データ インポート/エクスポート ジョブの概要
データ インポート/エクスポート ジョブを作成して管理するには、データ管理ワークスペースを使用します。 既定では、データ インポート/エクスポート プロセスにより、ターゲットのデータベースで各エンティティにステージング テーブルが作成されます。 ステージング テーブルにより、移動させる前にデータを確認、クリーンアップ、または変換できます。
メモ
この記事の内容は、データ エンティティ の内容を理解していることが前提です。
データ インポート/エクスポート プロセス
データをインポートまたはエクスポートする手順を以下に示します。
次のタスクを完了するインポートまたはエクスポート ジョブを作成します。
- プロジェクト カテゴリを定義します。
- インポートまたはエクスポートするエンティティを識別します。
- ジョブのデータ形式を設定します。
- 論理グループ内で道理にかなった順序で処理されるように、エンティティに順序付けをします。
- ステージング テーブルを使用するかどうかを決定します。
ソース データとターゲット データが正しくマップされていることを検証します。
インポート/エクスポート ジョブのセキュリティを確認します。
インポート/エクスポート ジョブを実行します。
ジョブの履歴を確認して、期待どおりにジョブが実行されたことを検証します。
ステージング テーブルをクリーンアップします。
この記事の残りのセクションでは、プロセスの各ステップの詳細について説明します。
ノート
最新の進行状況を表示するためデータのインポート/エクスポート フォームを更新するには、フォームの更新アイコンを使用します。 バッチで実行されていない任意のインポート/エクスポート ジョブが中断されますので、ブラウザー レベルの更新はお勧めできません。
インポートまたはエクスポート ジョブを作成する
データ インポート/エクスポート ジョブは、1 回または複数回実行できます。
プロジェクト カテゴリを定義する
インポート/エクスポート ジョブにふさわしいプロジェクト カテゴリを選択する時間を取るようお勧めします。 プロジェクト カテゴリは、関連するジョブを管理するのに役立ちます。
インポートまたはエクスポートするエンティティを識別する
インポート/エクスポート ジョブに特定のエンティティを追加したり、適用するテンプレートを選択することができます。 テンプレートは、ジョブにエンティティの一覧を入力します。 テンプレートの適用 オプションは、ジョブに名前を付けて保存した後に使用できます。
ジョブのデータ形式を設定する
エンティティを選択する時に、エクスポートまたはインポートするデータの形式を選択する必要があります。 データ ソース設定 タイルを使用して、形式を定義します。 ソース データ形式はタイプ、ファイル形式、行区切り、列区切りの組み合わせです。 他にもありますが、これらの属性は理解すべき重要な属性です。 次の表に、有効な組み合わせを示します。
| ファイル形式 | 行/列区切り | XML スタイル |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | XML-要素 XML-属性 |
| 区切り、固定幅 | コンマ、セミコロン、タブ、縦棒、コロン | -NA- |
ノート
ファイル形式 のオプションが 区切り に設定されている場合は、行区切り、列区切り、テキスト修飾子 に正しい値を選択することが重要です。 区切り記号や修飾子として使用されている文字がデータに含まれていないことを確認してください。これらの文字が含まれていると、インポートおよびエクスポート時にエラーが発生する可能性があります。
メモ
XML ベースのファイル形式の場合は、必ず有効な文字のみを使用してください。 有効な文字の詳細については、XML 1.0 の有効な文字 を参照してください。 XML 1.0 では、タブ、キャリッジ リターン、ライン フィード以外の制御文字は使用できません。 無効な文字の例としては、角かっこ、中かっこ、バックスラッシュがあります。
データをインポートまたはエクスポートするには、特定のコードページの代わりに Unicode を使用します。 これにより、最も一貫した結果を得ることができます。また、Unicode 文字も含まれるため、データ管理ジョブの失敗がなくなります。 Unicode を使用するシステム定義のソース データ形式ではすべて、ソース名に Unicode が使用されます。 Unicode 形式は、地域の設定 タブの コード ページ として Unicode エンコード ANSI コード ページを選択することで適用されます。Unicodeの次のいずれかのコード ページを選択します。
| コード ページ | 表示名 |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
コード ページの詳細については、コード ページ識別子 を参照してください。
エンティティに順序付けをする
データ テンプレート、またはインポート/エクスポート ジョブで、エンティティに順序付けをすることができます。 1 つ以上のデータ エンティティが含まれるジョブを実行する場合、データ エンティティが正しく順序付けされていることを確認する必要があります。 主にエンティティ間の機能依存関係に合うように、エンティティに順序付けします。 エンティティに機能依存関係がない場合は、並行インポートまたはエクスポートにスケジューリングできます。
実行単位、レベル、および順序
実行単位、実行単位のレベル、およびエンティティの順序はデータのエクスポートやインポートの順序をコントロールするのに役立ちます。
- 各実行ユニットでは、エンティティが並列処理されます。
- 各実行単位では、エンティティは同じレベルを持つ場合に並列処理されます。
- 各レベルでは、そのレベルの順序番号に従ってエンティティが処理されます。
- 1 つのレベルが処理された後、次のレベルが処理されます。
順序付け直し
以下のような状況で、エンティティの順序付け直しを行なう場合があります。
- すべての変更に 1 つのデータジョブだけを使用する場合、完全なジョブの実行時間を最適化するために、順序付け直しのオプションを使用できます。 これらの場合は、モジュールを表すのに実行単位、モジュールの機能領域を表すのにレベル、エンティティを表すのに順序を使用できます。 この方法を使用することで、複数のモジュールで並行作業できますが、1 つのモジュール内で順番に作業することもできます。 並行工程が確実に成功するように、すべての依存関係を考慮する必要があります。
- 複数のデータ ジョブを使用する場合は (たとえば、各モジュールに 1 つのジョブ)、優先順位を使用して、最適な実行のため、レベルおよびエンティティの順序に影響を与えることができます。
- 依存関係がまったくない場合は、最大の最適化のため、異なる実行単位でエンティティに順序付けをすることができます。
順序付け直し メニューは、複数のエンティティが選択されている場合に使用可能です。 実行単位、レベル、または順序オプションに基づいて、順序付け直しができます。 選択されたエンティティの順序付け直しの増分を設定することができます。 各エンティティに選択されている単位やレベルや順序番号が、指定された増分で更新されます。
並べ替え
並べ替え オプションを使用して、エンティティ リストを連番で表示できます。
切り詰め
プロジェクトのインポートのため、インポートする前にエンティティ内の切り詰めるレコードを選択できます。 切り詰めはテーブルのクリーンなセットにレコードをインポートする必要がある場合に役立ちます。 既定では、この設定は有効ではありません。
ソース データとターゲット データが正しくマップされていることを検証する
マッピングは、インポート、エクスポート ジョブの両方に適用される機能です。
- インポート ジョブのコンテキストで、マッピングはソース ファイルのどの列がステージング テーブルの列になるかを説明します。 そのため、システムはソース ファイルのどの列のデータをステージング テーブルのどの列にコピーする必要があるかを決定できます。
- エクスポート ジョブのコンテキストで、マッピングはステージング テーブル (つまりソース) のどの列が、ターゲット ファイルの列になるかを説明します。
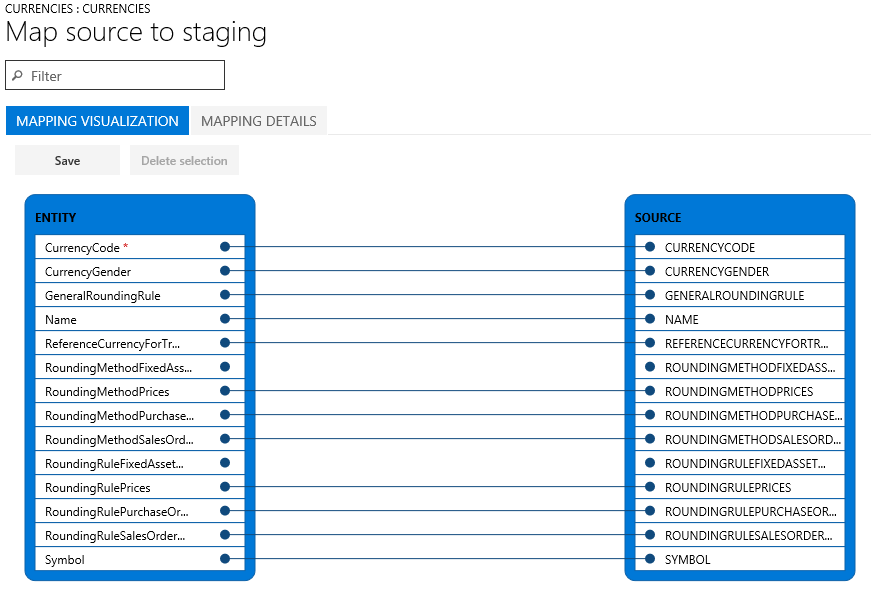
ステージング テーブルとファイルで列の名前が一致すると、システムは自動的にその名前に基づいてマッピングを確立します。 ただし、名前が異なる場合、列は自動的にマップされません。 こうした場合は、データ ジョブのエンティティで マップの表示 オプションを選択して、マッピングを完了する必要があります。
既定のビューである マッピングの視覚化、および マッピング詳細 という 2 つのマッピング ビューがあります。 赤いアスタリスク (*) はエンティティの必須フィールドを示します。 エンティティを使用して作業する前に、これらのフィールドをマップする必要があります。 エンティティを使用して作業する際に、必要に応じて他のフィールドのマップ解除をすることができます。 フィールドのマップ解除をするには、エンティティ 列、または ソース 列いずれかのフィールドを選択し、その後 選択の削除 を選択します。 保存 を選択して変更を保存し、ページを閉じてプロジェクトに戻ります。 同じプロセスを使用して、インポート後にソースからステージングへのフィールド マッピングを編集することができます。
ソース マッピングの生成を選択すると、ページ上にマッピングを生成することができます。 生成されたマッピングは、自動マッピングと同様に動作します。 したがって、マップされていないフィールドは、手動でマップする必要があります。
インポート/エクスポート ジョブのセキュリティを確認する
管理者以外のユーザーは特定のデータ ジョブにのみアクセスできるよう、データ管理 ワークスペースへのアクセスを制限することができます。 データ ジョブへのアクセスとは、そのジョブの実行履歴への完全なアクセス、またステージング テーブルへのアクセスを意味します。 そのため、データ ジョブの作成時に、適切なアクセス制御が設定されていることを確認する必要があります。
ロールおよびユーザー別にジョブをセキュリティ保護する
適用可能なロール メニューを使用して、ジョブを 1 つまたは複数のセキュリティ ロールに制限します。 これらのロールのユーザーだけが、そのジョブへのアクセス権を持ちます。
ジョブを特定のユーザーに制限することもできます。 ロールではなくユーザー別にジョブを保護すると、複数のユーザーがロールに割り当てられているかどうかをより細かく制御できます。
法人別にジョブをセキュリティ保護する
データ ジョブは、本質的にグローバルです。 したがって、ある法人内でデータ ジョブが作成され使用されると、そのジョブはシステム内の他の法人で表示されます。 この既定の動作は、いくつかのアプリケーション シナリオでは望ましい場合があります。 たとえば、データ エンティティを使用して請求書をインポートする組織は、組織内のすべての部局の請求書エラーの管理を担当する集中請求処理チームを備える場合があります。 このシナリオでは、集中請求処理チームにすべての法人からの請求書インポート ジョブへのアクセス権があることは有益です。 したがって、法人の視点からこの既定の動作は要件を満たしています。
ただし、組織によっては法人ごとに請求書処理チームが必要な場合があります。 この場合、法人のチームは、自分の法人内の請求書インポート ジョブにのみアクセス権を持つ必要があります。 この要件を満たすには、データ ジョブ内の 適用可能な法人 メニューを使用して、データ ジョブに対して法人ベースのアクセス制御をコンフィギュレーションすることができます。 構成が完了したら、ユーザーは、現在サインイン中の法人で使用できるジョブのみを表示できます。 別の法人からジョブを表示するには、ユーザーはその法人に切り替える必要があります。
ロール、ユーザー、および法人別のセキュリティ保護をジョブに同時に設定することができます。
インポート/エクスポート ジョブを実行する
ジョブを定義した後、 インポート または エクスポート ボタンを選択することにより、そのジョブを 1 回実行できます。 定期的なジョブを設定するには、 定期的なデータ ジョブの作成を選択します。
メモ
インポートまたはエクスポート ジョブは、インポートまたはエクスポートボタンを選択して実行できます。 このアクションは、バッチ ジョブを 1 回だけ実行するようにスケジュールします。 バッチサービスに対する負荷のために帯域幅調整がされている場合、ジョブがすぐに実行されない場合があります。 今すぐインポートまたは今すぐエクスポートを選択して、ジョブを同期的に実行することもできます。 これはすぐにジョブを開始し、帯域幅調整によってバッチが開始されない場合に役立ちます。 ジョブは、後で実行するようにスケジュール設定することもできます。 これを行うには、バッチで実行 オプションを選択します。 バッチ リソースは調整の影響を受けるため、バッチ ジョブはすぐには開始されない可能性があります。 バッチを使用することで、インポートやエクスポートが必要な大量のデータにも対応できるため、このオプションを推奨します。 バッチジョブは特定のバッチグループで実行するようにスケジュールでき、負荷分散の分析視点で、より多くの制御が可能になります。
ジョブが期待どおりに実行されたことを検証する
ジョブの履歴は、インポートおよびエクスポート ジョブ両方のトラブルシューティングと調査に使用できます。 履歴ジョブの実行は、時間範囲別に整理されています。
各ジョブの実行により、次の詳細情報が提供されます。
- 実行の詳細
- 実行ログ
実行の詳細は、ジョブが処理した各データ エンティティの状態を示します。 そのため、次の情報をすばやく見つけることができます。
- 処理されたエンティティ。
- エンティティに関する、正しく処理されたレコード数と失敗した数。
- 各エンティティのステージ レコード。
ステージング データは、エクスポート ジョブ用にファイルにダウンロードするか、インポート/エクスポート ジョブのパッケージとしてダウンロードすることができます。
実行の詳細から、実行ログも開くことができます。
並列インポート
データのインポートを高速化するために、エンティティで並列インポートがサポートされている場合は、ファイルのインポート時に並列処理を有効にすることができます。 エンティティの並列インポートを構成するには、次の手順に従う必要があります。
システム管理 > ワークスペース > データ管理 の順に移動します。
インポート/エクスポート セクションで、フレームワーク パラメータ タイルを選択し、データのインポート/エクスポートフレームワーク パラメータのページを開きます。
エンティティの設定 タブで、エンティティの実行パラメータを構成する を選択し、エンティティ インポートの実行パラメータ ページを開きます。
エンティティの並列インポートを構成するには、次のフィールドを設定します。
- エンティティ フィールドで、エンティティを選択します。 エンティティ フィールドが空の場合、エンティティが並列インポートをサポートしている場合、その空の値が後続のすべてのインポートの既定の設定として使用されます。
- インポートのしきい値レコード数 フィールドに、インポートのしきい値レコード数を入力します。 これにより、スレッドで処理されるレコード数が決まります。 ファイルに 1 万件のレコードが含まれている場合、レコード数 2,500、タスク数 4 ということは、各スレッドが 2,500 件のレコードを処理することを意味します。
- インポート タスク数 フィールドに、インポートするタスクの数を入力します。 カウントは、システム管理 > サーバーの構成 でバッチ処理に割り当てた最大バッチ スレッドを超えることはできません。
注意
並列タスクを追加しすぎると、基盤となるインフラストラクチャのリソース容量が 100% になり、環境のパフォーマンスや他のオペレーションに影響を与えます。 構成された並列インポートタスクに基づいて、環境のリソース容量と消費量を把握し、タスク数を制限することをお勧めします。
ジョブ履歴のクリーンアップ
既定では、90 日よりも古いジョブ履歴エントリおよび関連するステージング テーブル データは自動的に削除されます。 データ管理のジョブ履歴クリーンアップ機能を使用すると、この既定よりも保持期間の短い実行履歴の定期クリーンアップを構成できます。 この機能は、現在は推奨されていない以前のステージング テーブルのクリーンアップ機能を置き換えます。 次のテーブルは、クリーンアップ プロセスによってクリーンアップされます。
すべてのステージング テーブル
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
実行履歴のクリーンアップ 機能は、データ管理 > ジョブ履歴クリーンアップ からアクセスします。
スケジューリング パラメーター
クリーンアップ プロセスをスケジュールする場合は、クリーンアップ基準を定義するために次のパラメーターを指定する必要があります。
履歴を保持する日数 – この設定は、保存する実行履歴の量を制御するために使用されます。 履歴は日数で指定されます。 クリーンアップ ジョブが定期的なバッチ ジョブとしてスケジュールされている場合、この設定は継続的に移動するウィンドウのように機能し、残りのジョブを削除しながら、指定した日数の履歴を常にそのまま残します。 既定は 7 日です。
ジョブを実行する時間数 – クリーンアップする履歴の量によっては、クリーンアップ ジョブの合計実行時間が数分から数時間と異なります。 このパラメータは、ジョブが実行される時間数に設定する必要があります。 クリーン アップ ジョブが指定された時間数に対して実行された後、ジョブは終了し、次回の実行時には定期的スケジュールに基づいてクリーン アップされます。
この設定を使用してジョブを実行する必要がある時間数の上限を設定することで、最大実行時間を指定できます。 クリーンアップ ロジックは、時系列順で一度に 1 つのジョブ実行 ID を処理し、最も古いものが関連する実行履歴のクリーンアップに対して最初に行われます。 残りの実行期間が指定された期間の最後の 10% 以内である場合、クリーンアップ用の新しい実行 ID のピックアップが停止します。 場合によっては、クリーンアップ ジョブが指定された最大時間を超えて続行されます。 この期間は、10% のしきい値に達する前に開始された現在の実行 ID の削除対象レコード数に大きく依存します。 データの整合性を確保するため、開始されたクリーンアップを完了する必要があります。つまり、指定された制限を超えてもクリーンアップは続行されます。 完了すると、新しい実行 ID がピックアップされずに、クリーンアップ ジョブが完了します。 十分な実行時間がないためにクリーンアップされなかった残りの実行履歴は、次回クリーンアップ ジョブがスケジュールされるときにピックアップされます。 この設定の既定値と最小値は 2 時間に設定されています。
定期的なバッチ – クリーンアップ ジョブは、1 回の手動実行として実行することも、またはバッチでの定期的な実行をスケジュールすることもできます。 バッチは、標準バッチ設定である バックグラウンドで実行 設定を使用してスケジュールできます。
ノート
ジョブ履歴クリーンアップ機能を使用しない場合でも、90 日よりも古い実行履歴は 自動的に削除 されます。 この自動削除に加えて、ジョブ履歴のクリーンアップを実行できます。 クリーンアップ ジョブが繰り返し実行されるようにスケジュールされていることを確認してください。 上記で説明したように、クリーンアップを実行すると、ジョブは指定された最大時間内で可能な限り多くの実行 ID をクリーンアップします。
ジョブ履歴のクリーンアップとアーカイブ
ジョブ履歴のクリーンアップとアーカイブ機能は、以前のバージョンのクリーンアップ機能の改良版です。 このセクションでは、これら新機能について説明します。
クリーンアップ機能の主要な変更のひとつは、履歴のクリーンアップにシステムのバッチジョブを使用することです。 システム バッチ ジョブを使用すると、財務と運用アプリでクリーンアップ バッチ ジョブをシステムの準備が整った時点で自動的にスケジュールして実行できます。 そのため、バッチジョブを手動でスケジュールする必要がなくなります。 この既定の実行モードでは、バッチ ジョブは午前 0 時から 1 時間おきに実行され、直近 7 日間の実行履歴が保持されます。 削除された履歴はアーカイブされ、将来的に取得することができます。 バージョン 10.0.20 からは、この機能は常にオンになっています。
クリーンアップ プロセスの 2 つ目の変更は、削除された実行履歴のアーカイブです。 クリーンアップ ジョブは、削除されたレコードを DIXF が通常の統合に使用する Blob Storage にアーカイブします。 アーカイブされたファイルは DIXF パッケージ形式になり、7 日間は BLOB で利用可能となります。また、この期間にダウンロードすることができます。 アーカイブ ファイルの既定の寿命は 7 日間ですが、パラメーターで最大 90 日間に変更することができます。
既定の設定を変更する
この機能は現在プレビュー版であるため、flight DmfenableexecutionのCleanupsystemjob を有効にすることにより、明示的にオンにする必要があります。 機能管理では、ステージングのクリーンアップ機能も有効になっている必要があります。
アーカイブされたファイルの寿命の既定の設定を変更するには、データ管理ワークスペースで ジョブ履歴のクリーンアップを選択します。 Blob のパッケージを含む日付を 7 から 90 の値に設定します。 こ の変更は、 この変更が行われた後に作成 さ れたアーカイブに適用 さ れます。
アーカイブされたパッケージのダウンロード
この機能は現在プレビュー版であるため、flight DmfenableexecutionのCleanupsystemjob を有効にすることにより、明示的にオンにする必要があります。 機能管理では、ステージングのクリーンアップ機能も有効になっている必要があります。
アーカイブされた実行履歴をダウンロードするには、データ管理ワークスペースに移動して、 ジョブ履歴のクリーンアップを選択します。 パッケージのバックアップ履歴 を選択して、履歴フォームを開きます。 このフォームには、アーカイブされているすべてのパッケージの一覧が表示されます。 アーカイブを選択してダウンロードするには、パッケージのダウンロード を選択し ます。 ダウンロードされたパッケージは、DIXF パッケージで、次のファイルを含みます:
- エンティティのステージング テーブル ファイル
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
xslt を使用した複合エンティティデータの並べ替え
この機能により、複合エンティティをエクスポートし、xslt ファイルを適用して xml ファイルのデータを並べ替えることができます。
xslt を使用して複合エンティティ データを並べ替えるには、以下の手順に従います。
- XML 形式でデータをソートする xslt ファイルを作成します。 たとえば、既成エンティティ Purchase orders composite V3 の XSLT ファイルがある場合、PURCHPURCHASEORDERHEADERV2ENTITY では INVOICEVENDORACCOUNTNUMBER 順に、PURCHPURCHASEORDERLINEV2ENTITY では LINENUMBER 順に XML 属性フォーマットのデータを並べ替えることができます。
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- データ管理ワークスペースに移動します。
- データ エクスポート プロジェクトの一覧から、XML データ ソースを持つプロジェクトを選択し、マップの表示 を選択します。
- 任意のエンティティの マップを表示 を選択します。
- 変換タブに移動します
- 新規 を選択し、ステップ 1 で作成した xslt ファイルをアップロードします。