セット操作 (C#)
LINQ のセット操作とは、同一または別個のコレクション内に等しい要素があるかどうかに基づいて結果のセットを生成するクエリ操作を指します。
| メソッド名 | 説明 | C# のクエリ式の構文 | 詳細情報 |
|---|---|---|---|
Distinct または DistinctBy |
コレクションから重複する値を削除します。 | 該当なし。 | Enumerable.Distinct Enumerable.DistinctBy Queryable.Distinct Queryable.DistinctBy |
Except または ExceptBy |
差集合 (一方のコレクションにだけ存在し、もう一方のコレクションには出現しない要素) を返します。 | 該当なし。 | Enumerable.Except Enumerable.ExceptBy Queryable.Except Queryable.ExceptBy |
Intersect または IntersectBy |
積集合 (2 つのコレクションのそれぞれに出現する要素) を返します。 | 該当なし。 | Enumerable.Intersect Enumerable.IntersectBy Queryable.Intersect Queryable.IntersectBy |
Union または UnionBy |
和集合 (2 つのコレクションのどちらかに出現する一意の要素) を返します。 | 該当なし。 | Enumerable.Union Enumerable.UnionBy Queryable.Union Queryable.UnionBy |
Distinct および DistinctBy
次の例は、文字列のシーケンスに対する Enumerable.Distinct メソッドの動作を示しています。 返されたシーケンスには、入力シーケンスからの一意の要素が格納されています。
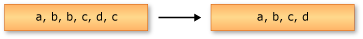
string[] words = ["the", "quick", "brown", "fox", "jumped", "over", "the", "lazy", "dog"];
IEnumerable<string> query = from word in words.Distinct()
select word;
foreach (var str in query)
{
Console.WriteLine(str);
}
/* This code produces the following output:
*
* the
* quick
* brown
* fox
* jumped
* over
* lazy
* dog
*/
DistinctBy は Distinct に対する別の方法であり、keySelector を受け取ります。 keySelector は、ソースの種類の比較識別子として使用されます。 次のコードでは、単語はその Length に基づいて判別され、それぞれの長さの最初の単語が表示されます。
string[] words = ["the", "quick", "brown", "fox", "jumped", "over", "the", "lazy", "dog"];
foreach (string word in words.DistinctBy(p => p.Length))
{
Console.WriteLine(word);
}
// This code produces the following output:
// the
// quick
// jumped
// over
Except および ExceptBy
次の例で、Enumerable.Except の動作を説明します。 返されたシーケンスには、1 つ目の入力シーケンスのうち、2 つ目の入力シーケンスに存在しない要素のみが格納されています。
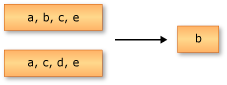
この記事の以下の例では、この分野の一般的なデータ ソースを使用します。
public enum GradeLevel
{
FirstYear = 1,
SecondYear,
ThirdYear,
FourthYear
};
public class Student
{
public required string FirstName { get; init; }
public required string LastName { get; init; }
public required int ID { get; init; }
public required GradeLevel Year { get; init; }
public required List<int> Scores { get; init; }
public required int DepartmentID { get; init; }
}
public class Teacher
{
public required string First { get; init; }
public required string Last { get; init; }
public required int ID { get; init; }
public required string City { get; init; }
}
public class Department
{
public required string Name { get; init; }
public int ID { get; init; }
public required int TeacherID { get; init; }
}
各 Student は、学年、主要学科、一連のスコアを持っています。 Teacher は、その教師が授業を受け持つキャンパスを示す City プロパティも持っています。 Department は名称と、学科長を務める Teacher への参照を持っています。
string[] words1 = ["the", "quick", "brown", "fox"];
string[] words2 = ["jumped", "over", "the", "lazy", "dog"];
IEnumerable<string> query = from word in words1.Except(words2)
select word;
foreach (var str in query)
{
Console.WriteLine(str);
}
/* This code produces the following output:
*
* quick
* brown
* fox
*/
ExceptBy メソッドは Except に対する別の方法であり、異なる種類と keySelector の 2 つのシーケンスを受け取ります。 keySelector は、最初のコレクションの型と同じ型です。 以下に示す除外対象の Teacher 配列と教師 ID を考えてみましょう。 最初のコレクション内の教師で 2 番目のコレクション内に存在していない教師を見つけるには、2 番目のコレクションに教師の ID を射影します。
int[] teachersToExclude =
[
901, // English
965, // Mathematics
932, // Engineering
945, // Economics
987, // Physics
901 // Chemistry
];
foreach (Teacher teacher in
teachers.ExceptBy(
teachersToExclude, teacher => teacher.ID))
{
Console.WriteLine($"{teacher.First} {teacher.Last}");
}
前述の C# コードでは:
teachers配列は、teachersToExclude配列内に存在しない教師のみにフィルター処理されます。teachersToExclude配列には、すべての学科長のID値が含まれています。ExceptByを呼び出すと、新しい値のセットがコンソールに書き込まれます。
新しい値のセットは Teacher 型であり、これは最初のコレクションの型です。 teachers 配列内の teacher のうち、対応する ID 値が teachersToExclude 配列内にないものがコンソールに出力されます。
Intersect および IntersectBy
次の例で、Enumerable.Intersect の動作を説明します。 返されたシーケンスには、両方の入力シーケンスに共通する要素が格納されています。
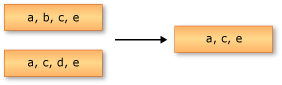
string[] words1 = ["the", "quick", "brown", "fox"];
string[] words2 = ["jumped", "over", "the", "lazy", "dog"];
IEnumerable<string> query = from word in words1.Intersect(words2)
select word;
foreach (var str in query)
{
Console.WriteLine(str);
}
/* This code produces the following output:
*
* the
*/
IntersectBy メソッドは Intersect に対する別の方法であり、異なる種類と keySelector の 2 つのシーケンスを受け取ります。 keySelector は、2 番目のコレクションの種類の比較識別子として使用されます。 以下の生徒と教師の配列について考えてみましょう。 次のクエリは、各シーケンス内の項目を名前で照合して、教師でもある学生を見つけます。
foreach (Student person in
students.IntersectBy(
teachers.Select(t => (t.First, t.Last)), s => (s.FirstName, s.LastName)))
{
Console.WriteLine($"{person.FirstName} {person.LastName}");
}
前述の C# コードでは:
- このクエリは、名前を比較することで、
TeacherとStudentの共通部分を生成します。 - 結果のシーケンスには、両方の配列内で見つかる人物だけが含まれます。
- 結果の
Studentインスタンスが、コンソールに出力されます。
Union および UnionBy
次の例は、2 つの文字列シーケンスに対する和集合演算を示しています。 返されたシーケンスには、両方の入力シーケンスからの一意の要素が格納されています。
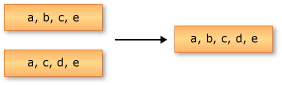
string[] words1 = ["the", "quick", "brown", "fox"];
string[] words2 = ["jumped", "over", "the", "lazy", "dog"];
IEnumerable<string> query = from word in words1.Union(words2)
select word;
foreach (var str in query)
{
Console.WriteLine(str);
}
/* This code produces the following output:
*
* the
* quick
* brown
* fox
* jumped
* over
* lazy
* dog
*/
UnionBy メソッドは Union に対する別の方法であり、同じ種類と keySelector の 2 つのシーケンスを受け取ります。 keySelector は、ソースの種類の比較識別子として使用されます。 次のクエリは、学生または教師であるすべての人物の一覧を生成します。 教師でもある学生は、和集合セットに 1 回だけ追加されます。
foreach (var person in
students.Select(s => (s.FirstName, s.LastName)).UnionBy(
teachers.Select(t => (FirstName: t.First, LastName: t.Last)), s => (s.FirstName, s.LastName)))
{
Console.WriteLine($"{person.FirstName} {person.LastName}");
}
前述の C# コードでは:
teachersおよびstudents配列は、名前をキー セレクターとして使用して結合されます。- 結果の名前がコンソールに出力されます。
関連項目
.NET
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示