データ管理の概要
この記事では、データ管理フレームワークを使用して、財務と運用のデータ エンティティおよびデータ エンティティ パッケージを管理する方法について説明します。
データ管理フレームワークは、以下の概念で構成されています。
- データ エンティティ - データ エンティティは、1 つ以上の基になるテーブルを概念的に抽象化してカプセル化したものです。 データ エンティティは、共通のデータ概念や機能、たとえば、顧客または仕入先を表します。 データ エンティティは、業務コンセプトに精通したユーザーが容易に理解できるように意図されています。 データ エンティティの作成後、Excel アドインを使用して再利用したり、インポート/エクスポート パッケージを定義したり、統合に使用することができます。
- データ プロジェクト - マッピングおよび既定の処理オプションを含む、コンフィギュレーションされているデータ エンティティを含むプロジェクト。
- データ ジョブ - データ プロジェクトの実行インスタンス、アップロードされたファイル、スケジュール (反復)、および処理オプションを含むジョブ。
- ジョブ履歴 - ステージングおよびターゲット ジョブへのステージングのソースの履歴。
- データ パッケージ - データ プロジェクト マニフェストとデータ ファイルを含む単一の圧縮ファイル。 これは、データジョブから生成され、マニフェストを含む複数のファイルのインポートまたはエクスポートに使用されます。
データ管理フレームワークでは、以下のコア データ管理シナリオでデータ エンティティを使用することができます。
- データ移行
- セットアップとコピーのコンフィギュレーション
- 統合
データ エンティティ
データ エンティティは重要なデータの概念および機能を表すテーブル スキーマの抽象化およびカプセル化の概念を提供します。 Microsoft Dynamics AX 2012 では、顧客テーブルおよび仕入先テーブルなどのほとんどのテーブルが正規化されてなく、複数のテーブルに分割されていました。 これはデータベース設計の観点からは有益でしたが、実装者や ISV が物理スキーマを十分に理解することなく使用することは困難でした。 データ エンティティは、ビジネス概念を使用して容易に理解できる抽象化のレイヤーとして使用されるデータ管理の一部として導入されました。 以前のバージョンでは、Microsoft Excel アドイン、AIF、および DIXF など、データを管理する複数の方法がありました。 データ エンティティの概念は、これらの異なる概念を 1 つにまとめたものです。 データ エンティティの作成後、Excel アドイン、インポート/エクスポート、または統合のためにそれらを再利用できるようになります。 次のテーブルは、コア データ管理シナリオを示しています。
| データ移行 |
|
| セットアップとコピーのコンフィギュレーション |
|
| 統合 |
|
データ移行
データ管理フレームワークを使用することで、レガシまたは外部システムからの参照、マスター、およびドキュメント データを簡単に移行できます。 このフレームワークは、次の機能を使用してデータをすばやく移行するのに役立ちます。
- 移行する必要があるエンティティのみを選択することができます。
- インポート中にエラーが発生した場合は、選択したレコードをスキップでき、適切なデータのみを使用し、不正なデータを修正して後でインポートし続行できます。 部分的に継続し、エラーを使用して不正なデータをすばやく見つけることができます。
- Excel または XML を介することなく、データ エンティティを直接 1 つのシステムから別のシステムに移動することができます。
- バッチを使用してデータのインポートを簡単にスケジュールすることができ、実行が必要なときに柔軟性を提供します。 たとえば、システムでいつでも顧客グループ、顧客、仕入先、およびその他のデータ エンティティを移行できます。
セットアップとコピーのコンフィギュレーション
データ管理フレームワークを使用すると、会社間または環境間で構成をコピーし、Microsoft Dynamics Lifecycle Services (LCS) を使用してプロセスまたはモジュールを構成することができます。
コンフィギュレーションのコピーは、入力が必要なデータの構造やデータの依存関係、または実装にデータを追加する順序をチームが深く理解していなくても、新しい実装の開始を容易にするためのものです。
データ管理フレームワークでは、次のことが可能です。
- 2 つの類似したシステム間でのデータの移動
- エンティティと与えられた業務プロセスまたはモジュールのエンティティ間の依存関係を検出
- データ テンプレートおよびデータセットの再利用可能なライブラリの管理
- 差分データ エンティティを作成するには、データ パッケージを使用します。 データ エンティティは、パッケージ内で順序付けすることができます。 データ パッケージは、インポートまたはエクスポート中に識別しやすい名前を付けることができます。 データ パッケージを作成するときは、グリッドに、またはビジュアル マッピング ツールを使用して、ステージング テーブルにマップすることができます。 また、列を手動でドラッグ アンド ドロップすることができます。
- データを比較して有効であることを確認できるように、インポート中にデータを表示します。
データ エンティティの作業
次のセクションでは、データ エンティティを使用するデータ管理のさまざまな機能の簡単なスナップショットを提供します。 目標は、データ移行中に利用可能なツールを最適に活用する方法を戦略化し、効果的に決定するのを支援することです。 データ移行時に各領域を効果的に使用する方法についてのヒントとコツも検索します。 各領域の使用可能なデータ エンティティの一覧は、データの依存関係を示す、推奨されるデータの順序で見つけることもできます。 Microsoft は、Lifecycle Services (LCS) で確認できるデータ パッケージを初期ガイドとして提供します。 このドキュメントの情報は、独自のパッケージを作成するためのガイドとして使用できます。 各データ エンティティの説明には、オブジェクトに含まれるものとデータ移行中に必要なものが表示されます。
優先順位
データ エンティティを扱うときに考慮する必要がある優先順位には 2 つのタイプがあります。
- データ パッケージ内のシーケンス データ エンティティ
- データ パッケージ インポートの順序の優先順位
データ パッケージ内のシーケンス データ エンティティ
ユーザーがデータ プロジェクトにデータ エンティティを追加すると、既定では、シーケンスはエンティティが読み込まれる順序に設定されます。 プロジェクトに追加された最初のエンティティは、ロードする最初のエンティティとして設定され、次に追加されるエンティティは 2 番目に、次のエンティティは 3 番目に、などとなります。
たとえば、ユーザーがこの注文に 2 つのエンティティ売上税コードおよび売上税グループを追加した場合、売上税コードに 1. 1.1 のエンティティ順序に割り当てられ、さらに売上税グループに 1.1.2 のエンティティ順序が割り当てられます。 シーケンス レベルは、第 1 レベルが終了するまで第 2 エンティティがインポート プロセスを開始しないことを示します。
シーケンスを表示または編集するには、データ プロジェクトのアクション ウィンドウにある エンティティのシーケンス ボタンをクリックします。

定義グループ エンティティの順序で、実行単位と順序を表示できます。 一覧からデータ エンティティを選択して、異なる実行単位またはシーケンスを等しく設定してから、選択対象の更新 をクリックすることにより、シーケンスを変更することができます。 選択対象の更新をクリックした後、エンティティはエンティティの一覧で上または下に移動します。
例
次のスクリーンショットは、消費税 CodeGroups データ パッケージに設定されているエンティティの順序を示しています。
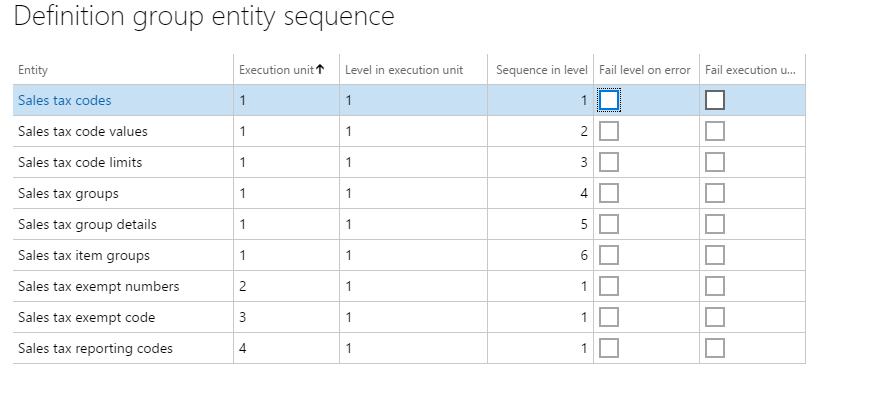
売上税コードとグループを正常にインポートするためには、最初に売上税コードおよび詳細を読み込んでから、売上税グループをインポートする必要があります。 売上税コードとグループがすべて実行単位 = 1 になっていますが、シーケンスはインポートされる順序になっています。 読み込まれる他のデータ エンティティに依存していないその他の関連する売上税エンティティは、パッケージに含まれます。 たとえば、消費税非課税番号が独自の実行単位 = 2 に設定されます。 このデータ エンティティは、直前に読み込んでいる他のエンティティに依存しないため、すぐに読み込みを開始します。
シーケンス データ パッケージのインポート
正常にデータを読み込むには、モジュール内およびモジュール間に存在する依存関係のため、データ パッケージをインポートするための適切な順序を設定することが重要です。 LCS 内のデータ パッケージ用に作成された番号の形式は、次のとおりです。
- 最初のセグメント: モジュール
- 2 番目のセグメント: データ型 (設定、マスター、トランザクション)
- 第 3 セグメント: シーケンス番号
次のテーブルは、既定の番号付け形式の詳細を示しています。
モジュール番号
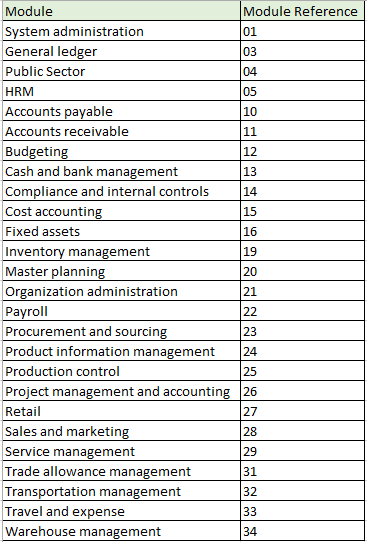
データ型の数

連番
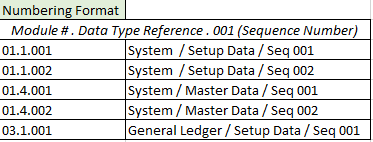
データ パッケージは、シーケンス番号に続いて、モジュールの省略形、記述の順に続きます。 次の例は、総勘定元帳 データ パッケージを示しています。
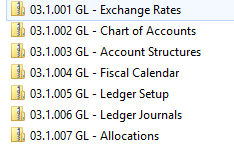
マッピング
データ エンティティを使用するときは、ソースへのエンティティのマッピングは自動です。 必要な場合は、フィールドの自動マッピングを上書きできます。
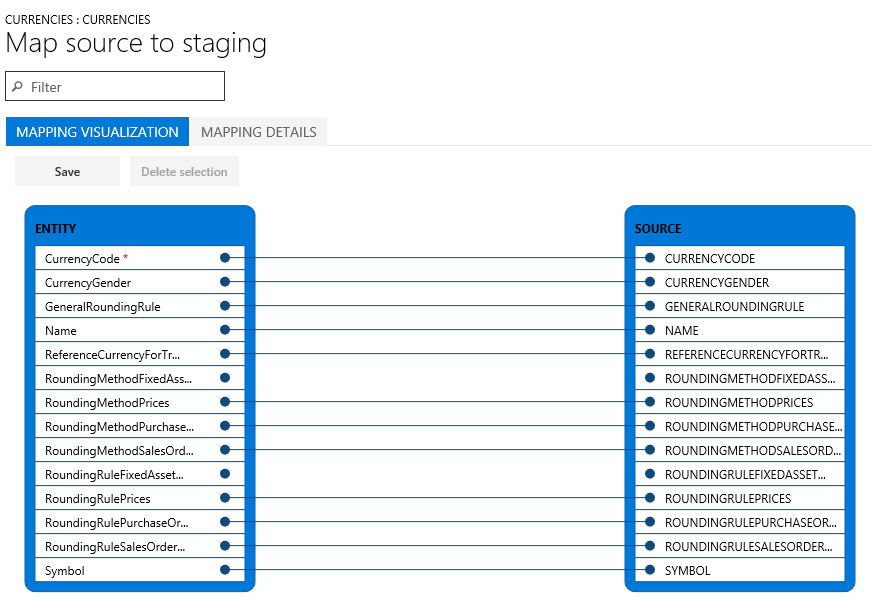
マッピングの表示
エンティティのマッピング方法を表示するには、プロジェクト内のエンティティのタイルを見つけて、マップを表示 をクリックします。
マッピング視覚化ビュー (既定値) とマッピング詳細ビューを提供します。 赤いアスタリスク (*) によりエンティティの必須フィールドを識別します。 エンティティを使用して作業するために、これらのフィールドをマップする必要があります。 エンティティを使用して作業する際、必要に応じて他のフィールドのマップ解除をすることができます。
- フィールドのマップ解除をするには、いずれかの列 (エンティティまたはソース) でフィールドを強調表示し、選択項目を削除 をクリックしてから 保存 をクリックします。 保存したら、フォームを閉じてプロジェクトに戻ります。
ソースからステージングへのフィールド マッピングも、同じプロセスを使用してインポートした後で編集できます。
マップを再生成
エンティティ (追加済みフィールド) を拡張する場合、または自動マッピングが不適切であると表示された場合は、エンティティのマッピングをマッピング フォームで再生成できます。
これを行うには、ソース マッピングの生成 をクリックします。
「マッピングを最初から生成しますか?」と尋ねるメッセージが表示されます。
マップを再生成するためには、はいをクリックします。
データの生成
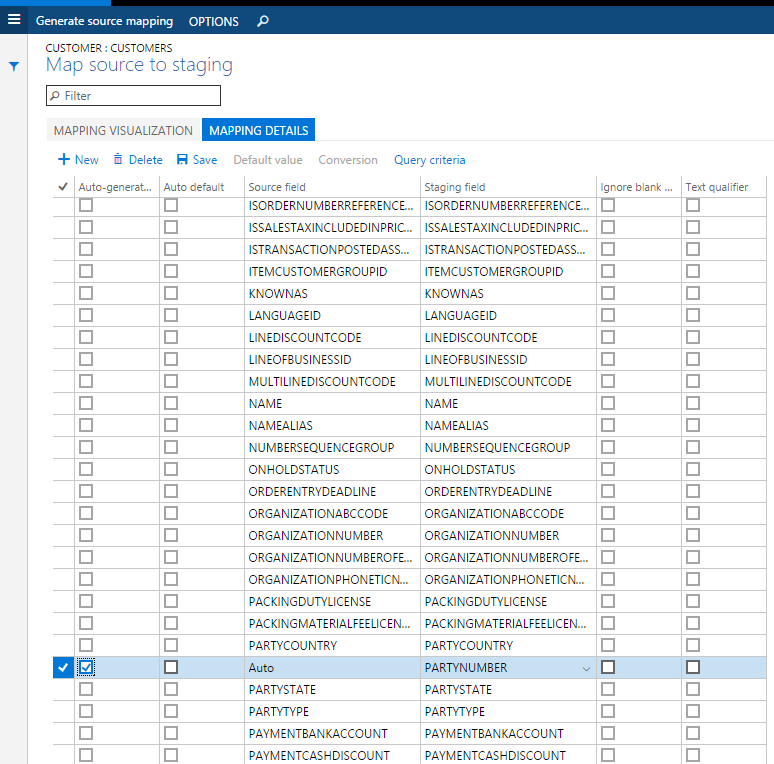
エンティティに、インポート時にデータを生成するフィールドがある場合は、ソース ファイルにデータを提供する代わりに、エンティティのマッピングの詳細で自動生成された機能を使用できます。 たとえば、顧客および顧客の住所情報をインポートしても、住所情報がグローバル アドレス帳エンティティで以前にインポートされなかった場合、インポート上の関係者番号を自動生成するエンティティを持つことができ、GAB 情報が作成されます。 この機能にアクセスするには、エンティティのマップを表示し、マッピング詳細 タブをクリックします。自動生成するフィールドを選択します。 これにより、ソース フィールドが自動に変更されます。
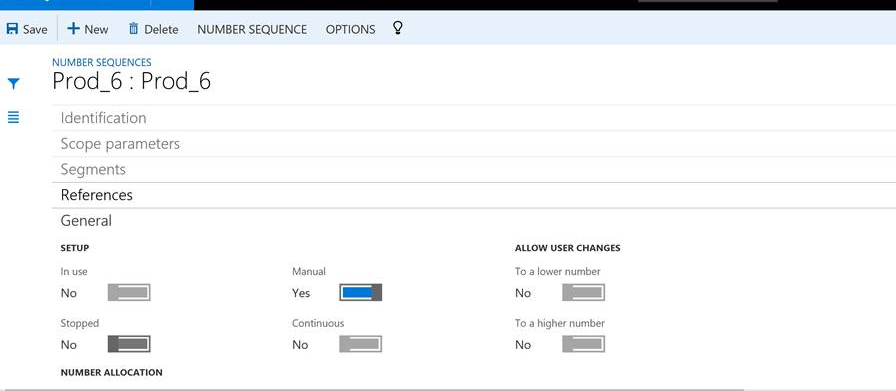
自動的に生成される番号シーケンスをオフにする
多くのエンティティは、番号順序の設定に基づく ID の自動生成をサポートしています。 たとえば、製品を作成するときに、製品番号は自動で生成され、フォームで値を手動で編集することはできません。

特定のエンティティに対する番号順序の手動割り当てを有効にできます。
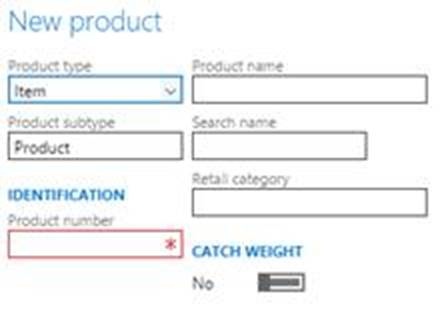
手動割り当てを有効にした後、代わりに手動で割り当てられた番号を指定できます。
輸出
エキスポートは、データ エンティティを使用してシステムからデータを取得するプロセスです。 エクスポート プロセスは、プロジェクトを通じて行われます。 エクスポートするとき、エクスポート プロジェクトの定義方法に関して、多くの柔軟性があります。 エクスポートするデータ エンティティ、エンティティ数、使用するファイル形式 (エクスポートのために選択できる 14 の形式があります)、を選択して、各エンティティにフィルターを適用してエクスポート対象を制限することができます。 データ エンティティがプロジェクトを取り出した後、前述されたシーケンスとマッピングは、各エクスポート プロジェクトに対して実行できます。
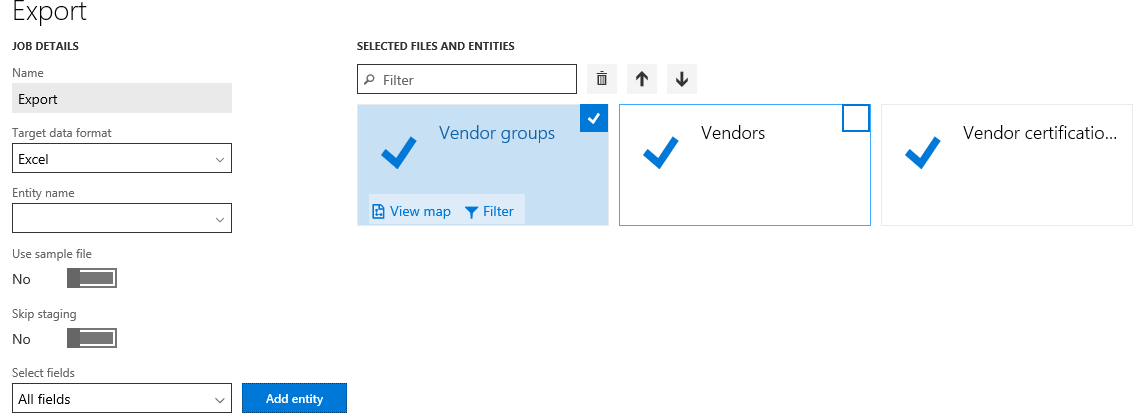
プロジェクトが作成され保存された後は、プロジェクトをエクスポートし、ジョブを作成することができます。 エクスポート プロセス中に、ジョブのステータスとレコード数をグラフィカルに表示できます。 このビューには複数のレコードが表示されるので、実際のファイルをダウンロードする前に各レコードの状態を確認できます。
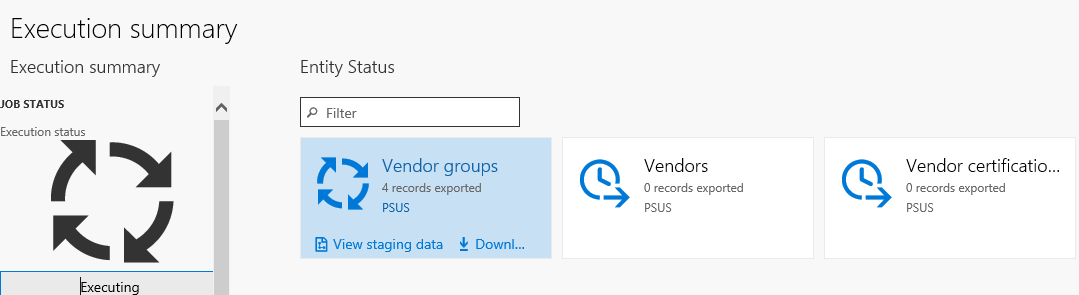
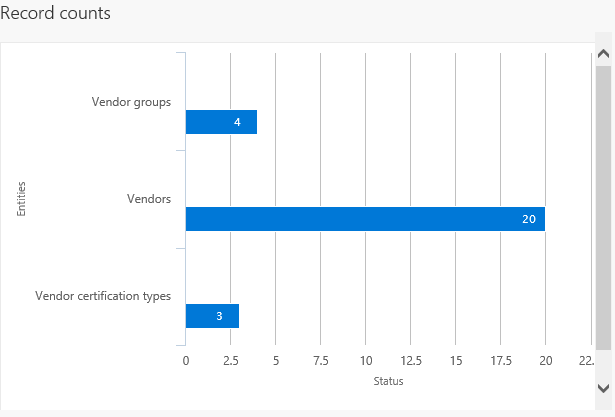
ジョブが完了した後、ファイルのダウンロード方法を選択できます。各データ エンティティは別々のファイルにすることも、ファイルをパッケージにまとめることもできます。 ジョブに複数のデータ エンティティがある場合は、パッケージ オプションを選択すると、アップロードのプロセス速度が上がります。 パッケージは zip ファイルであり、各エンティティのデータ ファイルとパッケージ ヘッダーとマニフェストを含んでいます。 これらの追加のドキュメントは、データ ファイルを正しいデータ エンティティに追加してインポート プロセスを順序付けるために、インポート時に使用されます。
インポート元
インポートは、データ エンティティを使用してシステムにデータを引き出すプロセスです。 インポートプロセスは、データ管理 ワークスペースの インポート タイルで行います。 データは、個々のエンティティまたは正しい順序で配列された論理的に関連するエンティティのグループのいずれかにインポートできます。 ファイル形式はインポートのタイプによって異なります。 エンティティについては、コンマ区切り、タブ区切り、またはテキストの Excel ファイルである可能性があります。 データ パッケージで、それは .zip ファイルです。 どちらの場合も、ファイルは上記のエクスポート プロセスを使用してエクスポートされます。
データ パッケージのインポート
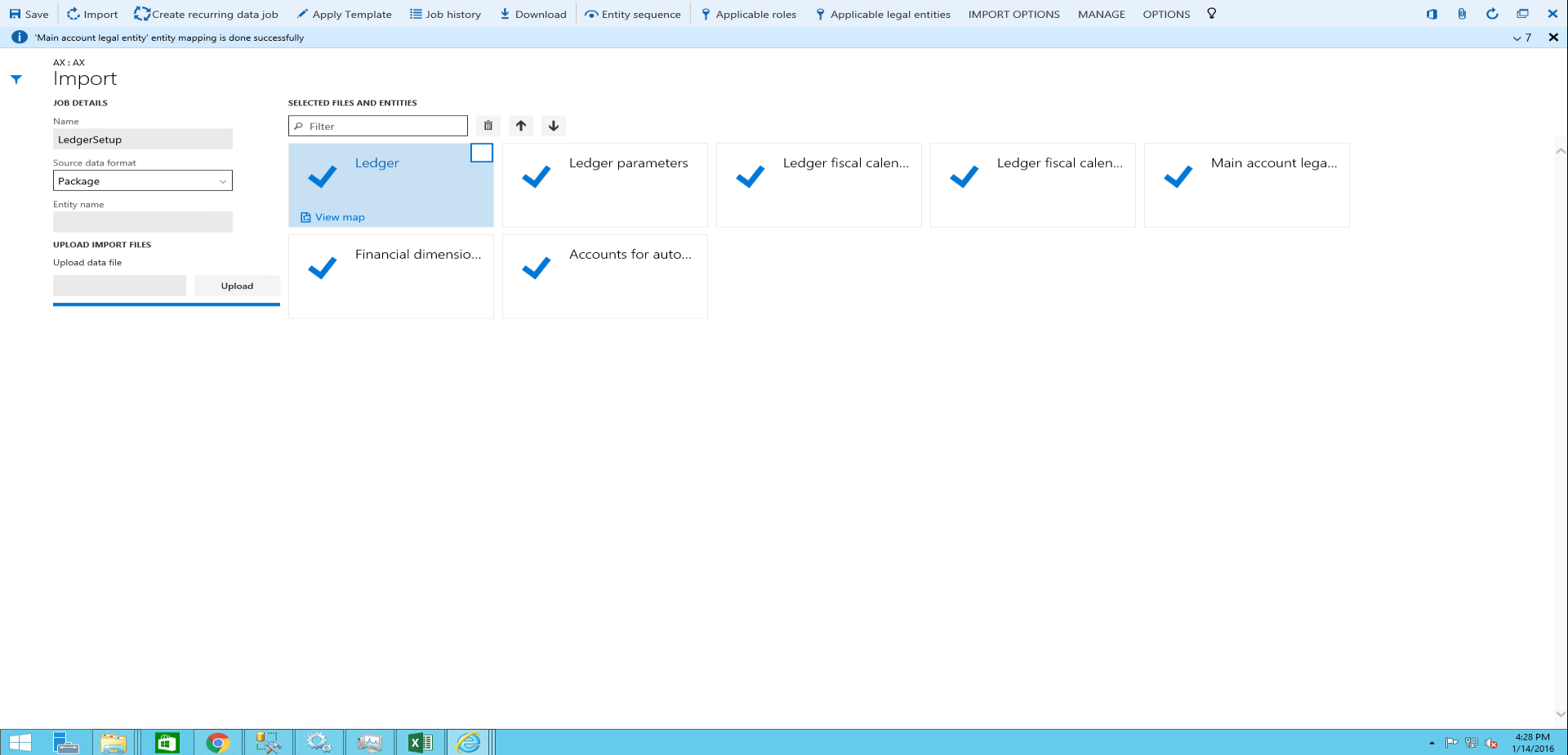
十分な権限 (通常、これは管理者ロール) のあるログインを使用して環境にログインします。
ダッシュボードで、データ管理ワークスペースをクリックします。
インポート タイルをクリックします。
次のページで、次の操作を行います。
名前を入力します。
ソース データ形式フィールドで、パッケージを選択します。
アップロード ボタンをクリックし、インポートするデータの場所から適切なパッケージ ファイルを選択します。 これにより、パッケージからすべてのファイルがインポートされます。
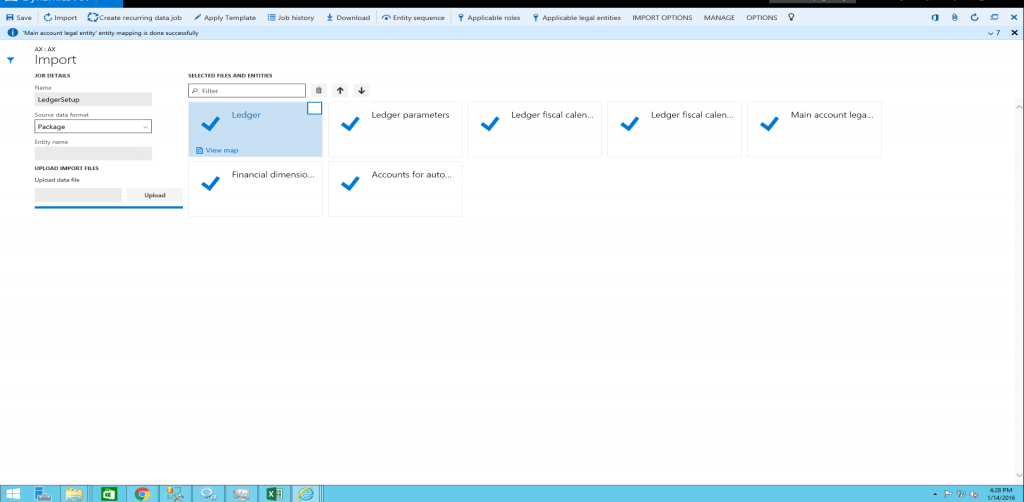
保存をクリックし、インポートをクリックします。
複数のデータ パッケージのインポート
複数のデータ パッケージをインポートするには、次のいずれかの方法を使用します。
各パッケージの新しいジョブを作成し、上記の手順 4(a) から 4(d) をパッケージごとに繰り返します。
1 つのジョブを作成して、複数のパッケージをシーケンス内にインポートします。 インポートする必要があるすべてのパッケージで上記の手順 4(a) ~ 4(c) を繰り返します。 パッケージを選択した後に、ステップ 4 (d) を実行し選択したデータ パッケージから単一のジョブでデータをインポートします。
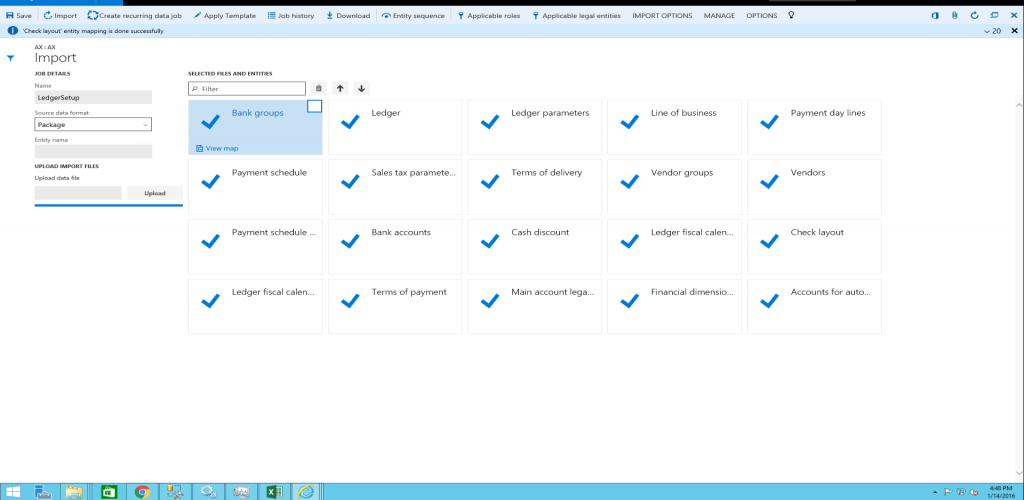
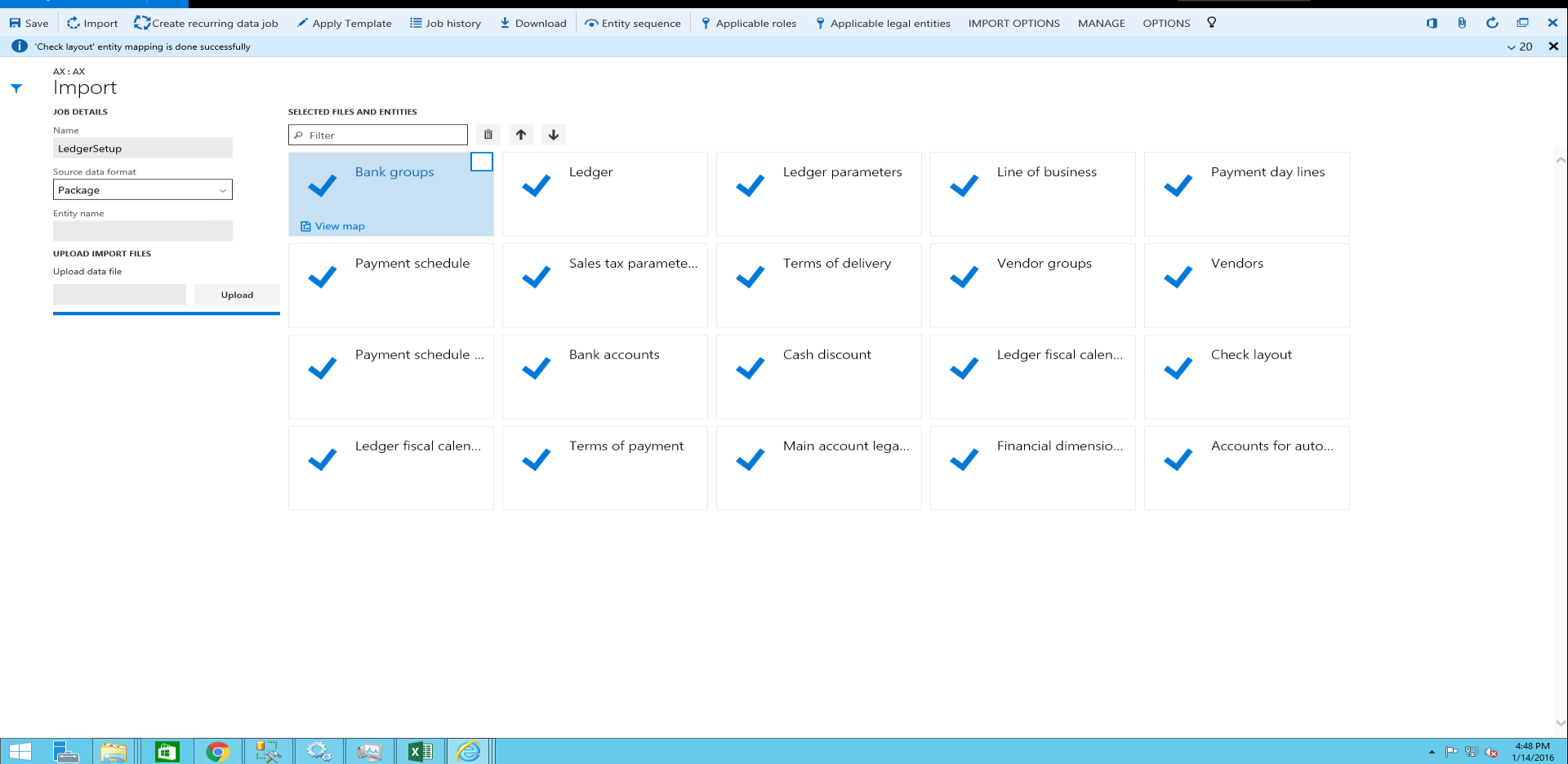
インポートをクリックした後、ステージング テーブルを使用してデータがインポートされます。 インポートの進行状況は、画面の右上にある 更新 ボタンを使用して追跡できます。
データ パッケージ処理のトラブルシューティング
このセクションでは、データ パッケージ処理のさまざまな段階に関するトラブルシューティング情報を提供します。
- スケジュールされたジョブのステータスおよびエラーの詳細は、データ管理 フォームの ジョブの履歴 セクションにあります。
- データ エンティティの前の実行のステータスおよびエラーの詳細は、データ プロジェクトを選択して ジョブの履歴 をクリックすることで表示できます。 実行履歴フォームで、ジョブを選択してステージング データの表示および実行ログの表示をクリックします。 上記の実行には、バッチ ジョブとして、または手動で実行された、データのプロジェクトの実行が含まれます。
プロセス トラブルシューティングをエキスポート
- エクスポート プロセス中にエラーが発生した場合、実行ログの表示をクリックし、ログのテキスト、ステージング ログ詳細、詳細情報の情報ログをを確認します。
- エクスポート プロセス中にエラーが発生し、ステージングをスキップするように指示ノートが表示された場合、ステージングをスキップ オプションをオフにし、エンティティを追加します。 複数のデータ エンティティをエクスポートする場合は、個々のデータ エンティティに対してステージングのスキップボタンを使用できます。
プロセス トラブルシューティングのインポート
データ エンティティ ファイルをアップロードするとき、次の操作を行います。
- インポート処理中にアップロードをクリックした後に、データ エンティティが選択したファイルとエンティティ内で表示されていない場合は、数分待ってから、OLEDB ドライバーがまだインストールされているかどうかを確認します。 それ以外の場合は、OLEDB ドライバーを再インストールします。 ドライバーは Microsoft Access データベース エンジン 2010 再頒布可能パッケージ – AccessDatabaseEngine_x64.exe です。
- インポート処理中にアップロードをクリックした後に、データ エンティティが選択されているファイルとエンティティ内で警告と一緒に表示されている場合、マップの表示をクリックし、個々のデータ エンティティのマッピングを確認し、修正します。 マッピングを更新し、各データ エンティティの 保存 をクリックします。
データ エンティティのインポート中:
- インポートをクリックし、データ エンティティ (データ エンティティ タイルの赤い X アイコンまたは黄色の三角アイコンで表示されている) が失敗した場合、実行の概要ページにある各タイルのステージング データの表示をクリックし、エラーを確認します。 移動ステータス = エラーのレコードを並べ替えてスクロールし、メッセージ セクションにエラーを表示します。 ステージング テーブルをダウンロードします。 編集、すべて検証、およびデータをターゲットにコピーをクリックしてステージングで直接レコード (またはすべてのレコード) を修正するか、またはインポート ファイル (ステージング ファイルではない) を修正し、データを再インポートします。
- インポートをクリックし、データ エンティティ (データ エンティティ タイルの赤い x アイコンまたは黄色の三角アイコンで表示されている) が失敗し、ステージング データの表示にデータがない場合は、実行の概要ページに戻ります。 実行ログの表示に移動し、データ エンティティを選択し、詳細についてはログ テキスト、ステージング ログの詳細、および情報ログを確認してください。 ステージング ログ詳細が表示されエラー列 (フィールド) の詳細およびログ説明がエラーの詳細を説明します。
- データ エンティティが失敗した場合、インポート ファイルを確認し、「これは 255 文字以上をサポートするための列にするダミー セルとして Excel に挿入される文字列です」というテキストが表示されている追加の明細行がファイルにあるかどうかを確認できます。 既定では、Excel 出力先コンポーネントは 255 文字以上をサポートしません。 既定の Excel タイプは、最初の数行に基づいて設定されます。 この行は、データのエクスポート中に追加されます。 この明細行が存在する場合は、それを削除し、データ エンティティを再パッケージし、インポートを試行します。
データ管理でフライトされる機能とフライトされた機能の有効化
フライト経由で次の機能が有効になります。 フライトは、機能を既定でオンまたはオフにできる概念です。
| フライト名 | 説明 |
|---|---|
| DMFEnableAllCompanyExport | 同一のエクスポート ジョブ内のすべての会社からのBYODエクスポートを有効にします。(BYODファイルのみが対象となります) この既定値はオフです。 この機能はデータ管理フレームワーク パラメーターのパラメーターを使用してオンにできるため、プラットフォーム アップデート 27 以降は、このフライトは不要になりました。 |
| DMFExportToPackageForceSync | データ パッケージ API エクスポートの同期実行を実行できます。 既定では、非同期式です。 |
| EntityNamesInPascalCaseInXMLFiles | エンティティの XML ファイルでエンティティの名前が Pascal Case である場合の動作が有効になります。 既定では、名前は大文字です。 |
| DMFByodMissingDelete | 特定の条件下で、変更の追跡を使用して特定の削除操作が BYOD に同期されなかった場合の以前の動作が有効になります。 |
| DMFDisableExportFieldsMappingCache | ターゲット フィールド マッピングを作成するときに、ロジックのキャッシュを無効にします。 |
| EnableAttachmentForPackageApi | パッケージ API で添付ファイル機能を有効にします。 |
| FailErrorOnBatchForExport | エクスポート ジョブの実行単位またはレベルでエラー時の失敗が有効になります。 |
| IgnorePreventUploadWhenZeroRecord | "レコード数が 0 の場合にアップロードしない" 機能を無効にします。 |
| DMFInsertStagingLogToContainer | この既定値は ON です。 これにより、パフォーマンスが向上し、ステージング テーブル内のエラー ログの機能の問題が修正されます。 |
| ExportWhileDataEntityListIsBeingRefreshed | 有効な場合、エンティティの更新の実行中にジョブがスケジューリングされると、マッピングで追加の検証が行われます。 この既定値はオフです。 |
| DMFDisableXSLTTransformationForCompositeEntity | これは、複合エンティティで変換の適用を無効にできます。 |
| DMFDisableInputFileCheckInPackageImport | すべてのエンティティ ファイルがデータ パッケージから欠落している場合にエラー メッセージが表示されるように、追加の検証が行われます。 これは既定の動作です。 必要な場合、このフライトによりこれを OFF にできます。 |
| FillEmptyXMLFileWhenExportingCompositeEntity | プラットフォーム更新プログラム 15 よりも前は、エクスポートするレコードを持っていない複合エンティティをエクスポートするとき、生成された XML ファイルにはスキーマ要素は含まれませんでした。 この動作は、このフライトを有効にすることで空のスキーマの出力に変更できます。 既定では、この動作は引き続き空のスキーマを出力します。 |
| EnableNewNamingForPackageAPIExport | エクスポート シナリオに対して ExportToPackage が使用されている場合、実行 ID に一意の名前が使用されるように修正が行われました。 ExportToPackage が連続してすばやく呼び出された場合、重複する実行 ID が作成されていました。 互換性を維持するために、この動作は既定でオフになっています。 このフライトをオンにすると、実行 ID の新しい名前付け規則によって一意の名前が保証される新しい動作が有効になります。 |
| DMFDisableDoubleByteCharacterExport | コード ページ 932 設定を使用するようにフォーマットがコンフィギュレーションされているときにデータをエクスポートできるように、修正が行われました。 2 バイト エクスポートに関連して問題が発生した場合、該当する場合は、このフライトを無効にしてブロック解除することによって、この修正を止めることができます。 |
| DisablePendingRecordFromJobStatus | インポート ジョブの最終ステータスの評価時に保留中のレコードを確実に考慮するように、修正が行われました。 実装がステータス評価ロジックに依存し、この変更が実装の重大な変更として見なされる場合、この新しいロジックをこのフライトを使用して無効にすることができます。 |
| DMFDisableEnumFieldDefaultValueMapping | データ パッケージの生成時に、列挙フィールドに対する高度なマッピングで設定されている既定値がデータ パッケージ マニフェスト ファイルに正常に保存されるように、修正を行いました。 このような高度なマッピングが使用されている場合、これによりデータ パッケージを統合のテンプレートとして使用できます。 この修正はこのフライトによって保護されており、以前の動作がまだ必要な場合 (データ パッケージ マニフェストで常に値を 0 に設定) は無効にできます。 |
| DMFXsltEnableScript | このフライトは、Platform update 34 および非運用環境にのみ適用されます。 XSLT でのスクリプト作成を防止するために、Platform update 34 で修正が行われました。 ただし、これにより、スクリプトに依存する機能の一部が無効になりました。 その結果、このフライトでは、予防措置としてすべての運用環境で Microsoft によって有効にされています。 非運用環境では、スクリプトに関連する XSLT 障害が発生した場合に、お客様がこれを追加する必要があります。 Platform update 35 以降、Platform update 34 の変更を元に戻すコード変更が行われたため、このフライトは Platform update 35 以降適用されません。 このフライトを Platform update 34 で有効にした場合でも、Platform update 35 にアップグレードしても、Platform update 34 からこのフライトがオンになっていることで悪影響が生じることはありません。 |
| DMFExecuteSSISInProc | このフライトは、既定でオフです。 これは、SQL Server Integration Services (SSIS) をプロセス外で実行して、DIXF ジョブの実行時に SSIS のメモリ使用率を最適化するために行われたコード修正に関連しています。 ただし、この変更により、DIXF データ プロジェクト名にアポストロフィ (') が含まれている場合、ジョブがエラーで失敗するというシナリオで回帰が発生しました。 この問題が発生した場合は、データ プロジェクト名の (') を削除するとエラーを解決できます。 ただし、何らかの理由で名前を変更できない場合は、このフライトを有効にして、このエラーを解決できます。 このフライトを有効にすると、以前と同様に SSIS が進行中で実行され、DIXF ジョブの実行時にメモリ消費が増加する可能性があります。 |
次の手順では、ティア 1 環境でフライトを有効にします。 次の SQL コマンドを実行します。
運用環境またはサンドボックス環境でフライトを有効にするには、サポート案件を Microsoft に記録する必要があります。
この SQL ステートメントを実行した後、各 AOS 上の web.config ファイル内に、以下が設定されていることを確認します。 add key="DataAccess.FlightingServiceCatalogID" value="12719367"
上記の変更を行った後、すべての AOS 上で IISReset を実行します。
INSERT INTO SYSFLIGHTING ([FLIGHTNAME] ,[ENABLED] ,[FLIGHTSERVICEID] ,[PARTITION] ,[RECID] ,[RECVERSION] ) VALUES ('name', 1, 12719367, PARTITION, RECID, 1)パーティション - 環境のパーティション ID。レコードを照会 (選択) することで取得できます。 すべてのレコードには、ここでコピーおよび使用する必要があるパーティション ID があります。
RecID - パーティションと同じ ID。 ただし、複数のフライトが有効な場合、これは一意の値を持つようにするためパーティション ID + "n" にすることができます。
RecVersion = 1
追加リソース
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示