SUSE Linux Enterprise Server 上の Azure VM での SAP HANA の高可用性
オンプレミスの SAP HANA デプロイで高可用性を確立するために、SAP HANA システム レプリケーションまたは共有ストレージを使用することができます。
現在、Azure 仮想マシン (VM) 上では、Azure 上の SAP HANA システム レプリケーションがサポートされている唯一の高可用性機能です。
SAP HANA システム レプリケーション は、1 つのプライマリ ノードと、少なくとも 1 つのセカンダリ ノードで構成されています。 プライマリ ノードのデータに対する変更は、セカンダリ ノードに同期的または非同期的にレプリケートされます。
この記事では、VM のデプロイおよび構成方法、クラスター フレームワークのインストール方法、SAP HANA システム レプリケーションのインストールおよび構成方法について説明します。
始める前に、次の SAP のノートとペーパーをお読みください:
- SAP ノート 1928533。 ノートには次のものが含まれます。
- SAP ソフトウェアのデプロイでサポートされる Azure VM サイズの一覧。
- Azure VM サイズの容量に関する重要な情報。
- サポートされる SAP ソフトウェア、およびオペレーティング システム (OS) とデータベースの組み合わせ。
- Microsoft Azure 上の Windows と Linux に必要な SAP カーネル バージョン
- SAP Note 2015553: SAP でサポートされる Azure 上の SAP ソフトウェア デプロイの前提条件が記載されています。
- SAP Note 2205917: SUSE Linux Enterprise Server 12 (SLES 12) for SAP Applications 向けの推奨 OS 設定が記載されています。
- SAP Note 2684254: SUSE Linux Enterprise Server 15 (SLES 15) for SAP Applications 向けの推奨 OS 設定が記載されています。
- SAP Note 2235581: SAP HANA でサポートされているオペレーティング システムが記載されています
- SAP Note 2178632: Azure 上の SAP について報告されるすべての監視メトリックに関する詳細情報が記載されています。
- SAP Note 2191498: Azure 上の Linux に必要な SAP ホスト エージェントのバージョンが記載されています。
- SAP Note 2243692: Azure の Linux で動作する SAP のライセンスに関する情報が記載されています。
- SAP Note 1984787: SUSE Linux Enterprise Server 12 に関する一般情報が記載されています。
- SAP Note 1999351はAzure Enhanced モニタリング拡張機能 for SAP に関するその他のトラブルシューティング情報が記載されています。
- SAP Note 401162: HANA システム レプリケーションを設定するときに "アドレスは既に使用中です" というエラーを回避する方法に関する情報が記載されています。
- SAP Community Support Wiki: Linux に必要なすべての SAP Note が記載されています。
- SAP HANA 認定 IaaS プラットフォーム。
- Linux 上の SAP のための Azure Virtual Machines の計画と実装に関するガイド
- Linux 上の SAP のための Azure Virtual Machines のデプロイ ガイド。
- Linux 上の SAP のための Azure Virtual Machines DBMS のデプロイに関するガイド
- SUSE Linux Enterprise Server for SAP Applications 15 ベスト プラクティス ガイド および SUSE Linux Enterprise Server for SAP Applications 12 ベスト プラクティス ガイド:
- SAP HANA SR パフォーマンス最適化インフラストラクチャの設定 (SLES for SAP Applications) に関するガイド。 このガイドには、SAP HANA システム レプリケーションをオンプレミス開発で設定するときに必要なすべての情報が記載されています。 このガイドをベースラインとして使用します。
- SAP HANA SR コスト最適化インフラストラクチャの設定 (SLES for SAP Applications) に関するガイド。
SAP HANA の高可用性の計画
高可用性を実現するには、2 つの VM に SAP HANA をインストールします。 データは、HANA システム レプリケーションを使用してレプリケートされます。

SAP HANA システム要件の設定では、専用の仮想ホスト名と仮想 IP アドレスが使用されます。 Azure では、仮想 IP アドレスをデプロイするためのロード バランサーが必要です。
上の図は、これらが構成されたロード バランサーの例を示しています。
- フロントエンド IP アドレス: 10.0.0.13 (HN1-db)
- プローブ ポート: 62503
インフラストラクチャの準備
SAP HANA のリソース エージェントは、SUSE Linux Enterprise Server for SAP Applications に含まれています。 Azure Marketplace には、SUSE Linux Enterprise Server for SAP Applications 12 または 15 の画像が掲載されています。 この画像を使用して新しい VM をデプロイできます。
Azure portal 経由での手動による Linux VM のデプロイ
このドキュメントは、リソース グループ、Azure Virtual Network、サブネットが既にデプロイ済みであることを前提としています。
SAP HANA 用の仮想マシンをデプロイします。 HANA システムでサポートされている適切な SLES イメージを選択します。 VM は、仮想マシン スケール セット、可用性ゾーン、可用性セットのいずれかの可用性オプションでデプロイできます。
重要
選択した OS が、デプロイで使用する予定の特定の種類の VM 上の SAP HANA に対して SAP 認定されていることを確認してください。 SAP HANA 認定されている VM の種類とその OS リリースは、「SAP HANA 認定されている IaaS プラットフォーム」で調べることができます。 特定の VM の種類に対して SAP HANA でサポートされている OS のリリースの完全な一覧を取得するために、VM の種類の詳細を確認するように注意してください。
Azure Load Balancer の構成
VM 構成中に、ネットワーク セクションでロード バランサーを作成するか既存のものを選択する選択肢もあります。 HANA データベースの高可用性セットアップ用に Standard Load Balancer をセットアップするには、次の手順のようにします。
- Azure Portal
- Azure CLI
- PowerShell
Azure portal を使って高可用性 SAP システム用の標準ロード バランサーを設定するには、「ロード バランサーの作成」の手順に従います。 ロード バランサーのセットアップ時には、以下の点を考慮してください。
- フロントエンド IP 構成: フロントエンド IP を作成します。 お使いのデータベース仮想マシンと同じ仮想ネットワークとサブネットを選択します。
- バックエンド プール: バックエンド プールを作成し、データベース VM を追加します。
- インバウンド規則: 負荷分散規則を作成します。 両方の負荷分散規則で同じ手順に従います。
- フロントエンド IP アドレス: フロントエンド IP を選択します。
- バックエンド プール: バックエンド プールを選択します。
- 高可用性ポート: このオプションを選択します。
- [プロトコル]: [TCP] を選択します。
- 正常性プローブ: 次の詳細を使って正常性プローブを作成します。
- [プロトコル]: [TCP] を選択します。
- ポート: 例: 625<インスタンス番号>。
- サイクル間隔: 「5」と入力します。
- プローブしきい値: 「2」と入力します。
- アイドル タイムアウト (分): 「30」と入力します。
- フローティング IP を有効にする: このオプションを選択します。
Note
正常性プローブ構成プロパティ numberOfProbes (ポータルでは [異常なしきい値] とも呼ばれます) は考慮されません。 成功または失敗した連続プローブの数を制御するには、プロパティ probeThreshold を 2 に設定します。 現在、このプロパティは Azure portal を使用して設定できないため、Azure CLI または PowerShell コマンドを使用してください。
SAP HANA に必要なポートについて詳しくは、SAP HANA テナント データベース ガイドのテナント データベースへの接続に関する章または SAP Note 2388694 を参照してください。
Note
パブリック IP アドレスを持たない VM が Azure Load Balancer の内部 (パブリック IP アドレスがない) 標準インスタンスのバックエンド プールに配置されている場合、既定の構成ではインターネットへの送信接続はありません。 追加の手順を実行して、パブリック エンドポイントへのルーティングを許可することができます。 送信接続を実現する方法の詳細については、「SAP の高可用性シナリオにおける Azure Standard Load Balancer を使用した VM のパブリック エンドポイント接続」を参照してください。
重要
- Azure Load Balancer の背後に配置された Azure VM では TCP タイムスタンプを有効にしないでください。 TCP タイムスタンプを有効にすると正常性プローブが失敗します。 パラメータ
net.ipv4.tcp_timestampsを0にセットします。 詳細については、「Load Balancer の正常性プローブ」または SAP Note 2382421 を参照してください。 - 手動で設定した
net.ipv4.tcp_timestampsの値0が、saptune によって1に戻されないようにするには、saptune のバージョンを 3.1.1 以降に更新します。 詳細については、「saptune 3.1.1 – 更新する必要がありますか?」を参照してください。
Pacemaker クラスターの作成
「Set up Pacemaker on SUSE Linux Enterprise Server in Azure (Azure で SUSE Linux Enterprise Server に Pacemaker を設定する)」の手順に従って、この HANA サーバーに対して基本的な Pacemaker クラスターを作成します。 SAP HANA および SAP NetWeaver (A) SCS に対して同じ Pacemaker クラスターを使用することができます。
SAP HANA のインストール
このセクションの手順では、次のプレフィックスを使用します。
- [A] :この手順はすべてのノードに適用されます。
- [1]: この手順はノード 1 にのみ適用されます。
- [2]: この手順は Pacemaker クラスターのノード 2 にのみ適用されます。
<placeholders> を SAP HANA インストールの値に置き換えます。
[A] 論理ボリューム マネージャー (LVM) を使用してディスクのレイアウトを設定します。
データおよびログ ファイルを格納するボリュームには、LVM を使用することをお勧めします。 次の例は、VM に 4 つのデータ ディスクがアタッチされていて、これを使用して 2 つのボリュームを作成することを前提としています。
次のコマンドを実行して、使用可能なすべてのディスクを一覧表示します。
/dev/disk/azure/scsi1/lun*出力例:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3使用するすべてのディスクの物理ボリュームを作成します。
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3データ ファイル用のボリューム グループを作成します。 ログ ファイル用に 1 つ、SAP HANA の共有ディレクトリ用に 1 つのボリューム グループを作成します。
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3論理ボリュームを作成します。
-iスイッチを指定せずにlvcreateを使用すると、線形のボリュームが作成されます。 I/O パフォーマンスが向上するように、"ストライプ" ボリュームを作成することお勧めします。 ストライプ サイズは、SAP HANA VM ストレージ構成に関するページ説明されている値に合わせます。-i引数は、基になる物理ボリュームの数、-I引数はストライプ サイズにする必要があります。たとえば、データ ボリュームに 2 つの物理ボリュームが使用されている場合、
-iスイッチ引数は 2 に設定され、データ ボリュームのストライプ サイズは 256KiB に設定されます。 ログ ボリューム用に物理ボリュームが 1 つ使用されるため、ログ ボリューム コマンドに対して-iおよび-Iスイッチは明示的には使用されません。重要
データ ボリューム、ログ ボリューム、または共有ボリュームごとに複数の物理ボリュームを使用する場合は、
-iスイッチを使用して基になる物理ボリュームの数を設定します。 ストライプ ボリュームを作成する場合は、-Iスイッチを使用してストライプ サイズを指定します。ストライプ サイズやディスク数など、推奨されるストレージ構成については、SAP HANA VM のストレージ構成に関する記事を参照してください。
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_sharedマウント ディレクトリを作成し、すべての論理ボリュームの UUID をコピーします。
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkid/etc/fstab ファイルを編集して、3 つの論理ボリュームの
fstabエントリを作成します。sudo vi /etc/fstab/etc/fstab ファイルに次の行を挿入します。
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2新しいボリュームをマウントします。
sudo mount -a
[A] プレーン ディスクを使用してディスク レイアウトを設定します。
デモ システムの場合、ご自身の HANA のデータとログ ファイルを 1 つのディスクに配置することができます。
/dev/disk/azure/scsi1/lun0 にパーティションを作成し、XFS を使用してフォーマットします。
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstab/etc/fstab ファイルにこの行を挿入します。
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2ターゲット ディレクトリを作成してディスクをマウントします。
sudo mkdir /hana sudo mount -a
[A] すべてのホストにホスト名解決を設定します。
DNS サーバーを使用するか、すべてのノードの /etc/hosts ファイルを変更することができます。 この例では、/etc/hosts ファイルを使用する方法を示します。 次のコマンドで、IP アドレスとホスト名を置き換えます。
/etc/hosts ファイルを編集します。
sudo vi /etc/hosts次の行を /etc/hosts ファイルに挿入します。 お使いの環境に合わせて IP アドレスとホスト名を変更します。
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] SAP のドキュメントに従って、SAP HANA をインストールします。
SAP HANA 2.0 システム レプリケーションの構成
このセクションの手順では、次のプレフィックスを使用します。
- [A] :この手順はすべてのノードに適用されます。
- [1]: この手順はノード 1 にのみ適用されます。
- [2]: この手順は Pacemaker クラスターのノード 2 にのみ適用されます。
<placeholders> を SAP HANA インストールの値に置き換えます。
[1] テナント データベースを作成します。
SAP HANA 2.0 または SAP HANA MDC を使用している場合は、ご自身の SAP NetWeaver システムに対してテナント データベースを作成します。
<HANA SID>adm として次のコマンドを実行します。
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] 最初のノードでシステム レプリケーションを構成します。
まず、<HANA SID>adm としてデータベースをバックアップします。
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"次に、システム公開キー基盤 (PKI) ファイルをセカンダリ サイトにコピーします。
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/プライマリ サイトを作成します。
hdbnsutil -sr_enable --name=<site 1>[2] 2 番目のノードでシステム レプリケーションを構成します。
2 番目のノードを登録して、システム レプリケーションを開始します。
<HANA SID>adm として次のコマンドを実行します。
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
HANA リソース エージェントを実装する
SUSE には、SAP HANA を管理するために、2 つの異なる Pacemaker リソース エージェント向けソフトウェア パッケージが用意されています。 ソフトウェア パッケージ SAPHanaSR と SAPHanaSR-angi では、使用されている構文が若干異なっており、互換性がありません。 SAPHanaSR と SAPHanaSR-angi の詳細と相違点については、SUSE のリリース ノートとドキュメントを参照してください。 このドキュメントでは、両方のパッケージについて、各セクションの個別のタブで説明します。
警告
既に構成済みのクラスターでは、パッケージ SAPHanaSR を SAPHanaSR-angi に置き換えないでください。 SAPHanaSR から SAPHanaSR-angi にアップグレードするには、特定の手順が必要です。
- [A] SAP HANA 高可用性パッケージをインストールします。
次のコマンドを実行して、高可用性パッケージをインストールします。
sudo zypper install SAPHanaSR
SAP HANA HA/DR プロバイダーを設定する
SAP HANA HA/DR プロバイダーにより、クラスターとの統合が最適化され、クラスターのフェールオーバーが必要になった場合の検出が向上します。 主なフック スクリプトは、SAPHanaSR (SAPHanaSR パッケージの場合)/susHanaSR (SAPHanaSR-angi の場合) です。 SAPHanaSR/susHanaSR Python フックを構成することを強くお勧めします。 HANA 2.0 SPS 05 以降では、SAPHanaSR/susHanaSR フックと susChkSrv フックの両方を実装することをお勧めします。
susChkSrv は、主要 SAPHanaSR/susHanaSR HA プロバイダーの機能を拡張します。 これは、HANA プロセス hdbindexserver がクラッシュした場合に機能します。 1 つのプロセスがクラッシュした場合、通常、HANA は再起動を試みます。 indexserver プロセスの再起動には長時間かかる場合があり、その間は HANA データベースが応答しません。
susChkSrv が実装されるとすぐに、構成可能なアクションが実行されます。 このアクションは、hdbindexserver プロセスが同じノードで再起動するのを待たず、構成されたタイムアウト期間にフェールオーバーをトリガーします。
- [A] 両方のノードで HANA を停止します。
次のコードを <sap-sid>adm として実行します。
sapcontrol -nr <instance number> -function StopSystem
[A] HANA システム レプリケーション フックをインストールします。 フックは両方の HANA データベース ノードにインストールする必要があります。
ヒント
SAPHanaSR Python フックは、HANA 2.0 にのみ実装できます。 SAPHanaSR パッケージは、バージョン 0.153 以上である必要があります。
SAPHanaSR-angi Python フックは、HANA 2.0 SPS 05 以降にのみ実装できます。
susChkSrv Python フックには SAP HANA 2.0 SPS 05 が必要です。さらに、SAPHanaSR バージョン 0.161.1_BF 以降がインストールされている必要があります。[A] 各クラスター ノードで global.ini を調整します。
susChkSrv フックの要件が満たされていない場合は、次のパラメータから
[ha_dr_provider_suschksrv]ブロック全体を削除します。action_on_lostパラメータを使用して、susChkSrvの動作を調整できます。 有効な値は [ignore|stop|kill|fence] です。[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR execution_order = 3 action_on_lost = fence [trace] ha_dr_saphanasr = info既定の場所
/usr/share/SAPHanaSRへのパラメーター パスをポイントすると、OS の更新プログラムまたはパッケージの更新によって Python フック コードの更新が自動的に行われます。 HANA は、次回再起動するときにフック コードの更新を使用します。/hana/shared/myHooksなどの省略可能な独自のパスを使用すると、使用するフック バージョンから OS 更新プログラムを切り離すことができます。[A] クラスターでは、<sap-sid>adm の各クラスター ノードで sudoers を構成する必要があります。 この例では、新しいファイルを作成することでそれを実現します。
root として次のコマンドを実行します。 <sid> を小文字の SAP システム ID、<SID> を大文字の SAP システム ID、<siteA/B> を、選択した HANA サイト名に置き換えます。
cat << EOF > /etc/sudoers.d/20-saphana # Needed for SAPHanaSR and susChkSrv Python hooks Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HELPER_TAKEOVER = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=checkTakeover Cmnd_Alias HELPER_FENCE = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=fenceMe <sid>adm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB, HELPER_TAKEOVER, HELPER_FENCE EOF
SAP HANA システム レプリケーション フックの実装の詳細については、HANA HA/DR プロバイダーの設定に関するページを参照してください。
[A] 両方のノードで SAP HANA を開始します。 <sap-sid>adm として次のコマンドを実行します。
sapcontrol -nr <instance number> -function StartSystem[1] フックのインストールを確認します。 アクティブな HANA システム レプリケーション サイト <sap-sid>adm として次のコマンドを実行します。
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example output # 2021-04-08 22:18:15.877583 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:18:46.531564 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:21:26.816573 ha_dr_SAPHanaSR SOK
- [1] susChkSrv フックのインストールを確認します。
HANA VM で次のコマンドを <sap-sid>adm として実行します。
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
SAP HANA クラスター リソースの作成
- [1] 最初に、HANA トポロジ リソースを作成します。
Pacemaker クラスター ノードのいずれかで、次のコマンドを実行します。
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
operations \$id="rsc_sap2_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" target-role="Started" interleave="true"
- [1] 次に、HANA リソースを作成します。
Note
この記事には、Microsoft が使用しなくなった用語への言及が含まれています。 ソフトウェアからこれらの用語が削除された時点で、この記事から削除します。
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHana_<HANA SID>_HDB<instance number> ocf:suse:SAPHana \
operations \$id="rsc_sap_<HANA SID>_HDB<instance number>-operations" \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false"
# Run the following command if the cluster nodes are running on SLES 12 SP05.
sudo crm configure ms msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true"
# Run the following command if the cluster nodes are running on SLES 15 SP03 or later.
sudo crm configure clone msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true" promotable="true"
sudo crm resource meta msl_SAPHana_<HANA SID>_HDB<instance number> set priority 100
- [1] 仮想 IP、既定値、制約のクラスター リソースに進みます。
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_ip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Master
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHana_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHana_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
重要
AUTOMATED_REGISTER の false への設定は、フェールオーバー テストの完了中にのみ行うことをお勧めします。これにより、失敗したプライマリ インスタンスがセカンダリとして自動的に登録されるのを防ぐことができます。 フェールオーバー テストが正常に完了したら、AUTOMATED_REGISTER を trueに設定して、引き継ぎ後にシステム レプリケーションが自動的に再開されるようにします。
クラスターの状態が OK であること、すべてのリソースが起動されていることを確認します。 リソースがどのノードで実行されているかは重要ではありません。
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Pacemaker クラスターで HANA アクティブ/読み取り可能のシステム レプリケーションを構成する
SAP HANA 2.0 SPS 01 以降のバージョンでは、SAP では SAP HANA システム レプリケーションに対してアクティブかつ読み取り可能なセットアップが可能になりました。 このシナリオでは、読み取りを集中的に行うワークロードに対して、SAP HANA システム レプリケーションのセカンダリ システムをアクティブに使用できます。
クラスターでこの設定をサポートするには、2 番目の仮想 IP アドレスが必要です。これにより、セカンダリ読み取りが有効な SAP HANA データベースにクライアントからアクセスできます。 引き継ぎ後もセカンダリ レプリケーション サイトにアクセスできるようにするために、クラスターは SAPHana リソースのセカンダリと共に仮想 IP アドレスを移動する必要があります。
このセクションでは、2 番目の仮想 IP アドレスを使用して、SUSE 高可用性クラスターで HANA のアクティブ/読み取り可能のシステム レプリケーションを管理するために必要な追加の手順について説明します。
先に進む前に、前のセクションで説明されているように、SAP HANA データベースを管理する SUSE 高可用性クラスターが完全に構成されていることを確認してください。
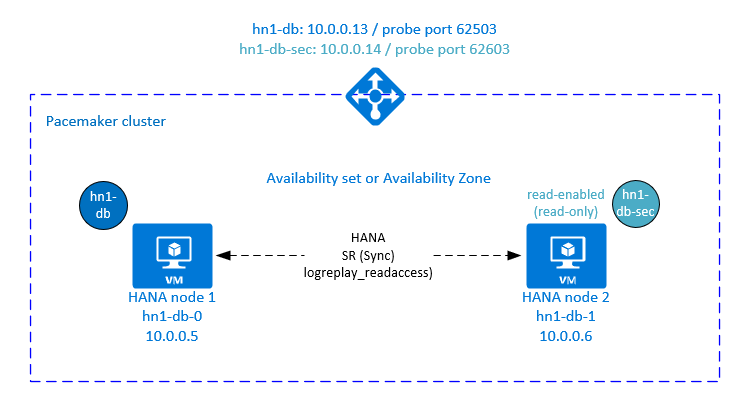
アクティブかつ読み取り可能なシステム レプリケーション用にロード バランサーを設定する
2 つ目の仮想 IP をプロビジョニングする追加の手順を続行するには、「Azure portal を使用して Linux VM を手動でデプロイする」の説明に従って Azure Load Balancer を構成していることを確認します。
Standard ロード バランサーの場合は、前に作成したのと同じロード バランサーでこれらの追加の手順を実行します。
- 2 番目のフロントエンド IP プールを作成する:
- ロード バランサーを開き、 [frontend IP pool](フロントエンド IP プール) を選択して [Add](追加) を選択します
- この 2 番目のフロントエンド IP プールの名前を入力します (例: hana-secondaryIP)。
- [割り当て] を [静的] に設定し、IP アドレスを入力します (例: 10.0.0.14)。
- [OK] を選択します。
- 新しいフロントエンド IP プールが作成されたら、フロントエンド IP アドレスを書き留めます。
- 正常性プローブを作成する:
- ロード バランサーで、[Health probes] (正常性プローブ) を選択して [追加] を選びます。
- 新しい正常性プローブの名前を入力します (例: hana-secondaryhp)。
- プロトコルとして TCP を、ポートは 626<インスタンス番号>を選択します。 [Interval]\(間隔\) の値を 5 に設定し、[Unhealthy threshold]\(異常しきい値\) の値を 2 に設定します。
- [OK] を選択します。
- 負荷分散規則を作成します。
- ロード バランサーで、[load balancing rules] (負荷分散規則) を選択して [追加] を選択します。
- 新しいロード バランサー規則の名前を入力します (例: hana-secondarylb)。
- 前の手順で作成したフロントエンド IP アドレス、バックエンド プール、正常性プローブを選択します (例: hana-secondaryIP、hana-backend、hana-secondaryhp)。
- [HA ポート] を選択します。
- アイドル タイムアウトを 30 分に増やします。
- フローティング IP を有効にしていることを確認します。
- [OK] を選択します。
HANA のアクティブかつ読み取り可能のシステム レプリケーションの設定
HANA システム レプリケーションを構成する手順については、「SAP HANA 2.0 システム レプリケーションの構成」を参照してください。 読み取り可能なセカンダリ シナリオをデプロイする場合、2 番目のノードでシステム レプリケーションを設定するときに、次のコマンドを <HANA SID>adm として実行します。
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
セカンダリ仮想 IP アドレス リソースを追加する
次のコマンドを使用して、2 番目の仮想 IP と適切なコロケーション制約を設定できます。
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_secip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Slave
crm configure property maintenance-mode=false
クラスターの状態が OK であること、すべてのリソースが起動されていることを確認します。 2 番目の仮想 IP は、SAPHana セカンダリ リソースと共にセカンダリ サイトで実行されます。
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
次のセクションでは、実行する一般的なフェールオーバー テストのセットを示します。
読み取りが可能なセカンダリで構成された HANA クラスターをテストする場合の考慮事項:
SAPHana_<HANA SID>_HDB<instance number>クラスター リソースをhn1-db-1に移行すると、2 つ目の仮想 IP はhn1-db-0に移動します。AUTOMATED_REGISTER="false"を構成していて、HANA システム レプリケーションが自動的に登録されていない場合は、2 番目の仮想 IP がサーバーがhn1-db-0で実行されます。このサーバーが使用可能であり、クラスター サービスがオンラインであるためです。サーバーのクラッシュをテストする場合、2 番目の仮想 IP リソース (
rsc_secip_<HANA SID>_HDB<instance number>) と Azure ロード バランサーのポート リソース (rsc_secnc_<HANA SID>_HDB<instance number>) は、プライマリ仮想 IP リソースと共にプライマリ サーバー上で実行されます。 セカンダリ サーバーが停止している間、読み取り可能な HANA データベースに接続されているアプリケーションは、プライマリ HANA データベースに接続します。 この動作は想定どおりです。セカンダリ サーバーが使用できない間も、読み取り可能な HANA データベースに接続されているアプリケーションにアクセスできるようにするためです。セカンダリ サーバーが使用可能で、クラスター サービスがオンラインになっているときは、HANA システム レプリケーションがセカンダリとして登録されていなくても、2 番目の仮想 IP とポート リソースが自動的にセカンダリ サーバーに移行します。 そのサーバーでクラスター サービスを開始する前に、セカンダリ HANA データベースを読み取り可能として登録しておいてください。 パラメータ
AUTOMATED_REGISTER="true"を設定することで、セカンダリを自動的に登録するように HANA インスタンスのクラスター リソースを構成できます。フェールオーバーとフォールバックの間は、2 番目の仮想 IP を使用して HANA データベースに接続するアプリケーションの既存の接続が中断される場合があります。
クラスターの設定をテストする
ここでは、設定をテストする方法について説明します。 すべてのテストでは、ルートとしてサインインしていること、SAP HANA マスターが hn1-db-0 VM で実行されていることを前提としています。
移行をテストする
テストを開始する前に、Pacemaker に (crm_mon -r を実行して) 失敗したアクションがないこと、予期しない場所の制約 (たとえば移行テストの残り物) がないこと、HANA が (たとえば SAPHanaSR-showAttr を実行して) 同期していることを確認します。
hn1-db-0:~ # SAPHanaSR-showAttr
Sites srHook
----------------
SITE2 SOK
Global cib-time
--------------------------------
global Mon Aug 13 11:26:04 2018
Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED 1534159564 online logreplay nws-hana-vm-1 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.030.00.1522209842 nws-hana-vm-0
hn1-db-1 DEMOTED 30 online logreplay nws-hana-vm-0 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.030.00.1522209842 nws-hana-vm-1
次のコマンドを実行して、SAP HANA マスター ノードを移行できます。
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
クラスターは、SAP HANA マスター ノードと仮想 IP アドレスを含むグループを hn1-db-1 に移行します。
移行が完了すると、crm_mon -r 出力は次の例のようになります。
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
AUTOMATED_REGISTER="false" では、クラスターは障害が発生した HANA データベースを再起動したり、hn1-db-0 の新しいプライマリに対して登録したりしません。 その場合は、次のコマンドを実行して HANA のインスタンスをセカンダリとして構成してください。
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
移行では場所の制約が作成されますが、これは再度削除する必要があります。
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
また、セカンダリ ノードのリソースの状態をクリーンアップする必要があります。
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
crm_mon -r を使用して HANA リソースの状態を監視します。 hn1-db-0 で HANA を起動すると、出力は次の例のようになります。
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
ネットワーク通信のブロック
テスト開始前のリソースの状態:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
ファイアウォール規則を実行して、いずれかのノードでの通信をブロックします。
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
クラスター ノードが相互に通信できない場合、スプリット ブレイン シナリオのリスクがあります。 このような状況では、クラスター ノードは互いに同時にフェンスを試行し、フェンス レースを引き起こします。
フェンス デバイスを構成する場合は、pcmk_delay_max プロパティを構成することをお勧めします。 そのため、スプリット ブレイン シナリオの場合、クラスターでは、各ノードのフェンシング アクションに、pcmk_delay_max 値までのランダムな遅延が発生します。 最も短い遅延を持つノードがフェンシング用に選択されます。
さらに、HANA マスターを実行しているノードが優先され、スプリット ブレイン シナリオでフェンス レースに勝つよう、クラスター構成でプロパティ priority-fencing-delay 設定することをお勧めします。 priority-fencing-delay プロパティを有効にすると、クラスターでは、特に HANA マスター リソースをホストしているノードに対してフェンシング アクションに遅延が発生し、ノードがフェンス レースに勝つ可能性があります。
次のコマンドを実行して、ファイアウォール規則を削除します。
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
SBD フェンスをテストする
SBD の設定をテストするには、inquisitor プロセスを強制終了します:
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
<HANA SID>-db-<database 1> クラスター ノードが再起動します。 Pacemaker サービスが再起動しない可能性があります。 その場合、もう一度起動してください。
手動フェールオーバーをテストする
手動フェールオーバーをテストするには、hn1-db-0 ノードで Pacemaker サービスを停止します。
service pacemaker stop
フェールオーバー後、サービスを再度開始できます。 AUTOMATED_REGISTER="false" を設定した場合、hn1-db-0 ノードの SAP HANA リソースはセカンダリとして起動できません。
その場合は、次のコマンドを実行して HANA のインスタンスをセカンダリとして構成してください。
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
SUSE のテスト
重要
選択した OS が、使用する予定の特定の VM の種類で SAP HANA に対して SAP から認定されていることを確認してください。 SAP HANA 認定されている VM の種類とその OS リリースは、「SAP HANA 認定されている IaaS プラットフォーム」で調べることができます。 使用する VM の種類に対して SAP HANA でサポートされている OS のリリースの完全な一覧を取得するために、VM の種類の詳細を確認するように注意してください。
シナリオに応じて、「SAP HANA SR Performance Optimized Scenario」(SAP HANA SR パフォーマンス最適化シナリオ) ガイドまたは「SAP HANA SR Cost Optimized Scenario」(SAP HANA SR コスト最適化シナリオ) ガイドに記載されているすべてのテスト ケースを実行します。 SLES for SAP のベスト プラクティスに関するページに記載されているガイドを参照してください。
次のテストは、「SAP HANA SR Performance Optimized Scenario SUSE Linux Enterprise Server for SAP Applications 12 SP1」(SAP HANA SR パフォーマンス最適化シナリオ SUSE Linux Enterprise Server for SAP Applications 12 SP1) ガイドのテストに関する説明のコピーです。 最新バージョンについては、ガイドも参照してください。 テストを開始する前に常に HANA が同期していることを確認し、Pacemaker の設定が正しいことを確認してください。
次のテストの説明は、PREFER_SITE_TAKEOVER="true" と AUTOMATED_REGISTER="false" を想定しています。
Note
次のテストは、順番に実行するように設計されています。 各テストは、前のテストの終了状態によって異なります。
テスト 1: ノード 1 上のプライマリ データベースを停止します。
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-0ノード上で <hana sid>adm として次のコマンドを実行します。hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stop停止した HANA インスタンスが Pacemaker によって検出され、他のノードにフェールオーバーされます。 Pacemaker によってノードが HANA セカンダリとして自動的に登録されないため、フェールオーバーが完了すると、
hn1-db-0ノード上の HANA インスタンスは停止します。次のコマンドを実行して、
hn1-db-0ノードをセカンダリとして登録し、失敗したリソースをクリーンアップします。hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1テスト 2: ノード 2 上のプライマリ データベースを停止します。
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1hn1-db-1ノード上で <hana sid>adm として次のコマンドを実行します。hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stop停止した HANA インスタンスが Pacemaker によって検出され、他のノードにフェールオーバーされます。 Pacemaker によってノードが HANA セカンダリとして自動的に登録されないため、フェールオーバーが完了すると、
hn1-db-1ノード上の HANA インスタンスは停止します。次のコマンドを実行して、
hn1-db-1ノードをセカンダリとして登録し、失敗したリソースをクリーンアップします。hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0テスト 3: ノード 1 上のプライマリ データベースをクラッシュさせます。
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-0ノード上で <hana sid>adm として次のコマンドを実行します。hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9強制停止された HANA インスタンスが Pacemaker によって検出され、他のノードにフェールオーバーされます。 Pacemaker によってノードが HANA セカンダリとして自動的に登録されないため、フェールオーバーが完了すると、
hn1-db-0ノード上の HANA インスタンスは停止します。次のコマンドを実行して、
hn1-db-0ノードをセカンダリとして登録し、失敗したリソースをクリーンアップします。hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1テスト 4: ノード 2 上のプライマリ データベースをクラッシュさせます。
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1hn1-db-1ノード上で <hana sid>adm として次のコマンドを実行します。hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9強制停止された HANA インスタンスが Pacemaker によって検出され、他のノードにフェールオーバーされます。 Pacemaker によってノードが HANA セカンダリとして自動的に登録されないため、フェールオーバーが完了すると、
hn1-db-1ノード上の HANA インスタンスは停止します。次のコマンドを実行して、
hn1-db-1ノードをセカンダリとして登録し、失敗したリソースをクリーンアップします。hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0テスト 5: プライマリ サイト ノード (ノード 1) をクラッシュさせます。
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-0ノードでルートとして次のコマンドを実行します。hn1-db-0:~ # echo 'b' > /proc/sysrq-trigger強制終了されたクラスター ノードが Pacemaker によって検出され、ノードがフェンスされます。 ノードがフェンスされると、Pacemaker で HANA インスタンスの引き継ぎがトリガーされます。 フェンス ノードが再起動されるときに、Pacemaker は自動的に起動しません。
次のコマンドを実行して Pacemaker を起動し、
hn1-db-0ノードの SBD メッセージを消去し、hn1-db-0ノードをセカンダリとして登録し、失敗したリソースをクリーンアップします。# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1テスト 6: セカンダリ サイト ノード (ノード 2) をクラッシュさせます。
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1hn1-db-1ノードでルートとして次のコマンドを実行します。hn1-db-1:~ # echo 'b' > /proc/sysrq-trigger強制終了されたクラスター ノードが Pacemaker によって検出され、ノードがフェンスされます。 ノードがフェンスされると、Pacemaker で HANA インスタンスの引き継ぎがトリガーされます。 フェンス ノードが再起動されるときに、Pacemaker は自動的に起動しません。
次のコマンドを実行して Pacemaker を起動し、
hn1-db-1ノードの SBD メッセージを消去し、hn1-db-1ノードをセカンダリとして登録し、失敗したリソースをクリーンアップします。# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>テスト 7: ノード 2 上のセカンダリ データベースを停止する
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-1ノード上で <hana sid>adm として次のコマンドを実行します。hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stop停止した HANA インスタンスが Pacemaker によって検出され、
hn1-db-1ノード上のリソースは失敗とマークされます。 Pacemaker によって HANA インスタンスが自動的に再起動されます。次のコマンドを実行して、失敗した状態をクリーンアップします。
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0テスト 8: ノード 2 上のセカンダリ データベースをクラッシュさせる
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-1ノード上で <hana sid>adm として次のコマンドを実行します。hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9強制終了された HANA インスタンスが Pacemaker によって検出され、
hn1-db-1ノード上のリソースは失敗とマークされます。 次のコマンドを実行して、失敗した状態をクリーンアップします。 その後、Pacemaker によって HANA インスタンスが自動的に再起動されます。# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0テスト 9: セカンダリ HANA データベースを実行しているセカンダリ サイト ノード (ノード 2) をクラッシュさせます。
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-1ノードでルートとして次のコマンドを実行します。hn1-db-1:~ # echo b > /proc/sysrq-trigger強制終了されたクラスター ノードが Pacemaker によって検出され、ノードがフェンスされます。 フェンス ノードが再起動されるときに、Pacemaker は自動的に起動しません。
次のコマンドを実行して Pacemaker を起動し、
hn1-db-1ノードの SBD メッセージを消去し、失敗したリソースをクリーンアップします。# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0テスト 10: プライマリ データベース インデックスサーバーをクラッシュさせる
このテストは、「HANA リソース エージェントを実装する」で説明されているように、susChkSrv フックを設定した場合にのみ関連します。
テスト開始前のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-0ノードでルートとして次のコマンドを実行します。hn1-db-0:~ # killall -9 hdbindexserverindexserver が終了すると、susChkSrv フックはイベントを検出し、'hn1-db-0' ノードをフェンスして引き継ぎプロセスを開始するアクションをトリガーします。
次のコマンドを実行して、
hn1-db-0ノードをセカンダリとして登録し、失敗したリソースをクリーンアップします。# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0テスト後のリソースの状態:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1セカンダリ ノード上の indexserver をクラッシュさせることで、同等のテスト ケースを実行できます。 indexserver がクラッシュした場合、susChkSrv フックは発生を認識し、セカンダリ ノードをフェンスするアクションを開始します。