データ統一のためのマッチングルールの定義
統合のこの手順では、テーブル間照合の一致順序とルールを定義します。 この手順には少なくとも 2 つのテーブルが必要です。 レコードが一致すると、各テーブルのすべてのフィールドを含む 1 つのレコードに連結されます。 代替行 (重複排除ステップからの非勝者行) は、照合時に考慮されます。 ただし、行がテーブル内の代替行と一致する場合、レコードは勝者の行と一致します。
注意
一致条件を作成して 次へ を選択すると、選択したテーブルや列を削除することはできません。 必要に応じて、戻る を選択し、選択したテーブルと列を確認してから続行します。
次の手順と画像は、統合プロセスを初めて実行したときのものです。 既存の統合設定を編集するには、統合設定を更新するを参照してください。
エンリッチしたテーブルを含める (プレビュー)
統合結果を改善するためにデータ ソース レベルでテーブルをエンリッチした場合は、それらを選択します。 詳細については、データ ソースのエンリッチメント を参照してください。 重複排除ルール ページ でエンリッチ テーブルを選択した場合は、再度選択する必要はありません。
マッチング ルールページで、ページ上部の 強化されたテーブルを使用する を選択します。
エンリッチしたテーブルを使用する ペインから、1 つ以上のエンリッチされたテーブルを選択します。
完了を選択します。
一致順を指定します。
各照合では、2 つ以上のテーブルを単一の連結テーブルに統合します。 同時に、一意の顧客レコードを保持します。 照合順序はシステムがレコードの照合を行う順序を示します。
重要
最初のテーブルは主テーブルと呼ばれ、統合されたプロファイルの基盤として機能します。 選択された追加のテーブルが、このテーブルに追加されます。
重要な考慮事項:
- 主テーブルとして、顧客に関する最も完全で信頼性の高いプロファイル データを含むテーブルを選択します。
- 他のテーブルと共通のカラムをいくつか持つテーブル (たとえば、名前、電話番号、メールアドレスなど) を主テーブルとして選択します。
- テーブルは、優先度の高い他のテーブルとのみ照合できます。 したがって、Table2 は Table1 とのみ一致し、Table3 は Table2 または Table1 と一致することができます。
マッチング ルール ページで、上下の矢印を使ってテーブルを好きな順番に移動するか、ドラッグ アンド ドロップします。 たとえば、主テーブルとして eCommerceCustomers を選択し、2 番目のテーブルとして loyCustomers を選択します。
一致するものが見つかったかどうかに関係なく、テーブルが含むすべてのレコードを一意の顧客として保持するには、すべてのレコードを含める を選択します。 他のテーブルのレコードと一致しないこのテーブルのレコードは、統合プロファイルに含まれます。 一致しないレコードはシングルトンと呼ばれます。
主テーブル Contacts:eCommerce は次のテーブル CustomerLoyalty:Loyalty と一致します。 2 つ以上のテーブルがある場合、最初の照合ステップの結果であるデータセットは、次のテーブルと一致します。 eCommerceContacts に重複がまだ存在する場合 、loyCustomer が eCommerceContacts と一致すれば、 eCommerceContacts 重複行は 1 つの顧客レコードに縮小されません。 ただし、loyCustomer の重複行が eCommerceContacts の行と一致する場合、それらは 1 つの顧客レコードに縮小されます。。

照合ペアのルールを定義する
一致ルールは、テーブルの特定のペアが一致するロジックを指定します。 ルールは、1 つ以上の条件で構成されます。
テーブル名の横にある警告は、一致ペアに対して一致ルールが定義されていないことを意味します。
一致ルールを定義するには、テーブル ペアに対してルールの追加を選択します。
ルールの追加ウインドウで、ルールの条件を構成します。
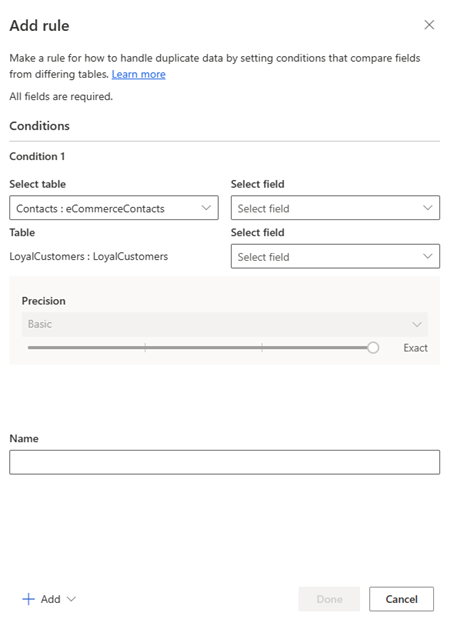
テーブル/フィールドの選択 (最初の行): 顧客固有のテーブルと列を選択します。 たとえば、電話番号や電子メール アドレスなどです。 アクティビティ タイプの列によるマッチングは避けてください。 たとえば、購入 ID は、他のレコードの種類では一致しない可能性があります。
テーブル/フィールドの選択 (2 番面目の行): 最初の行で指定したテーブルの列に関連する列を選択します。
正規化: 選択した列の正規化オプションを以下から選択します。
- 数字: ローマ数字などの他の数字システムをアラビア数字に変換します。 VIII は 8 になります。
- 記号: すべての記号と特殊文字を削除します。 Head&Shoulder は HeadShoulder になります。
- テキストを小文字に: すべての文字を小文字に変換します。 ALL CAPS and Title Case は all caps and title case になります。
- タイプ (電話、名前、住所、組織): 名前、役職、電話番号、住所および組織を標準化します。
- Unicode から ASCII へ: Unicode 表記を ASCII 文字に変換します。 /u00B2 は 2 になります。
- 空白: すべてのスペースを削除します。 Hello World は、HelloWorld になります。
精度: この条件に適用する精度のレベルを設定します。 精度はあいまい一致で使用され、2 つの文字列が一致するとみなされるために必要な近似性を決定します。
- 基本: 低 (30%)、中 (60%)、高 (80%)、完全一致t (100%) から選択します。 100%一致するレコードのみを一致とする場合は 完全一致 を選択します。
- カスタム: レコードが一致する必要がある割合を設定します。 システムは、このしきい値を超えるレコードのみを照合します。
名前: ルールの名前です。
カラムが複数の条件を満たす場合にのみテーブルを一致させるには、追加>条件の追加 を選択して一致規則に条件を追加します。 条件は論理 AND 演算子で接続されるため、すべての条件が満たされた場合にのみ実行されます。
完了を選択してルールを終了します。
オプションで、ルールをさらに追加 します。
次へを選択します。
照合ペアにルールを追加する
照合ルールは条件セットを表します。 複数の列に基づく条件でテーブルをマッチさせるには、さらにルールを追加します。
ルールを追加するテーブルで ルールの追加 を選択します。
照合ペアのルールを定義する の手順に従います。
Note
ルールの順序は重要です。 照合アルゴリズムは、最初のルールに基づいて特定の顧客レコードを一致しようと試み、最初のルールで一致が識別されなかった場合にのみ 2 番目のルールに進みます。
詳細オプション
ルールに例外を追加する
ほとんどの場合、テーブルの照合により、統合されたデータを持つ一意の顧客プロファイルが作成されます。 偽陽性や偽陰性のまれなケースに対処するために、照合ルールの例外を定義します。 例外は、照合ルールの処理後に適用され、例外条件を満たすレコードすべての照合を回避します。
たとえば、照合ルールが姓、都市、および生年月日を組み合わせている場合、システムは、同じプロファイルと同じ町に住んでいる同じ姓を持つ双子を識別します。 結合するテーブルが含む名が同じでない場合は、プロファイルに一致しない例外を指定できます。
ルールの編集ウィンドウで、追加>例外の追加を選択します。
例外条件を指定します。
完了 を選択してルールを保存します。
カスタム照合条件の指定
既定の照合ロジックをオーバーライドする条件を指定します。 次の 4 つのオプションを使用できます。
| 回答内容 | 説明設定 | 例 |
|---|---|---|
| 常に照合する | 常に照合される主キーの値を定義します。 | 常に、主キーが 12345 の行と主キーが 54321 の行を照合します。 |
| 照合しない | 照合しない主キーの値を定義します。 | 主キーが 12345 の行と主キーが 54321 の行を照合しません。 |
| バイパス | システムが照合フェーズで常に無視するべき値を定義します。 | 照合中に 11111 と Unknown の値を無視します。 |
| エイリアス マッピング | システムが同じ値と見なすべき値を定義します。 | Joe が Joseph と等しいと見なします。 |
カスタムを選択します。
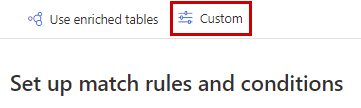
カスタム タイプを選択し、テンプレートのダウンロードを選択します。 スペースを使用せずにテンプレートの名前を変更します。 照合オプションごとに個別のテンプレートを使用します。
ダウンロードしたテンプレート ファイルを開き、詳細を入力します。 テンプレートには、カスタム照合で使用されるテーブルとテーブルの主キーの値を指定するフィールドが含まれています。 テーブル名は大文字と小文字が区別されます。 たとえば、営業 テーブルの主キー 12345 を 連絡先 テーブルの主キー 34567 と常に一致させる場合は、テンプレートに次のように入力します:
- Table1: 営業
- Table1Key: 12345
- Table2: 連絡先
- Table2Key: 34567
同じテンプレート ファイルで、複数のテーブルからカスタム一致レコードを指定できます。
テーブルの重複排除にカスタム照合を指定する場合は、Table1 と Table2 の両方と同じテーブルを指定し、異なる主キー値を設定します。 カスタム照合を使用するには、少なくとも 1 つの重複排除規則をテーブルに定義する必要があります。
オーバーライドをすべて追加してからテンプレート ファイルを保存します。
データ>データ ソース に移動し、テンプレート ファイルを新しいテーブルとして取り込みます。
ファイルをアップロードした後、カスタム オプションを再度選択します。 ドロップダウン メニューから必要なテーブルを選択し、完了 を選択します。
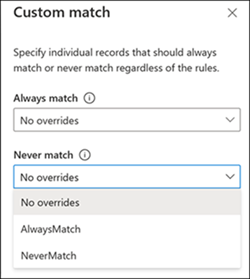
使用する照合オプションにより、カスタム照合の適用が異なります。
- 常に一致 または 常に不一致 の場合は次のステップに進みます。
- バイパスまたはエイリアス マッピングの場合は、既存の照合ルールで編集を選択するか、新しいルールを作成します。 正規化ドロップダウンから カスタム バイパス または エイリアス マッピング オプションを選択してから、完了 を選択します。
カスタム ウィンドウで完了を選択して、カスタム一致構成を適用します。
取り込まれた各テンプレート ファイルは、独自のデータ ソースです。 特別な照合処理が必要なレコードが見つかった場合は、適切なデータ ソースを更新します。 更新は、次の統合プロセスで使用されます。 たとえば、1 人として統合された同じ住所に住むほぼ同じ名前の双子を識別します。 データ ソース を更新して、双子を個別の一意のレコードとして識別します。