クラウドネイティブ データ パターン
ヒント
このコンテンツは eBook の「Azure 向けクラウド ネイティブ .NET アプリケーションの設計」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

本書で見てきたように、クラウドネイティブ アプローチによって、アプリケーションの設計、デプロイ、管理の方法が変わります。 また、データの管理や格納の方法も変わります。
図 5-1 は、その違いを比較したものです。
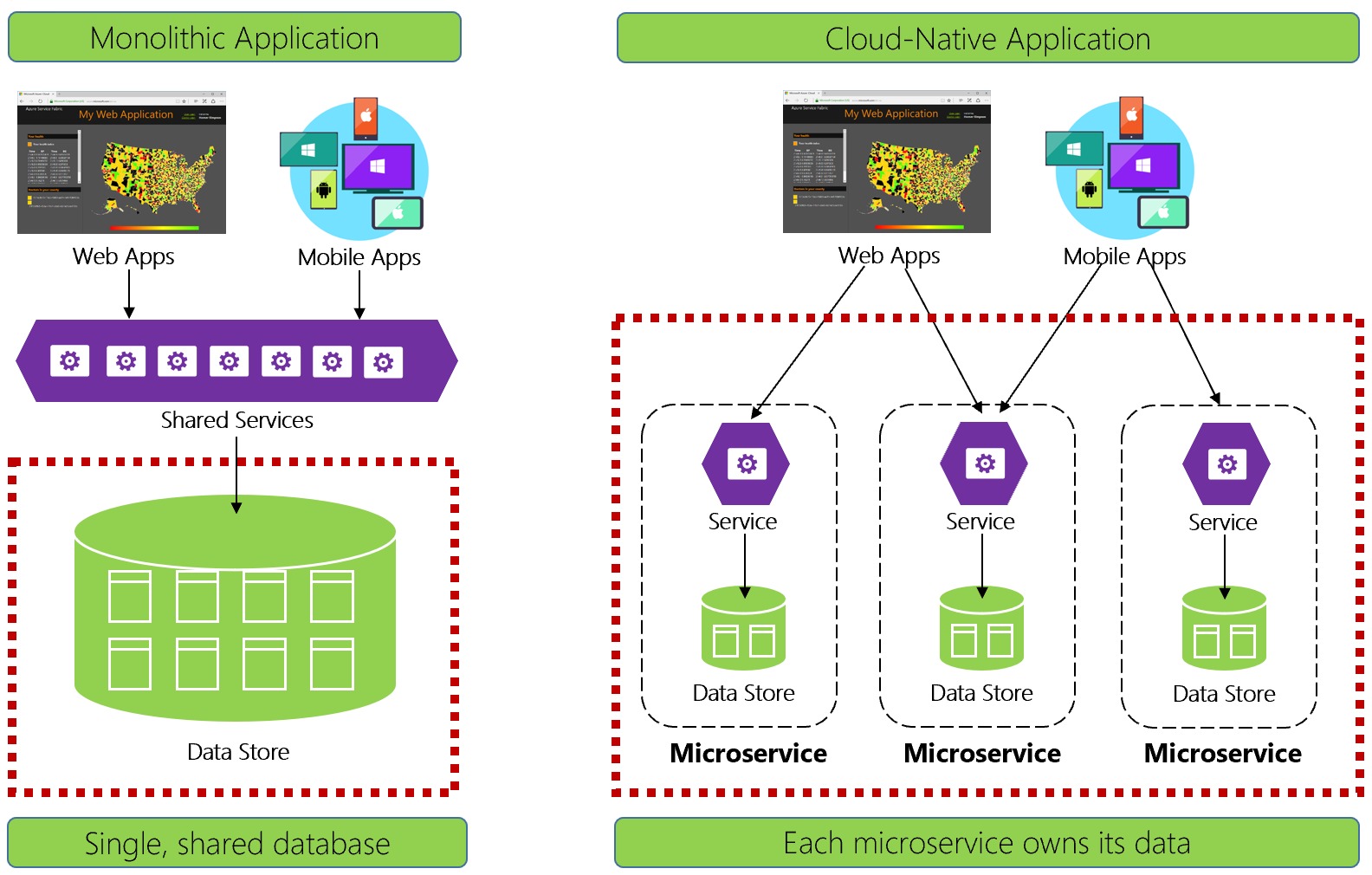
図 5-1. クラウドネイティブ アプリケーションでのデータ管理
経験豊富な開発者であれば、図 5-1 の左側のアーキテクチャをすぐに理解できるでしょう。 この "モノリシック アプリケーション" では、ビジネス サービス コンポーネントが共有サービス レベルに併置され、1 つのリレーショナル データベースからデータが共有されています。
データベースを 1 つにすると、多くの点でデータ管理をシンプルに保つことができます。 複数のテーブルにまたがるデータのクエリも簡単です。 データを変更すると、一緒に更新されるか、すべてがロールバックされます。 ACID トランザクションにより、強力な即時の整合性が保証されます。
クラウドネイティブの設計では、異なるアプローチを採用します。 図 5-1 の右側では、ビジネス機能が小さな独立したマイクロサービスにどのように分離されているかに注目してください。 各マイクロサービスにより、特定のビジネス機能と独自のデータがカプセル化されています。 モノリシック データベースは、それぞれがマイクロサービスと連携する多数の小さなデータベースを持つ分散データ モデルに分解されます。 このようにして、"マイクロサービスごとのデータベース" を公開する設計が完成します。
なぜマイクロサービスごとのデータベースなのでしょうか。
このマイクロサービスごとのデータベースは、特に急速に進化し、大規模なスケールをサポートしなければならないシステムに多くのメリットがあります。 このモデルでは次のようになります。
- ドメイン データはサービス内にカプセル化されます
- データ スキーマは、他のサービスに直接影響することなく進化できます
- 各データ ストアは独立してスケーリングできます
- あるサービスのデータ ストアの障害は、他のサービスには直接影響しません
データを分離することで、マイクロサービスごとに、ワークロード、ストレージのニーズ、読み取りおよび書き込みパターンに最適化されたデータ ストアの種類を実装できます。 選択肢には、リレーショナル、ドキュメント、キー値、グラフベースのデータ ストアがあります。
図 5-2 は、クラウドネイティブ システムにおけるポリグロットな永続化の原則を示しています。
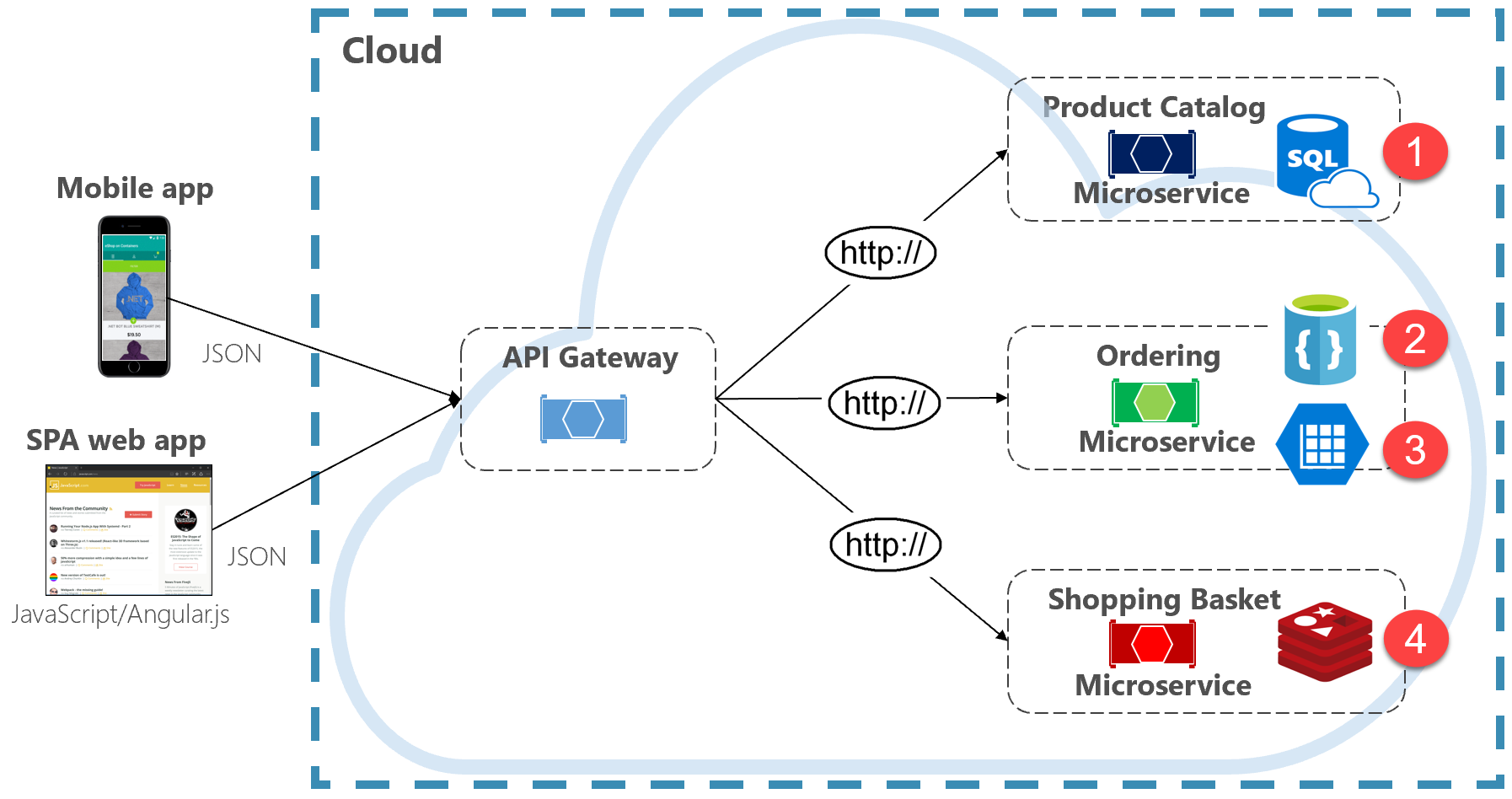
図 5-2 ポリグロットなデータ永続化
前の図では、各マイクロサービスが異なる種類のデータ ストアをサポートしていることに注目してください。
- 製品カタログ マイクロサービスには、基礎となるデータの豊富なリレーショナル構造に対応するため、リレーショナル データベースが使用されています。
- ショッピング カート マイクロサービスには、シンプルなキー値データ ストアをサポートする分散キャッシュが使用されています。
- 注文マイクロサービスには、大量の読み取り操作に対応するために、書き込み操作用の NoSql ドキュメント データベースと、高度に非正規化されたキー/値ストアの両方が使用されています。
複雑なデータを扱うマイクロサービスにはリレーショナル データベースが適していますが、NoSQL データベースは非常に人気があります。 これには大規模なスケールと高い可用性が備わっています。 そのスキーマレスという性質により、開発者は、変更にコストも時間もかかる型指定されたデータ クラスや ORM などのアーキテクチャから解放されます。 NoSQL データベースについては、この章で後述します。
データを個別のマイクロサービスにカプセル化することで、アジリティ、パフォーマンス、スケーラビリティを向上させることができますが、同時に多くの課題もあります。 次のセクションでは、これらの課題と、課題を克服するためのパターンと手法について説明します。
サービスをまたぐクエリ
マイクロサービスは独立しており、在庫、出荷、注文などの特定の機能に特化していますが、他のマイクロサービスとの統合が必要になることがよくあります。 多くの場合、統合には、あるマイクロサービスが他のマイクロサービスに対してデータの "クエリを実行する処理" を伴います。 図 5-3 は、このシナリオを示しています。
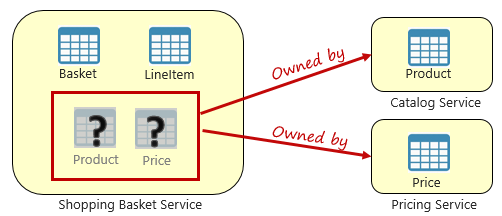
図 5-3 マイクロサービスをまたがるクエリ
前の図は、ユーザーの買い物かごに項目を追加する買い物かごマイクロサービスを示しています。 このマイクロサービスのデータ ストアには、バスケットと品目のデータが含まれていますが、製品や価格設定のデータは保持されていません。 代わりに、これらのデータ項目はカタログと価格設定のマイクロサービスによって所有されています。 この側面が問題となります。 どうすれば買い物かごマイクロサービスからユーザーの買い物かごに製品を追加する際に、そのデータベース内に製品や価格設定のデータがない場合はどうすればよいでしょうか。
第 4 章で説明されている選択肢の 1 つは、買い物かごからカタログと価格設定のマイクロサービスに対する直接 HTTP 呼び出しです。 ただし、第 4 章では、同期 HTTP 呼び出しを使用すると、複数のマイクロサービスがまとめて "カップル" にされ、マイクロサービスの自律性が低下し、アーキテクチャ上の利点を減ると説明しました。
また、サービスごとに受信と送信のキューを分けて、要求/応答パターンを実装することもできます。 ただし、このパターンは複雑であり、要求と応答のメッセージを関連付けるためのプラミングが必要になります。 バックエンド マイクロサービスの呼び出しは分離されますが、呼び出し元のサービスは、呼び出しが完了するまで同期的に待機する必要があります。 ネットワークの輻輳、一時的な障害、マイクロサービスの過負荷により、処理が長引いたり、失敗したりすることがあります。
その代わりに、サービスをまたぐサービスの依存関係を取り除くためのパターンとして広く受け入れられているのは、図 5-4 に示す具体化されたビュー パターンです。
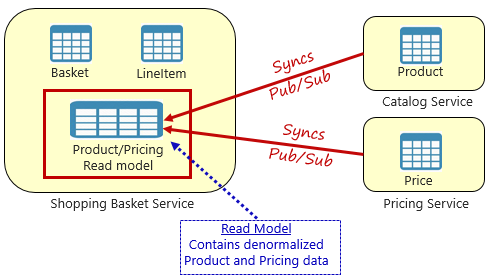
図 5-4 具体化されたビュー パターン
このパターンでは、ローカル データ テーブル ("読み取りモデル" と呼ばれます) を買い物かごサービスに配置します。 このテーブルには、製品と価格設定のマイクロサービスの必要なデータの非正規化されたコピーが含まれています。 データを買い物かごマイクロサービスに直接コピーすることで、コストのかかるサービスをまたぐ呼び出しが不要になります。 データがサービスのローカルにあるので、サービスの応答時間と信頼性が向上します。 さらに、データの独自のコピーがあるので、買い物かごサービスの回復性が高まります。 万が一、カタログ サービスが使用できなくなった場合でも、買い物かごサービスには直接影響しません。 独自のストアのデータを使用して、買い物かごの運用を続けることができます。
このアプローチの問題点は、システム内に重複するデータが存在することです。 ただし、"戦略的に" クラウドネイティブ システムでデータを重複させることは確立された手法であり、アンチパターンや悪い慣習とは考えられていません。 "1 つのサービスのみ" がデータ セットを所有し、それに対する権限を持つことができることに注意してください。 レコードのシステムが更新されたら、読み取りモデルを同期する必要があります。 通常、同期は、図 5.4 に示すように発行とサブスクライブ パターンを使用した非同期メッセージングによって実装されます。
分散トランザクション
マイクロサービスをまたいでデータのクエリを実行することは困難ですが、複数のマイクロサービスをまたぐトランザクションを実装することはさらに複雑です。 異なるマイクロサービスの独立したデータ ソース全体でデータの整合性を維持する場合に固有の課題を軽視することはできません。 クラウドネイティブ アプリケーションに分散トランザクションがないということは、分散トランザクションをプログラムで管理する必要があることを意味します。 "即時の整合性" の世界から、"最終的な整合性" の世界へと引っ越すことになります。
図 5-5 は、この問題を示しています。
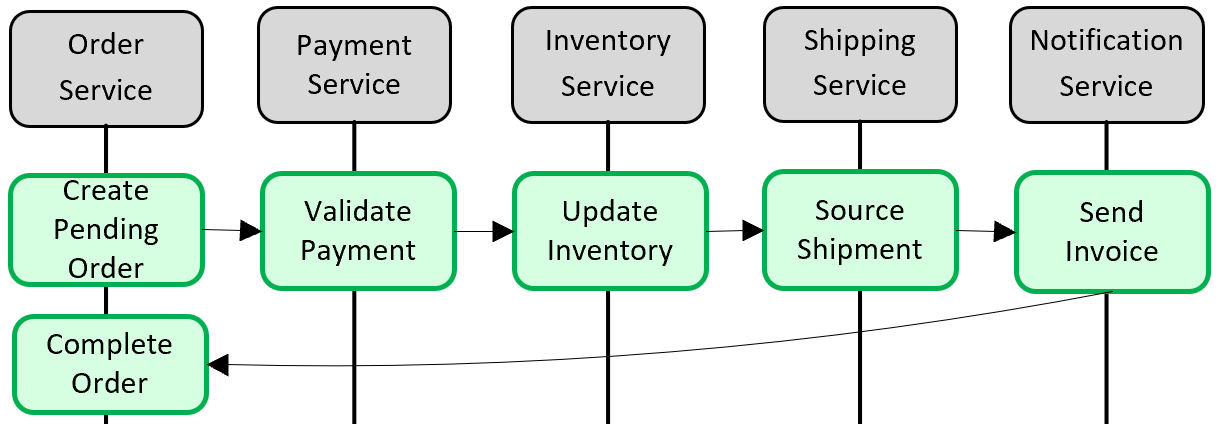
図 5-5 マイクロサービスをまたぐトランザクションの実装
前の図では、5 つの独立したマイクロサービスが、注文を作成する分散トランザクションに参加しています。 各マイクロサービスには独自のデータ ストアが維持され、そのストアのローカル トランザクションが実装されています。 注文を作成するには、個々のマイクロサービスの "それぞれ" のローカル トランザクションが成功する必要があります。それ以外の場合は、"すべて" が中止され、操作がロールバックされる必要があります。 各マイクロサービスの内部では組み込みのトランザクションがサポートされていますが、データの整合性を維持するための 5 つのサービスすべてにまたがる分散トランザクションはサポートされていません。
代わりに、この分散トランザクションを "プログラムで" 構築する必要があります。
分散トランザクションのサポートを追加するための一般的なパターンは Saga パターンです。 これを実装するには、ローカル トランザクションをプログラムでグループ化し、1 つずつ順番に呼び出します。 ローカル トランザクションのいずれかが失敗すると、Saga により操作は中止され、一連の補償トランザクションが呼び出されます。 補償トランザクションは、先行するローカル トランザクションによって行われた変更を元に戻し、データの整合性を復元するものです。 図 5-6 は、Saga パターンで失敗したトランザクションを示しています。
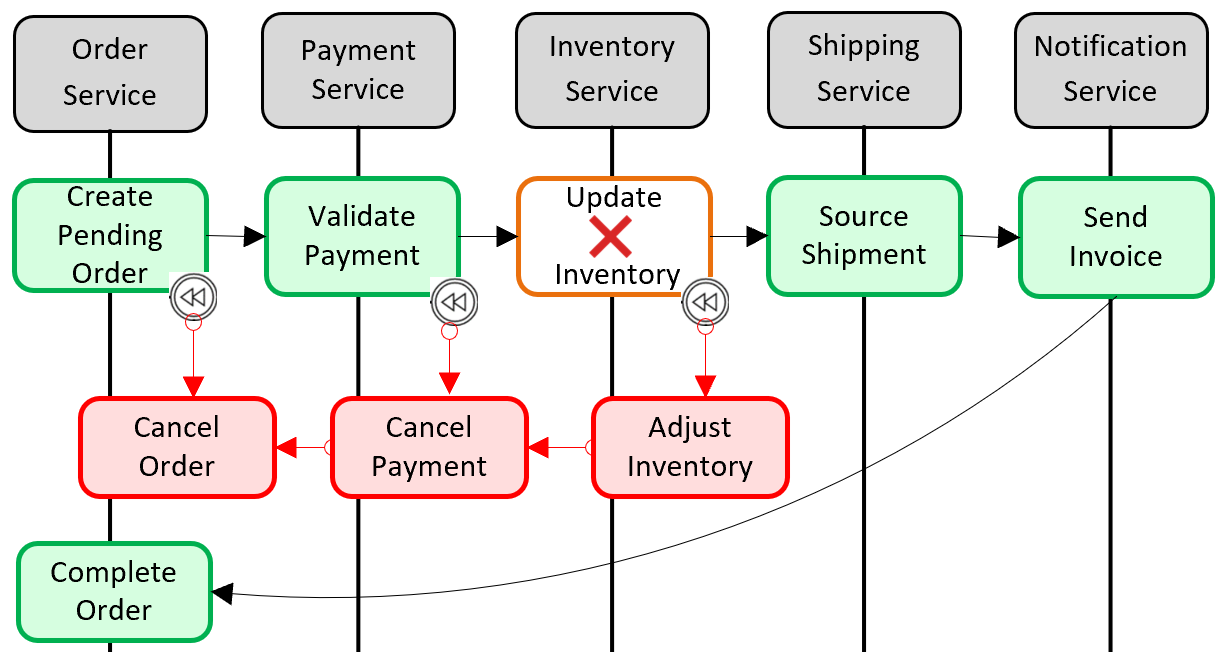
図 5-6. トランザクションのロールバック
前の図では、在庫マイクロサービスで "在庫の更新" 操作が失敗しています。 Saga により、一連の補償トランザクション (赤色) が呼び出され、在庫数が調整され、支払いと注文が取り消され、各マイクロサービスのデータが一貫した状態に戻されます。
通常、Saga パターンは、関連する一連のイベントとして振り付けられるか、関連する一連のコマンドとして編成されます。 第 4 章では、編成された saga 実装の基盤となるサービス アグリゲーター パターンについて説明しました。 また、Azure Service Bus と Azure Event Grid のトピックに沿って、振り付けられた saga の実装の基盤となるイベントについても説明しました。
大量のデータ
大規模なクラウドネイティブ アプリケーションは、多くの場合、大量のデータ要件をサポートします。 このようなシナリオでは、従来のデータ ストレージ テクノロジがボトルネックになることがあります。 大規模にデプロイする複雑なシステムの場合、コマンド クエリ責務分離 (CQRS) とイベント ソーシングの両方によってアプリケーションのパフォーマンスが向上する可能性があります。
CQRS
CQRS は、パフォーマンス、スケーラビリティ、およびセキュリティを最大化するのに役立つアーキテクチャ パターンです。 このパターンにより、データを読み取る操作とデータを書き込む操作が分離されます。
通常のシナリオでは、読み取りと書き込みの "両方" の操作に、同じエンティティ モデルとデータ リポジトリ オブジェクトが使用されます。
ただし、大量のデータを扱うシナリオでは、読み取り用と書き込み用にモデルとデータ テーブルを分けることが有効です。 パフォーマンスを向上させるために、読み取り操作では、データの高度に非正規化された表現に対してクエリを実行し、コストの高い反復的なテーブル結合とテーブルのロックを回避できます。 "コマンド" と呼ばれる "書き込み" 操作は、整合性を保証する完全に正規化されたデータ表現に対して更新されます。 次に、両方の表現の同期状態を維持するメカニズムを実装する必要があります。通常、書き込みテーブルが変更されるたびに、読み取りテーブルに変更をレプリケートするイベントが発行されます。
図 5-7 は、CQRS パターンの実装を示しています。
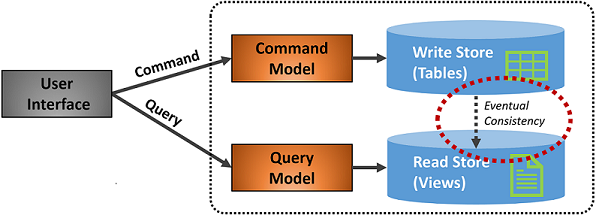
図 5-7 CQRS の実装
前の図では、コマンドとクエリのモデルが別々に実装されています。 各データ書き込み操作は、書き込みストアに格納されてから、読み取りストアに反映されます。 最終的な整合性の原則に基づいてデータが反映されていることに注目してください。 読み取りモデルは最終的に書き込みモデルと同期されますが、その過程で多少の遅れが生じる可能性があります。 最終的な整合性については次のセクションで説明します。
このように分離することで、読み取りと書き込みを独立してスケーリングすることができます。 読み取り操作には、クエリに最適化されたスキーマが使用され、書き込みには、更新に最適化されたスキーマが使用されます。 読み込みクエリを非正規化されたデータに対して実行し、書き込みモデルには複雑なビジネス ロジックを適用することができます。 また、書き込み操作の方に、読み取りを公開する場合よりも厳しいセキュリティを課すことができます。
CQRS を実装すると、クラウドネイティブ サービスのアプリケーション パフォーマンスを向上させることができます。 ただし、設計はより複雑になります。 この原則は、クラウドネイティブ アプリケーションのうち、メリットがあるセクションに、慎重かつ戦略的に適用してください。 CQRS の詳細については、Microsoft のドキュメント「.NET マイクロサービス: コンテナー化された .NET アプリケーションのアーキテクチャ」を参照してください。
イベント ソーシング
大量のデータのシナリオを最適化するもう 1 つのアプローチとして、イベント ソーシングがあります。
通常、システムによって、データ エンティティの現在の状態が格納されます。 たとえば、ユーザーが電話番号を変更した場合、顧客レコードは新しい番号で更新されます。 データ エンティティの現在の状態は常にわかりますが、更新のたびに以前の状態が上書きされます。
ほとんどの場合、このモデルはうまく機能します。 ただし、大量のシステムでは、トランザクションのロックや頻繁な更新操作によるオーバーヘッドが、データベースのパフォーマンスや応答性に影響し、スケーラビリティが制限される可能性があります。
イベント ソーシングは、データをキャプチャするアプローチが異なります。 データに影響する各操作は、イベント ストアに保存されます。 データ レコードの状態を更新するのではなく、過去のイベントの連続した一覧に各変更を追加します。これは会計士の台帳と似ています。 イベント ストアは、データの記録システムになります。 これは、マイクロサービスの限界のあるコンテキスト内で、さまざまな具体化されたビューを反映するために使用されます。 図 5.8 は、そのパターンを示しています。
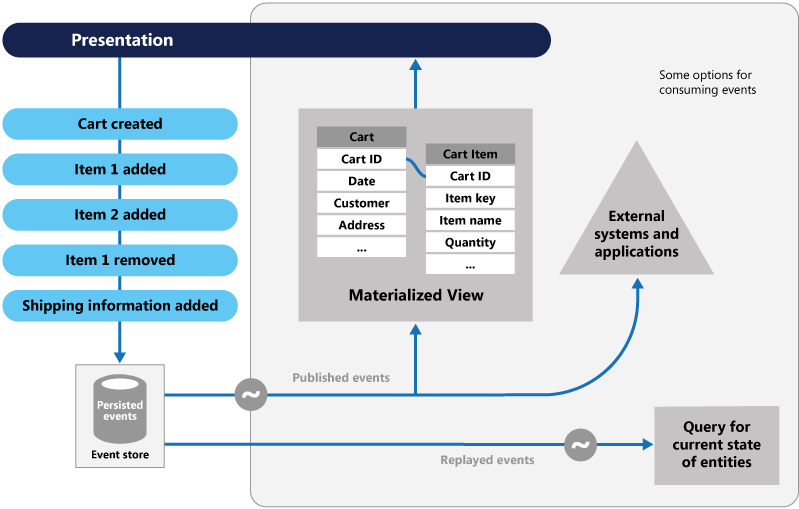
図 5-8. イベント ソーシング
前の図では、ユーザーのショッピング カートの各エントリ (青色) が、基礎となるイベント ストアにどのように追加されているかに注目してください。 隣接する具体化されたビューでは、各ショッピング カートに関連するすべてのイベントを再生することで、システムによって現在の状態が投影されています。 このビュー、つまり読み取りモデルは、UI に公開されます。 イベントを外部のシステムやアプリケーションと統合することや、エンティティの現在の状態を調べるためにクエリを実行することができます。 このアプローチでは、履歴を維持します。 エンティティの現在の状態だけでなく、どのようにしてその状態に至ったかも把握できます。
メカニズム的に言えば、イベント ソーシングによって書き込みモデルは単純になります。 更新も削除もありません。 各データ エントリを不変のイベントとして追加することで、リレーショナル データベースに関連する競合、ロック、同時実行の競合を最小限に抑えることができます。 具体化されたビュー パターンで読み取りモデルを構築すると、書き込みモデルからビューを切り離し、アプリケーション UI のニーズに合わせて最適なデータ ストアを選択することができます。
このパターンでは、イベント ソーシングを直接サポートするデータ ストアを検討してください。 Azure Cosmos DB、MongoDB、Cassandra、CouchDB、RavenDB が候補として挙げられます。
すべてのパターンやテクノロジと同様に、戦略的に必要なときに実装してください。 イベント ソーシングにより、パフォーマンスとスケーラビリティを向上させることはできますが、複雑さと学習曲線を犠牲にすることになります。
.NET