タイルの使用
タイルを使用して、アプリのアクセラレーションを最大化することができます。 タイルでは、スレッドを等しい四角形のサブセット、つまり "タイル" に分割します。 適切なタイルのサイズとタイル アルゴリズムを使用している場合、C++ AMP コードによるアクセラレーションがさらに向上します。 タイルの基本コンポーネントは次のとおりです。
tile_static変数。 タイルの主な利点は、tile_staticへのアクセスによるパフォーマンスの向上です。tile_staticメモリのデータへのアクセスは、グローバル空間内のデータ (arrayまたはarray_viewオブジェクト) へのアクセスよりも大幅に高速になる場合があります。 各タイルについてtile_static変数のインスタンスが作成され、タイル内のすべてのスレッドがこの変数にアクセスできます。 一般的なタイル アルゴリズムでは、データをグローバル メモリからtile_staticメモリに 1 回コピーし、tile_staticメモリから何度もアクセスします。tile_barrier::wait メソッド.
tile_barrier::waitの呼び出しは、同じタイル内のすべてのスレッドがtile_barrier::waitの呼び出しに到達するまで、現在のスレッドの実行を中断します。 スレッドが実行される順序を保証することはできません。ただ、すべてのスレッドがtile_barrier::waitの呼び出しに到達するまで、タイル内のどのスレッドもこの呼び出しを越えて実行されないだけです。 これは、tile_barrier::waitメソッドを使用することによって、スレッド単位ではなく、タイル単位でタスクを実行できることを意味します。 一般的なタイル アルゴリズムでは、tile_staticメモリ全体を初期化するコードがあり、その後にtile_barrier::waitの呼び出しが続きます。tile_barrier::waitの後に続くコードには、すべてのtile_static値へのアクセスを必要とする計算が含まれます。ローカルおよびグローバル インデックス作成。
array_viewオブジェクトやarrayオブジェクト全体を基準とするスレッドのインデックス、およびタイルを基準とするインデックスにアクセスできます。 ローカル インデックスを使うと、コードが読みやすくなり、デバッグも容易になります。 通常、tile_static変数にアクセスするにはローカル インデックスを使用し、array変数やarray_view変数にアクセスするにはグローバル インデックスを使用します。tiled_extent クラスと tiled_index クラス。
tiled_extentの呼び出しでextentオブジェクトではなくparallel_for_eachオブジェクトを使用します。tiled_indexの呼び出しでindexオブジェクトではなくparallel_for_eachオブジェクトを使用します。
タイルを活用するには、アルゴリズムによって、計算ドメインをタイルに分割し、すばやくアクセスできるようにタイルのデータを tile_static 変数にコピーする必要があります。
グローバル、タイル、およびローカル インデックスの例
Note
C++ AMP ヘッダーは、Visual Studio 2022 バージョン 17.0 以降では非推奨です。
AMP ヘッダーを含めると、ビルド エラーが発生します。 警告をサイレント状態にするには、AMP ヘッダーを含める前に _SILENCE_AMP_DEPRECATION_WARNINGS を定義します。
次の図は、2 × 3 のタイルに配置された 8 × 9 のデータ行列を示しています。
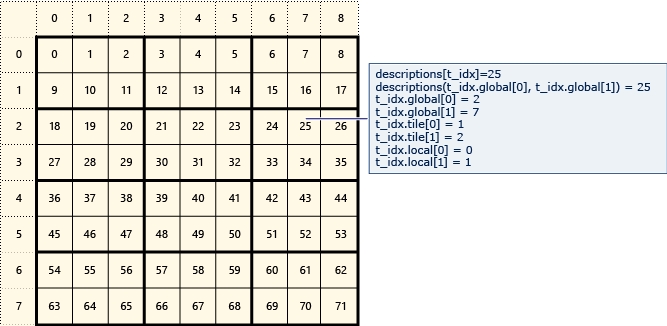
次の例では、このタイル化された行列のグローバル、タイル、およびローカル インデックスを表示します。 array_view オブジェクトは、Description 型の要素を使用して作成されます。 Description は、行列の要素のグローバル、タイル、およびローカル インデックスを保持します。 parallel_for_each の呼び出しのコードは、各要素のグローバル、タイル、およびローカル インデックスの値を設定します。 出力は Description 構造体の値を表示します。
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
この例の主要な処理は、array_view オブジェクトの定義と parallel_for_each の呼び出しにあります。
Description構造体のベクターが 8 × 9 のarray_viewオブジェクトにコピーされます。parallel_for_eachメソッドは、tiled_extentオブジェクトを計算ドメインとして使用して呼び出されます。tiled_extentオブジェクトは、extent::tile()変数のdescriptionsメソッドを呼び出すことによって作成されます。extent::tile()の呼び出しの型パラメーター<2,3>は、2 × 3 のタイルが作成されることを指定します。 したがって、8 × 9 行列が 4 行 3 列の 12 のタイルになります。parallel_for_eachメソッドは、tiled_index<2,3>オブジェクト (t_idx) をインデックスとして使用することによって呼び出されます。 インデックス (t_idx) の型パラメーターは、計算ドメイン (descriptions.extent.tile< 2, 3>()) の型パラメーターと一致している必要があります。各スレッドが実行されるときに、インデックス
t_idxは、スレッドが含まれているタイル (tiled_index::tileプロパティ) およびタイル内のスレッドの位置 (tiled_index::localプロパティ) に関する情報を返します。
タイルの同期: tile_static と tile_barrier::wait
前の例は、タイルのレイアウトとインデックスについて説明していますが、それ自体は有用ではありません。 タイルは、タイルがアルゴリズムに不可欠であり、tile_static 変数を十分に活用する場合に有用になります。 タイル内のすべてのスレッドは tile_static 変数にアクセスできるため、tile_static 変数へのアクセスを同期するために tile_barrier::wait の呼び出しが使用されます。 タイル内のすべてのスレッドが tile_static 変数にアクセスできますが、タイル内のスレッドの実行順序は保証されません。 次の例では、tile_static 変数と、tile_barrier::wait メソッドを使用して、各タイルの平均値を計算する方法を示します。 この例を理解するための鍵を次に示します。
rawData は 8 × 8 の行列に格納されます。
タイルのサイズは 2 × 2 です。 これにより 4 × 4 グリッドのタイルが作成され、
arrayオブジェクトを使用することによって、4 × 4 の行列に平均値を格納できます。 AMP 制限関数では、参照によってキャプチャできる型の数は限られています。arrayクラスはそのうちの 1 つです。行列のサイズとサンプルのサイズは、
#defineステートメントを使用することによって定義されます。これは、array、array_view、extent、およびtiled_indexに対する型パラメーターは定数値である必要があるためです。const int static宣言を使用することもできます。 もう 1 つの利点として、サンプル サイズを変更して、4 × 4 のタイルで平均を計算することは容易であることが挙げられます。浮動小数点値の
tile_staticの 2 × 2 の配列は、各タイルについて宣言されます。 この宣言は各スレッドのコード パスにありますが、行列内の各タイルについて配列は 1 つだけ作成されます。tile_static配列に各タイルの値をコピーするコード行があります。 各スレッドについて、値が配列にコピーされた後、tile_barrier::waitの呼び出しによってスレッドの実行は停止します。タイル内のすべてのスレッドがこのバリアに到達したときに、平均を計算できます。 コードは各スレッドに対して実行されるため、1 つのスレッドでのみ平均を計算するために
ifステートメントがあります。 平均は averages 変数に格納されます。 バリアは基本的にタイルごとの計算を制御するコンストラクトであり、forループと同じように使用します。averages変数内のデータは、arrayオブジェクトであるため、ホストにコピーして戻す必要があります。 この例では、ベクター変換演算子を使用します。完成した例では、SAMPLESIZE を 4 に変更でき、他のコードは変更されずに正しく実行されます。
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
競合状態
次のように、tile_static という名前の total の変数を作成し、スレッドごとにその変数をインクリメントすることは魅力的です。
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
このアプローチの最初の問題は、tile_static 変数で初期化子を含むことができないことです。 2 番目の問題は、タイル内のすべてのスレッドが total 変数にアクセスでき、特定の順序ではないため、この変数への代入で競合状態が発生することです。 次に示すように、各バリアで 1 つのスレッドだけが total にアクセスできるようなアルゴリズムをプログラミングできます。 ただし、このソリューションは拡張可能ではありません。
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
メモリ フェンス
グローバル メモリのアクセスと tile_static メモリのアクセスの 2 種類のメモリ アクセスを同期する必要があります。 concurrency::array のオブジェクトはグローバル メモリのみを割り当てます。 concurrency::array_view は、構築の方法に応じて、グローバル メモリ、tile_static メモリ、またはその両方を参照できます。 2 種類のメモリを同期する必要があります。
グローバル メモリ
tile_static
"メモリ フェンス" により、スレッド タイル内の他のスレッドがメモリ アクセスを使用できること、およびメモリ アクセスがプログラムの順序に従って実行されることが保証されます。 これを実現するために、コンパイラとプロセッサは、フェンスを越えて読み取りと書き込みの順序を変更しません。 C++ AMP では、メモリ フェンスは、次のいずれかのメソッドを呼び出すことによって作成されます。
tile_barrier::wait メソッド: グローバル メモリと
tile_staticメモリの両方の周囲にフェンスを作成します。tile_barrier::wait_with_all_memory_fence メソッド: グローバル メモリと
tile_staticメモリの両方の周囲にフェンスを作成します。tile_barrier::wait_with_global_memory_fence メソッド: グローバル メモリの周囲にのみフェンスを作成します。
tile_barrier::wait_with_tile_static_memory_fence メソッド:
tile_staticメモリの周囲にのみフェンスを作成します。
必要な特定のフェンスを呼び出すことによって、アプリのパフォーマンスが向上する場合があります。 バリアの種類は、コンパイラやハードウェアによるステートメントの並べ替えに影響します。 たとえば、グローバル メモリ フェンスを使用する場合、フェンスはグローバル メモリ アクセスにのみ適用されます。このため、コンパイラやハードウェアは、フェンスの両側で tile_static 変数の読み取りや書き込みを並べ替える可能性があります。
次の例では、バリアは tileValues 変数である tile_static への書き込みを同期します。 この例では、tile_barrier::wait_with_tile_static_memory_fence の代わりに tile_barrier::wait を呼び出しています。
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
関連項目
C++ AMP (C++ Accelerated Massive Parallelism)
tile_static キーワード