このクイックスタートでは、Spark Structured Streaming を使用する Python コードを含む Spark ジョブ定義を作成し、レイクハウスにデータを配置し、SQL 分析エンドポイントを介して提供する方法について説明します。 このクイックスタートを完了すると、継続的に実行される Spark ジョブ定義が作成され、SQL 分析エンドポイントで受信データを表示できるようになります。
Python スクリプトを作成する
Apache Spark を使用して Lakehouse にストリーミング Delta テーブルを作成するには、次の Python スクリプトを使用します。 スクリプトは、生成されたデータのストリーム (1 秒あたり 1 行) を読み取り、追加モードで streamingtable という名前の Delta テーブルに書き込みます。 指定されたレイクハウスにデータとチェックポイント情報が格納されます。
Spark 構造化ストリーミングを利用する次の Python コードを使用して、レイクハウス テーブル内のデータを取得します。
from pyspark.sql import SparkSession if __name__ == "__main__": # Start Spark session spark = SparkSession.builder \ .appName("RateStreamToDelta") \ .getOrCreate() # Table name used for logging tableName = "streamingtable" # Define Delta Lake storage path deltaTablePath = f"Tables/{tableName}" # Create a streaming DataFrame using the rate source df = spark.readStream \ .format("rate") \ .option("rowsPerSecond", 1) \ .load() # Write the streaming data to Delta query = df.writeStream \ .format("delta") \ .outputMode("append") \ .option("path", deltaTablePath) \ .option("checkpointLocation", f"{deltaTablePath}/_checkpoint") \ .start() # Keep the stream running query.awaitTermination()スクリプトを Python ファイル (.py) としてローカル コンピューターに保存します。
レイクハウスを作成する
次の手順を使用して、レイクハウスを作成します。
Microsoft Fabric ポータルにサインインします。
目的のワークスペースに移動するか、必要に応じて新しいワークスペースを作成します。
レイクハウスを作成するには、ワークスペースから [新しい項目
選択し、開いたパネルで Lakehouse を選択します。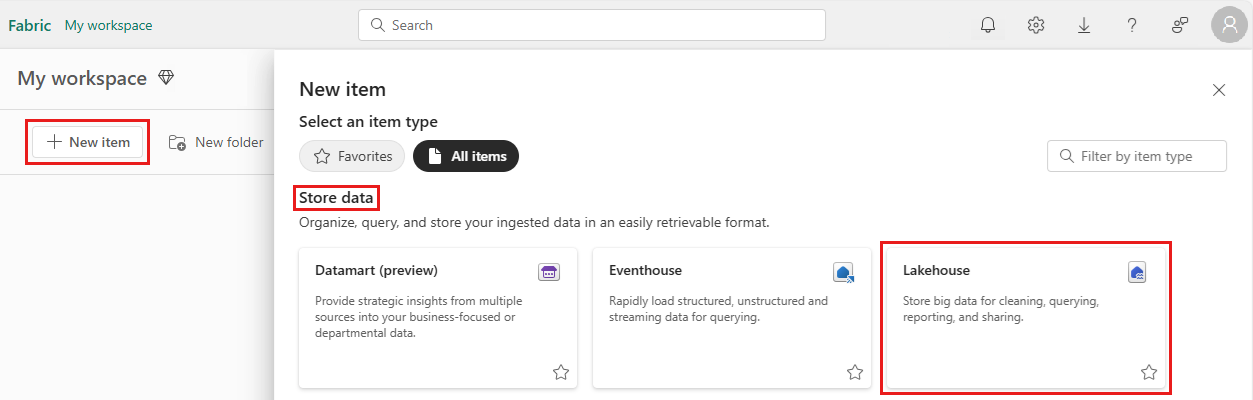
レイクハウスの名前を入力し、[作成] を選択します。

Spark ジョブ定義を作成する
ジョブ定義を作成するには、次の手順を実行します。
レイクハウスを作成したのと同じワークスペースから、[新しいアイテム]
選択します。 開いたパネルで、データの取得の下にある Spark ジョブ定義を選択します。
Spark ジョブ定義の名前を入力し、[作成] を選択します。
[アップロード] を選択し、前の手順で作成した Python ファイルを選択します。
[レイクハウス リファレンス] で、作成したレイクハウスを選択します。
Spark ジョブ定義の再試行ポリシーの設定
Spark ジョブ定義の再試行ポリシーを設定するには、次の手順に従います。
トップ メニューから、[設定] アイコンを選択します。
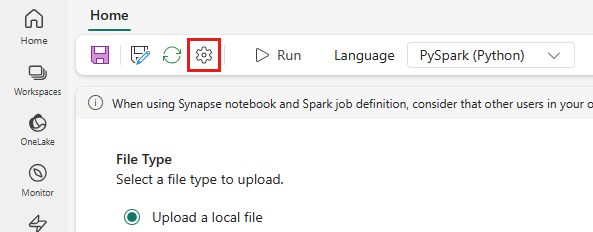
[最適化] タブを開き、[再試行ポリシー] のトリガーを [オン] に設定します。
![[Spark ジョブ定義の最適化] タブを示すスクリーンショット。](media/get-started-streaming/sjd-retry-on.png)
最大再試行回数を定義するか、[無制限の試行を許可する] をチェックします。
再試行の間隔を指定し、[適用] を選択します。

![[Spark ジョブ定義の最適化] タブを示すスクリーンショット。](media/get-started-streaming/sjd-retry-on.png#lightbox)
Note
再試行ポリシーのセットアップでは、有効期間に 90 日の制限があります。 その再試行ポリシーが有効になると、ポリシーに従って 90 日以内にそのジョブは再起動されます。 この期間が過ぎると、その再試行ポリシーは自動的に機能しなくなり、そのジョブは終了します。 その後、ユーザーはそのジョブを手動で再起動する必要があります。これにより、今度は再試行ポリシーがもう一度有効になります。
Spark ジョブ定義の実行と監視
トップ メニューから、[実行] アイコンを選択します。
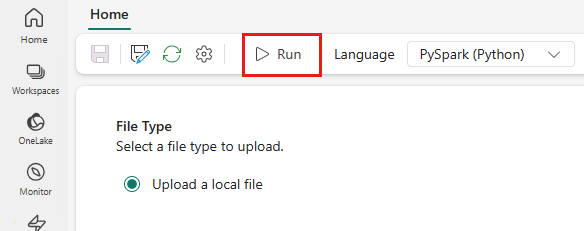
Spark ジョブ定義が正常に送信され、実行されているかどうかを確認します。

SQL 分析エンドポイントを使用してデータを表示する
スクリプトを実行すると、タイムスタンプ列と値列を含む streamingtable という名前のテーブルが lakehouse に作成されます。 SQL 分析エンドポイントを使用してデータを表示できます。
ワークスペースから、Lakehouse を開きます。
右上隅から SQL 分析エンドポイント に切り替えます。
左側のナビゲーション ウィンドウで、[ スキーマ] > [dbo >Tables] を展開し、[ ストリーミングテーブル ] を選択してデータをプレビューします。