Fabric ユーザー データ関数を、サポートされている Fabric データ ソースに Fabric ポータルから直接接続できます。 ファブリックが自動的に認証を処理するため、ユーザー データ関数コードは、資格情報や接続の詳細を格納するのではなく、接続エイリアスのみを参照する必要があります。
この記事では、次の方法について説明します。
- ユーザー データ関数項目の新しい接続を作成します。
- 関数コードで新たな接続を使用します。
- データ接続を変更または削除します。
Fabric ユーザー データ関数でサポートされているデータ ソース
現在、Fabric ユーザー データ関数では次のデータ ソースがサポートされています。
- 読み取り/書き込み操作用の Fabric SQL データベース
- 読み取り/書き込み操作用のファブリック倉庫
- Lakehouse ファイルの読み取り/書き込み操作と SQL エンドポイントの読み取り専用操作用の Fabric Lakehouse。
- 読み取り専用操作用のファブリック ミラー化されたデータベース
注
Fabric 変数ライブラリに接続して、関数の変数として構成設定にアクセスすることもできます。 関数コードで変数ライブラリ変数を使用する方法については、「 Fabric 変数ライブラリから変数を取得する」を参照してください。
[前提条件]
データ ソースに接続する前に、次のものが必要です。
- ワークスペース内の Fabric ユーザー データ関数項目
- ユーザーデータ関数項目に対する書き込み権限を接続管理のために設定する
- アクセス可能なワークスペースで サポートされているデータ ソース (SQL データベース、ウェアハウス、レイクハウス、ミラー化されたデータベース) の少なくとも 1 つ
- 接続するデータ ソースの読み取り権限 (またはそれ以上)
Fabric ポータルで接続を追加する
関数からデータにアクセスするには、データ ソースへの接続を作成する必要があります。 この接続では認証と承認が自動的に処理されるため、コード内の接続文字列や資格情報を管理する必要はありません。 接続を作成すると、ユーザー データ関数項目内の任意の関数から参照できるエイリアスが生成されます。
接続を追加するには:
Fabric ポータルで、ユーザー データ関数項目を見つけて開きます。
ユーザー データ関数エディターのリボンで 、[ 接続の管理 ] を選択します。
![[接続の管理] ボタンが強調表示されているユーザー データ関数エディターのスクリーンショット。](../media/user-data-functions-manage-connections/manage-connections.png)
開いたウィンドウで、[ データ接続の追加] を選択します。
![[接続] タブが選択され、接続が一覧に表示されていない作業ウインドウのスクリーンショット。](../media/user-data-functions-manage-connections/add-data-connection.png)
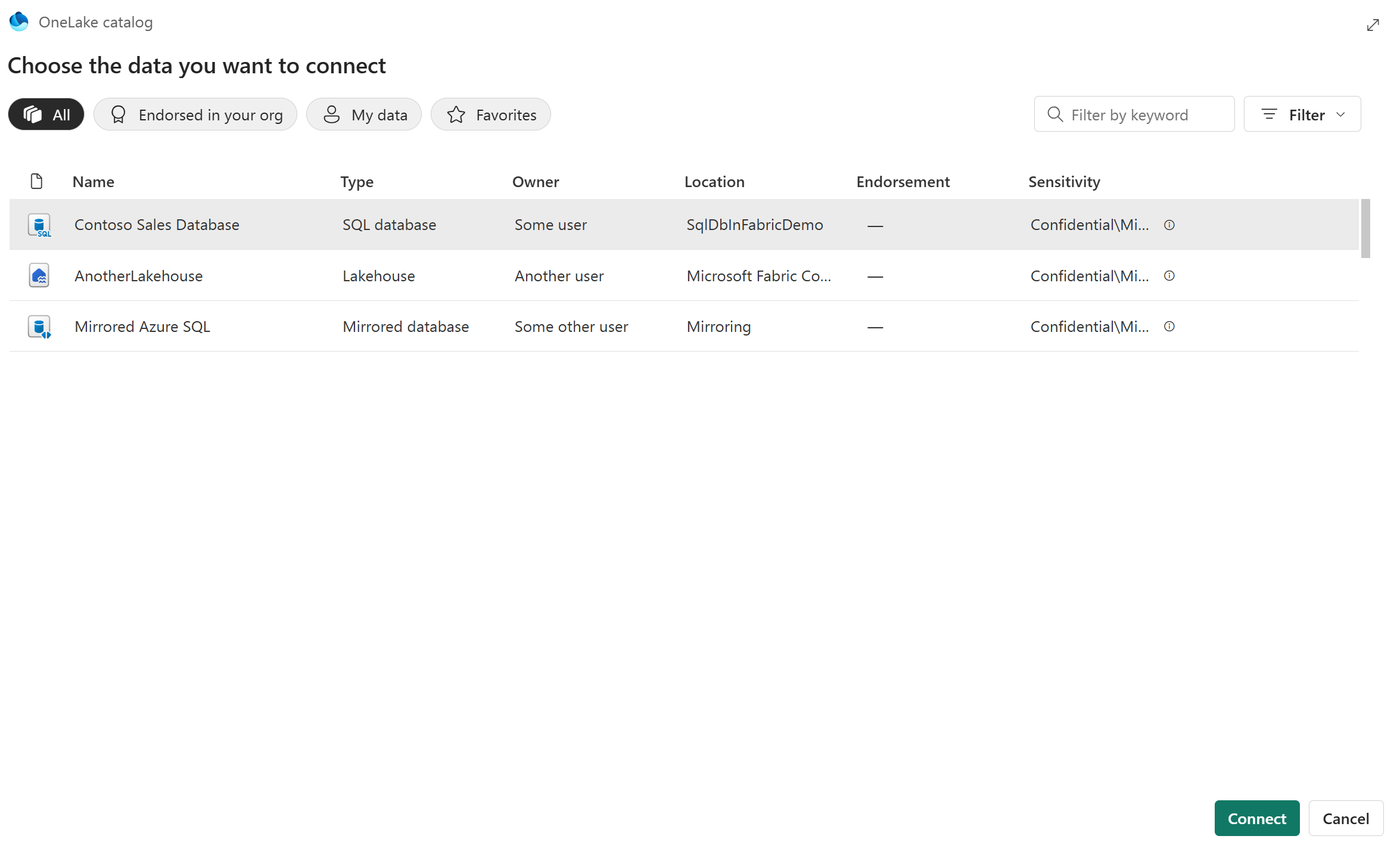
OneLake カタログが開いたら、データ ソースの一覧を参照します。
注
この一覧は、ユーザー アカウントがアクセスできるサポートされているデータ ソースのみを含むようにフィルター処理されます。 データ ソースは、他のワークスペースにある可能性があります。 探しているデータ ソースが見つからない場合は、そのデータ ソースに接続するための適切なアクセス許可があることを確認してください。
データ ソースを選択し、[接続] を選択します。
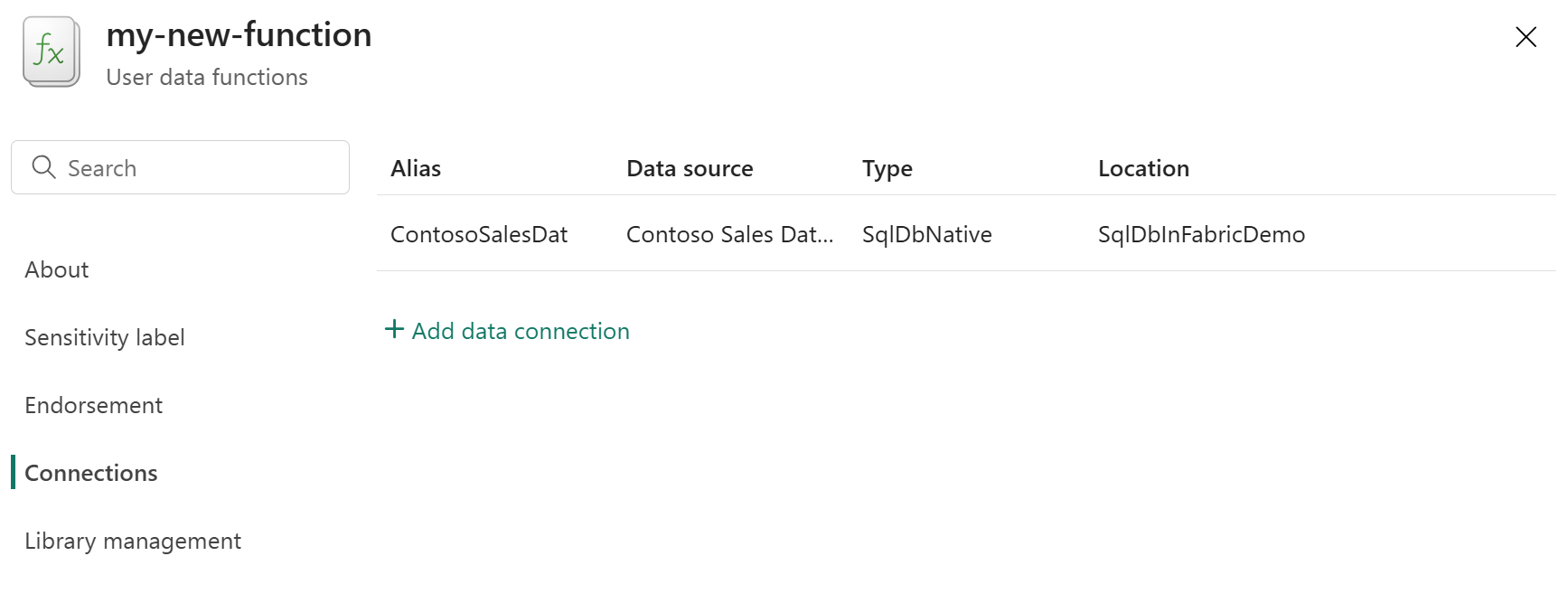
作成されると、[接続] タブのサイド ウィンドウに新しい 接続 が表示されます。生成された エイリアス 名を書き留めておきます。 ユーザー データ関数項目内の関数から接続を参照するには、このエイリアスが必要です。
![[接続の管理] ボタンが強調表示されているユーザー データ関数エディターのスクリーンショット。](../media/user-data-functions-manage-connections/manage-connections.png#lightbox)
![[接続] タブが選択され、接続が一覧に表示されていない作業ウインドウのスクリーンショット。](../media/user-data-functions-manage-connections/add-data-connection.png#lightbox)


あなたの関数コードで接続を使用する
接続を作成した後、接続のエイリアスを使用して関数コードで参照できます。 エイリアスは、接続先のデータ ソースの名前に基づいて自動的に生成されます。 このエイリアスを関数の @udf.connection デコレーターに追加すると、関数の実行時に接続によって認証が処理されます。
最初から記述した任意の関数に接続コードを追加できますが、サンプルを使用すると、既に記述されている接続コードの開始点が提供されます。 接続に合わせてエイリアスを変更するだけです。
コードで接続を使用するには:
エディターをまだ使用していない場合は、ユーザー データ関数項目を開き、[ 開発モード] を選択してから、[ 編集 ] タブを選択します。
リボンで、[サンプルの 挿入] を選択します。
ドロップダウン リストから、[SQL Database>SQL Database のテーブルからデータを読み取ります。
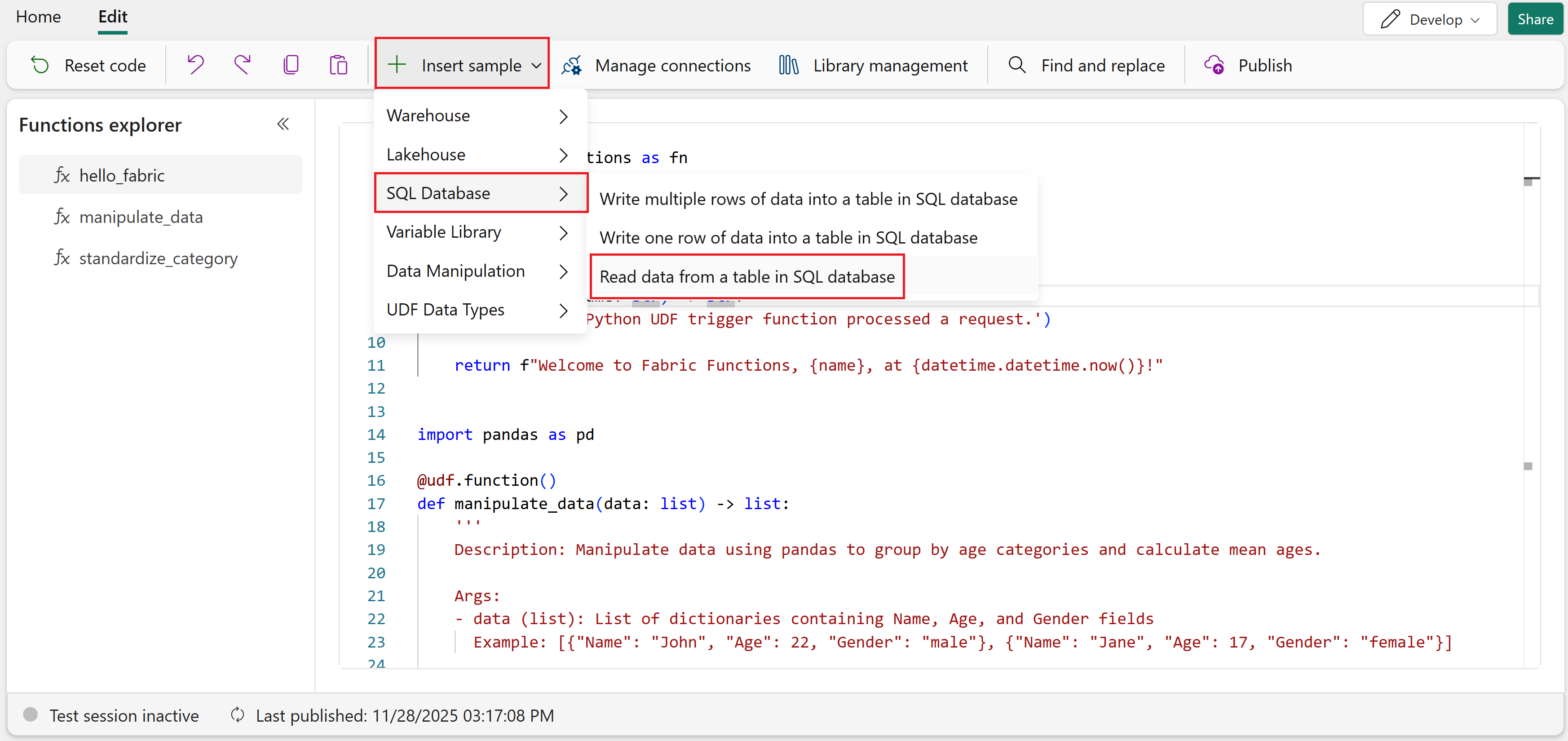
このサンプルでは、SQL データベース テーブルからデータを読み取る次のコードを挿入します。
@udf.connection(argName="sqlDB",alias="<alias for sql database>") @udf.function() def read_from_sql_db(sqlDB: fn.FabricSqlConnection)-> list: # Replace with the query you want to run query = "SELECT * FROM (VALUES ('John Smith', 31), ('Kayla Jones', 33)) AS Employee(EmpName, DepID);" # Establish a connection to the SQL database connection = sqlDB.connect() cursor = connection.cursor() query.capitalize() # Execute the query cursor.execute(query) # Fetch all results results = [] for row in cursor.fetchall(): results.append(row) # Close the connection cursor.close() connection.close() return results注
このサンプル クエリでは、
VALUES句を使用してインラインでテスト データが生成されるため、データベースにテーブルがまだない場合でも接続をテストできます。 独自のデータに対してクエリを実行する準備ができたら、クエリを実際のテーブルを参照するクエリに置き換えます。<alias for sql database>デコレーターの@udf.connectionを、前のセクションで作成した接続のエイリアスに置き換えます。たとえば、接続エイリアスが
ContosoSalesDatされている場合、デコレーターは次のようになります。@udf.connection(argName="sqlDB",alias="ContosoSalesDat") @udf.function() def read_from_sql_db(sqlDB: fn.FabricSqlConnection)-> list: [...]関数をテスト して、接続が正しく動作することを確認します。

接続を使用して関数をテストした後、それを発行して実行できます。 詳細については、「 ユーザー データ関数のテスト」を参照してください。
接続を変更または削除する
[接続の管理] ウィンドウから既存の 接続 を変更または削除できます。 ただし、変更を加える前に、自分の機能への影響に注意してください。
接続エイリアスを変更する
既存の接続のエイリアスを変更するには:
Fabric ポータルで、ユーザー データ関数項目を開きます。
リボンの [ 接続の管理 ] を選択します。
[ 接続の管理 ] ウィンドウで、変更する接続を見つけて、[ 接続の編集] アイコン (鉛筆) を選択します。
新しいエイリアス名を入力します。
[更新] を選択して変更を保存します。
Important
接続のエイリアスを変更すると、古いエイリアスを使用するすべての関数が実行時に失敗します。 新しいエイリアス名を使用するには、古いエイリアスを参照するすべての関数コードを更新する必要があります。 別のデータ ソースに接続するには、既存の接続を変更するのではなく、新しい接続を作成します。
接続を削除する
接続を削除するには:
Fabric ポータルで、ユーザー データ関数項目を開きます。
リボンの [ 接続の管理 ] を選択します。
[ 接続の管理 ] ウィンドウで、削除する接続を見つけて、[ 接続の削除 ] アイコン (ごみ箱) を選択します。
削除を確定します。
Warnung
関数コードで参照されている接続を削除すると、それらの関数は実行時に接続エラーで失敗します。 接続を削除する前に、関数が接続を使用していないことを確認するか、削除された接続エイリアスへの参照を削除するように関数コードを更新します。