Direct Lake 用のレイクハウスを作成する
この記事では、レイクハウスおよびそのレイクハウスの Delta テーブルを作成する方法について説明し、次に Microsoft Fabric ワークスペースでレイクハウスの基本的なセマンティック モデルを作成する方法について説明します。
Direct Lake 用のレイクハウスの作成を開始する前に、「Direct Lake の概要」を必ずお読みください。
レイクハウスを作成する
Microsoft Fabric ワークスペースで、[新規]>[その他のオプション] を選んだ後、[データ エンジニアリング] で [Lakehouse] タイルを選択します。
[新しい lakehouse] ダイアログ ボックスで、名前を入力して、[作成] を選びます。 名前に使用できるのは英数字とアンダースコアのみです。
新しいレイクハウスが作成され、正常に開かれることを確認します。
レイクハウス で Delta テーブルを作成する
新しい レイクハウス を作成した後、Direct Lake がデータにアクセスできるように、少なくとも 1 つの Delta テーブルを作成する必要があります。 Direct Lake は Parquet 形式のファイルを読み取ることができますが、パフォーマンスを最高にするには、VORDER 圧縮方法を使ってデータを圧縮するのが最善です。 VORDER は、Power BI エンジンのネイティブ圧縮アルゴリズムを使ってデータを圧縮します。 これにより、エンジンは可能な限り速くデータをメモリに読み込むことができます。
レイクハウスにデータを読み込むには、データ パイプラインやスクリプトなど、複数のオプションがあります。 次の手順では、PySpark を使い、Azure Open Dataset に基づいてレイクハウス に Delta テーブルを追加します。
新しく作成したレイクハウスで、[ノートブックを開く] を選んでから、[新しいノートブック] を選びます。
次のコード スニペットをコピーして最初のコード セルに貼り付け、 SPARK が開いているモデルにアクセスできるようにしてから、Shift + Enter キーを押してコードを実行します。
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)コードでリモート BLOB パスが正常に出力されることを確認します。
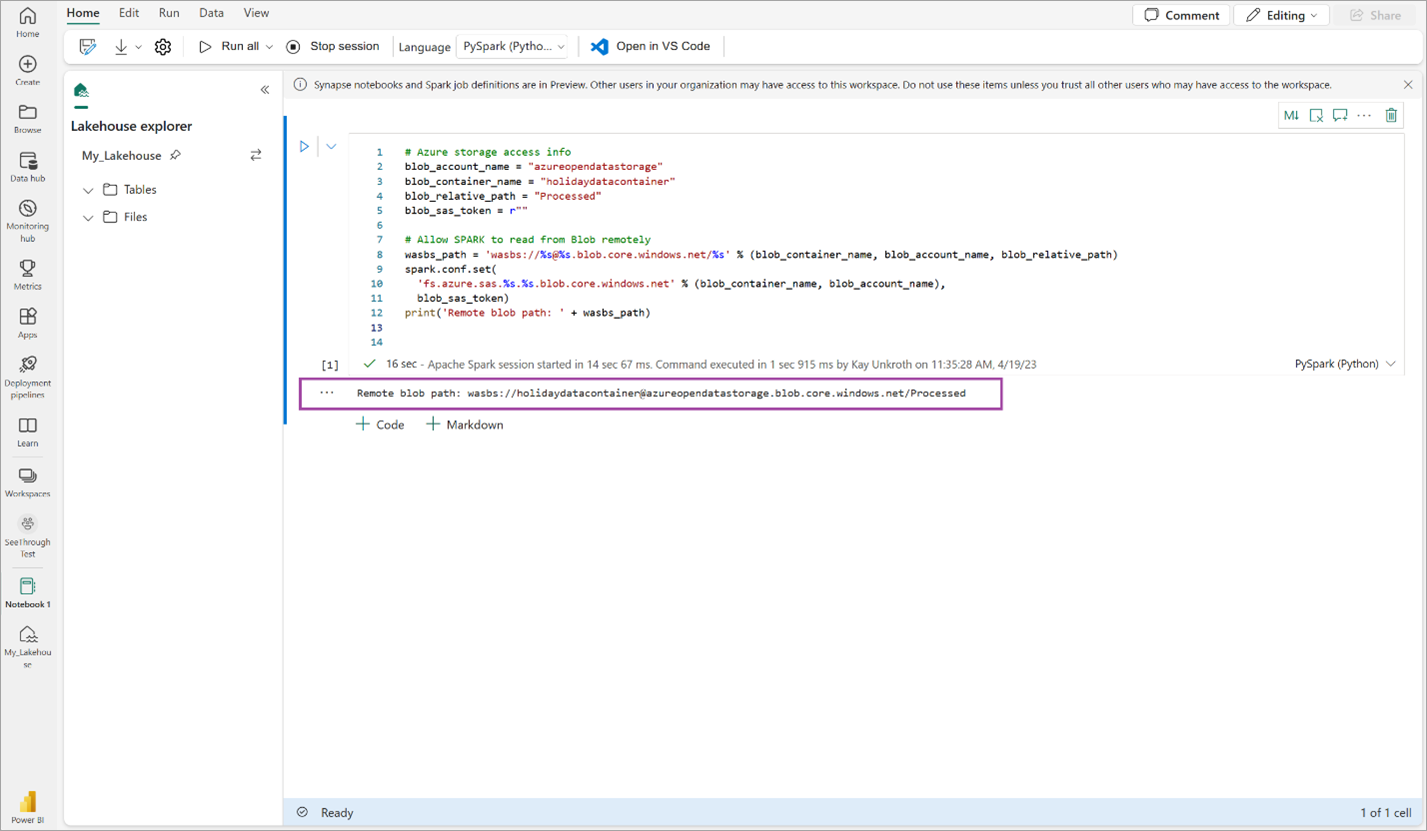
以下のコードをコピーして次のセルに貼り付け、Shift + Enter キーを押します。
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())コードで DataFrame スキーマが正常に出力されることを確認します。
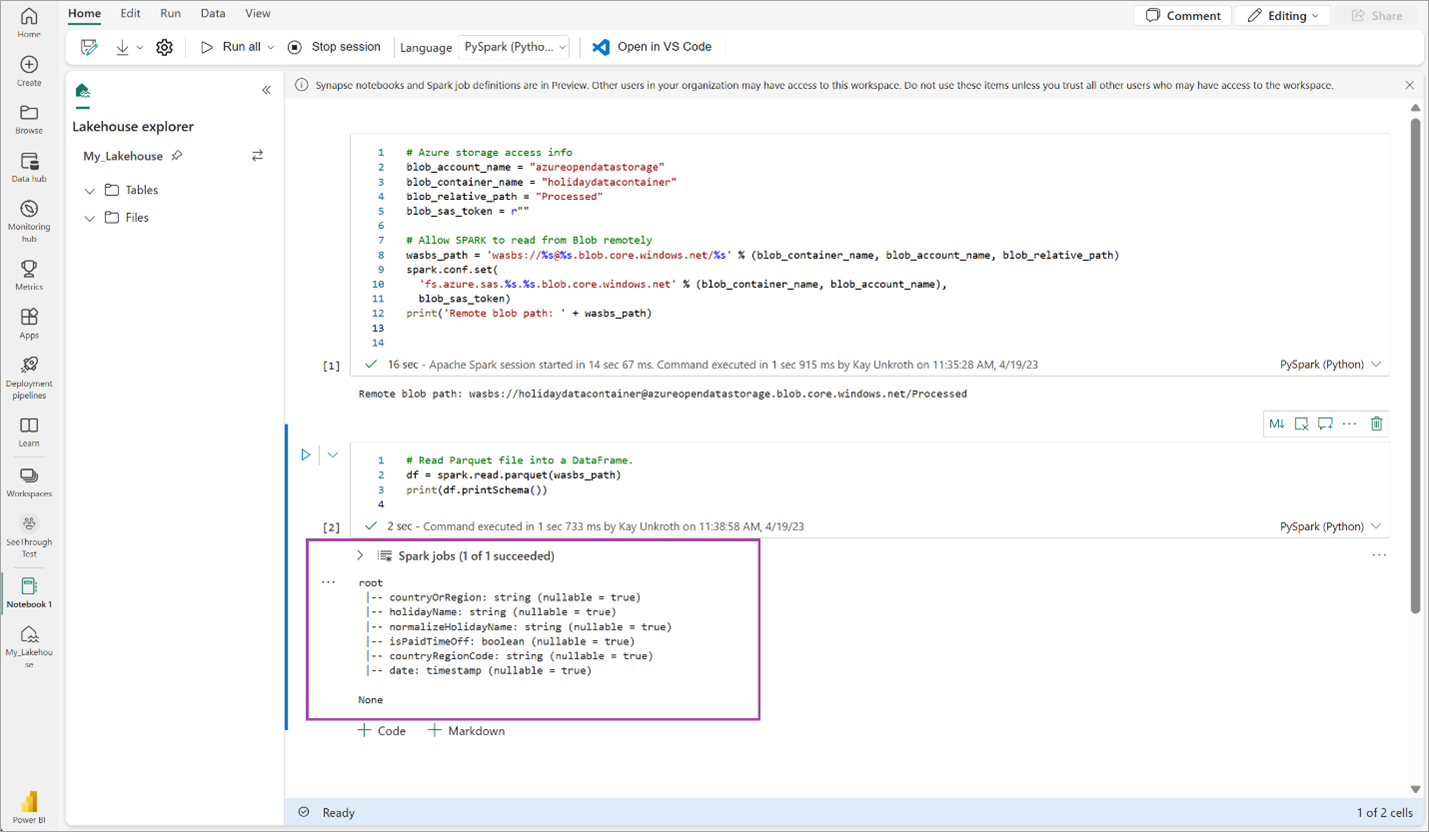
以下の行をコピーして次のセルに貼り付け、Shift + Enter キーを押します。 最初の命令によって VORDER 圧縮方法が有効になり、次の命令によって DataFrame が レイクハウス に Delta テーブルとして保存されます。
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")すべての Spark ジョブが正常に完了することを確認します。 Spark ジョブの一覧を展開して、詳細を表示します。
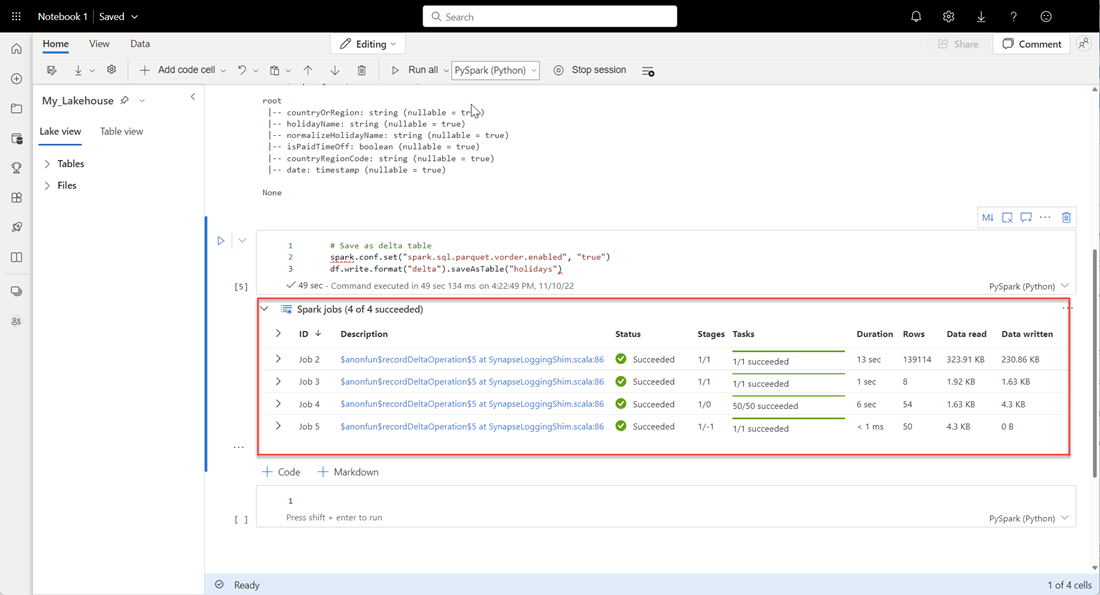
テーブルが正常に作成されたことを確認するには、左上の領域で [テーブル] の横にある省略記号 [...] を選び、[最新の情報に更新] を選んで、[テーブル] ノードを展開します。
![[[テーブル] ノードを示すスクリーンショット。](media/direct-lake-create-lakehouse/direct-lake-tables-node.png)
上記と同じ方法または他のサポートされている方法を使って、分析するデータの Delta テーブルを追加します。
レイクハウス用の基本的な Direct Lake データセットを作成する
レイクハウスで [新しいセマンティック モデル] を選択し、ダイアログでセマンティック モデルに含めるテーブルを選びます。
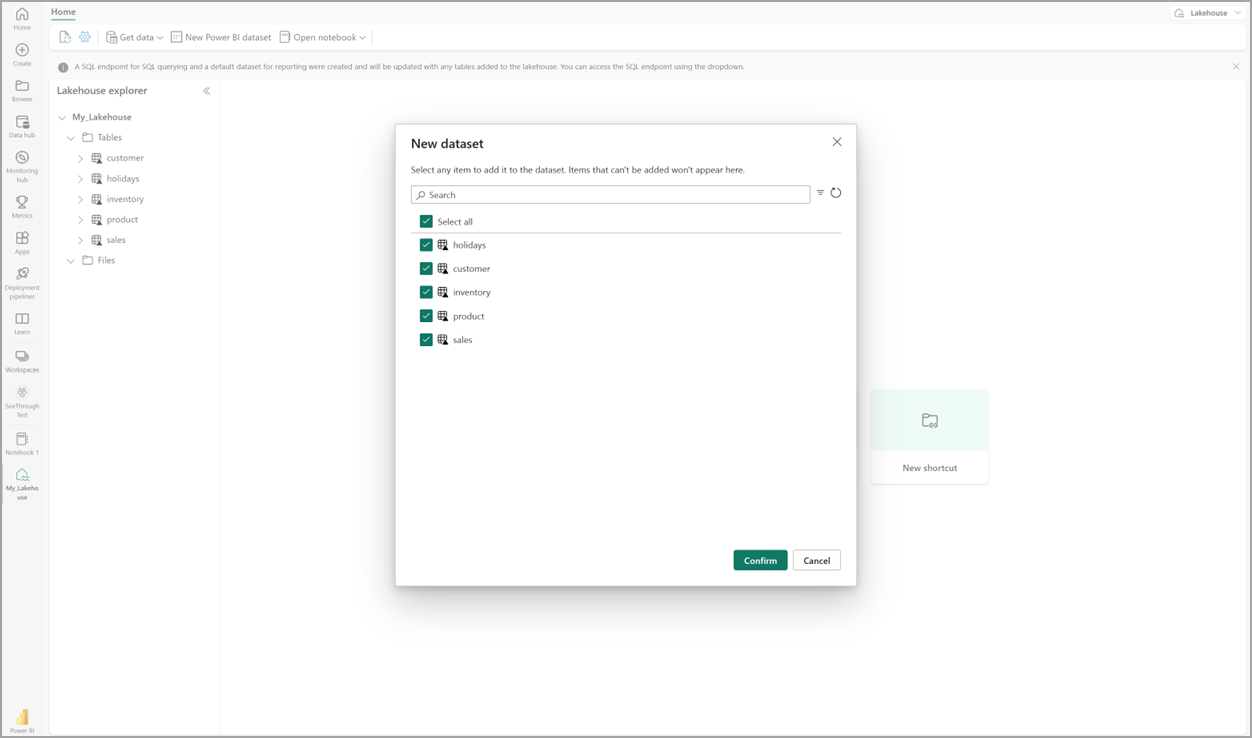
[確認] を選んで、Direct Lake のモデルを生成します。 モデルがレイクハウスの名前に基づくワークスペースに自動的に保存された後、モデルが開きます。
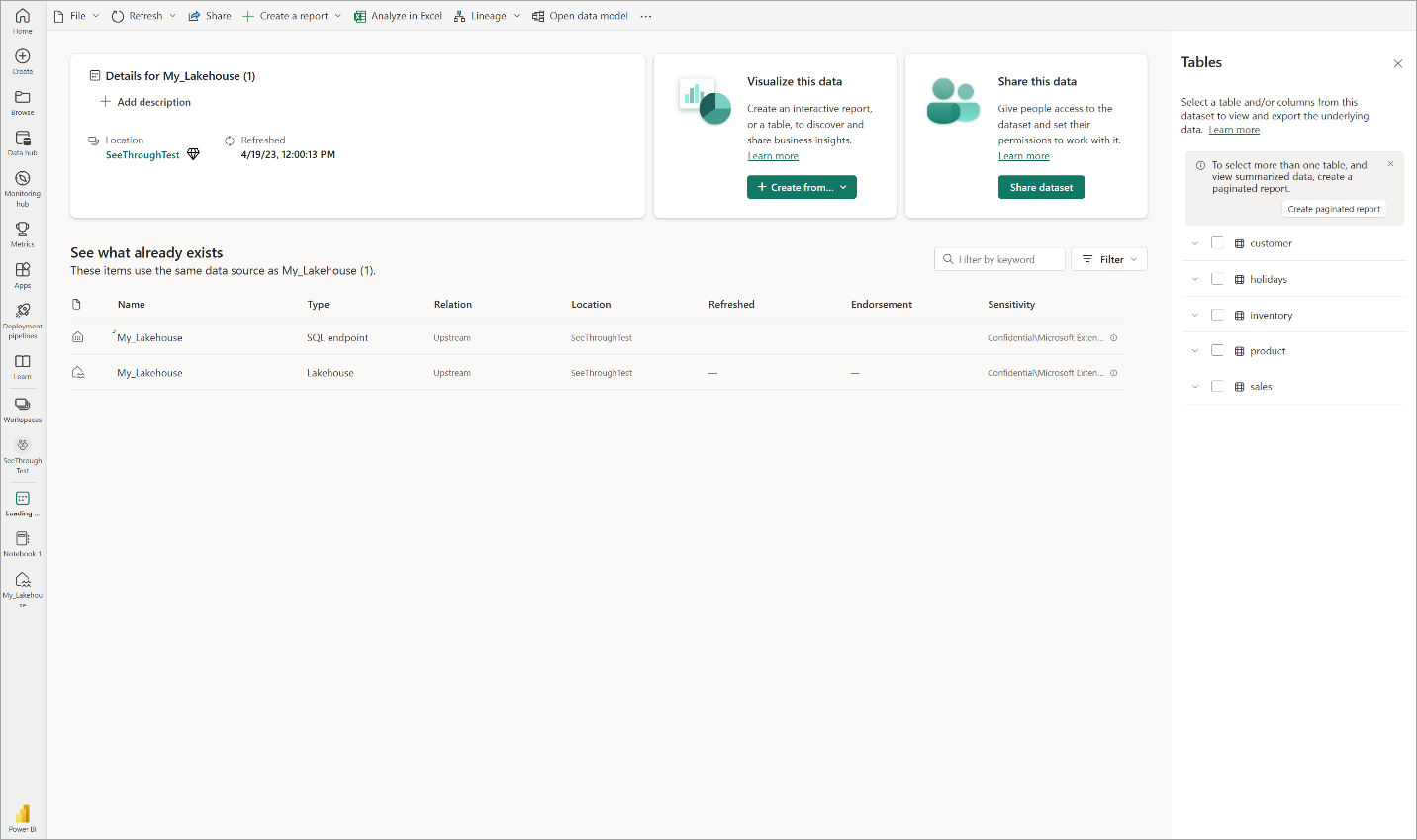
[データ モデルを開く] を選ぶと開く Web モデリング エクスペリエンスで、テーブルのリレーションシップと DAX のメジャーを追加できます。
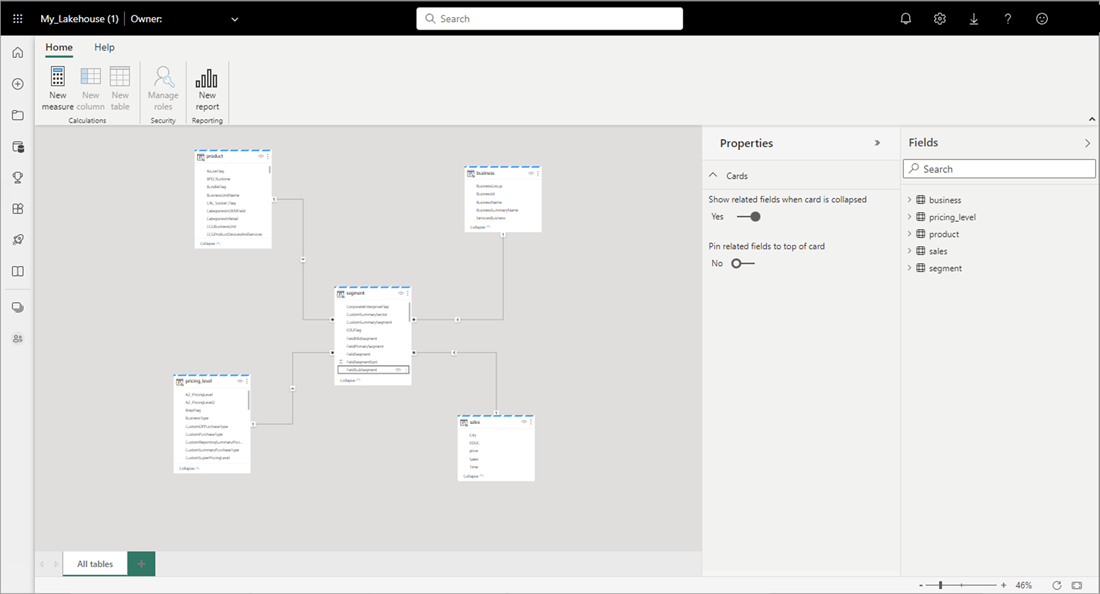
リレーションシップと DAX メジャーの追加が終わったら、他のモデルとほぼ同じ方法で、レポートの作成、複合モデルの構築、XMLA エンドポイント経由でのモデルのクエリを行うことができます。