Red Hat Enterprise Linux 上の Azure VM での SAP HANA の高可用性
オンプレミス開発の場合、HANA システム レプリケーションまたは共有記憶域を使用して、SAP HANA の高可用性 (HA) を実現できます。 Azure 仮想マシン上では、Azure 上の HANA システム レプリケーションが現在サポートされている唯一の HA 機能です。
SAP HANA レプリケーション は、1 つのプライマリ ノードと、少なくとも 1 つのセカンダリ ノードで構成されています。 プライマリ ノードのデータに対する変更は、セカンダリ ノードに同期的または非同期的にレプリケートされます。
この記事では、仮想マシン (VM) のデプロイおよび構成方法、クラスター フレームワークのインストール方法、SAP HANA システム レプリケーションのインストールおよび構成方法について説明します。
サンプルの構成では、インストールのコマンドで、インスタンス番号として 03、HANA システム ID として HN1 が使用されています。
前提条件
はじめに、次の SAP Note およびガイドを確認してください
- SAP Note 1928533: 次の情報が含まれています。
- SAP ソフトウェアのデプロイでサポートされる Azure VM サイズの一覧。
- Azure VM サイズの容量に関する重要な情報。
- サポートされる SAP ソフトウェア、およびオペレーティング システム (OS) とデータベースの組み合わせ。
- Microsoft Azure 上の Windows と Linux に必要な SAP カーネル バージョン。
- SAP Note 2015553: SAP でサポートされる Azure 上の SAP ソフトウェア デプロイの前提条件が記載されています。
- SAP Note 2002167: Red Hat Enterprise Linux 用の OS 設定が推奨されています。
- SAP Note 2009879: Red Hat Enterprise Linux 用の SAP HANA ガイドラインが記載されています。
- SAP Note 3108302 には、Red Hat Enterprise Linux 9.x 用の SAP HANA ガイドラインがあります。
- SAP Note 2178632: Azure 上の SAP について報告されるすべての監視メトリックに関する詳細情報が記載されています。
- SAP Note 2191498: Azure 上の Linux に必要な SAP Host Agent のバージョンが記載されています。
- SAP Note 2243692: Azure 上の Linux で動作する SAP のライセンスに関する情報が記載されています。
- SAP Note 1999351はAzure Enhanced モニタリング拡張機能 for SAP に関するその他のトラブルシューティング情報が記載されています。
- SAP Community WIKI: Linux に必要なすべての SAP Note を参照できます。
- Linux 上の SAP のための Azure Virtual Machines の計画と実装
- Linux 上の SAP のための Azure Virtual Machines のデプロイ (この記事)
- Linux 上の SAP のための Azure Virtual Machines DBMS のデプロイ
- Pacemaker クラスターでの SAP HANA システム レプリケーション
- 一般的な RHEL ドキュメント:
- Azure 固有の RHEL ドキュメント:
概要
HA を実現するために、SAP HANA は 2 台の VM にインストールされます。 データは、HANA システム レプリケーションを使用してレプリケートされます。
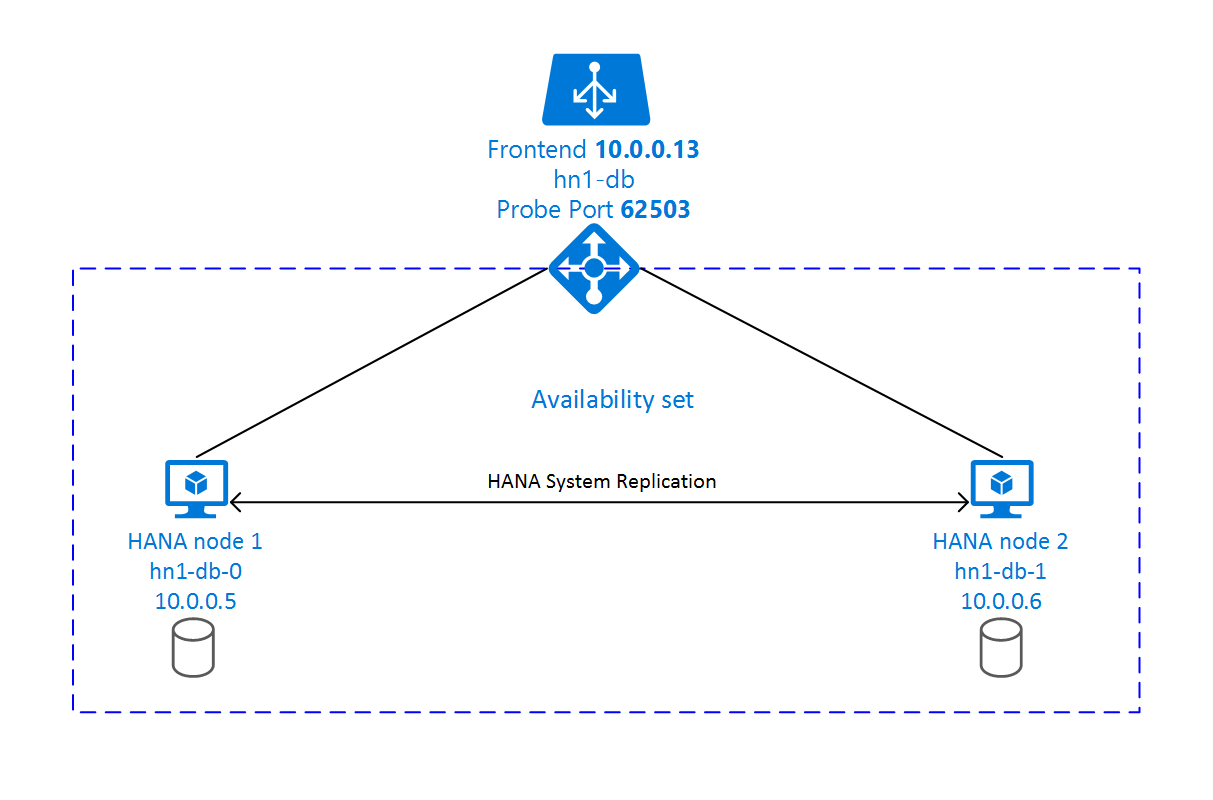
SAP HANA システム レプリケーションの設定では、専用の仮想ホスト名と仮想 IP アドレスが使用されます。 Azure では、仮想 IP アドレスを使用するためにロード バランサーが必要になります。 表示されている構成は、次のものを含むロード バランサーを示しています。
- フロントエンド IP アドレス: 10.0.0.13 (hn1-db)
- プローブ ポート: 62503
インフラストラクチャの準備
Azure Marketplace には、高可用性アドオンを備えた SAP HANA に適したイメージが含まれています。これは、さまざまなバージョンの Red Hat を使用して新しい VM をデプロイするために使用できます。
Azure portal 経由での手動による Linux VM のデプロイ
このドキュメントは、リソース グループ、Azure Virtual Network、サブネットが既にデプロイ済みであることを前提としています。
SAP HANA 用の VM をデプロイします。 HANA システムでサポートされている適切な RHEL イメージを選択します。 VM は、仮想マシン スケール セット、可用性ゾーン、可用性セットのいずれかの可用性オプションでデプロイできます。
重要
選択した OS が、デプロイで使用する予定の特定の種類の VM 上の SAP HANA に対して SAP 認定されていることを確認してください。 SAP HANA 認定されている VM の種類とその OS リリースは、「SAP HANA 認定されている IaaS プラットフォーム」で調べることができます。 特定の VM の種類に対して SAP HANA でサポートされている OS のリリースの完全な一覧を取得するために、VM の種類の詳細を確認するように注意してください。
Azure Load Balancer の構成
VM 構成中に、ネットワーク セクションでロード バランサーを作成するか既存のものを選択する選択肢もあります。 HANA データベースの高可用性セットアップ用に Standard Load Balancer をセットアップするには、次の手順のようにします。
Azure portal を使って高可用性 SAP システム用の標準ロード バランサーを設定するには、「ロード バランサーの作成」の手順に従います。 ロード バランサーのセットアップ時には、以下の点を考慮してください。
- フロントエンド IP 構成: フロントエンド IP を作成します。 お使いのデータベース仮想マシンと同じ仮想ネットワークとサブネットを選択します。
- バックエンド プール: バックエンド プールを作成し、データベース VM を追加します。
- インバウンド規則: 負荷分散規則を作成します。 両方の負荷分散規則で同じ手順に従います。
- フロントエンド IP アドレス: フロントエンド IP を選択します。
- バックエンド プール: バックエンド プールを選択します。
- 高可用性ポート: このオプションを選択します。
- [プロトコル]: [TCP] を選択します。
- 正常性プローブ: 次の詳細を使って正常性プローブを作成します。
- [プロトコル]: [TCP] を選択します。
- ポート: 例: 625<インスタンス番号>。
- サイクル間隔: 「5」と入力します。
- プローブしきい値: 「2」と入力します。
- アイドル タイムアウト (分): 「30」と入力します。
- フローティング IP を有効にする: このオプションを選択します。
Note
正常性プローブ構成プロパティ numberOfProbes (ポータルでは [異常なしきい値] とも呼ばれます) は考慮されません。 成功または失敗した連続プローブの数を制御するには、プロパティ probeThreshold を 2 に設定します。 現在、このプロパティは Azure portal を使用して設定できないため、Azure CLI または PowerShell コマンドを使用してください。
SAP HANA に必要なポートについて詳しくは、SAP HANA テナント データベース ガイドのテナント データベースへの接続に関する章または SAP Note 2388694 を参照してください。
Note
パブリック IP アドレスのない VM が、Standard の Azure Load Balancer の内部 (パブリック IP アドレスのない) インスタンスのバックエンド プール内に配置されている場合、パブリック エンドポイントへのルーティングを許可するように追加の構成が実行されない限り、送信インターネット接続はありません。 送信接続を実現する方法の詳細については、「SAP の高可用性シナリオにおける Azure Standard Load Balancer を使用した VM のパブリック エンドポイント接続」を参照してください。
重要
Azure Load Balancer の背後に配置された Azure VM では TCP タイムスタンプを有効にしないでください。 TCP タイムスタンプを有効にすると正常性プローブが失敗する可能性があります。 パラメーター net.ipv4.tcp_timestamps を 0 に設定します。 詳しくは、「Azure Load Balancer の正常性プローブ」と、SAP Note 2382421 をご覧ください。
SAP HANA のインストール
このセクションの手順では、次のプレフィックスを使用します。
- [A] :この手順はすべてのノードに適用されます。
- [1] :この手順はノード 1 にのみ適用されます。
- [2] :この手順は Pacemaker クラスターのノード 2 にのみ適用されます。
[A] ディスク レイアウトの設定:論理ボリューム マネージャー (LVM) 。
データおよびログ ファイルを格納するボリュームには、LVM を使用することをお勧めします。 次の例は、VM に 4 つのデータ ディスクがアタッチされていて、これを使用して 2 つのボリュームを作成することを前提としています。
すべての使用できるディスクの一覧を出力します。
ls /dev/disk/azure/scsi1/lun*出力例:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3使用するすべてのディスクの物理ボリュームを作成します。
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3データ ファイル用のボリューム グループを作成します。 ログ ファイル用に 1 つ、SAP HANA の共有ディレクトリ用に 1 つのボリューム グループを作成します。
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_HN1 /dev/disk/azure/scsi1/lun3論理ボリュームを作成します。
-iスイッチを指定せずにlvcreateを使用すると、線形のボリュームが作成されます。 I/O パフォーマンスが向上するように、"ストライプ" ボリュームを作成することお勧めします。 ストライプ サイズは、SAP HANA VM のストレージ構成に関するページに記載されている値に合わせます。-i引数は、基になる物理ボリュームの数、-I引数はストライプ サイズにする必要があります。このドキュメントでは、2 つの物理ボリュームが使用されるため、
-iスイッチ引数は 2 に設定されます。 データ ボリュームのストライプ サイズは 256KiB です。 ログ ボリューム用に物理ボリュームが 1 つ使用されるため、ログ ボリューム コマンドに対して-iおよび-Iスイッチは明示的には使用されません。重要
データ、ログ、または共有ボリュームごとに複数の物理ボリュームを使用する場合は、
-iスイッチを使用して基になる物理ボリュームの番号に設定します。 ストライプ ボリュームを作成するときにストライプ サイズを指定するには、-Iスイッチを使用します。 ストライプ サイズやディスク数など、推奨されるストレージ構成については、SAP HANA VM ストレージ構成に関する記事を参照してください。 次のレイアウト例は、特定のシステム サイズのパフォーマンス ガイドラインを必ずしも満たしているとは限りません。 これらは説明のみを目的としています。sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log sudo mkfs.xfs /dev/vg_hana_shared_HN1/hana_sharedマウント コマンドを発行してディレクトリをマウントしないでください。 代わりに、
fstabに構成を入力し、構文を検証する最後のmount -aを発行します。 まず、各ボリュームのマウント ディレクトリを作成します。sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared次に、
/etc/fstabファイルに次の行を挿入して、3 つの論理ボリュームのfstabエントリを作成します。/dev/mapper/vg_hana_data_HN1-hana_data /hana/data xfs defaults,nofail 0 2 /dev/mapper/vg_hana_log_HN1-hana_log /hana/log xfs defaults,nofail 0 2 /dev/mapper/vg_hana_shared_HN1-hana_shared /hana/shared xfs defaults,nofail 0 2
最後に、新しいボリュームをすべて一度にマウントします。
sudo mount -a[A] すべてのホストにホスト名解決を設定します。
/etc/hostsで次のようなすべてのノードのエントリを作成することで、DNS サーバーを使用するか、 すべてのノードで/etc/hostsファイルを変更することができます。10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] HANA 構成のための RHEL を実行します。
次のメモで説明されているように RHEL を構成します。
- 2447641 - RHEL 7.X に SAP HANA SPS 12 をインストールするために必要な追加パッケージ
- 2292690 - SAP HANA DB: Recommended OS settings for RHEL 7 (SAP HANA DB: RHEL 7 に推奨される OS 設定)
- 2777782 - SAP HANA DB:RHEL 8 に推奨される OS 設定
- 2455582 - Linux:GCC 6.x でコンパイルされた SAP アプリケーションの実行
- 2593824 - Linux:GCC 7.x でコンパイルされた SAP アプリケーションの実行
- 2886607 - Linux:GCC 9.x でコンパイルされた SAP アプリケーションの実行
[A] SAP のドキュメントに従って、SAP HANA をインストールします。
[A] ファイアウォールを構成します。
Azure Load Balancer のプローブ ポート用にファイアウォール規則を作成します。
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp --permanent
SAP HANA 2.0 システム レプリケーションの構成
このセクションの手順では、次のプレフィックスを使用します。
- [A] :この手順はすべてのノードに適用されます。
- [1] :この手順はノード 1 にのみ適用されます。
- [2] :この手順は Pacemaker クラスターのノード 2 にのみ適用されます。
[A] ファイアウォールを構成します。
HANA システム レプリケーションおよびクライアント トラフィックを許可するファイアウォール規則を作成します。 必要なポートは、すべての SAP 製品の TCP/IP ポートのページにあります。 次のコマンドは、HANA 2.0 システム レプリケーションと、データベース SYSTEMDB、HN1 および NW1 へのクライアント トラフィックを許可する 1 つの例です。
sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp --permanent sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp[1] テナント データベースを作成します。
<hanasid>adm として次のコマンドを実行します。
hdbsql -u SYSTEM -p "[passwd]" -i 03 -d SYSTEMDB 'CREATE DATABASE NW1 SYSTEM USER PASSWORD "<passwd>"'[1] 最初のノードでシステム レプリケーションを構成します。
<hanasid>adm としてデータベースをバックアップします。
hdbsql -d SYSTEMDB -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')" hdbsql -d NW1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupNW1')"システム PKI ファイルをセカンダリ サイトにコピーします。
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/プライマリ サイトを作成します。
hdbnsutil -sr_enable --name=SITE1[2] 2 番目のノードでシステム レプリケーションを構成します。
2 番目のノードを登録して、システム レプリケーションを開始します。 <hanasid>adm として次のコマンドを実行します。
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2[2] HANA を開始します。
<hanasid>adm として次のコマンドを実行して、HANA を開始します。
sapcontrol -nr 03 -function StartSystem[1] レプリケーションの状態をチェックします。
レプリケーションの状態をチェックし、すべてのデータベースが同期されるまで待機します。状態が不明な場合、ファイアウォール設定を確認します。
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | -------- | ----- | ------------ | --------- | ------- | --------- | --------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | SYSTEMDB | hn1-db-0 | 30301 | nameserver | 1 | 1 | SITE1 | hn1-db-1 | 30301 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30307 | xsengine | 2 | 1 | SITE1 | hn1-db-1 | 30307 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | NW1 | hn1-db-0 | 30340 | indexserver | 2 | 1 | SITE1 | hn1-db-1 | 30340 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30303 | indexserver | 3 | 1 | SITE1 | hn1-db-1 | 30303 | 2 | SITE2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # # mode: PRIMARY # site id: 1 # site name: SITE1
Pacemaker クラスターの作成
「Setting up Pacemaker on Red Hat Enterprise Linux in Azure」 (Azure で Red Hat Enterprise Linux に Pacemaker を設定する) の手順に従って、この HANA サーバーに対して基本的な Pacemaker クラスターを作成します。
重要
systemd ベースの SAP スタートアップ フレームワークにより、SAP HANA インスタンスを systemd で管理できるようになりました。 必要な Red Hat Enterprise Linux (RHEL) の最小バージョンは RHEL 8 for SAP です。 SAP Note 3189534 で説明されているように、SAP HANA SPS07 リビジョン 70 以降の新規インストール、または HANA 2.0 SPS07 リビジョン 70 以降への HANA システムの更新では、SAP スタートアップ フレームワークが systemd に自動的に登録されます。
HA ソリューションを使い、systemd 対応 SAP HANA インスタンスと組み合わせて SAP HANA システムのレプリケーションを管理する場合は (SAP Note 3189534 を参照)、HA クラスターが systemd の干渉なしに SAP インスタンスを管理できるようにするための追加手順が必要です。 そのため、systemd と統合された SAP HANA システムの場合は、すべてのクラスター ノードで Red Hat KBA 7029705 で説明されている追加手順のようにする必要があります。
SAP HANA システム レプリケーション フックを実装する
これは、クラスターとの統合を最適化し、クラスターのフェールオーバーが必要になった場合の検出を改善するための重要なステップです。 SAPHanaSR フックを有効にするには、正しいクラスター操作が必須です。 SAPHanaSR フックと ChkSrv Python フックの両方を構成することを強くお勧めします。
[A]すべてのノードに、SAP HANA リソース エージェントをインストールします。 このパッケージを含むリポジトリを必ず有効にします。 RHEL 8.x HA 以降が有効なイメージを使用している場合、追加のリポジトリを有効にする必要はありません。
# Enable repository that contains SAP HANA resource agents sudo subscription-manager repos --enable="rhel-sap-hana-for-rhel-7-server-rpms" sudo dnf install -y resource-agents-sap-hanaNote
RHEL 8.x と RHEL 9.x の場合は、インストールされている resource-agents-sap-hana パッケージがバージョン 0.162.3-5 以降であることを確認します。
[A] HANA
system replication hooksをインストールします。 レプリケーション フックの構成は、両方の HANA DB ノードにインストールする必要があります。両方のノードで HANA を停止します。 <sid>adm として実行します。
sapcontrol -nr 03 -function StopSystem各クラスター ノードで
global.iniを調整します。[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/srHook execution_order = 1 [ha_dr_provider_chksrv] provider = ChkSrv path = /usr/share/SAPHanaSR/srHook execution_order = 2 action_on_lost = kill [trace] ha_dr_saphanasr = info ha_dr_chksrv = info
パラメーター
pathを既定の/usr/share/SAPHanaSR/srHookの場所にポイントすると、OS の更新プログラムまたはパッケージの更新によって Python フック コードの更新が自動的に行われます。 HANA は、次回再起動するときにフック コードの更新を使用します。/hana/shared/myHooksなどの省略可能な独自のパスを使用すると、HANA が使用するフック バージョンから OS 更新プログラムを切り離すことができます。action_on_lostパラメータを使用して、ChkSrvフックの動作を調整できます。 有効な値は [ignore|stop|kill] です。[A] クラスターでは、<sid> adm の各クラスター ノードで
sudoersを構成する必要があります。 この例では、新しいファイルを作成することでそれを実現します。visudoコマンドを使用して、20-saphanaドロップイン ファイルをrootとして編集します。sudo visudo -f /etc/sudoers.d/20-saphana次の行を挿入して保存します。
Cmnd_Alias SITE1_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE1_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL Defaults!SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL !requiretty[A] 両方のノードで SAP HANA を開始します。 <sid>adm として実行します。
sapcontrol -nr 03 -function StartSystem[1] SRHanaSR フックのインストールを確認します。 アクティブな HANA システム レプリケーション サイトで、<sid>adm として実行します。
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_*# 2021-04-12 21:36:16.911343 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:36:29.147808 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:37:04.898680 ha_dr_SAPHanaSR SOK[1] ChkSrv フックのインストールを確認します。 アクティブな HANA システム レプリケーション サイトで、<sid>adm として実行します。
cdtrace tail -20 nameserver_chksrv.trc
SAP HANA フックの実装の詳細については、「SAP HANA srConnectionChanged() フックの有効化」および「hdbindexserver プロセス障害アクションの SAP HANA srServiceStateChanged() フックの有効化 (省略可能)」を参照してください。
SAP HANA クラスター リソースの作成
HANA トポロジを作成します。 Pacemaker クラスター ノードのいずれかで、次のコマンドを実行します。 これらの手順全体を通して、インスタンス番号、HANA システム ID、IP アドレス、およびシステム名を必要に応じて置き換えてください。
sudo pcs property set maintenance-mode=true
sudo pcs resource create SAPHanaTopology_HN1_03 SAPHanaTopology SID=HN1 InstanceNumber=03 \
op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 \
clone clone-max=2 clone-node-max=1 interleave=true
次に、HANA リソースを作成します。
Note
この記事には、Microsoft が使用しなくなった用語への言及が含まれています。 ソフトウェアからこの用語が削除された時点で、この記事から削除します。
RHEL 7.x でクラスターを構築する場合は、次のコマンドを使用します。
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
master notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-master symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-master 4000
sudo pcs resource defaults resource-stickiness=1000
sudo pcs resource defaults migration-threshold=5000
sudo pcs property set maintenance-mode=false
RHEL 8.x/9.x でクラスターを構築する場合は、次のコマンドを使用します。
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
promotable notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-clone symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-clone 4000
sudo pcs resource defaults update resource-stickiness=1000
sudo pcs resource defaults update migration-threshold=5000
sudo pcs property set maintenance-mode=false
SAP HANA の priority-fencing-delay (pacemaker-2.0.4-6.el8 以降でのみ適用可能) を構成するには、次のコマンドを実行する必要があります。
Note
2 ノード クラスターがある場合は、priority-fencing-delay クラスター プロパティを構成できます。 このプロパティを使用すると、スプリット ブレイン シナリオが発生したときに、リソースの優先度の合計が高いノードをフェンスする際に遅延が発生します。 詳細については、実行中のリソースが最も少ないクラスター ノードの Pacemaker によるフェンスに関するページを参照してください。
priority-fencing-delay プロパティは pacemaker-2.0.4-6.el8 バージョン以降に適用されます。 既存のクラスターで priority-fencing-delay を設定する場合は、フェンス デバイスで pcmk_delay_max オプションの設定を解除してください。
sudo pcs property set maintenance-mode=true
sudo pcs resource defaults update priority=1
sudo pcs resource update SAPHana_HN1_03-clone meta priority=10
sudo pcs property set priority-fencing-delay=15s
sudo pcs property set maintenance-mode=false
重要
フェールオーバー テストの実行中に AUTOMATED_REGISTER を false に設定して、失敗したプライマリ インスタンスが自動的にセカンダリとして登録されないようにすることをお勧めします。 ベスト プラクティスとして、テストが終わったら AUTOMATED_REGISTER を true に設定し、引き継ぎ後にシステム レプリケーションが自動的に再開できるようにします。
クラスターの状態が正常であることと、すべてのリソースが起動されていることを確認します。 リソースがどのノードで実行されているかは重要ではありません。
Note
上記の構成のタイムアウトはほんの一例であり、特定の HANA のセットアップに適合させる必要がある場合があります。 たとえば、SAP HANA データベースの起動に時間がかかる場合は、開始タイムアウトを長くする必要がある可能性があります。
sudo pcs status コマンドを使用して、作成されたクラスター リソースの状態をチェックします。
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# azure_fence (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Pacemaker クラスターで HANA アクティブ/読み取り可能のシステム レプリケーションを構成する
SAP HANA 2.0 SPS 01 以降では、SAP HANA システム レプリケーションでアクティブ/読み取り可能のセットアップを使用できます。この場合、読み取り処理の多いワークロードに対して SAP HANA システム レプリケーションのセカンダリ システムを積極的に活用できます。
クラスターでこのような設定をサポートするには、2 番目の仮想 IP アドレスが必要です。これにより、セカンダリ読み取りが有効な SAP HANA データベースにクライアントからアクセスできます。 引き継ぎの実行後もセカンダリ レプリケーション サイトにアクセスできるようにするために、クラスターが仮想 IP アドレスをセカンダリ SAPHana リソースに移行する必要があります。
このセクションでは、2 番目の仮想 IP を使用して Red Hat HA クラスターで HANA のアクティブ/読み取り可能のシステム レプリケーションを管理するために必要な追加の手順について説明します。
先に進む前に、上に記載したドキュメントのセグメントを参照して、SAP HANA データベースを管理する Red Hat HA クラスターの構成が完了していることを確認してください。
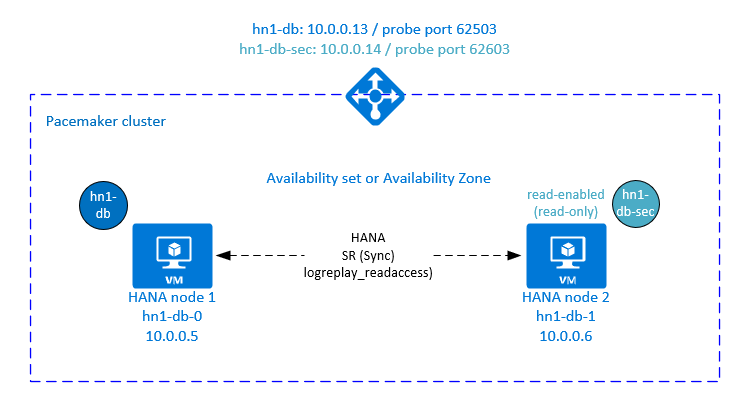
アクティブかつ読み取り可能なセットアップ用の Azure Load Balancer の追加設定
2 番目の仮想 IP をプロビジョニングする追加の手順を続行するには、「Azure portal を使用して Linux VM を手動でデプロイする」セクションの説明に従って Azure Load Balancer を構成していることを確認してください。
標準ロード バランサーの場合は、前のセクションで作成したのと同じロード バランサーで、次の手順に従います。
a. 2 番目のフロントエンド IP プールを作成する:
- ロード バランサーを開き、 [frontend IP pool](フロントエンド IP プール) を選択して [Add](追加) を選択します
- この 2 番目のフロントエンド IP プールの名前を入力します (例: hana-secondaryIP)。
- [割り当て] を [静的] に設定し、IP アドレスを入力します (例: 10.0.0.14)。
- [OK] を選択します。
- 新しいフロントエンド IP プールが作成されたら、プールの IP アドレスを書き留めます。
b. 正常性プローブを作成する:
- ロード バランサーを開き、 [health probes](正常性プローブ) を選択して [Add](追加) を選択します。
- 新しい正常性プローブの名前を入力します (例: hana-secondaryhp)。
- プロトコルとして [TCP] を、ポートは 62603 を選択します。 [Interval] (間隔) の値を 5 に設定し、[Unhealthy threshold] (異常しきい値) の値を 2 に設定します。
- [OK] を選択します。
c. 負荷分散規則を作成します。
- ロード バランサーを開き、 [load balancing rules](負荷分散規則) を選択して [Add](追加) を選択します。
- 新しいロード バランサー規則の名前を入力します (例: hana-secondarylb)。
- 前の手順で作成したフロントエンド IP アドレス、バックエンド プール、正常性プローブを選択します (例: hana-secondaryIP、hana-backend、hana-secondaryhp)。
- [HA ポート] を選択します。
- Floating IP を有効にします。
- [OK] を選択します。
HANA のアクティブかつ読み取り可能のシステム レプリケーションの構成
HANA システム レプリケーションを構成する手順については、「SAP HANA 2.0 システム レプリケーションの構成」セクションを参照してください。 読み取り対応のセカンダリ シナリオをデプロイする場合は、2 番目のノードでシステム レプリケーションを構成するときに、hanasidadm として次のコマンドを実行します。
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2 --operationMode=logreplay_readaccess
アクティブかつ読み取り可能のセットアップ用のセカンダリ仮想 IP アドレス リソースを追加する
2 番目の仮想 IP と適切なコロケーション制約は、次のコマンドを使用して構成できます。
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.40.0.16"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
pcs constraint location g_secip_HN1_03 rule score=INFINITY hana_hn1_sync_state eq SOK and hana_hn1_roles eq 4:S:master1:master:worker:master
pcs constraint location g_secip_HN1_03 rule score=4000 hana_hn1_sync_state eq PRIM and hana_hn1_roles eq 4:P:master1:master:worker:master
# Set the priority to primary IPaddr2 and azure-lb resource if priority-fencing-delay is configured
sudo pcs resource update vip_HN1_03 meta priority=5
sudo pcs resource update nc_HN1_03 meta priority=5
pcs property set maintenance-mode=false
クラスターの状態が正常であることと、すべてのリソースが起動されていることを確認します。 2 番目の仮想 IP は、SAPHana セカンダリ リソースと共にセカンダリ サイトで実行されます。
sudo pcs status
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full List of Resources:
# rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]:
# Started: [ hn1-db-0 hn1-db-1 ]
# Clone Set: SAPHana_HN1_03-clone [SAPHana_HN1_03] (promotable):
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03:
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# Resource Group: g_secip_HN1_03:
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
次のセクションでは、実行する典型的なフェールオーバー テストのセットを示します。
読み取り可能なセカンダリが構成されている HANA クラスターをテストするときに、2 番目の仮想 IP の動作に注意してください。
SAPHana_HN1_03 クラスター リソースをセカンダリ サイト hn1-db-1 に移行すると、2 番目の仮想 IP は引き続き同じサイト hn1-db-1 で実行されます。 リソースに
AUTOMATED_REGISTER="true"を設定していて、HANA システム レプリケーションが hn1-db-0 に自動的に登録されている場合は、2 番目の仮想 IP も hn1-db-0 に移動します。サーバーのクラッシュをテストする場合、2 番目の仮想 IP リソース (secvip_HN1_03) と Azure Load Balancer のポート リソース (secnc_HN1_03) は、プライマリ仮想 IP リソースと共にプライマリ サーバー上で実行されます。 そのため、セカンダリ サーバーがダウンするまで、読み取り可能な HANA データベースに接続されているアプリケーションはプライマリ HANA データベースに接続します。 セカンダリ サーバーが使用できなくなるまで、読み取り可能な HANA データベースに接続されているアプリケーションにアクセスできないようにするため、この動作が想定されます。
2番目の仮想 IP アドレスのフェールオーバーとフォールバック中に、HANA データベースへの接続に 2 番目の仮想 IP を使用するアプリケーション上の既存の接続が中断される可能性があります。
この設定により、正常な SAP HANA インスタンスが実行されているノードに 2 番目の仮想 IP リソースが割り当てられる時間が最大になります。
クラスターの設定をテストする
ここでは、設定をテストする方法について説明します。 テストを開始する前に、Pacemaker に失敗したアクション (pcs 状態を使用) がなく、予期しない場所の制約 (移行テストの残りなど) がなく、HANA が systemReplicationStatus などと同期状態であることを確認します。
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"
移行をテストする
テスト開始前のリソースの状態:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
次のコマンドを root として実行することで、SAP HANA マスター ノードを移行できます。
# On RHEL 7.x
pcs resource move SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource move SAPHana_HN1_03-clone --master
クラスターは、SAP HANA マスター ノードと仮想 IP アドレスを含むグループを hn1-db-1 に移行します。
移行が完了すると、sudo pcs status の出力は次のようになります。
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
AUTOMATED_REGISTER="false" では、クラスターは障害が発生した HANA データベースを再起動したり、hn1-db-0 の新しいプライマリに対して登録したりしません。 この場合は、次のコマンドを hn1adm として実行して、HANA インスタンスをセカンダリとして構成します。
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
移行では場所の制約が作成されますが、これは再度削除する必要があります。 root として、または sudo を使用して、次の操作を行います。
pcs resource clear SAPHana_HN1_03-master
pcs status を使用して HANA リソースの状態を監視します。 hn1-db-0 上で HANA が起動されている場合、出力は次のようになります。
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
ネットワーク通信のブロック
テスト開始前のリソースの状態:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
ファイアウォール規則を実行して、いずれかのノードでの通信をブロックします。
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
クラスター ノードが相互に通信できない場合は、スプリット ブレイン シナリオのリスクがあります。 このような状況では、クラスター ノードは互いに同時にフェンスを試行し、フェンス レースを引き起こします。 このような状況を回避するには、クラスター構成で priority-fencing-delay プロパティを設定することをお勧めします (pacemaker-2.0.4-6.el8 以降にのみ適用されます)。
priority-fencing-delay プロパティを有効にすると、クラスターでは、特に HANA マスター リソースをホストしているノードに対してフェンス アクションに遅延が発生し、ノードがフェンス レースに勝つことができます。
次のコマンドを実行して、ファイアウォール規則を削除します。
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Azure フェンス エージェントをテストする
Note
この記事には、Microsoft が使用しなくなった用語への言及が含まれています。 ソフトウェアからこの用語が削除された時点で、この記事から削除します。
テスト開始前のリソースの状態:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
SAP HANA がマスターとして実行されているノードで、ネットワーク インターフェイスを無効にして Azure フェンス エージェントのセットアップをテストできます。 ネットワーク エラーをシミュレートする方法の説明については、Red Hat のサポート情報記事 79523 を参照してください。
この例では net_breaker スクリプトを root として使用して、ネットワークへのすべてのアクセスをブロックします。
sh ./net_breaker.sh BreakCommCmd 10.0.0.6
クラスターの構成によっては、VM が再起動するか停止します。
stonith-action 設定を off に設定すると、VM が停止し、実行中の VM にリソースが移行されます。
AUTOMATED_REGISTER="false" を設定した場合、VM を再起動すると、SAP HANA リソースがセカンダリとしての起動に失敗します。 この場合は、次のコマンドを hn1adm ユーザーとして実行して、 HANA インスタンスをセカンダリとして構成します。
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
root に戻り、失敗した状態をクリーンします。
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
テスト後のリソースの状態:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
手動フェールオーバーをテストする
テスト開始前のリソースの状態:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
手動フェールオーバーをテストするには、hn1-db-0 ノードでクラスターを root として停止します。
pcs cluster stop
フェールオーバー後、クラスターを再度開始できます。 AUTOMATED_REGISTER="false" を設定した場合、hn1-db-0 ノードの SAP HANA リソースはセカンダリとして起動できません。 この場合は、root として次のコマンドを実行して、HANA インスタンスをセカンダリとして構成します。
pcs cluster start
hn1adm として次を実行します。
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
次に root として
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
テスト後のリソースの状態:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1