このチュートリアルでは、既存の Azure Cosmos DB for NoSQL アカウントから Fabric ミラー化データベースを構成します。
ミラーリングは、Azure Cosmos DB データを Fabric OneLake にほぼリアルタイムで段階的にレプリケートします。トランザクション ワークロードのパフォーマンスに影響を与えたり、要求ユニット (RU) を消費したりすることはありません。 DirectLake モードを使用して、OneLake 内のデータを直接対象にした Power BI レポートを作成できます。 SQL または Spark でアドホック クエリを実行し、ノートブックを使用してデータ モデルを構築し、Fabric 内の組み込みの Copilot と高度な AI 機能を使用してデータを分析できます。
重要
Azure Cosmos DB のサポートは現在プレビュー段階です。 プレビュー期間中は、運用環境のワークロードはサポートされていません。 現在、Azure Cosmos DB for NoSQL アカウントのみでサポートされています。
前提条件
- 既存の Azure Cosmos DB for NoSQL アカウント。
- Azure サブスクリプションをお持ちでない場合は、Azure Cosmos DB for NoSQL を無料でお試しください。
- 既存の Azure サブスクリプションをお持ちの場合は、新しい Azure Cosmos DB for NoSQL アカウントを作成してください。
- 既存の Fabric 容量。 既存の容量がない場合は、Fabric 試用版を開始します。 一部の Fabric リージョンではミラーリングを使用できない場合があります。 詳細については、「サポートされているリージョン」を参照してください。
ヒント
パブリック プレビュー期間中は、バックアップから迅速に復旧できる既存の Azure Cosmos DB データのテスト コピーまたは開発コピーを使用することをお勧めします。
Azure Cosmos DB アカウントの構成
まず、ソースとなる Azure Cosmos DB アカウントが Fabric ミラーリングで使用するように正しく構成されていることを確認します。
Azure portal で Azure Cosmos DB アカウントに移動します。
継続的バックアップが有効になっていることを確認します。 継続的バックアップが有効になっていない場合は、既存の Azure Cosmos DB アカウントを継続的バックアップに移行する手順に従って有効にします。 一部のシナリオでは、この機能が利用できない場合があります。 詳細については、「 データベースとアカウントの制限事項」を参照してください。
ネットワーク オプションが、すべてのネットワークのパブリック ネットワーク アクセスに設定されていることを確認します。 そうでない場合は、「Azure Cosmos DB アカウントへのネットワーク アクセスの構成」に記載されたガイドに従ってください。
ミラー データベースを作成する
次に、レプリケートされたデータのターゲットとなるミラー データベースを作成します。 詳細については、「ミラーリングに対する期待事項」を参照してください。
Fabric ポータルの [ホーム] ページに移動します。
既存のワークスペースを開くか、新規ワークスペースを作成します。
ナビゲーション メニューで [作成] を選択します。
[作成] を選択し、[データ ウェアハウス] セクションを見つけたら、[ミラーリングされた Azure Cosmos DB (プレビュー)] を選択します。
ミラー データベースの名前を指定し、[作成] を選択します。
ソース データベースに接続する
次に、ソース データベースをミラー データベースに接続します。
[新しい接続] セクションで、Azure Cosmos DB for NoSQL を選択します。
次のアイテムを含む、Azure Cosmos DB for NoSQL アカウントの資格情報を指定します。
価値 Azure Cosmos DB エンドポイント ソース アカウントの URL エンドポイント。 接続名 接続には、固有の名前を入力してください。 認証の種類 [アカウント キー] または [組織アカウント] を選択します。 アカウント キー ソース アカウントの読み取り/書き込みキー。 組織アカウント Microsoft Entra ID からのアクセス トークン。 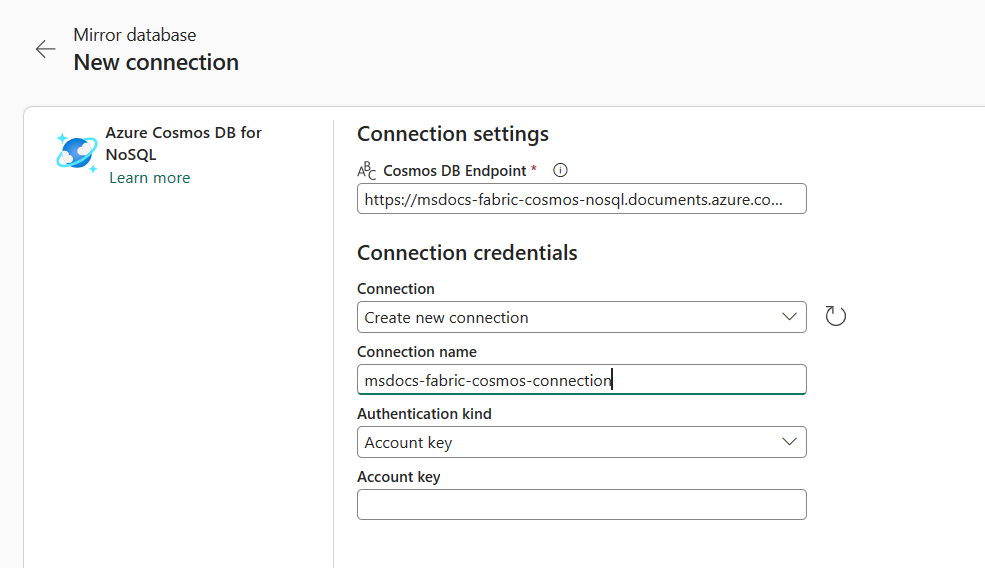
注
Microsoft Entra ID 認証では、次の RBAC アクセス許可が必要です。
Microsoft.DocumentDB/databaseAccounts/readMetadataMicrosoft.DocumentDB/databaseAccounts/readAnalytics
[接続] を選択します。 次に、ミラーリングするデータベースを選択します。 必要に応じて、ミラー化する特定のコンテナーを選択します。

ミラーリング プロセスの開始
[ミラー データベース] を選択 します。 ミラーリングが今、開始されます。
2 から 5 分待ちます。 次に、[レプリケーションの監視] を選択して、レプリケーション操作の状態を確認します。
数分後に、状態が [実行中] に変わります。これは、コンテナーの同期が進行中であることを示します。
ヒント
コンテナーとそれに対応するレプリケーションの状態が見つからない場合は、数秒待ってからウィンドウを更新します。 まれに、一時的なエラー メッセージが表示されることがあります。 それらは無視して、更新を続けても問題ありません。
ミラーリングコンテナーの初期コピーが完了すると、[最終更新] 列に日付が表示されます。 データが正常にレプリケートされた場合、[合計行数] 列にはレプリケートされたアイテムの数が表示されます。
ファブリック ミラーリングの監視
これでデータが稼働し、Fabric 全体でさまざまな分析シナリオが利用できるようになりました。
Fabric ミラーリングが構成されると、[レプリケーションの状態] ウィンドウに自動的に移動します。
ここでは、レプリケーションの現在の状態を監視します。 詳細情報とレプリケーション状態については、「Fabric ミラー化データベース レプリケーションを監視する」を参照してください。
Fabric からソース データベースをクエリする
Fabric ポータルを使用して、Azure Cosmos DB アカウントに既に存在するデータを調べ、ソース Cosmos DB データベースに対してクエリを実行します。
Fabric ポータルで [ミラーリングされたデータベース] に移動します。
[表示]、[ソース データベース] の順に選択します。 この操作により、ソース データベースの読み取り専用ビューで Azure Cosmos DB データ エクスプローラーが開きます。
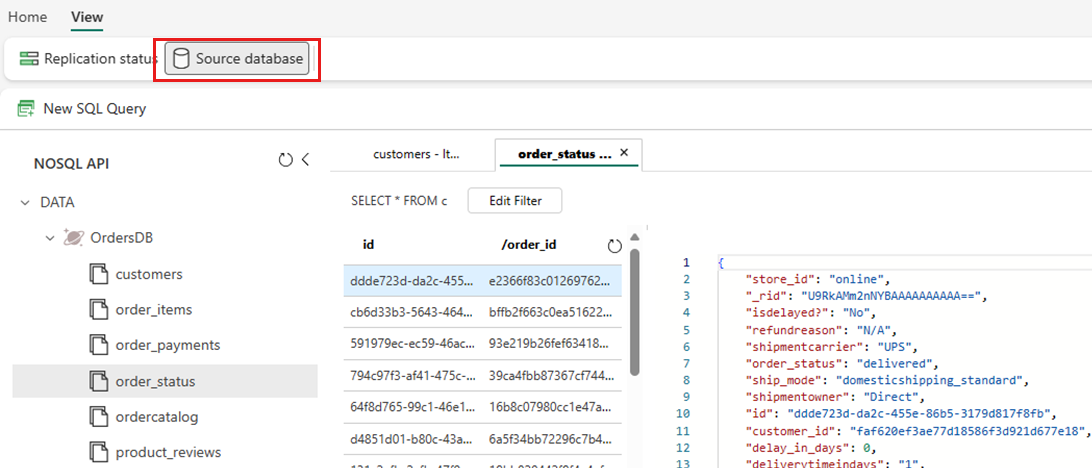
コンテナーを選択し、コンテキスト メニューを開き、[新しい SQL クエリ] を選択 します。
任意のクエリを実行します。 たとえば、コンテナー内のアイテムの数をカウントするには、
SELECT COUNT(1) FROM containerを使用します。注
ソース データベースのすべての読み取りは Azure にルーティングされ、アカウントに割り当てられた要求ユニット (RU) が使用されます。

ターゲット ミラー データベースを分析する
次に、T-SQL を使用して、Fabric OneLake に格納されている NoSQL データに対してクエリを実行します。
Fabric ポータルで [ミラーリングされたデータベース] に移動します。
ミラー化された Azure Cosmos DB から SQL 分析エンドポイントに切り替えます。
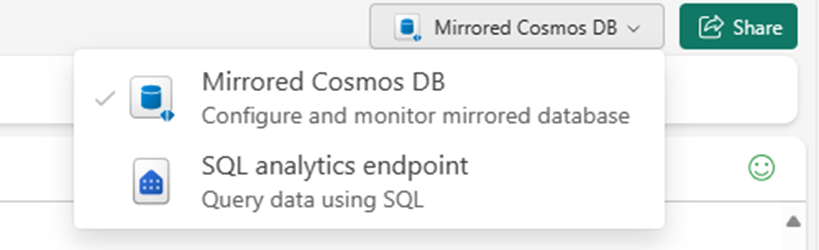
ソース データベース内の各コンテナーは、SQL 分析エンドポイントでウェアハウス テーブルとして表されます。
任意のテーブルを選択し、コンテキスト メニューを開き、[新しい SQL クエリ] を選択して、最後に [上位 100 を選択] を選択します。
クエリが実行され、選択したテーブル内の 100 個のレコードが返されます。
同じテーブルのコンテキスト メニューを開き、[新しい SQL クエリ] を選択 します。
SUM、COUNT、MIN、MAXなどの集計を使用するクエリの例を記述します。 ウェアハウス内の複数のテーブルを結合して、複数のコンテナー間でクエリを実行します。注
たとえば、このクエリは複数のコンテナーで実行されます。
SELECT d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type], sum(o.[price]) as price, sum(o.[freight_value]) freight_value FROM [dbo].[products] p INNER JOIN [dbo].[OrdersDB_order_payments] p on o.[order_id] = p.[order_id] INNER JOIN [dbo].[OrdersDB_order_status] t ON o.[order_id] = t.[order_id] INNER JOIN [dbo].[OrdersDB_customers] c on t.[customer_id] = c.[customer_id] INNER JOIN [dbo].[OrdersDB_productdirectory] d ON o.product_id = d.product_id INNER JOIN [dbo].[OrdersDB_sellers] s on o.seller_id = s.seller_id GROUP BY d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type]この例では、テーブルと列の名前を想定しています。 SQL クエリを記述するときは、独自のテーブルと列を使用します。
クエリを選択し、[名前を付けて保存] ビューを選択します。 ビューに一意の名前を付けます。 このビューには、Fabric ポータルからいつでもアクセスできます。
Fabric ポータルでミラー データベースに戻ります。
[新しいビジュアル クエリ] を選択 します。 クエリ エディターを使用すると、複雑なクエリを作成できます。
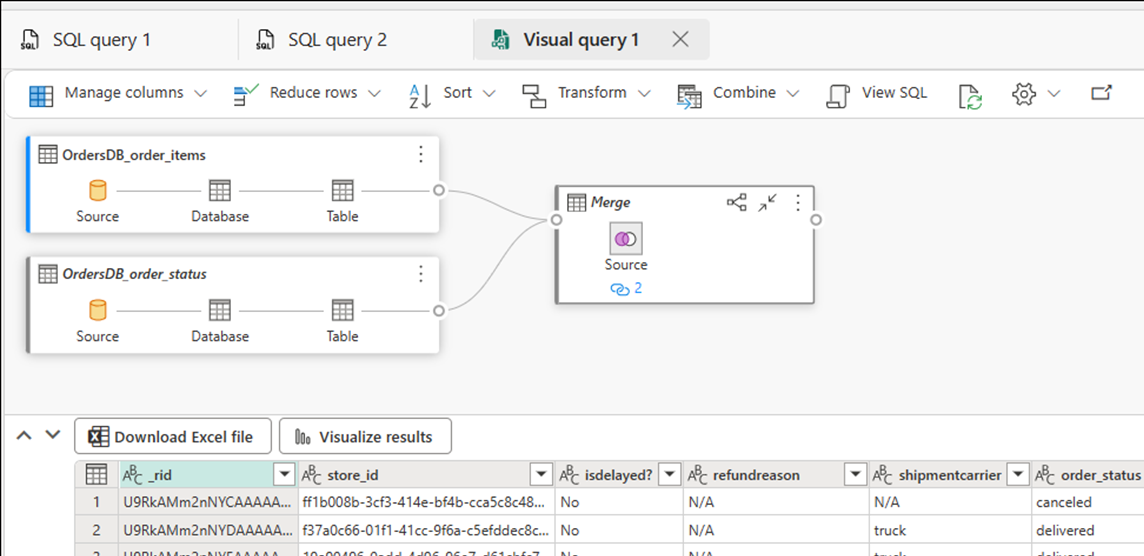


SQL クエリまたはビューに基づいて BI レポートを作成する
- クエリまたはビューを選択した後、[このデータを探索する (プレビュー)] を選択します。 このアクションでは、OneLake ミラー データ上の Direct Lake を使用して、Power BI のクエリを直接探索します。
- 必要に応じてグラフを編集し、レポートを保存します。
ヒント
必要に応じて、Copilot またはその他の拡張機能を使用して、それ以上のデータ移動を行わずにダッシュボードやレポートを作成することもできます。
その他の例
Fabric でミラーリングされた Azure Cosmos DB データにアクセスしてクエリを実行する方法について説明します。
- 方法: Azure Cosmos DB から Microsoft Fabric ミラー化データベース内の入れ子になったデータのクエリを実行する (プレビュー)
- 操作方法: Lakehouse とノートブックのミラーリングさらた Azure Cosmos DB データに Microsoft Fabric からアクセスする (プレビュー)
- 方法: ミラー化された Azure Cosmos DB データを Microsoft Fabric 内の他のミラー化されたデータベースと結合する (プレビュー)