このチュートリアルでは、探索的データ分析 (EDA) を実行してデータを調査し、データ視覚化手法を使用して主な特性を要約する方法について説明します。
データフレームと配列でビジュアルを構築するための高度なインターフェイスを提供する Python データ視覚化ライブラリである seabornを使用します。
seabornの詳細については、「Seaborn: 統計データ視覚化」を参照してください。
また、Data Wrangler(探索的データの分析とクリーニングを行うためのイマーシブ エクスペリエンスを提供するノートブック ベースのツール) も使用します。
このチュートリアルの主な手順は次のとおりです。
- レイクハウス内のデルタ テーブルから格納されているデータを読み取ります。
- Spark DataFrame を Pandas DataFrame に変換します。Python 視覚化ライブラリでサポートされています。
- Data Wrangler を使用して、初期データのクリーニングと変換を実行します。
-
seabornを使用して探索的データ分析を実行します。
前提 条件
Microsoft Fabric サブスクリプションを取得します。 または、無料で Microsoft Fabric の試用版 にサインアップします。
Microsoft Fabric にサインインします。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して Fabric に切り替えます。
これはチュートリアル シリーズのパート 2/5 です。 このチュートリアルを完了するには、最初に次の手順を完了します。
- パート 1: Apache Sparkを使用して Microsoft Fabric Lakehouse にデータを取り込みます。
ノートブックで作業を進める
2-explore-cleanse-data.ipynb は、このチュートリアルに付属するノートブックです。
このチュートリアルの付属のノートブックを開くには、「データ サイエンス用にシステムを準備する」の手順に従って、ノートブックをワークスペースにインポート します。
このページからコードをコピーして貼り付ける場合は、新しいノートブックを作成できます。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
重要
パート 1 で使用したのと同じレイクハウスをアタッチします。
レイクハウスから生データを読み取る
レイクハウスの [ファイル] セクションから生データを読み取ります。 前のノートブックでこのデータをアップロードしました。 このコードを実行する前に、パート 1 で使用したのと同じ lakehouse をこのノートブックにアタッチしていることを確認してください。
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
データセットから pandas DataFrame を作成する
spark DataFrame を pandas DataFrame に変換して、処理と視覚化を容易にします。
df = df.toPandas()
生データを表示する
displayを使用して生データを探索し、いくつかの基本的な統計情報を実行し、グラフ ビューを表示します。 まず、データ分析と視覚化のために必要なライブラリ (Numpy、Pnadas、Seaborn、Matplotlib など) をインポートする必要があることに注意してください。
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
# Code generated by Data Wrangler for pandas DataFrame
def clean_data(df):
# Drop duplicate rows in columns: 'CustomerId', 'RowNumber'
df = df.drop_duplicates(subset=['CustomerId', 'RowNumber'])
# Drop rows with missing data across all columns
df = df.dropna()
# Drop columns: 'CustomerId', 'RowNumber', 'Surname'
df = df.drop(columns=['CustomerId', 'RowNumber', 'Surname'])
return df
df_clean = clean_data(df.copy())
df_clean.head()
Data Wrangler を使用して初期データ クリーニングを実行する
ノートブック内の pandas データフレームを探索して変換するには、ノートブックから直接 Data Wrangler を起動します。
手記
ノートブック カーネルがビジー状態の間、データ ラングラーを開くできません。 Data Wrangler を起動する前に、セルの実行を完了する必要があります。
- ノートブック リボンの [データ ] タブで、[データ ラングラーの起動] 選択します。 編集に使用できるアクティブ化された pandas DataFrame の一覧が表示されます。
- Data Wrangler で開く DataFrame を選択します。 このノートブックには DataFrame が 1 つだけ含まれるため、
dfdf選択します。
Data Wrangler が起動し、データの説明的な概要を生成します。 中央のテーブルには、各データ列が表示されます。 テーブルの横にある [の概要 パネルには、DataFrame に関する情報が表示されます。 テーブル内の列を選択すると、選択した列に関する情報で概要が更新されます。 場合によっては、表示および要約されたデータは、DataFrame の一部が切り捨てられたビューになります。 これが発生すると、概要ウィンドウに警告画像が表示されます。 この警告にカーソルを合わせると、状況を説明するテキストが表示されます。

実行する各操作は、クリック数に関係なく適用でき、リアルタイムでデータ表示を更新し、再利用可能な関数としてノートブックに保存できるコードを生成します。
このセクションの残りの部分では、Data Wrangler でデータクリーニングを実行する手順について説明します。
重複する行を削除する
左側のパネルには、データセットに対して実行できる操作の一覧 ([の検索と置換、書式、数式、数値など) があります。
[検索と置換] を展開し、[重複する行をドロップする] を選びます。
![スクリーンショットは、[検索と置換] の下に重複する行をドロップする方法を示しています。](media/tutorial-data-science-explore-notebook/expand-section.png)
比較する列の一覧を選択して重複する行を定義するためのパネルが表示されます。 RowNumber を選択し、CustomerIdを選択します。
中央のパネルには、この操作の結果のプレビューが表示されます。 プレビューの下には、操作を実行するコードがあります。 この場合、データは変更されていないように見えます。 ただし、表示されているのは切り捨てられたビューなので、この操作を適用することをお勧めします。
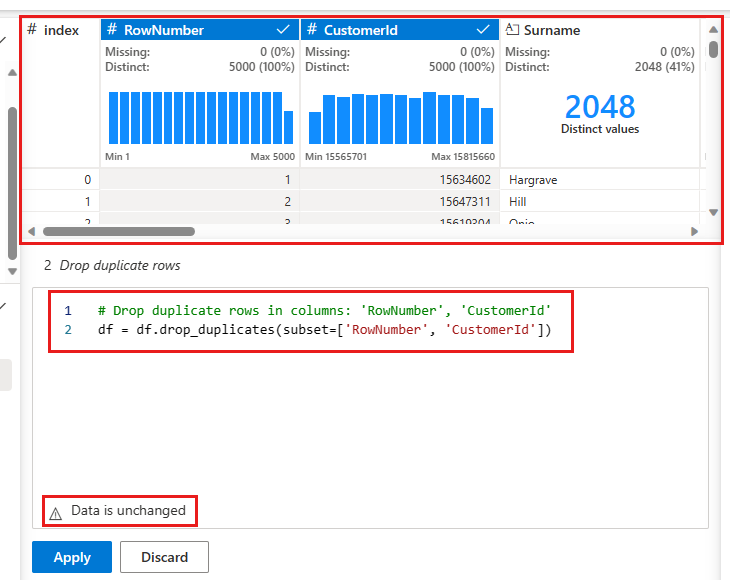
を選択し、(横または下部)を適用して、次の手順に進みます。

データが見つからない行を削除する
Data Wrangler を使用して、すべての列にデータがない行を削除します。
[検索と置換] から [欠損値をドロップする] を選びます。
[ターゲット列] から [すべて選択] を選びます。
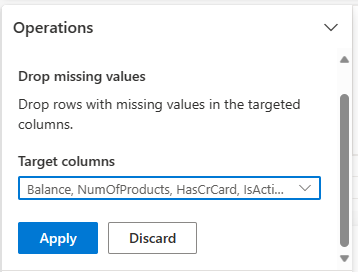
[ 適用] を選択して、次の手順に進みます。

列を削除する
不要な列を削除するには、Data Wrangler を使用します。
スキーマ を展開し、[列の削除]を選択します。
[ RowNumber]、[ CustomerId]、[ Surname]を選択します。 これらの列は、コードによって変更された (この場合は削除された) ことを示すために、プレビューでは赤で表示されます。
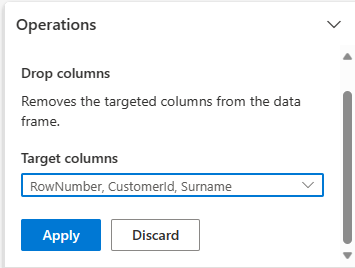
[ 適用] を選択して、次の手順に進みます。

ノートブックにコードを追加する
毎回 [を適用] を選択するたびに、左下の [クリーニング手順] パネルに新しい手順が作成されます。 パネルの下部で、すべてのステップ プレビュー コードを選択して、すべての個別のステップの組み合わせを表示します。
左上 ノートブック にコードを追加する] を選択して Data Wrangler を閉じ、コードを自動的に追加します。 [ノートブックにコードを追加する] を使うと、コードが関数にラップされ、その関数が呼び出されます。

ヒント
Data Wrangler によって生成されたコードは、新しいセルを手動で実行するまで適用されません。
Data Wrangler を使用していない場合は、代わりにこの次のコード セルを使用できます。
このコードは Data Wrangler によって生成されるコードに似ていますが、生成された各ステップに inplace=True 引数を追加します。
inplace=True設定すると、pandas は新しい DataFrame を出力として生成するのではなく、元の DataFrame を上書きします。
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
データを探索する
クリーンアップされたデータの概要と視覚化を表示します。
カテゴリ、数値、およびターゲットの属性を決定する
このコードを使用して、カテゴリ、数値、およびターゲットの属性を決定します。
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
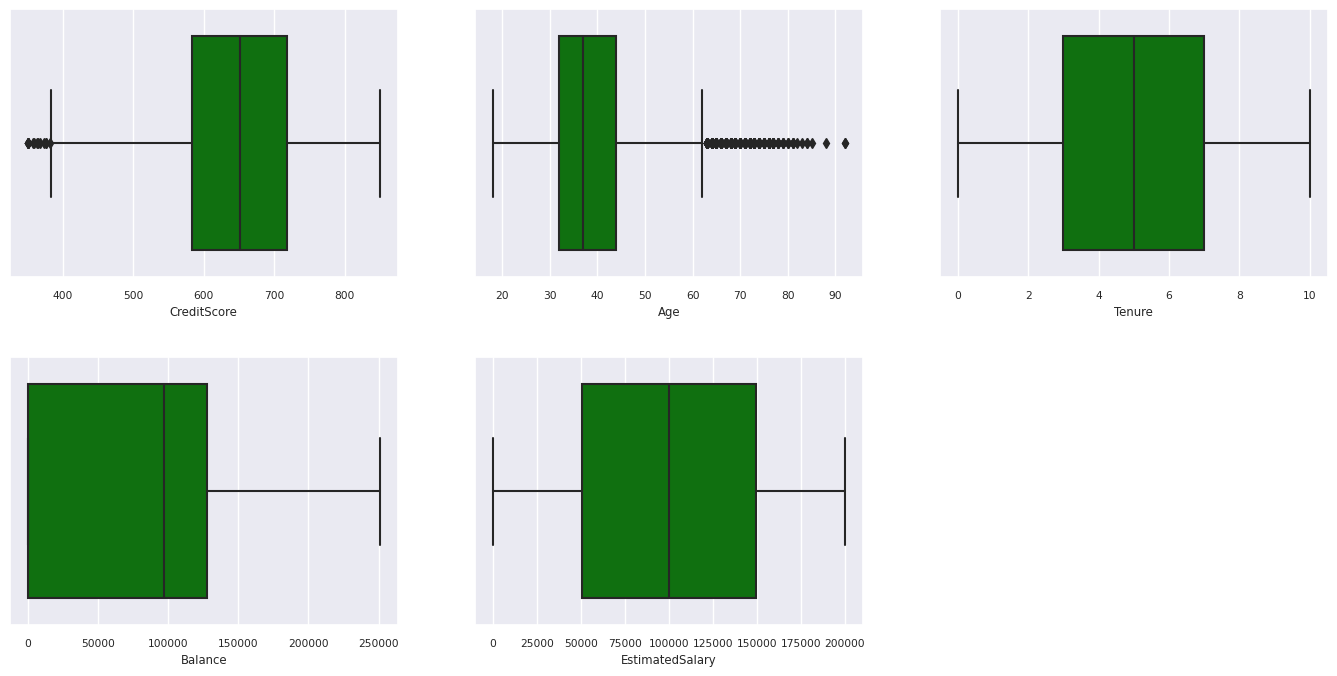
5 つの数値の概要
ボックス プロットを使用して、数値属性の 5 つの数値の概要 (最小スコア、最初の四分位数、中央値、3 番目の四分位数、最大スコア) を表示します。
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
離脱した顧客と離脱していない顧客の分布
カテゴリ属性ごとに、解約した顧客と未解約の顧客の分布を表示します。
df_clean['Exited'] = df_clean['Exited'].astype(str)
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
print(ind, item)
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
df_clean['Exited'] = df_clean['Exited'].astype(int)

数値属性の分布
ヒストグラムを使用して数値属性の頻度分布を表示します。
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

特徴エンジニアリングを実行する
フィーチャ エンジニアリングを実行して、現在の属性に基づいて新しい属性を生成します。
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Data Wrangler を使用してワンホット エンコードを実行する
データ ラングラーを使用して、ワンホット エンコードを実行することもできます。 これを行うには、Data Wrangler を再度開きます。 今回は、df_clean データを選択します。
- 数式 を展開し、ワンホット エンコードを選択します。
- ワンホット エンコードを実行する列の一覧を選択するためのパネルが表示されます。 [地理] と [性別] を選択します。
生成されたコードをコピーし、Data Wrangler を閉じてノートブックに戻り、新しいセルに貼り付けることができます。 または、左上 ノートブック にコードを追加する] を選択して Data Wrangler を閉じ、コードを自動的に追加します。
Data Wrangler を使用していない場合は、代わりに次のコード セルを使用できます。
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
for column in ['Geography', 'Gender']:
insert_loc = df_clean.columns.get_loc(column)
df_clean = pd.concat([df_clean.iloc[:,:insert_loc], pd.get_dummies(df_clean.loc[:, [column]]), df_clean.iloc[:,insert_loc+1:]], axis=1)
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
探索的データ分析からの観測の概要
- ほとんどのお客様は、スペインやドイツと比較してフランスからの顧客ですが、スペインはフランスとドイツに比べてチャーン率が最も低くなります。
- ほとんどのお客様はクレジット カードを持っています。
- 年齢とクレジット スコアがそれぞれ 60 を超え、400 を下回る顧客がいますが、外れ値と見なすことはできません。
- 銀行の製品を 2 つ以上持っている顧客はごくわずかです。
- アクティブでないお客様は、チャーン率が高くなります。
- 性別と在職年数は、銀行口座を閉鎖する顧客の決定に影響を与えないようです。
クリーンアップされたデータのデルタ テーブルを作成する
このデータは、このシリーズの次のノートブックで使用します。
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
次の手順
次のデータを使用して、機械学習モデルをトレーニングして登録します。
パート 3: 機械学習モデルをトレーニングし、登録します。