etc/csync2/key_hagroupを使用して生成されます。ファイル key_hagroup が作成されたら、クラスターの全メンバーに手動でコピーします。 必ずファイルを node1 から node2 にコピーします。 [次へ] を選択します。
既定のオプションでは、 [Booting](ブート) オプションは [Off](オフ) です。 これを [On](オン) に変更すると、起動時に pacemaker サービスが開始されます。 セットアップの要件に基づいて選ぶことができます。
![[Booting]\(ブート\) が有効な Cluster Service ウィンドウを示すスクリーンショット。](media/howtohli/hasetupwithfencing/yast-cluster-service.png)
[Next](次へ) をクリックしてクラスターの設定を完了します。
softdog ウォッチドッグをセットアップします
"両方" のノードの /etc/init.d/boot.local に次の行を追加します。
modprobe softdog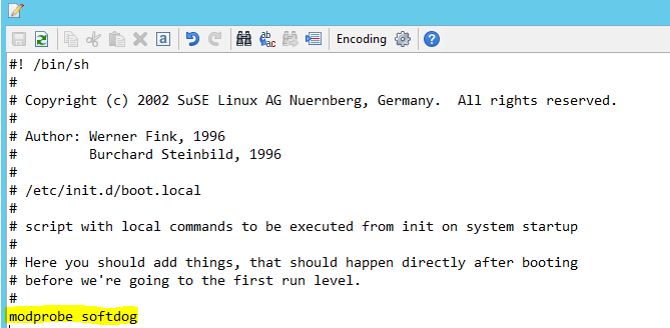
"両方" のノード上で次のコマンドを使用して、ファイル /etc/sysconfig/sbd を更新します。
SBD_DEVICE="<SBD Device Name>"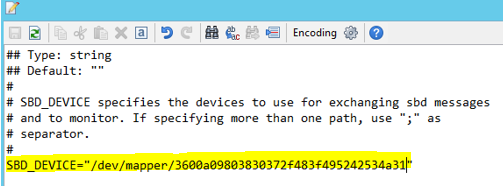
"両方" のノード上で次のコマンドを実行して、カーネル モジュールを読み込みます。
modprobe softdog
"両方" のノード上で次のコマンドを使用して、softdog が実行されていることを確認します。
lsmod | grep dog
"両方" のノード上で次のコマンドを使用して、SBD デバイスを起動します。
/usr/share/sbd/sbd.sh start
"両方" のノード上で次のコマンドを使用して、SBD デーモンをテストします。
sbd -d <SBD Device Name> list両方のノードの構成後の結果には、2 つのエントリが表示されます。

次のテスト メッセージをノードの "いずれか" に送信します。
sbd -d <SBD Device Name> message <node2> <message>"2 つ目" のノード (node2) 上で次のコマンドを使用して、メッセージの状態を確認します。
sbd -d <SBD Device Name> list
SBD の構成を採用するには、"両方" のノード上のファイル /etc/sysconfig/SBD を次のように更新します。
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS="""プライマリ ノード" (node1) 上で次のコマンドを使用して、pacemaker サービスを開始します。
systemctl start pacemaker
pacemaker サービスが失敗する場合は、後述の「シナリオ 5: Pacemaker サービスが失敗する」セクションを参照してください。
クラスターにノードを参加させる
node2 上で次のコマンドを実行して、ノードをクラスターに参加させます。
ha-cluster-join
クラスターの参加中にエラーが発生した場合は、この記事で後述する「シナリオ 6: Node2 がクラスターに参加できない」セクションを参照してください。
クラスターを検証する
次のコマンドを使用して確認し、必要に応じて "両方" のノード上でクラスターを初めて開始します。
systemctl status pacemaker systemctl start pacemaker
次のコマンドを実行して、"両方" のノードがオンラインであることを確認します。 これは、クラスターのどのノードでも実行できます。
crm_mon
hawk にサインインして、クラスターの状態
https://\<node IP>:7630を確認することもできます。 既定のユーザーは hacluster であり、パスワードは linux です。 必要であれば、passwdコマンドでパスワードを変更できます。
クラスターのプロパティとリソースを構成する
このセクションでは、クラスター リソースを構成する手順について説明します。 この例では、次のリソースを設定しています。 残りの部分は (必要に応じて) SUSE HA のガイドを参照して構成できます。
- クラスターのブートストラップ
- フェンス デバイス
- Virtual IP address
この構成は "プライマリ ノード" でのみ行います。
クラスターのブートストラップ ファイルを作成し、次のテキストを追加して構成します。
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"次のコマンドを使用して、構成をクラスターに追加します。
crm configure load update crm-bs.txt
次のようにリソースを追加し、ファイルを作成し、テキストを追加して、フェンス デバイスを構成します。
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"次のコマンドを使用して、構成をクラスターに追加します。
crm configure load update crm-sbd.txtファイルを作成して次のテキストを追加することで、リソースの仮想 IP アドレスを追加します。
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"次のコマンドを使用して、構成をクラスターに追加します。
crm configure load update crm-vip.txtcrm_monコマンドを使用してリソースを検証します。結果には、2 つのリソースが表示されます。

また、https://<ノード IP アドレス>:7630/cib/live/state で状態を確認することもできます
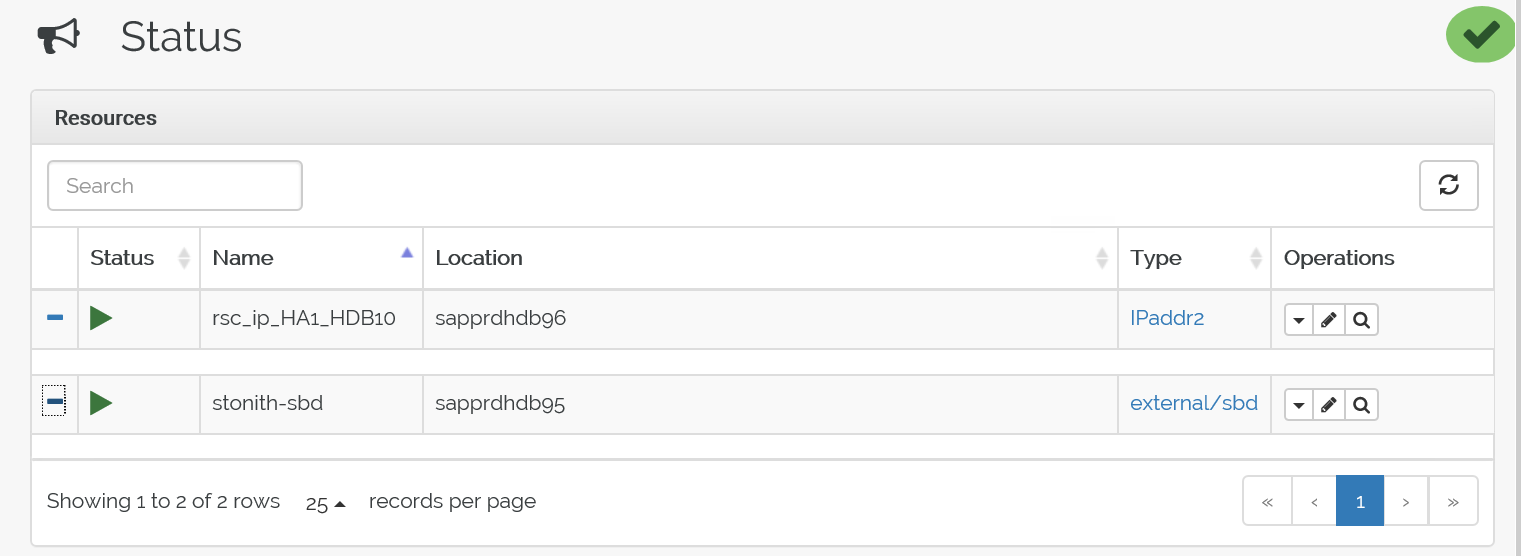
フェールオーバー プロセスをテストする
フェールオーバー プロセスをテストするには、次のコマンドを使用して node1 上の pacemaker サービスを停止します。
Service pacemaker stopリソースは node2 にフェールオーバーされます。
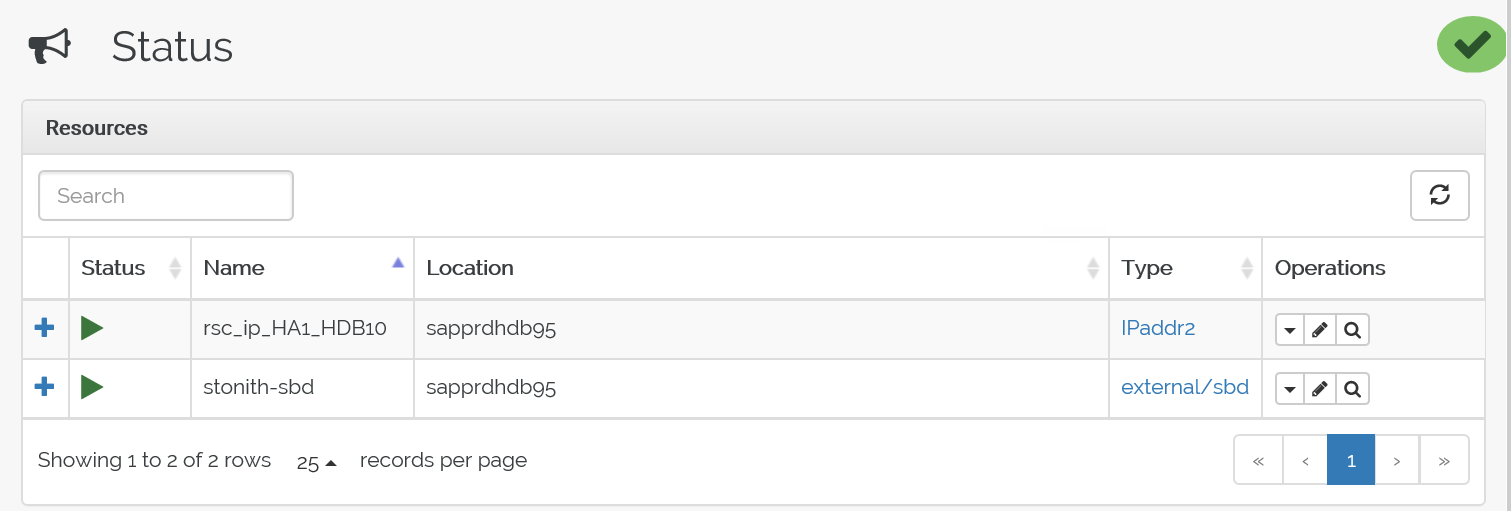
pacemaker のサービスを node2 で停止します。するとリソースが node1 にフェールオーバーします。
フェールオーバー前の状態は次のとおりです。
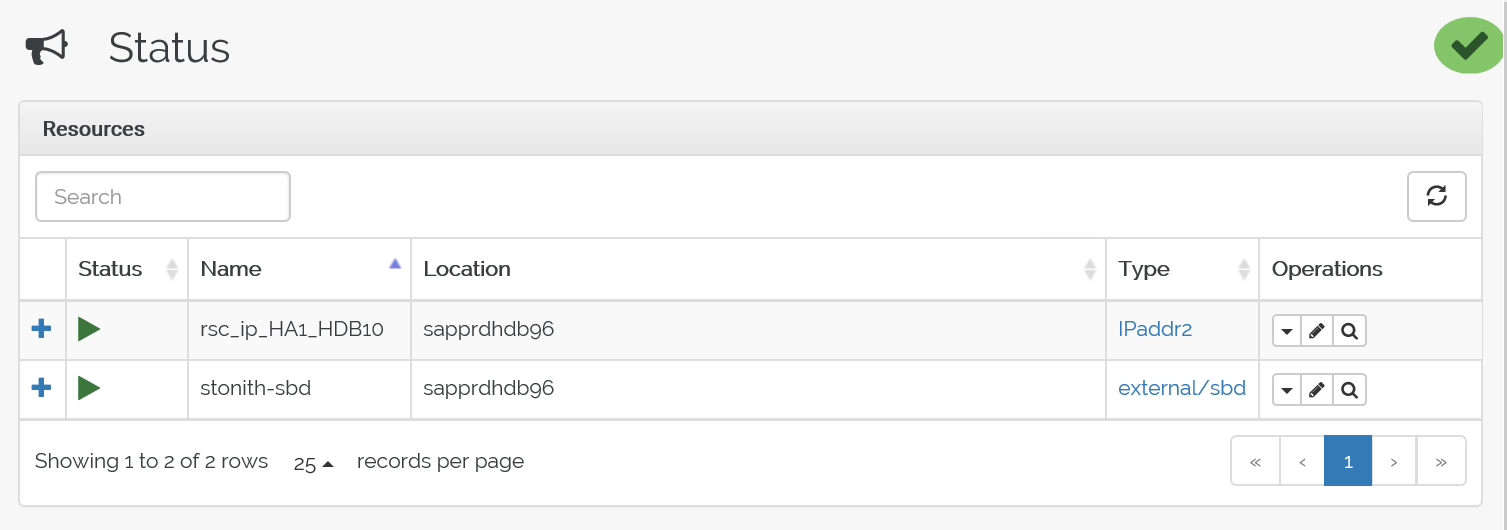
フェールオーバー後の状態は次のとおりです。

トラブルシューティング
このセクションでは、設定時に発生する可能性のあるエラー シナリオについて説明します。
シナリオ 1:クラスター ノードがオンラインではない
クラスター マネージャーでオンラインと表示されないノードがある場合は、これをオンラインにするために次の手順を試すことができます。
次のコマンドを使用して iSCSI サービスを開始します。
service iscsid start次のコマンドを使用してその iSCSI ノードにサインインします。
iscsiadm -m node -l次のような出力が表示されます。
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
シナリオ 2: yast2 で GUI が表示されない
この記事では、yast2 の GUI 画面で高可用性クラスターを設定します。 yast2 が図のような GUI ウィンドウで開かず、Qt エラーがスローされる場合は、次の手順で必要なパッケージをインストールします。 グラフィカル ウィンドウが開く場合は、この手順を省略できます。
Qt エラーの例を次に示します。

想定される出力の例を次に示します。
必ず "root" ユーザーとしてログインし、SMT セットアップでパッケージをダウンロードしてインストールします。
[yast]>[Software](ソフトウェア)>[Software Management](ソフトウェア管理)>[Dependencies](依存関係) に移動し、 [Install recommended packages](推奨パッケージのインストール) を選択します。
注意
両方のノードから yast2 の GUI を利用できるように、"両方" のノード上でこの手順を実行します。
次のスクリーンショットは、想定される画面を示しています。
[Dependencies](依存関係) で、 [Install Recommended Packages](推奨パッケージのインストール) を選択します。
![コンソール ウィンドウのスクリーンショット。[Install Recommended Packages]\(推奨パッケージのインストール\) が選択されている。](media/howtohli/hasetupwithfencing/yast-dependencies.png)
変更内容を確認し [OK] を選択します。
パッケージのインストールが続行されます。
[次へ] を選択します。
[Installation Successfully Finished](インストールが正常に完了しました) 画面が表示されたら、 [Finish](完了) を選択します。
次のコマンドを使用して、libqt4 および libyui-qt パッケージをインストールします。
zypper -n install libqt4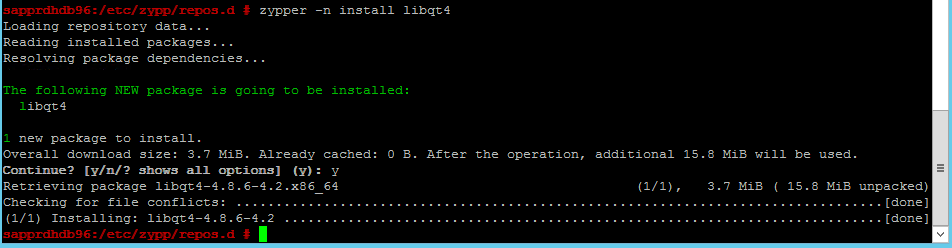
zypper -n install libyui-qt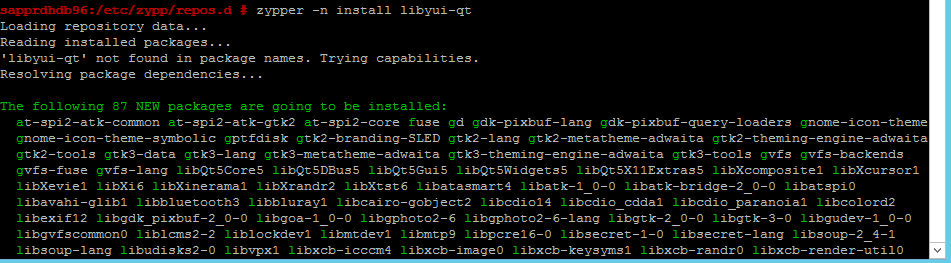

yast2 で GUI を表示できるようになります。
![[Software]\(ソフトウェア\) と [Online Update]\(オンライン更新\) が選択された YaST Control Center を示すスクリーンショット。](media/howtohli/hasetupwithfencing/yast2-control-center.png)
シナリオ 3: yast2 に高可用性オプションが表示されない
高可用性オプションを yast2 Control Center に表示するには、他のパッケージもインストールする必要があります。
[Yast2]>[Software](ソフトウェア)>[Software Management](ソフトウェア管理) に移動します。 次に、 [Software](ソフトウェア)>[Online Update](オンライン更新) を選択します。
次の項目のパターンを選択します。 次に [Accept](承認) を選択します。
- SAP HANA サーバー ベース
- C/C++ コンパイラとツール
- 高可用性
- SAP アプリケーション サーバー ベース
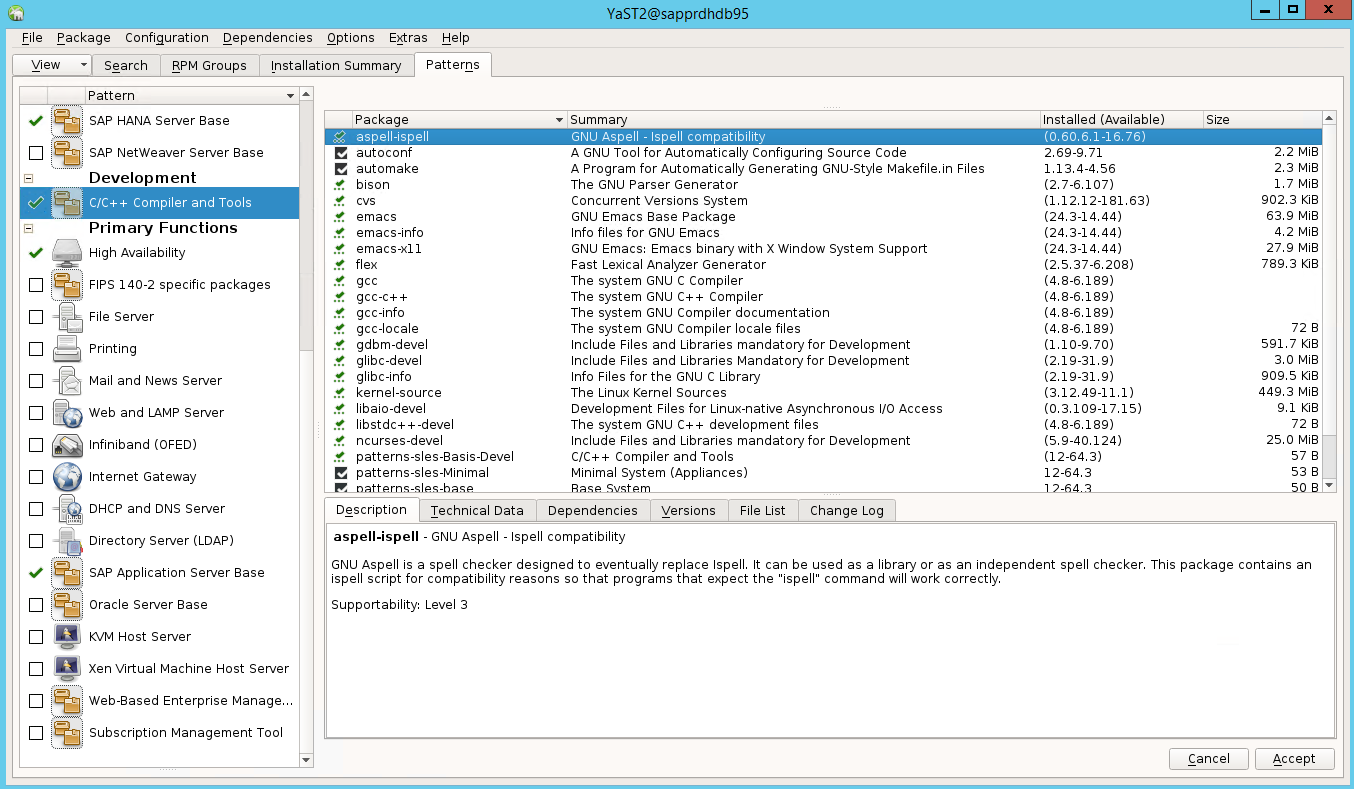
依存関係を解決するように変更されたパッケージの一覧で、 [Continue](続行) を選択します。
![依存関係を解決するように変更されたパッケージが表示された [Changed Packages]\(変更されたパッケージ\) ダイアログを示すスクリーンショット。](media/howtohli/hasetupwithfencing/yast-changed-packages.png)
[Performing Installation](インストールの実行中) 状態ページで、 [Next](次へ) を選択します。
![[Performing Installation]\(インストールの実行中\) 状態ページが示されたスクリーンショット。](media/howtohli/hasetupwithfencing/yast2-performing-installation.png)
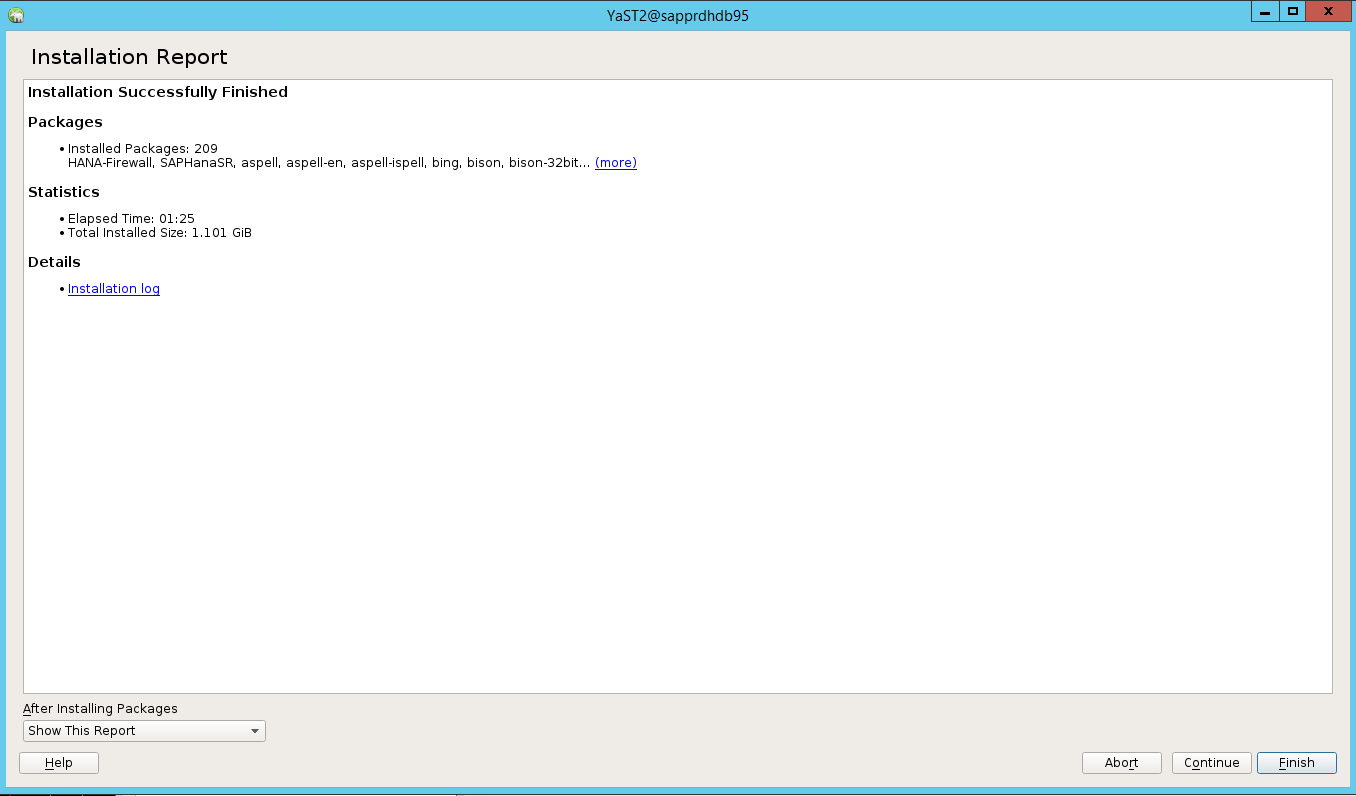
インストールが完了すると、インストール レポートが表示されます。 [完了] を選択します。
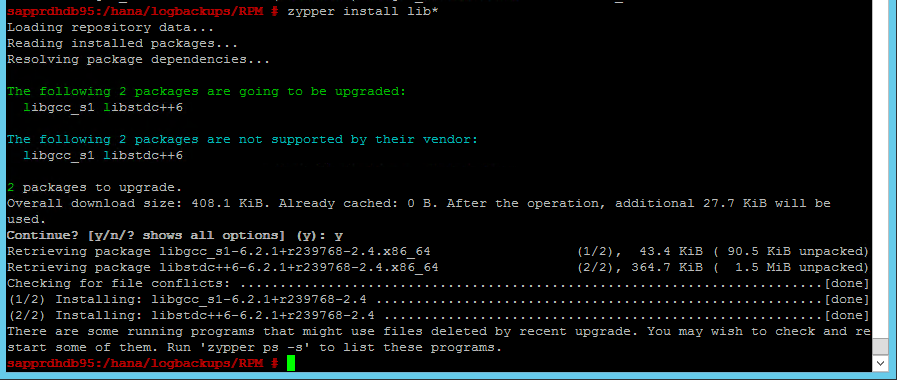
シナリオ 4: gcc アセンブリ エラーが出て HANA のインストールが失敗する
HANA のインストールに失敗すると、次のようなエラーが発生することがあります。
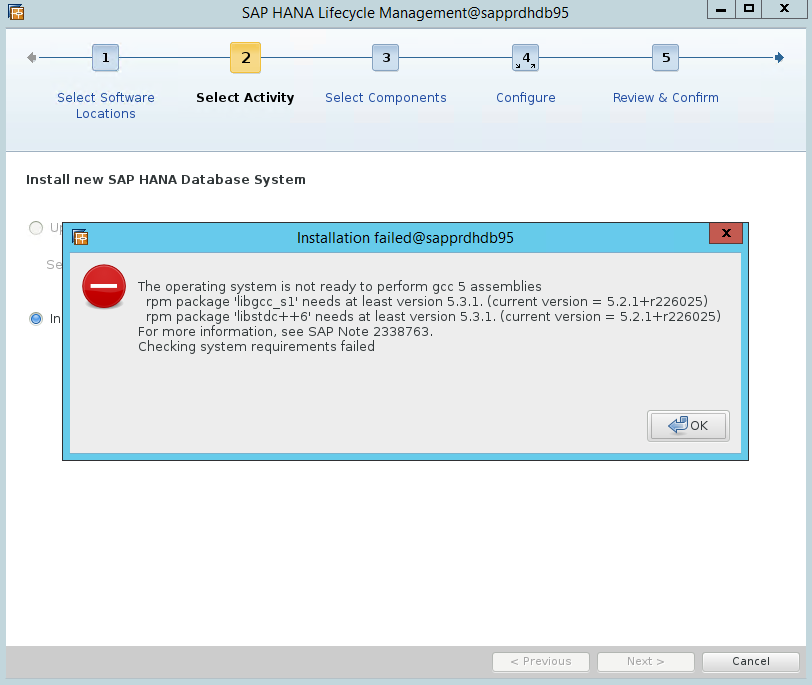
この問題を解決するには、次のスクリーンショットに示すように、libgcc_sl と libstdc++6 のライブラリをインストールします。
シナリオ 5: Pacemaker サービスが失敗する
pacemaker サービスを開始できない場合は、次の情報が表示されます。
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
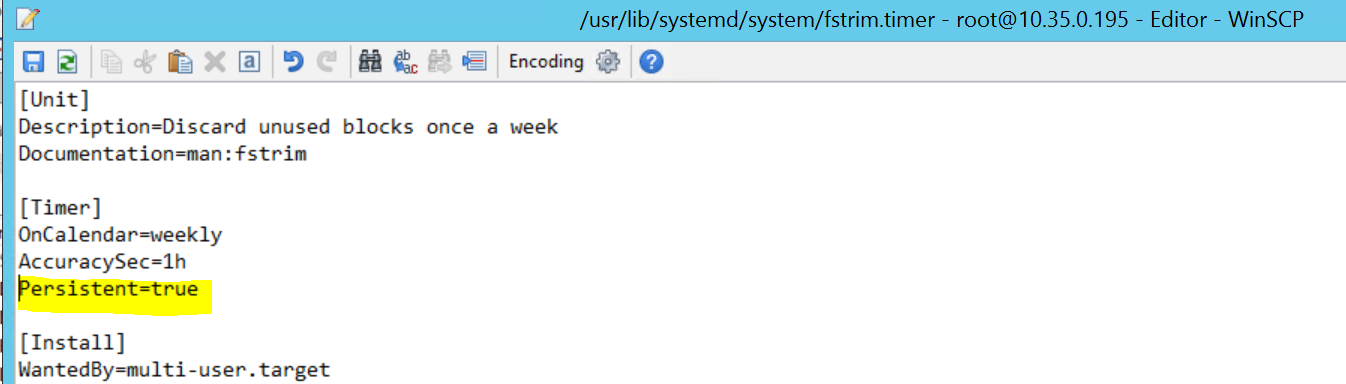
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
これを修正するには、 /usr/lib/systemd/system/fstrim.timer ファイルから次の行を削除します。
Persistent=true
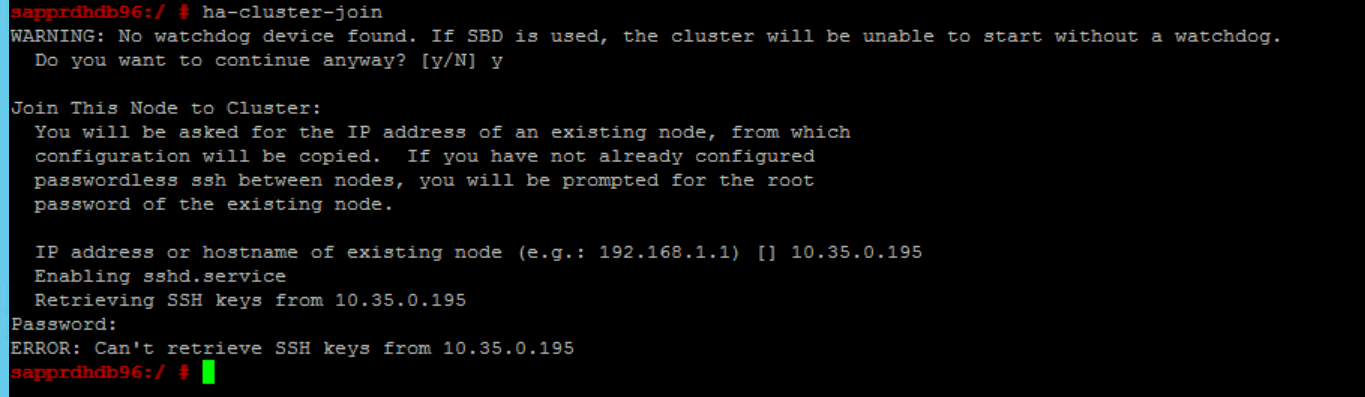
シナリオ 6: Node2 がクラスターに参加できない
ha-cluster-join コマンドを使用して node2 を既存のクラスターに参加させる操作に問題がある場合は、次のようなエラーが表示されます。
ERROR: Can’t retrieve SSH keys from <Primary Node>
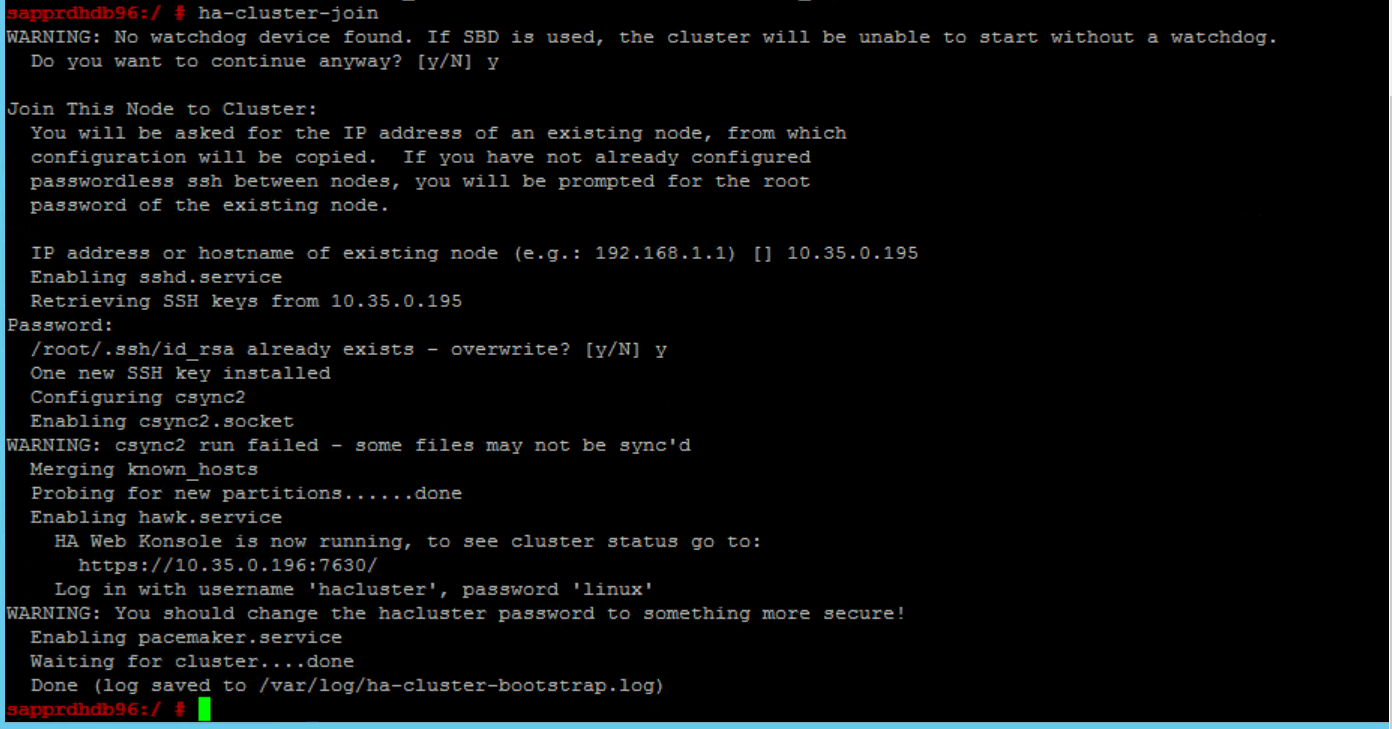
これを修正するには:
"両方のノード" 上で次のコマンドを実行します。
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

node2 がクラスターに追加されたことを確認します。
次のステップ
SUSE HA のセットアップについて詳しくは、次の記事をご覧ください。
- SAP HANA SR Performance Optimized Scenario (SAP HANA SR パフォーマンス最適化シナリオ) (SUSE Web サイト)
- フェンスとフェンス デバイス (SUSE Web サイト)
- Be Prepared for Using Pacemaker Cluster for SAP HANA - Part 1: Basics (Pacemaker Cluster for SAP HANA を使用するための準備 - パート 1: 基本) (SAP ブログ)
- Be Prepared for Using Pacemaker Cluster for SAP HANA – Part 2: Failure of Both Nodes (Pacemaker Cluster for SAP HANA を使用するための準備 - パート 2: 両方のノードの失敗) (SAP ブログ)
- OS のバックアップと復元