ヒント
このコンテンツは、Azure 用のクラウド ネイティブ .NET アプリケーションの設計に関する電子ブックからの抜粋であり、.NET Docs またはオフラインで読み取ることができる無料のダウンロード可能な PDF として入手できます。

この本で説明したように、クラウドネイティブのアプローチによって、アプリケーションの設計、デプロイ、管理の方法が変わります。 また、データの管理と格納方法も変更されます。
図 5-1 では、違いを比較しています。
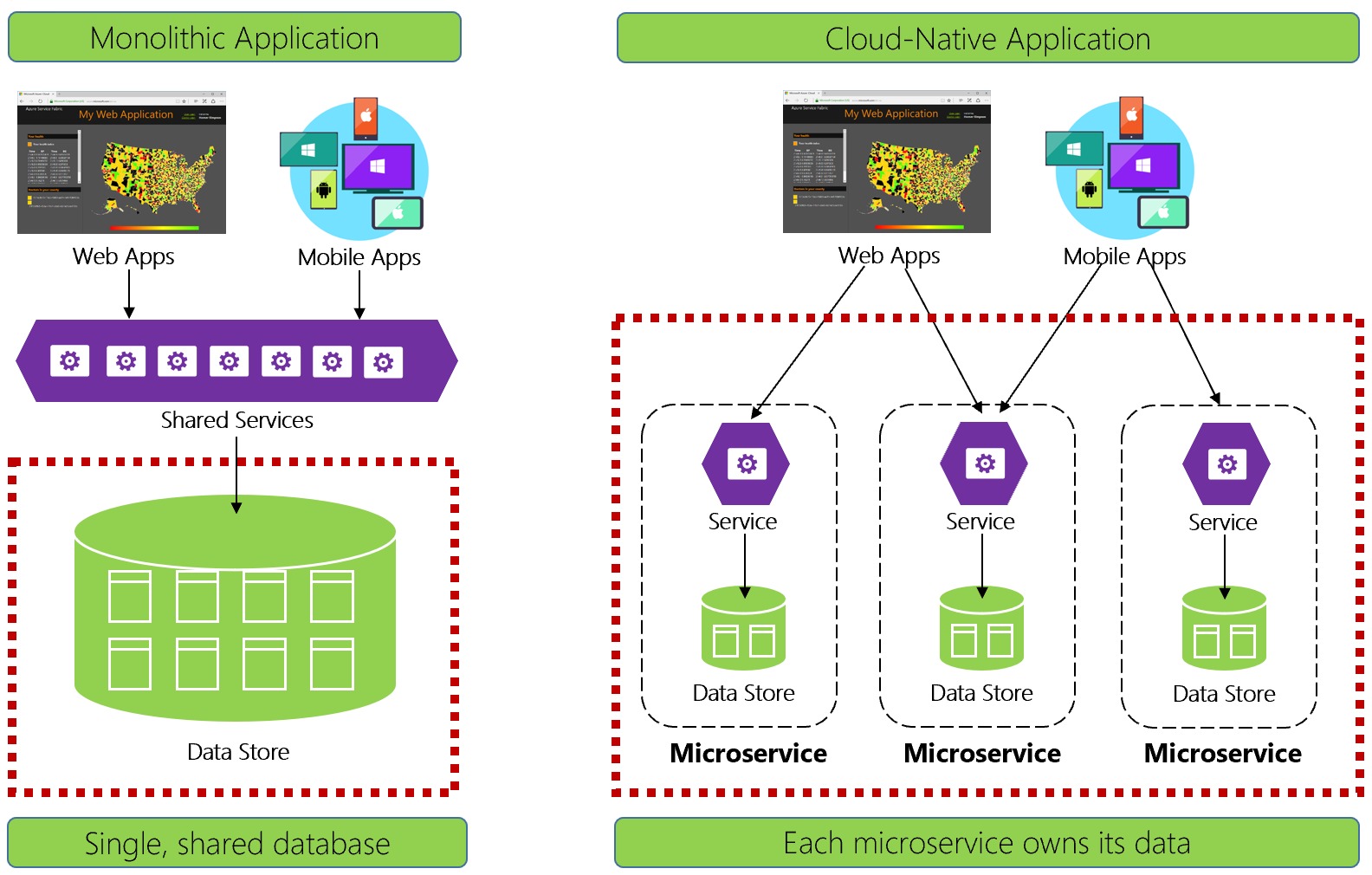
図 5-1 クラウドネイティブ アプリケーションでのデータ管理
経験豊富な開発者は、図 5-1 の左側にあるアーキテクチャを簡単に認識できます。 この モノリシック アプリケーションでは、ビジネス サービス コンポーネントが共有サービス層に併置され、1 つのリレーショナル データベースからデータが共有されます。
多くの点で、1 つのデータベースでデータ管理が簡単になります。 複数のテーブル間でデータのクエリを実行するのは簡単です。 データを変更すると、一緒に更新されるか、すべてがロールバックされます。 ACID トランザクションは、 強力で即時の一貫性を保証します。
クラウドネイティブ向けの設計では、別のアプローチを採用しています。 図 5-1 の右側で、ビジネス機能が小規模で独立した マイクロサービスにどのように分離されるかに注意してください。 各マイクロサービスは、特定のビジネス機能と独自のデータをカプセル化します。 モノリシック データベースは、多数の小規模なデータベースを持つ分散データ モデルに分解され、それぞれがマイクロサービスに合わせて配置されます。 煙が消えると、 マイクロサービスごとにデータベースを公開する設計が現れます。
マイクロサービスごとのデータベース、理由
マイクロサービスごとのこのデータベースは、特に急速に進化し、大規模なスケールをサポートする必要があるシステムに対して、多くの利点を提供します。 このモデルを使用しています...
- ドメイン データはサービス内にカプセル化されます
- データ スキーマは、他のサービスに直接影響を与えることなく進化する可能性があります
- 各データ ストアは、個別にスケーリングできます。
- 1 つのサービスでのデータ ストアの障害が他のサービスに直接影響を与えることはありません
また、データを分離することで、各マイクロサービスは、ワークロード、ストレージのニーズ、読み取り/書き込みパターンに最適なデータ ストアの種類を実装することもできます。 リレーショナル、ドキュメント、キー値、さらにはグラフ ベースのデータ ストアも選択できます。
図 5-2 は、クラウドネイティブ システムでのポリグロット永続化の原則を示しています。
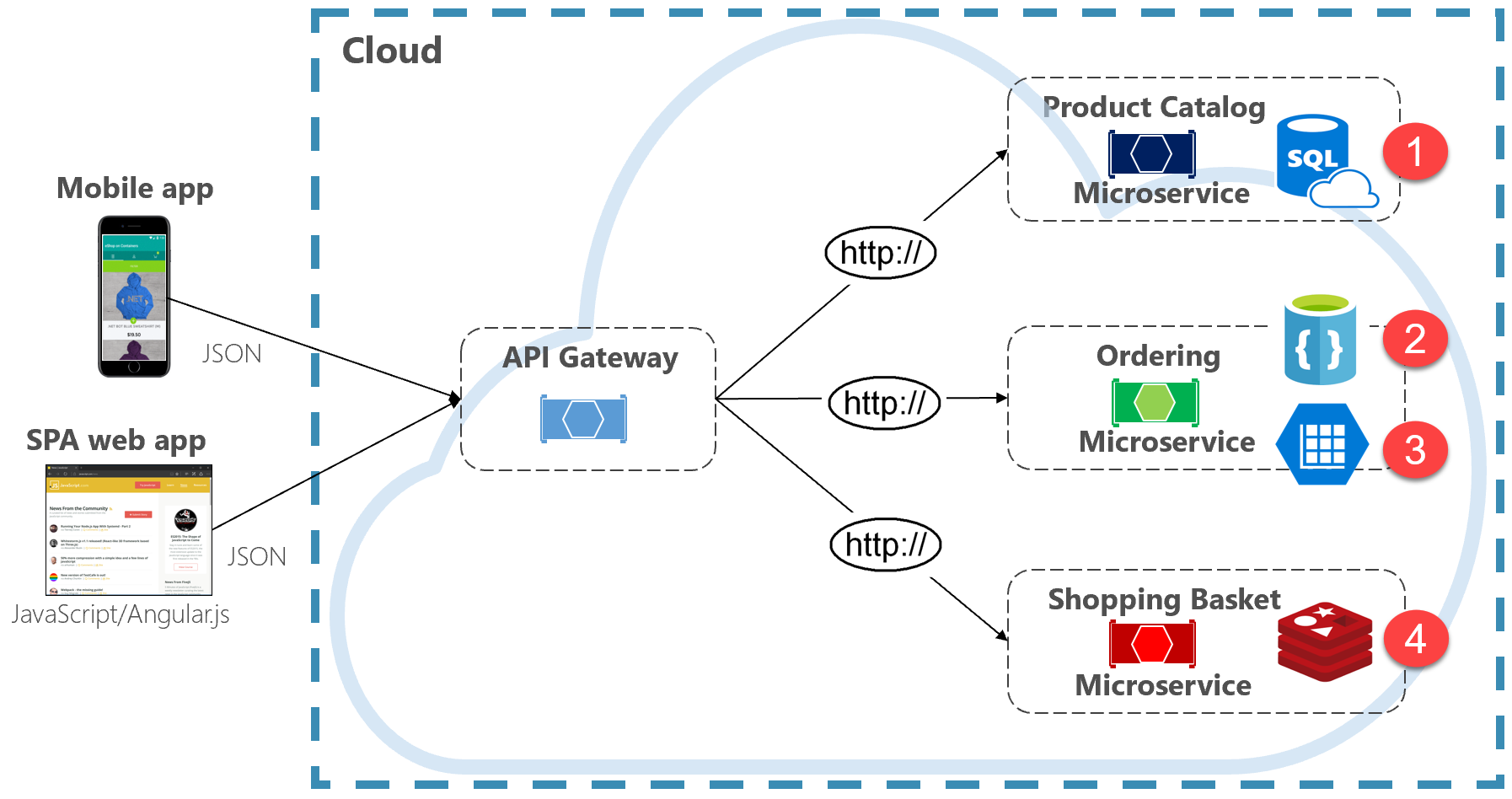
図 5-2 Polyglot データの永続化
前の図では、各マイクロサービスが異なる種類のデータ ストアをサポートする方法に注意してください。
- 製品カタログ マイクロサービスは、リレーショナル データベースを使用して、基になるデータの豊富なリレーショナル構造に対応します。
- ショッピング カート マイクロサービスは、シンプルなキー値データ ストアをサポートする分散キャッシュを使用します。
- 注文マイクロサービスは、大量の読み取り操作に対応するために、書き込み操作用の NoSql ドキュメント データベースと、高度に非正規化されたキー/値ストアの両方を使用します。
リレーショナル データベースは、複雑なデータを含むマイクロサービスに関連し続けますが、NoSQL データベースはかなり人気を集めています。 大規模で高可用性を提供します。 スキーマレスな性質により、開発者は型指定されたデータ クラスと ORM のアーキテクチャから離れ、変更にコストがかかり、時間がかかります。 NoSQL データベースについては、この章の後半で説明します。
データを個別のマイクロサービスにカプセル化すると、機敏性、パフォーマンス、スケーラビリティが向上しますが、多くの課題もあります。 次のセクションでは、これらの課題を克服するためのパターンとプラクティスと共に説明します。
サービス間クエリ
マイクロサービスは独立しており、インベントリ、出荷、順序付けなどの特定の機能に重点を置いているが、他のマイクロサービスとの統合が必要な場合が多い。 多くの場合、統合には、1 つのマイクロサービスが別のマイクロサービス に対してデータのクエリを実行する 必要があります。 図 5-3 にシナリオを示します。
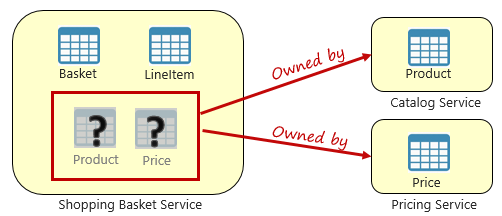
図 5-3 マイクロサービス間でのクエリ
前の図では、ユーザーの買い物かごに項目を追加するショッピング バスケット マイクロサービスが表示されています。 このマイクロサービスのデータ ストアにはバスケットと品目のデータが含まれていますが、製品データや価格データは保持されません。 代わりに、これらのデータ項目はカタログと価格マイクロサービスによって所有されます。 この側面は問題を提示します。 買い物かごマイクロサービスは、データベースに製品や価格データがない場合に、ユーザーの買い物かごに製品を追加するにはどうすればよいですか?
第 4 章で説明するオプションの 1 つは、ショッピング バスケットからカタログおよび価格マイクロサービスへの 直接 HTTP 呼び出 しです。 ただし、第 4 章では、同期 HTTP 呼び出しによってマイクロサービスが 2 つ 結合され、自律性が低下し、アーキテクチャ上の利点が低下するという説明がありました。
また、サービスごとに個別の受信キューと送信キューを含む 要求/応答パターン を実装することもできます。 ただし、このパターンは複雑であり、要求メッセージと応答メッセージを関連付けるために組み込み処理が必要です。 バックエンド マイクロサービス呼び出しは切り離されますが、呼び出し元サービスは呼び出しが完了するまで同期的に待機する必要があります。 ネットワークの輻輳、一時的な障害、または過負荷のマイクロサービスにより、実行時間が長く、操作が失敗する可能性があります。
代わりに、サービス間の依存関係を削除するための広く受け入れられたパターンは、図 5-4 に示す 具体化されたビュー パターンです。
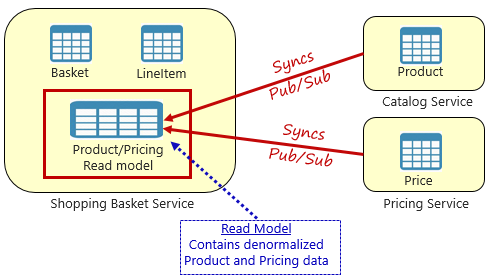
図 5-4. 具体化されたビュー パターン
このパターンでは、買い物かごサービスにローカル データ テーブル ( 読み取りモデルと呼ばれます) を配置します。 この表には、製品マイクロサービスと価格マイクロサービスから必要なデータの非正規化コピーが含まれています。 データをショッピング バスケット マイクロサービスに直接コピーすると、コストのかかるサービス間呼び出しが不要になります。 サービスにローカルなデータを使用すると、サービスの応答時間と信頼性が向上します。 さらに、データの独自のコピーを持つことで、買い物かごサービスの回復性が向上します。 カタログ サービスが使用できなくなった場合、買い物かごサービスに直接影響しません。 買い物かごは、独自のストアからのデータを操作し続けることができます。
この方法には注意が必要で、現在システムにデータの重複が発生しています。 ただし、クラウドネイティブ システムで 戦略的に データを複製することは確立されたプラクティスであり、アンチパターンや不適切なプラクティスとは見なされません。 1 つのサービスのみがデータ セットを所有し、それに対する権限を持つことに注意してください。 レコードのシステムが更新されたときに、読み取りモデルを同期する必要があります。 同期は、通常、図 5.4 に示すように、 発行/サブスクライブ パターンを使用した非同期メッセージングを使用して実装されます。
分散トランザクション
マイクロサービス間でのデータのクエリは困難ですが、複数のマイクロサービス間でトランザクションを実装することはさらに複雑です。 異なるマイクロサービス内の独立したデータ ソース間でデータの一貫性を維持する固有の課題は、控えめにすることはできません。 クラウドネイティブ アプリケーションに分散トランザクションがないということは、分散トランザクションをプログラムで管理する必要があることを意味します。 あなたは、即時整合性の世界から最終的整合性の世界に移行します。
図 5-5 に問題を示します。
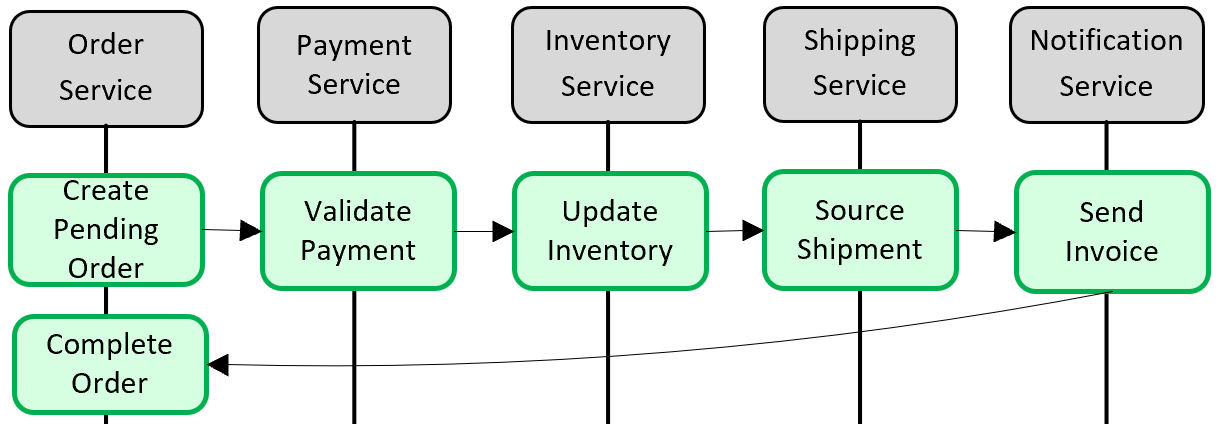
図 5-5. マイクロサービス間でのトランザクションの実装
上の図では、5 つの独立したマイクロサービスが、注文を作成する分散トランザクションに参加しています。 各マイクロサービスは、独自のデータ ストアを維持し、そのストアのローカル トランザクションを実装します。 注文を作成するには、 個々 のマイクロサービスのローカル トランザクションが成功するか、 すべて 操作を中止してロールバックする必要があります。 組み込みのトランザクション サポートは各マイクロサービス内で利用できます。ただし、データの一貫性を維持するために、5 つのサービスすべてにまたがって分散トランザクションをサポートすることはできません。
代わりに、この分散トランザクションを プログラムで構築する必要があります。
分散トランザクション サポートを追加するための一般的なパターンは 、Saga パターンです。 これは、ローカル トランザクションをプログラムでグループ化し、それぞれを順番に呼び出すことによって実装されます。 ローカル トランザクションのいずれかが失敗した場合、Saga は操作を中止し、一連の 補正トランザクションを呼び出します。 補正トランザクションは、前のローカル トランザクションによって行われた変更を元に戻し、データの整合性を復元します。 図 5-6 は、Saga パターンで失敗したトランザクションを示しています。
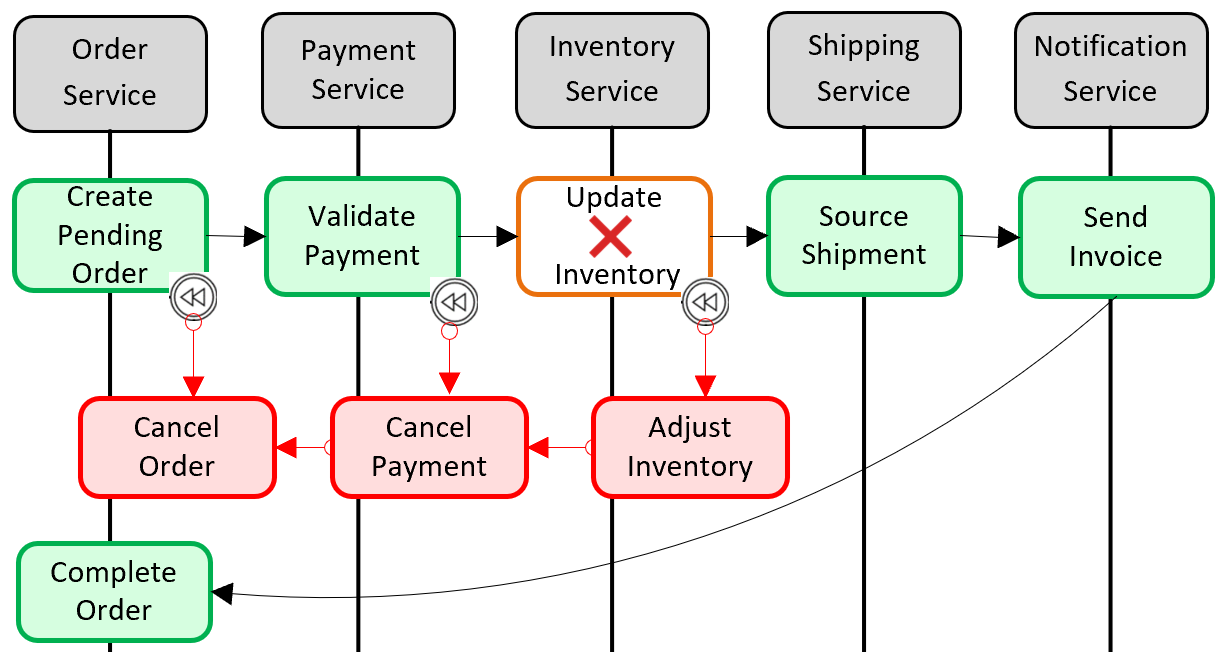
図 5-6 トランザクションのロールバック
前の図では、 インベントリ マイクロ サービスでインベントリの更新操作が失敗しました。 Saga は、一連の補正トランザクション (赤色) を呼び出して在庫数を調整し、支払いと注文を取り消し、各マイクロサービスのデータを一貫した状態に戻します。
Saga パターンは、通常、一連の関連イベントとして振り付けられるか、関連するコマンドのセットとして調整されます。 第 4 章では、オーケストレーションされた saga 実装の基礎となるサービス アグリゲーター パターンについて説明しました。 また、Azure Service Bus と Azure Event Grid のトピックに沿って、振り付けられた saga の実装の基盤となるイベントについても説明しました。
大量のデータ
大規模なクラウドネイティブ アプリケーションでは、多くの場合、大量のデータ要件がサポートされます。 これらのシナリオでは、従来のデータ ストレージ手法によってボトルネックが発生する可能性があります。 大規模にデプロイする複雑なシステムの場合、コマンドとクエリの責任分離 (CQRS) とイベント ソーシングの両方で、アプリケーションのパフォーマンスが向上する可能性があります。
CQRS
CQRS は、パフォーマンス、スケーラビリティ、およびセキュリティを最大化するのに役立つアーキテクチャ パターンです。 このパターンでは、データを読み取る操作と、データを書き込む操作を分離します。
通常のシナリオでは、読み取り操作と書き込み操作の 両方 に同じエンティティ モデルとデータ リポジトリ オブジェクトが使用されます。
ただし、大量のデータ シナリオでは、読み取りと書き込みに対して個別のモデルとデータ テーブルを利用できます。 パフォーマンスを向上させるために、読み取り操作では、データの非正規化表現に対してクエリを実行して、テーブルの結合とテーブル ロックの繰り返しの負荷を回避できます。 コマンドと呼ばれる書き込み操作は、一貫性を保証する完全に正規化されたデータ表現に対して更新されます。 その後、両方の表現を同期させるメカニズムを実装する必要があります。通常、書き込みテーブルが変更されるたびに、変更を読み取りテーブルにレプリケートする イベント が発行されます。
図 5-7 は、CQRS パターンの実装を示しています。
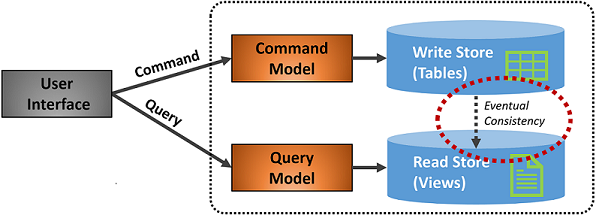
図 5-7 CQRS の実装
前の図では、個別のコマンド モデルとクエリ モデルが実装されています。 各データ書き込み操作は書き込みストアに保存され、読み取りストアに反映されます。 データ伝達プロセスが 最終的な整合性の原則にどのように作用するかに細心の注意を払います。 読み取りモデルは最終的に書き込みモデルと同期しますが、プロセスに多少の遅延がある可能性があります。 最終的な整合性については、次のセクションで説明します。
この分離により、読み取りと書き込みを個別にスケーリングできます。 読み取り操作ではクエリ用に最適化されたスキーマが使用され、書き込みでは更新用に最適化されたスキーマが使用されます。 読み取りクエリは非正規化されたデータに対して行われますが、複雑なビジネス ロジックは書き込みモデルに適用できます。 また、読み取りを公開する操作よりも、書き込み操作に対してセキュリティを強化することもできます。
CQRS を実装すると、クラウドネイティブ サービスのアプリケーション パフォーマンスを向上させることができます。 ただし、より複雑な設計になります。 この原則を、クラウドネイティブ アプリケーションのそれらのセクションに慎重かつ戦略的に適用します。このセクションは、その恩恵を受けることができます。 CQRS の詳細については、Microsoft の書籍 「.NET マイクロサービス: コンテナー化された .NET アプリケーションのアーキテクチャ」を参照してください。
イベント ソーシング
大量のデータ シナリオを最適化するためのもう 1 つのアプローチとして、 イベント ソーシングが含まれます。
通常、システムはデータ エンティティの現在の状態を格納します。 たとえば、ユーザーが電話番号を変更した場合、顧客レコードは新しい番号で更新されます。 データ エンティティの現在の状態は常にわかっていますが、各更新によって以前の状態が上書きされます。
ほとんどの場合、このモデルは正常に動作します。 ただし、大量のシステムでは、トランザクション ロックや頻繁な更新操作によるオーバーヘッドが、データベースのパフォーマンス、応答性、スケーラビリティの制限に影響を与える可能性があります。
イベント ソーシングでは、データをキャプチャする方法が異なります。 データに影響を与える各操作は、イベント ストアに保持されます。 データ レコードの状態を更新する代わりに、会計士の台帳と同様に、各変更を過去のイベントの順次リストに追加します。 イベント ストアは、データのレコードシステムになります。 マイクロサービスの境界付けられたコンテキスト内で、さまざまな具体化されたビューを伝達するために使用されます。 図 5.8 にパターンを示します。
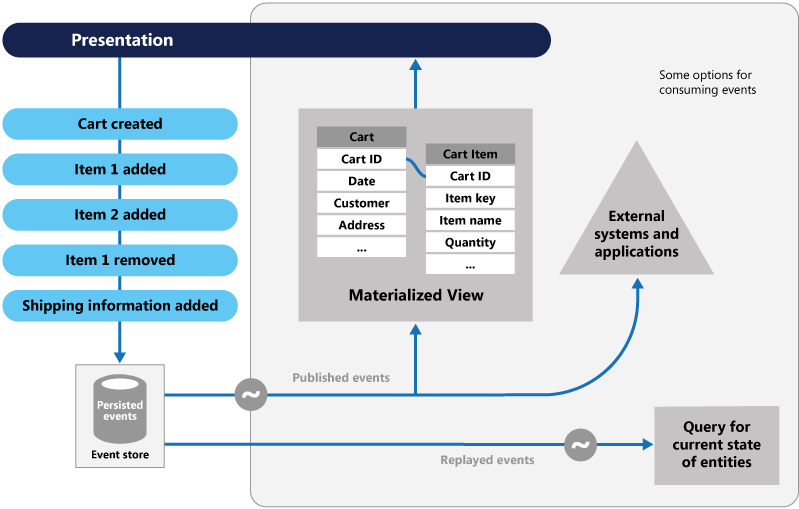
図 5-8 イベント ソーシング
前の図では、ユーザーのショッピング カートの各エントリ (青色) が基になるイベント ストアにどのように追加されるかに注意してください。 隣接する具体化されたビューでは、各ショッピング カートに関連付けられているすべてのイベントを再生することで、システムによって現在の状態が投影されます。 このビューまたは読み取りモデルは、UI に公開されます。 イベントは、外部システムやアプリケーションと統合したり、クエリを実行してエンティティの現在の状態を判断したりすることもできます。 この方法では、履歴を保持します。 エンティティの現在の状態だけでなく、この状態に達した方法も知っています。
機械的に言えば、イベント ソーシングによって書き込みモデルが簡略化されます。 更新または削除はありません。 各データ エントリを不変イベントとして追加すると、リレーショナル データベースに関連付けられている競合、ロック、コンカレンシーの競合が最小限に抑えられます。 具体化されたビュー パターンを使用して読み取りモデルを構築すると、ビューを書き込みモデルから切り離し、アプリケーション UI のニーズを最適化するための最適なデータ ストアを選択できます。
このパターンでは、イベント ソーシングを直接サポートするデータ ストアを検討してください。 Azure Cosmos DB、MongoDB、Cassandra、CouchDB、および RavenDB が適しています。
すべてのパターンやテクノロジと同様に、戦略的に、必要に応じて実装します。 イベント ソーシングはパフォーマンスとスケーラビリティを向上させることができますが、複雑さと学習曲線を犠牲にしています。
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET