Azure Monitor
ヒント
このコンテンツは eBook の「Azure 向けクラウド ネイティブ .NET アプリケーションの設計」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

Azure ほど成熟したクラウド アプリケーション監視ソリューションを提供しているクラウド プロバイダーは他にありません。 Azure Monitor は、システムの状態の可視性を提供するように設計されたツールのコレクションを示す包括的な名称です。 クラウドネイティブ サービスがどのように実行されているかを理解するのに役立ち、それらに影響する問題を事前に特定することができます。 図 7-12 は、Azure Monitor の概要図です。
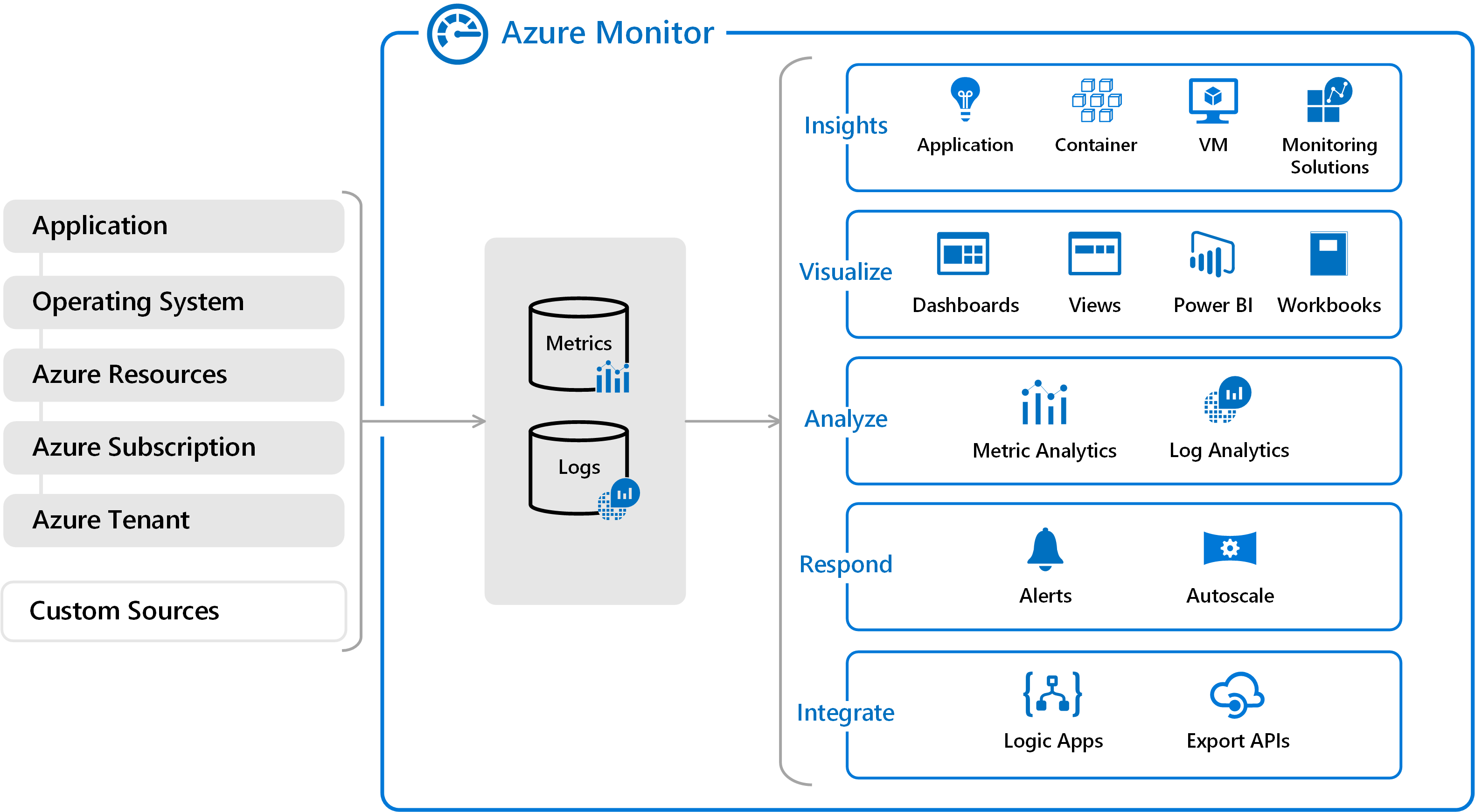 図 7-12。 Azure Monitor の概要。
図 7-12。 Azure Monitor の概要。
ログとメトリックの収集
監視ソリューションの最初の手順は、できるだけ多くのデータを収集することです。 収集されるデータが多いほど、より深い分析情報を得られます。 従来、システムのインストルメント化は困難でした。 簡易ネットワーク管理プロトコル (SNMP) は、マシン レベルの情報を収集するための代表的なプロトコルでしたが、多くの知識と構成が必要でした。 幸い、最も一般的なメトリックは Azure Monitor によって自動的に収集されるため、このような苦労の多くが解消されました。
アプリケーション レベルのメトリックとイベントは、デプロイされるアプリケーションに固有であるため、自動的に計測することはできません。 このようなメトリックを収集するために、お客様がサインアップしたときや注文を完了したときなどに、そのような情報を直接報告するための SDK と API が用意されています。 例外をキャプチャし、Application Insights を介して Azure Monitor に報告することもできます。 SDK は、Go、Python、JavaScript、.NET 言語など、クラウド ネイティブ アプリケーションにあるほとんどすべての言語をサポートしています。
アプリケーションの状態に関する情報を収集する最終的な目標は、エンド ユーザーに優れたエクスペリエンスを提供することです。 ユーザーに問題が発生しているかどうかを判断するには、アウトサイドイン Web テストを実行するのが一番です。 これらのテストは、世界各国の場所から Web サイトに ping を送信するような単純なものから、エージェントがサイトにログインしてユーザーの行動をシミュレートするような複雑なものまであります。
データの報告
データを収集した後は、それを操作し、要約し、グラフにプロットすることができます。これで、ユーザーは問題が発生したときにすぐに確認できるようになります。 このようなグラフは、ダッシュボードまたはブック (システムのある側面についてのストーリーを伝えるように設計された複数ページのレポート) にまとめることができます。
現代のアプリケーションは、人工知能や機械学習を抜きにしては成り立ちません。 そのためにデータを Azure のさまざまな機械学習ツールに渡すことで、他の方法では隠れてしまうような傾向や情報を抽出することができます。
Application Insights には Kusto という強力な (SQL に似た) クエリ言語が用意されており、レコードのクエリを実行し、要約し、グラフをプロットすることができます。 たとえば、次のクエリを実行すると、2007 年 11 月のすべてのレコードが検索され、それらが州ごとにグループ化され、上位 10 件が円グラフとしてプロットされます。
StormEvents
| where StartTime >= datetime(2007-11-01) and StartTime < datetime(2007-12-01)
| summarize count() by State
| top 10 by count_
| render piechart
図 7-13 は、この Application Insights クエリの結果を示しています。
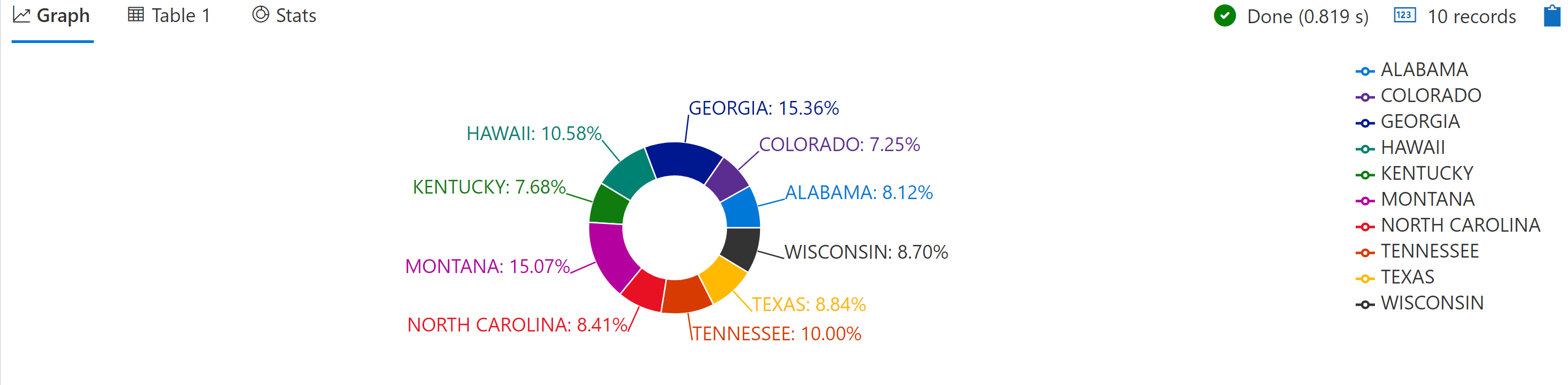 図 7-13。 Application Insights のクエリ結果。
図 7-13。 Application Insights のクエリ結果。
Kusto クエリを試すためのプレイグラウンドがあります。 サンプル クエリを参照することもお勧めします。
ダッシュボード
Azure Monitor からの情報を表示するために使用できるダッシュボード テクノロジがいくつかあります。 おそらく、最も簡単なのは、Application Insights でクエリを実行し、データをグラフにプロットすることです。
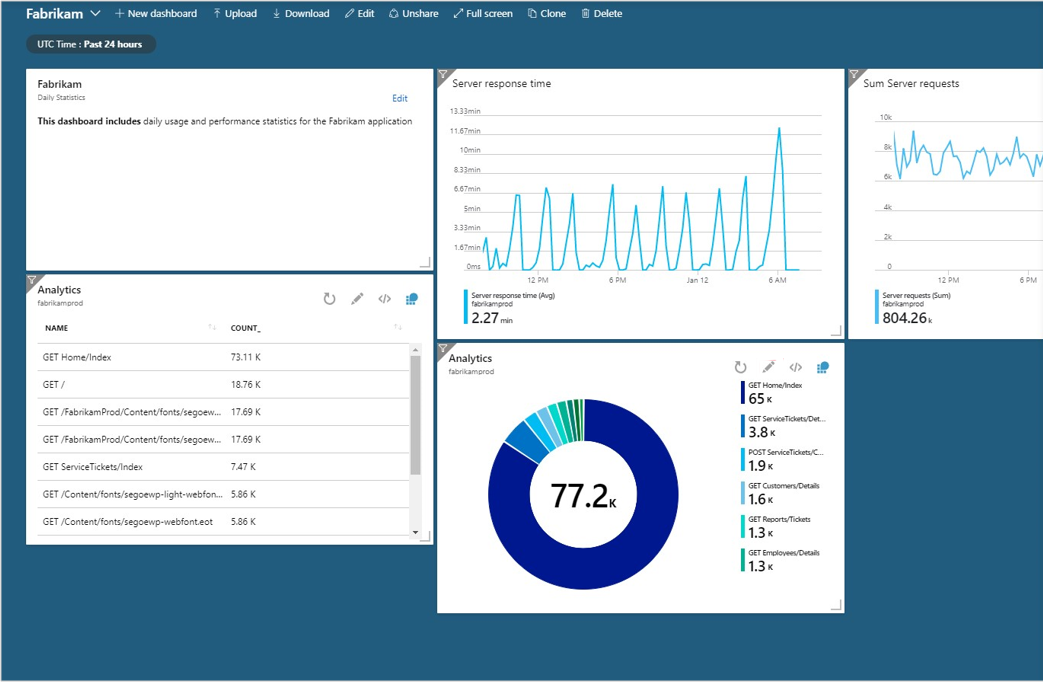 図 7-14。 メインの Azure ダッシュボードに埋め込まれた Application Insights グラフの例。
図 7-14。 メインの Azure ダッシュボードに埋め込まれた Application Insights グラフの例。
このようなグラフは、Azure portal でダッシュボード機能を使用して適切に埋め込むことができます。 複数の層のデータにドリルダウンできることなど、より厳しい要件を持つユーザーの場合は、Azure Monitor データを Power BI から使用できます。 Power BI は、業界をリードするエンタープライズ クラスのビジネス インテリジェンス ツールであり、さまざまなデータソースからデータを集計することができます。
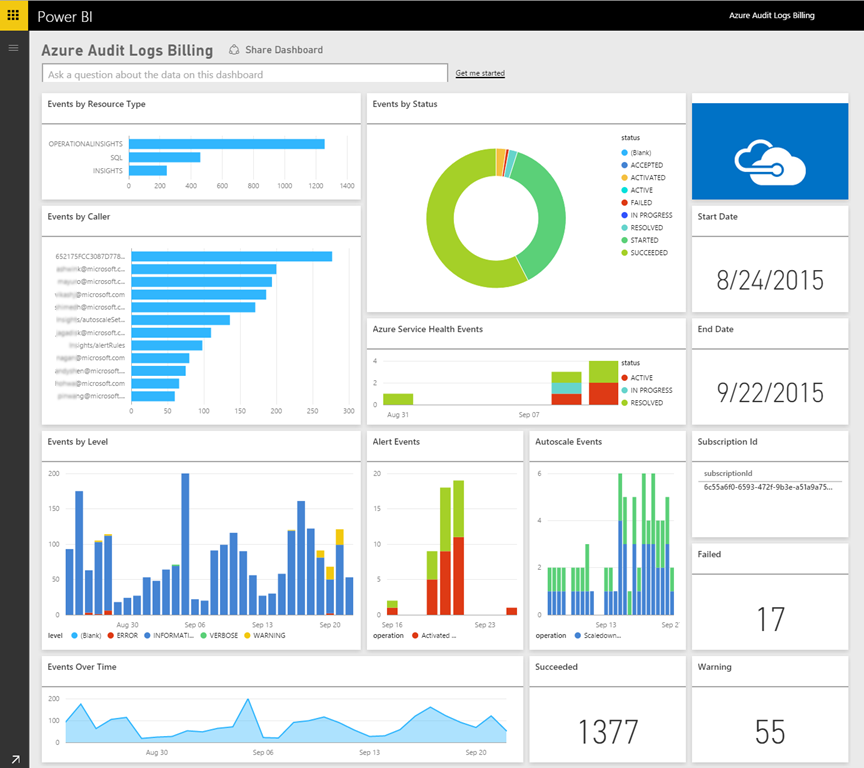
図 7-15。 Power BI ダッシュボードの例
警告
データ ダッシュボードがあるだけでは不十分な場合があります。 ダッシュボードを見るために起きている人がいなければ、問題が解決されるまで、または検出されるまでに何時間もかかる可能性があります。 このため、Azure Monitor には、最上級のアラート ソリューションも用意されています。 アラートは、次のようにさまざまな条件でトリガーされる可能性があります。
- メトリックの値
- ログの検索クエリ
- アクティビティ ログのイベント
- 基になっている Azure プラットフォームの正常性
- Web サイトの可用性のテスト
トリガーされると、アラートによってさまざまなタスクを実行できます。 簡単な例を挙げると、アラートによって、単にメーリング リストにメールの通知を送信したり、個人にテキスト メッセージを送ったりすることができます。 より複雑なアラートの場合は、特定のアプリケーションについて待機者を認識する機能がある PagerDuty のようなツールで、ワークフローをトリガーすることができます。 アラートを使用して Microsoft Flow のアクションをトリガーすると、ワークフローの可能性をほぼ無限に広げることができます。
アラートの一般的な原因が特定されたら、アラートの一般的な原因とそれを解決するための手順に関する詳細情報を使って、アラートを強化することができます。 高度に成熟したクラウドネイティブ アプリケーションのデプロイの場合、自己修復タスクを開始し、スケール セットから障害ノードを削除したり、自動スケーリング アクティビティをトリガーしたりするなどのアクションを実行することができます。 最終的には、ライブ サイトの問題を解決するために午前 2 時に待機担当者を起こす必要はなくなる可能性があります。安定するように自動的に調整されるか、少なくとも翌朝に誰かが出社するまでは持ちこたえることができるようになるからです。
Azure Monitor には、デプロイされたアプリケーションの正常な動作パラメーターを把握するために機械学習が自動的に利用されています。 このアプローチにより、通常のパラメーターから外れて動作しているサービスを検出することができます。 たとえば、平日の一般的なサイトのトラフィックが 1 分あたり 10,000 要求だとします。 そして、ある週に、突然、要求数が 1 分あたり 20,000 要求という通常とはかけ離れた数字になったとします。 スマート検出により、このような標準値からの逸脱が検出され、アラートがトリガーされます。 同時に、高度な傾向分析により、トラフィックの負荷が予想される場合には、誤検知の生成が回避されます。
リファレンス
.NET