C++ では、同じスコープ内で同じ名前の複数の関数を指定できます。 これらの関数は、 overloaded 関数、または overloads と呼ばれます。 オーバーロードされた関数を使用すると、その引数の型と数に応じて、関数に異なるセマンティクスを指定できます。
たとえば、print引数を受け取るstd::string関数があるとします。 この関数は、 double型の引数を受け取る関数とは非常に異なるタスクを実行する場合があります。 オーバーロードにより、 print_string や print_doubleなどの名前を使用する必要がなくなります。 コンパイル時に、コンパイラは、呼び出し元によって渡される引数の種類と数に基づいて、使用するオーバーロードを選択します。
print(42.0)を呼び出すと、void print(double d)関数が呼び出されます。
print("hello world")を呼び出すと、void print(std::string)オーバーロードが呼び出されます。
メンバー関数とフリー関数の両方をオーバーロードできます。 次の表は、関数宣言 C++ のどの部分を使用して、同じスコープ内の同じ名前の関数のグループを区別するかを示しています。
オーバーロードに関する考慮事項
| 関数宣言要素 | オーバーロードに使用されますか? |
|---|---|
| 関数の戻り値の型 | いいえ |
| 引数の数 | はい |
| 引数の型 | はい |
| 省略記号の有無 | はい |
typedef 名の使用 |
いいえ |
| 未指定の配列の範囲 | いいえ |
const または volatile |
はい (関数全体に適用される場合) |
参照修飾子 (& と &&) |
はい |
例
次の例は、関数オーバーロードを使用する方法を示しています。
// function_overloading.cpp
// compile with: /EHsc
#include <iostream>
#include <math.h>
#include <string>
// Prototype three print functions.
int print(std::string s); // Print a string.
int print(double dvalue); // Print a double.
int print(double dvalue, int prec); // Print a double with a
// given precision.
using namespace std;
int main(int argc, char *argv[])
{
const double d = 893094.2987;
if (argc < 2)
{
// These calls to print invoke print( char *s ).
print("This program requires one argument.");
print("The argument specifies the number of");
print("digits precision for the second number");
print("printed.");
exit(0);
}
// Invoke print( double dvalue ).
print(d);
// Invoke print( double dvalue, int prec ).
print(d, atoi(argv[1]));
}
// Print a string.
int print(string s)
{
cout << s << endl;
return cout.good();
}
// Print a double in default precision.
int print(double dvalue)
{
cout << dvalue << endl;
return cout.good();
}
// Print a double in specified precision.
// Positive numbers for precision indicate how many digits
// precision after the decimal point to show. Negative
// numbers for precision indicate where to round the number
// to the left of the decimal point.
int print(double dvalue, int prec)
{
// Use table-lookup for rounding/truncation.
static const double rgPow10[] = {
10E-7, 10E-6, 10E-5, 10E-4, 10E-3, 10E-2, 10E-1,
10E0, 10E1, 10E2, 10E3, 10E4, 10E5, 10E6 };
const int iPowZero = 6;
// If precision out of range, just print the number.
if (prec < -6 || prec > 7)
{
return print(dvalue);
}
// Scale, truncate, then rescale.
dvalue = floor(dvalue / rgPow10[iPowZero - prec]) *
rgPow10[iPowZero - prec];
cout << dvalue << endl;
return cout.good();
}
上記のコードは、ファイル スコープ内の print 関数のオーバーロードを示しています。
既定の引数は、関数型の一部とは見なされません。 したがって、オーバーロードされた関数の選択では使用されません。 既定の引数のみが異なる 2 つの関数は、オーバーロードされた関数ではなく複数の定義と見なされます。
既定の引数は、オーバーロードされた演算子に指定することはできません。
引数の一致
コンパイラは、現在のスコープ内の関数宣言と関数呼び出しで指定された引数との最適な一致に基づいて、呼び出すオーバーロードされた関数を選択します。 適切な関数がある場合、その関数が呼び出されます。 このコンテキストでの "適切" は、次のいずれかを意味します。
厳密な一致が見つかりませんでした。
単純変換が実行されました。
整数の上位変換が実行されました。
目的の引数の型への標準変換が存在します。
必要な引数型へのユーザー定義変換 (変換演算子またはコンストラクター) が存在します。
省略記号によって表される引数が見つかりませんでした。
コンパイラは、引数ごとに候補関数のセットを作成します。 候補関数は、その位置の実引数を仮引数の型に変換できる関数です。
一連の "最も一致する関数" は各引数にビルドされ、選択した関数はすべての設定の交差部分です。 交差部分に複数の関数が含まれている場合、オーバーロードはあいまいで、エラーが生成されます。 最終的に選択される関数は、少なくとも 1 つの引数について、グループ内の他のすべての関数よりも常に一致します。 明確な勝者がない場合、関数呼び出しによってコンパイラ エラーが生成されます。
次の宣言を考えます (関数には、以下の説明での識別のために Variant 1、Variant 2、および Variant 3 とマーク付けしています)。
Fraction &Add( Fraction &f, long l ); // Variant 1
Fraction &Add( long l, Fraction &f ); // Variant 2
Fraction &Add( Fraction &f, Fraction &f ); // Variant 3
Fraction F1, F2;
次のステートメントを考えます。
F1 = Add( F2, 23 );
前のステートメントは 2 つのセットをビルドします。
セット 1: 型の最初の引数を持つ候補関数 Fraction |
セット 2: 2 番目の引数を型に変換できる候補関数 int |
|---|---|
| バリアント 1 | バリアント 1 (int は、標準変換を使用して long に変換することができます) |
| バリアント 3 |
セット 2 の関数は、実際のパラメーター型から仮パラメーター型への暗黙的な変換を持つ関数です。 これらの関数の 1 つに、実際のパラメーター型を対応する仮パラメーター型に変換するための最小の "コスト" があります。
これら 2 つのセットの積集合は、バリアント 1 です。 あいまいな関数呼び出しの例は次のとおりです。
F1 = Add( 3, 6 );
前の関数呼び出しは次のセットをビルドします。
セット 1: int 型の第 1 引数を持つ候補関数 |
セット 2: int 型の第 2 引数を持つ候補関数 |
|---|---|
バリアント 2 (int は、標準変換を使用して long に変換することができます) |
バリアント 1 (int は、標準変換を使用して long に変換することができます) |
これらの 2 つのセットの積集合が空であるため、コンパイラはエラー メッセージを生成します。
引数の一致においては、n 個の既定の引数を持つ関数は、それぞれ異なる数の引数を持つ n+1 個の個別の関数として扱われます。
省略記号 (...) はワイルドカードとして機能し、実際の引数と一致します。 オーバーロード関数のセットを十分に注意して設計しないと、多くのあいまいさの原因になる可能性があります。
Note
オーバーロードされた関数のあいまいさは、関数呼び出しが出現するまで判断できません。 その時点で、設定は関数呼び出しの引数ごとに構築され、明確なオーバーロードがあるかどうかを確認できます。 つまり、特定の関数呼び出しによって呼び出されるまで、あいまいさがコード内に残る可能性があります。
引数の型の違い
オーバーロード関数では、異なる初期化子を受け取る引数型が区別されます。 したがって、指定された型の引数とその型への参照は、オーバーロードの目的では同一であると見なされます。 これらは同じ初期化子を受け取るため、同じと見なされます。 たとえば、max( double, double ) は max( double &, double & ) と同じであると見なされます。 このような関数を 2 つ宣言すると、エラーが発生します。
同じ理由から、 const または volatile によって変更された型の関数引数は、オーバーロードの目的で基本型と異なる方法で扱われません。
ただし、関数のオーバーロード メカニズムでは、const と volatile で修飾される参照と基本型への参照を区別できます。 そのため、次のようなコードが可能となります。
// argument_type_differences.cpp
// compile with: /EHsc /W3
// C4521 expected
#include <iostream>
using namespace std;
class Over {
public:
Over() { cout << "Over default constructor\n"; }
Over( Over &o ) { cout << "Over&\n"; }
Over( const Over &co ) { cout << "const Over&\n"; }
Over( volatile Over &vo ) { cout << "volatile Over&\n"; }
};
int main() {
Over o1; // Calls default constructor.
Over o2( o1 ); // Calls Over( Over& ).
const Over o3; // Calls default constructor.
Over o4( o3 ); // Calls Over( const Over& ).
volatile Over o5; // Calls default constructor.
Over o6( o5 ); // Calls Over( volatile Over& ).
}
出力
Over default constructor
Over&
Over default constructor
const Over&
Over default constructor
volatile Over&
const オブジェクトおよび volatile オブジェクトへのポインターもまた、オーバーロードの目的では基本型へのポインターとは異なるものと見なされます。
引数の一致と変換
コンパイラは、関数宣言の引数と実際の引数を照合するとき、厳密な一致が見つからない場合は、正しい型を取得するために標準またはユーザー定義の変換を指定できます。 変換は、次の規則に従って行われます。
複数のユーザー定義変換を含む変換のシーケンスは考慮されません。
中間変換を削除することで短縮できる変換のシーケンスは考慮されません。
変換の結果のシーケンス (存在する場合) は、 ベスト マッチング シーケンスと呼ばれます。 標準変換を使用して、 int 型のオブジェクトを型 unsigned long に変換するには、いくつかの方法があります ( Standard 変換で説明)。
intからlongに変換してから、longからunsigned longに変換します。intからunsigned longに変換します。
最初のシーケンスは目的の目標を達成しますが、短いシーケンスが存在するため、最適な一致シーケンスではありません。
次の表は、 trivial 変換と呼ばれる変換のグループを示しています。 自明な変換は、コンパイラが最適な一致として選択するシーケンスに影響が限られます。 単純な変換の効果については、表の後で説明します。
簡単な変換
| 引数の型 | 変換された型 |
|---|---|
type-name |
type-name& |
type-name& |
type-name |
type-name[] |
type-name* |
type-name(argument-list) |
(*type-name)(argument-list) |
type-name |
const type-name |
type-name |
volatile type-name |
type-name* |
const type-name* |
type-name* |
volatile type-name* |
変換が試行されたシーケンスは次のとおりです。
完全一致。 関数の呼び出しに使用された型と関数プロトタイプで宣言された型の完全な一致は、常に最適な一致です。 単純変換のシーケンスは、完全一致として分類されます。 ただし、次の変換を実行しないシーケンスは、実行するシーケンスよりも優先順位が高いと見なされます。
ポインターから、
constへのポインターへ (type-name*からconst type-name*)。ポインターから、
volatileへのポインターへ (type-name*からvolatile type-name*)。参照から、
constへの参照へ (type-name&からconst type-name&)。参照から、
volatileへの参照へ (type-name&からvolatile type&)。
上位変換を使用した一致。 整数の上位変換、
floatからdoubleへの変換、および単純変換だけを含む、完全一致として分類されないシーケンスは、上位変換を使用した一致として分類されます。 完全一致による一致ほどではありませんが、標準変換を使用するより上位変換を使用する方が一致の程度が高くなります。標準変換を使用した一致。 完全一致としても、標準変換および単純変換だけを含む上位変換を使用した一致としても分類されないシーケンスは、標準変換を使用した一致として分類されます。 このカテゴリ内では、次の規則が適用されます。
派生クラスへのポインターから直接または間接基底クラスへのポインターへの変換は、
void *またはconst void *への変換よりも適しています。派生クラスへのポインターから基底クラスへのポインターに変換すると、基底クラスが直接基底クラスに近ければ近いほど、一致の程度が向上します。 次の図に示すように、クラス階層があるとします。

優先される変換を示すグラフ。
D* 型から C* 型への変換は、D* 型から B* 型への変換よりも適しています。 同様に、D* 型から B* 型への変換は、D* 型から A* 型への変換よりも適しています。
この同じ規則が、参照変換に適用されます。
D& 型から C& 型への変換は、D& 型から B& 型への変換などよりも適しています。
この同じ規則は、ポインターからメンバーへの変換にも適用されます。
T D::* 型から T C::* 型への変換は、T D::* 型から T B::* 型への変換などよりも適しています (T はメンバーの型)。
上記の規則は、派生の特定のパスに沿ってのみ適用されます。 次の図に示すグラフについて考えます。
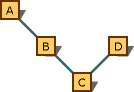
優先される変換を示す多重継承グラフ。
C* 型から B* 型への変換は、C* 型から A* 型への変換よりも適しています。 理由は、これらが同じパスにあり、B* の方が近いからです。 しかし、C* 型から D* 型への変換が、A* 型への変換より適しているというわけではありません。これらの変換は違うパスをたどるので、優先順位が決まらないからです。
ユーザー定義変換を使用した一致。 これは、完全一致、上位変換を使用した一致、または標準変換を使用した一致のどれにも分類できないシーケンスです。 ユーザー定義の変換との一致として分類するには、シーケンスにユーザー定義の変換、標準変換、または単純な変換のみを含める必要があります。 ユーザー定義変換との一致は、省略記号 (
...) との一致よりも一致した方が良いと見なされますが、標準変換との一致ほど適していません。省略記号を使用した一致。 宣言内の省略記号に一致するシーケンスは、すべて省略記号による一致として分類されます。 これは最も弱い一致と見なされます。
組み込みの上位変換または変換が存在しない場合、ユーザー定義の変換が適用されます。 これらの変換は、一致する引数の型に基づいて選択されます。 次のコードがあるとします。
// argument_matching1.cpp
class UDC
{
public:
operator int()
{
return 0;
}
operator long();
};
void Print( int i )
{
}
UDC udc;
int main()
{
Print( udc );
}
UDC クラスに使用できるユーザー定義変換は、int 型および long 型からの変換です。 したがって、コンパイラは照合対象のオブジェクトの型、UDC に応じて変換を検討します。
intへの変換が存在し、選択されています。
引数の照合処理中は、引数とユーザー定義変換の結果の両方に標準変換を適用できます。 したがって、次のコードは機能します。
void LogToFile( long l );
...
UDC udc;
LogToFile( udc );
この例では、コンパイラはユーザー定義の変換 ( operator long) を呼び出して、 udc を long 型に変換します。 ユーザー定義型への変換longが定義されていない場合、コンパイラは最初に、ユーザー定義のUDC変換を使用して型intを型operator intに変換します。 その後、宣言内の引数に一致するように、 int 型から long 型への標準変換が適用されます。
引数の一致にユーザー定義変換が必要な場合、最適な一致を評価するときに標準変換は使用されません。 複数の候補関数がユーザー定義変換を必要としている場合でも、それらの候補関数は等しいと判断されます。 次に例を示します。
// argument_matching2.cpp
// C2668 expected
class UDC1
{
public:
UDC1( int ); // User-defined conversion from int.
};
class UDC2
{
public:
UDC2( long ); // User-defined conversion from long.
};
void Func( UDC1 );
void Func( UDC2 );
int main()
{
Func( 1 );
}
Func のどちらのバージョンにも、int 型をクラス型の引数に変換するユーザー定義変換が必要です。 発生しうる変換は、次のとおりです。
int型からUDC1型への変換 (ユーザー定義変換)。int型からlong型への変換後、UDC2型への変換 (2 段階の変換)。
2 番目の変換には標準変換とユーザー定義変換の両方が必要ですが、これら 2 つの変換は同じと見なされます。
Note
ユーザー定義の変換は、構築または初期化による変換と見なされます。 最適な一致が判断されると、コンパイラは両方のメソッドが等しいと見なします。
引数の一致と this ポインター
クラス メンバー関数は、 staticとして宣言されているかどうかに応じて、異なる方法で処理されます。
static 関数には、 this ポインターを提供する暗黙的な引数がないため、通常のメンバー関数よりも 1 つ少ない引数があると見なされます。 それ以外の場合は、同じように宣言されます。
staticされていないメンバー関数では、暗黙的なthisポインターが、関数の呼び出し先のオブジェクト型と一致する必要があります。 または、オーバーロードされた演算子の場合、演算子が適用されるオブジェクトに一致する最初の引数が必要です。 オーバーロードされた演算子の詳細については、「 オーバーロードされた演算子」を参照してください。
オーバーロードされた関数の他の引数とは異なり、コンパイラは一時オブジェクトを導入せず、 this ポインター引数と一致しようとしたときに変換を試みます。
-> メンバー選択演算子を使用してクラス class_name のメンバー関数にアクセスする場合、this ポインター引数は class_name * const の型を持ちます。 メンバーが const または volatile として宣言されている場合、型はそれぞれ const class_name * const と volatile class_name * const になります。
. メンバー選択演算子は、暗黙の & (アドレス) 演算子がオブジェクト名の前に付けられている場合を除き、まったく同じ方法で動作します 次の例では、このしくみを説明します。
// Expression encountered in code
obj.name
// How the compiler treats it
(&obj)->name
引数マッチングに関して、->* 演算子および .* (メンバーへのポインター) 演算子の左オペランドは . 演算子および -> (メンバー選択) 演算子と同じ方法で処理されます。
メンバー関数の参照修飾子
参照修飾子を使用すると、 this が指すオブジェクトが右辺値か左辺値かに基づいてメンバー関数をオーバーロードできます。 この機能を使用して、データへのポインター アクセスを提供しないことを選択するシナリオで不要なコピー操作を回避します。 たとえば、クラス C でコンストラクターの一部のデータを初期化し、そのデータのコピーをメンバー関数 get_data() で返すとします。
C型のオブジェクトが破棄されようとしている右辺値である場合、コンパイラはget_data() &&オーバーロードを選択し、データをコピーする代わりに移動します。
#include <iostream>
#include <vector>
using namespace std;
class C
{
public:
C() {/*expensive initialization*/}
vector<unsigned> get_data() &
{
cout << "lvalue\n";
return _data;
}
vector<unsigned> get_data() &&
{
cout << "rvalue\n";
return std::move(_data);
}
private:
vector<unsigned> _data;
};
int main()
{
C c;
auto v = c.get_data(); // get a copy. prints "lvalue".
auto v2 = C().get_data(); // get the original. prints "rvalue"
return 0;
}
オーバーロードに関する制限事項
許容可能なオーバーロード関数のセットには複数の制限が適用されます。
一連のオーバーロードされた関数の 2 つの関数には、異なる引数リストが必要です。
戻り値の型だけに基づいて、同じ型の引数リストを持つオーバーロード関数はエラーです。
Microsoft 固有の仕様
operator newは、戻り値の型 (具体的には、指定されたメモリ モデル修飾子に基づいて) に基づいてオーバーロードできます。Microsoft 固有の仕様はここまで
メンバー関数は、一方が
staticであり、もう一方がstaticされていないため、単にオーバーロードすることはできません。typedef宣言では新しい型は定義されません。既存の型のシノニムが導入されています。 オーバーロード メカニズムには影響しません。 次のコードがあるとします。typedef char * PSTR; void Print( char *szToPrint ); void Print( PSTR szToPrint );先行する 2 つの関数の引数リストはまったく同じです。
PSTRは、char *型のシノニムです。 メンバーのスコープでは、このコードによりエラーが発生します。列挙型は別個の型です。また、オーバーロードされた関数を識別するために使用できます。
型 "array of" と "pointer to" は、オーバーロードされた関数を区別する目的で同一と見なされますが、1 次元配列に対してのみ使用されます。 これらのオーバーロードされた関数が競合し、エラー メッセージが生成されます。
void Print( char *szToPrint ); void Print( char szToPrint[] );次元配列が大きい場合、2 番目以降の次元は型の一部と見なされます。 これらは、オーバーロードされた関数を区別するために使用されます。
void Print( char szToPrint[] ); void Print( char szToPrint[][7] ); void Print( char szToPrint[][9][42] );
オーバーロード、オーバーライド、隠ぺい
同じスコープ内の同じ名前の 2 つの関数宣言は、同じ関数または 2 つの個別のオーバーロードされた関数を参照できます。 宣言の引数リストに (前のセクションで説明したように) 型が同じ引数が含まれている場合、関数宣言は同じ関数を参照しています。 それ以外の場合は、オーバーロードを使用して選択された 2 つの異なる関数を参照します。
クラススコープは厳密に観察されます。 基底クラスで宣言された関数は、派生クラスで宣言された関数と同じスコープ内にありません。 派生クラスの関数が基底クラスの virtual 関数と同じ名前で宣言されている場合、派生クラス関数は基底クラス関数 overrides します。 詳細については、「仮想関数」を参照してください。
基底クラス関数が virtualとして宣言されていない場合、派生クラス関数は 表示 と呼びます。 オーバーライドと隠ぺいはどちらもオーバーロードとは異なります。
ブロック スコープは厳密に監視されます。 ファイル スコープで宣言された関数は、ローカルで宣言された関数と同じスコープ内にありません。 ローカルで宣言された関数の名前がファイル スコープで宣言された関数と同じ場合、ローカルで宣言された関数では、オーバーロードが発生する代わりに、ファイル スコープ関数を非表示にします。 次に例を示します。
// declaration_matching1.cpp
// compile with: /EHsc
#include <iostream>
using namespace std;
void func( int i )
{
cout << "Called file-scoped func : " << i << endl;
}
void func( char *sz )
{
cout << "Called locally declared func : " << sz << endl;
}
int main()
{
// Declare func local to main.
extern void func( char *sz );
func( 3 ); // C2664 Error. func( int ) is hidden.
func( "s" );
}
前のコードは、関数 func からの 2 つの定義を示します。
char * 型の引数を受け取る定義は、main ステートメントのため、extern に対してローカルです。 したがって、型 int の引数を受け取る定義は隠ぺいされ、func の最初の呼び出しはエラーになります。
オーバーロードされたメンバー関数の場合は、関数の各バージョンにそれぞれ異なるアクセス権限を与えることができます。 これらは、外側のクラスのスコープ内にあると見なされるため、オーバーロードされた関数です。
Deposit メンバー関数をオーバーロードしている次のコードを考えます。1 つのバージョンはパブリック、もう 1 つのバージョンはプライベートです。
このサンプルの目的は、預金を実行するために正しいパスワードが必要となる Account クラスを提供することです。 これは、オーバーロードを使用して行われます。
Deposit 呼び出し内の Account::Deposit への呼び出しでは、プライベート メンバー関数が呼び出されます。
Account::Deposit はメンバー関数であり、クラスのプライベート メンバーにアクセスできるため、この呼び出しは適切です。
// declaration_matching2.cpp
class Account
{
public:
Account()
{
}
double Deposit( double dAmount, char *szPassword );
private:
double Deposit( double dAmount )
{
return 0.0;
}
int Validate( char *szPassword )
{
return 0;
}
};
int main()
{
// Allocate a new object of type Account.
Account *pAcct = new Account;
// Deposit $57.22. Error: calls a private function.
// pAcct->Deposit( 57.22 );
// Deposit $57.22 and supply a password. OK: calls a
// public function.
pAcct->Deposit( 52.77, "pswd" );
}
double Account::Deposit( double dAmount, char *szPassword )
{
if ( Validate( szPassword ) )
return Deposit( dAmount );
else
return 0.0;
}