このレシピでは、Apache Spark で SynapseML と Foundry Tools を使用して、多変量異常検出を行う方法を示します。 多変量異常検出では、さまざまな変数間のすべての相互相関と依存関係を計算しながら、多くの変数または時系列間の異常の検出が含まれます。 このシナリオでは、SynapseML と Foundry Tools を使用して、多変量異常検出用のモデルをトレーニングします。 次に、モデルを使用して、3 つの IoT センサーからの合成測定値を含むデータセット内の多変量異常を推論します。
重要
2023 年 9 月 20 日から、新しい Anomaly Detector リソースを作成することはできません。 Anomaly Detector サービスは、2026 年 10 月 1 日に廃止されます。
Azure AI Anomaly Detectorの詳細については、Anomaly Detector 情報リソースを参照してください。
前提条件
- Azure サブスクリプション - 無料で作成します
- ノートブックをレイクハウスにアタッチします。 左側で [追加] を選択して、既存のレイクハウスを追加するか、レイクハウスを作成します。
セットアップ
既存の Anomaly Detector リソースから、さまざまな形式のデータを処理する方法を調べることができます。
Anomaly Detector リソースを作成する
注
2023 年 9 月 20 日以降、新しい Anomaly Detector リソースを作成することはできません。 次の手順は、既存の Anomaly Detector リソースがある場合にのみ適用されます。 Anomaly Detector サービスを必要としない多変量異常検出アプローチについては、「 分離フォレストを使用した多変量異常検出」を参照してください。
- Azure ポータルで、リソース グループで Create を選択し、「Anomaly Detector」と入力します。 Anomaly Detector リソースを選択します。
- リソースに名前を付け、理想的にはリソース グループの残りの部分と同じリージョンを使用します。 残りの部分には既定のオプションを使用し、[確認 + 作成] を選択して [作成] を選択します。
- Anomaly Detector リソースを作成したら、それを開き、左側のナビゲーションで
Keys and Endpointsパネルを選択します。 Anomaly Detector リソースのキーをANOMALY_API_KEY環境変数にコピーするか、anomalyKey変数に保存します。
ストレージ アカウント リソースを作成する
中間データを保存するには、Azure Blob Storage アカウントを作成する必要があります。 そのストレージ アカウント内に、中間データを保存するためのコンテナーを作成します。 コンテナー名をメモし、connection stringをそのコンテナーにコピーします。 後で containerName 変数と BLOB_CONNECTION_STRING 環境変数を設定する必要があります。
サービス キーの入力
まず、サービス キーの環境変数を設定します。 次のセルは、Azure Key Vaultに格納されている値に基づいて、ANOMALY_API_KEY と BLOB_CONNECTION_STRING 環境変数を設定します。 独自の環境でこのチュートリアルを実行する場合は、先に進む前に必ずこれらの環境変数を設定してください。
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
ANOMALY_API_KEYとBLOB_CONNECTION_STRING環境変数を読み取り、containerName変数とlocation変数を設定します。
# An Anomaly Detector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
異常検出で中間結果をそのストレージ アカウントに保存できるように、ストレージ アカウントに接続します。
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
必要なすべてのモジュールをインポートします。
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.services import *
サンプル データを Spark DataFrame に読み取ります。
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
モデルのトレーニングに使用する estimator オブジェクトを作成できるようになりました。 トレーニング データの開始時刻と終了時刻を指定します。 また、使用する入力列と、タイムスタンプを含む列の名前も指定します。 最後に、異常検出スライディング ウィンドウで使用するデータ ポイントの数を指定し、connection stringを Azure Blob Storage アカウントに設定します。
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
estimatorをデータに合わせる:
model = estimator.fit(df)
トレーニングが完了したら、推論にモデルを使用します。 次のセルのコードは、異常を検出するデータの開始時刻と終了時刻を指定します。
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
前のセルの .show(5) は、最初の 5 つのデータフレーム行を示しています。 推論ウィンドウの外側に配置されるため、結果はすべてnullとなります。
推論されたデータについてのみ結果を表示するには、必要な列を選択します。 その後、データフレーム内の行を昇順で並べ替え、結果をフィルター処理して推論ウィンドウの範囲内の行のみを表示できます。 ここでは、 inferenceEndTime データフレームの最後の行と一致するため、無視できます。
最後に、結果をより適切にプロットするには、Spark データフレームを Pandas データフレームに変換します。
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
次に、検出された異常に対応する各センサーからの寄与度スコアを保存する、contributors 列を形式化します。 次のセルはこれを処理し、各センサーのコントリビューション スコアを独自の列に分割します。
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
これで、センサー 1、2、3 のコントリビューション スコアがそれぞれ series_0、 series_1、 series_2 列に表示されます。
結果をプロットするには、次のセルを実行します。
minSeverity パラメーターは、プロットする異常の最小重大度を指定します。
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
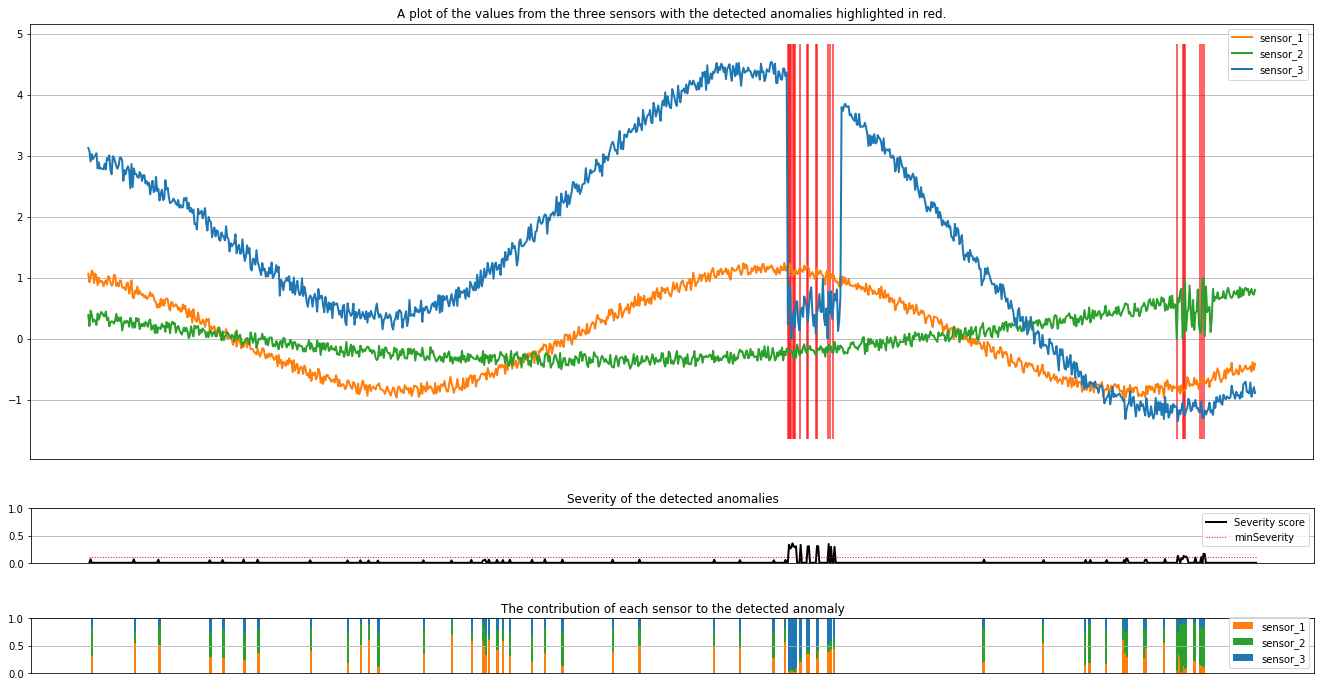
プロットには、センサー (推論ウィンドウ内) の生データがオレンジ、緑、青で表示されます。 最初の図の赤い縦線は、重要度が minSeverity 以上の検出された異常を示しています。
2 番目のプロットは、検出されたすべての異常の重要度スコアを示し、minSeverity しきい値は赤い点線で示されています。
最後に、最後のプロットには、検出された異常に対する各センサーからのデータの寄与が示されています。 これは、各異常の最も可能性の高い原因を診断して理解するのに役立ちます。
関連するコンテンツ
- 分離フォレストを使用した多変量異常検出 - Azure AI Anomaly Detector リソースは必要ありません。
- SynapseML で LightGBM を使用する方法
- SynapseML で Foundry Tools を使用する方法
- SynapseML を使用してハイパーパラメーターを調整する方法