Microsoft Syntexでエクストラクターを作成する
適用対象: ✓ 非構造化ドキュメント処理
特定のドキュメントの種類の識別および分類を自動化するために、分類子モデルを作成する前または後に、必要に応じて、ドキュメントから特定の情報を抽出するために、エクストラクターをモデルに追加することができます。 たとえば、モデルでドキュメント ライブラリに追加されたすべての契約更新ドキュメントを識別するだけでなく、ドキュメント ライブラリの列値として各ドキュメントのサービス開始日を表示することもできます。
抽出するドキュメント内の各エンティティに、エクストラクターを作成する必要があります。 この例では、モデルによって識別される各契約更新ドキュメントのサービス開始日を抽出します。 すべての コントラクト更新 ドキュメントのドキュメント ライブラリに、各ドキュメントの サービス開始日 の値を示す列を含むビューを表示できるようにする必要があります。
注:
エクストラクターを作成するには、先ほど分類子をトレーニングする目的でアップロードしたものと同ファイルを使用します。
エクストラクターに名前を付ける
モデルのホーム ページの [ 抽出器の作成とトレーニング ] タイルで、[ 抽出器のトレーニング] を選択します。
[新しいエンティティエクストラクター ] 画面で、[ 新しいエクストラクター 名] フィールドにエクストラクターの名前を入力します。 たとえば、契約更新の各ドキュメントからサービス開始日を抽出する場合は、「サービスの開始日と名前を入力します。 以前に作成した列 (例えば[管理されたメタデータ] 列など) を再使用することもできます。
既定では、列の種類は 1 行のテキストです。 列の種類を変更する場合は、[ 詳細設定>] [列の種類] を選択し、使用する種類を選択します。
![[列の種類] オプションを示す [新しいエンティティ抽出] パネルの [詳細設定] 部分のスクリーンショット。](../media/content-understanding/advanced-settings-column-type.png)
注:
列タイプが 1 行のテキストを含む抽出器の場合、最大文字数の上限は 255 です。 制限を超えて選択した文字はすべて切り捨てられます。 255 文字を超える文字を選択するには、抽出器の作成時に [複数行のテキスト 列の種類] を選択します。
既定では、 追加できるテキストの 量に制限がある複数行のテキスト列が作成されます。 この場合、抽出されたテキストが切り捨てられたように見える場合があります。 この場合、列設定 [ ドキュメント ライブラリの長さを無制限に許可する] を使用して、制限を削除できます。
完了したら、[ 作成] を選択します。
ラベルを追加する
次の手順では、サンプルトレーニングファイルで抽出するエンティティにラベルを付けます。
エクストラクターを作成すると、エクストラクターページが開きます。 ここでは、サンプルファイルの一覧が表示されます。リストの最初のファイルは、viewer に表示されています。
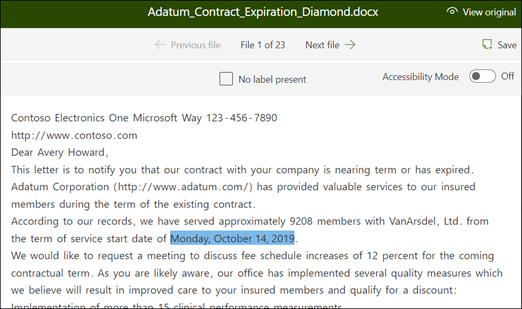
Viewer で、ファイルから抽出するデータを選択します。 たとえば、 サービス開始日を抽出する場合は、最初のファイル (2022 年 10 月 14 日月曜日) の日付値を強調表示します。 [保存] を選択 します。 ラベルの付いた [サンプル] リストにあるファイルの値を、[ ラベル ] 列で確認します。
[ 次のファイル ] を選択して自動保存し、ビューアーの一覧で次のファイルを開きます。 または、[保存] を選択し [ ラベルが付いた サンプル ] の一覧から別のファイルを選択します。
このビューアーで、手順1と2を繰り返し、5つのファイルすべてにラベルを保存します。
5個のファイルにラベルを付けたら、トレーニングに移動するように通知バナーが表示されます。 ドキュメントのラベルを追加するか、トレーニングに進めるか、選択することができます。
[検索] を使用してファイルを検索します。
検索機能を使用して、ドキュメント内でラベルを付けるエンティティを検索できます。
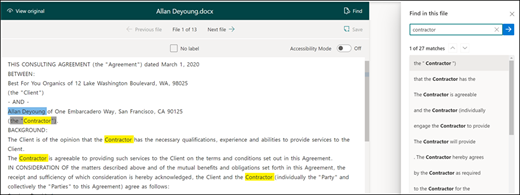
検索機能は、大規模なドキュメントを検索する場合、またはドキュメント内にエンティティの複数のインスタンスがある場合に便利です。 複数のインスタンスが見つかった場合は、検索結果から必要なインスタンスを選択して、ビューアー内のその場所に移動してラベルを付けることができます。
説明を作成する
この例では、エンティティ形式自体とサンプル ドキュメントに含まれるバリエーションに関するヒントを提供する説明を作成します。 たとえば、日付の値は、次のようないくつかの異なる形式にすることができます。
- 10/14/2022
- 2022 年 10 月 14 日
- 2022 年 10 月 14 日 (月)
サービスの開始日を特定するために、パターンの説明を作成できます。
- [説明] セクションで、[ 新しい] を選択し、名前 (例えば日付) を入力します。
- [種類] で、[ パターン一覧]を選択します。
- [値] には、サンプルファイルに表示される日付のバリエーションを入力します。 たとえば、0/00/0000 として表示される日付形式がある場合は、次のようなドキュメントに表示されるバリエーションを入力します。
- 0/0/0000
- 0/00/0000
- 00/0/0000
- 00/00/0000
- [保存] を選択します。
注:
説明の種類の詳細については、「 説明の種類」を参照してください。
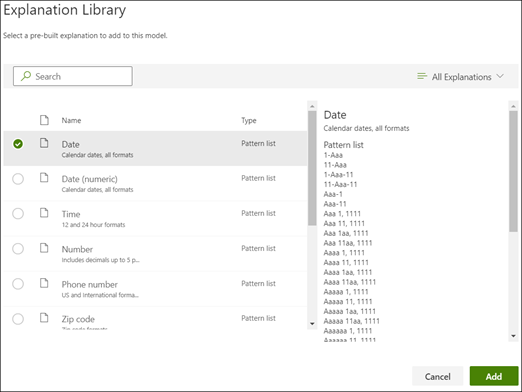
説明ライブラリを使用する
日付などの項目の説明を作成する場合は、すべてのバリエーションを手動で入力するよりも 、説明ライブラリを使用 する方が簡単です。 説明ライブラリは、あらかじめ用意されている語句やパターンの説明のセットです。 ライブラリは、日付、電話番号、郵便番号など、一般的なフレーズまたはパターン リストのすべての形式を提供しようとします。
サービス開始日のサンプルでは、説明ライブラリの Date に関する事前構築済みの説明を使用する方が効率的です。
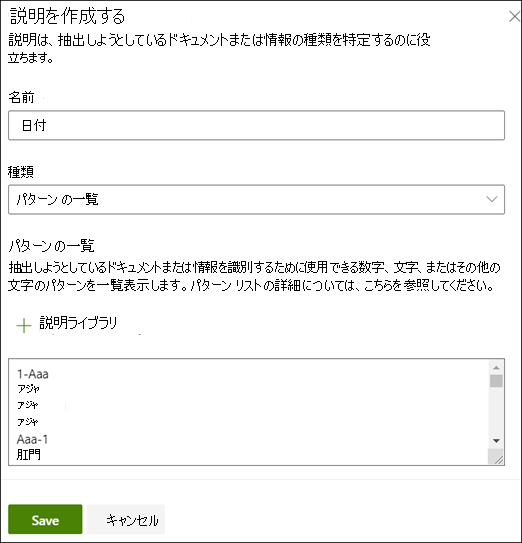
[ の説明] セクションで、[ 新規] を選択し、[説明ライブラリ から]を選択します。
[説明ライブラリ] で、[ 日付] を選択します。 認識された日付のあらゆるバリエーションを表示できます。
[追加] を選択します。
[説明を作成する ページで、説明ライブラリの 日付情報がフィールドに自動入力されます。 [保存] を選択します。
モデルをトレーニングする
説明を保存すると、トレーニングが開始されます。 ラベル付けされたサンプル ファイルからデータを抽出するのに十分な情報がモデルにある場合は、各ファイルに Match というラベルが付けられます。
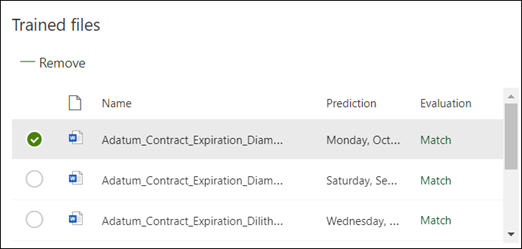
説明に抽出するデータを見つけるのに十分な情報がない場合は、各ファイルに [不一致] というラベルが付けられます。 [不一致ファイル] を選択すると、不一致が発生した理由の詳細を確認できます。
別の説明を追加する
多くの場合、不一致は、指定した説明で、ラベル付けされたファイルと一致するサービス開始日の値を抽出するのに十分な情報が提供されなかったことを示しています。 編集したり、別の説明を追加したりする必要がある場合があります。
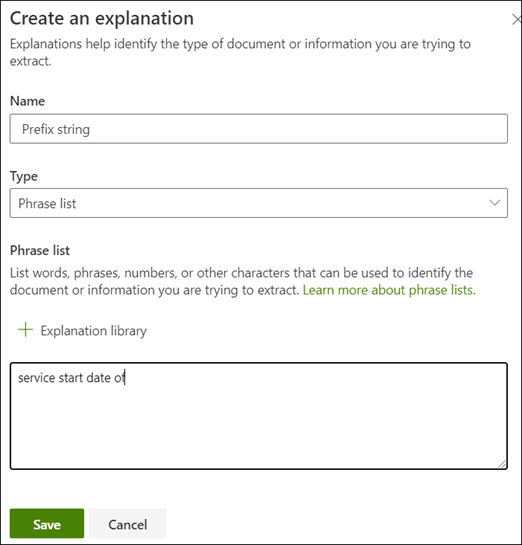
この例では、文字列 サービス開始日 が実際の値より前になることにご注意ください。 サービスの開始日を特定を容易にするには、語句の説明を作成する必要があります。
[説明] セクションで、[新しい] を選択し、名前を入力します (例: Prefix String)。
[種類] で、[ 語句のリスト] を選択します。
サービス の開始日を値として使用します。
[保存] を選択します。
モデルを再トレーニングする
説明を保存すると、トレーニングが開始されます。今回は、この2つの説明をサンプルファイルに使用します。 ラベル付けされたサンプルファイルからデータを抽出するのに十分な情報がモデルに含まれている場合は、 一致とファイルにラベルが付けられます。
ラベルが付けられたファイルの 不一致が再び表示された場合は、ドキュメントの種類を識別するための詳細な情報をさらに追加するか、または既存の説明を変更することをお考えください。
モデルをテストする
ラベル付きのサンプルファイルに対して一致が返された場合は、ラベルの付いていないその他のファイルの例でモデルをテストできます。 この手順は省略可能ですが、モデルを使用する前にモデルの "適合性" または準備状況を評価する場合に役立ちます。これは、モデルがこれまでに見たことがないファイルでテストすることで行います。
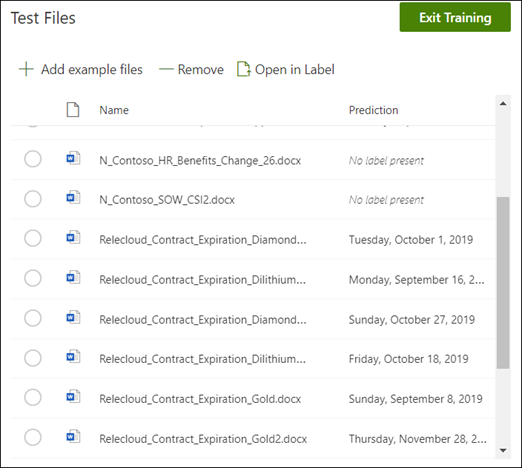
モデルのホーム ページで、[ テスト ] タブを選択します。これにより、ラベル付けされていないサンプル ファイルでモデルが実行されます。
[ テストファイル ] の一覧で、サンプルファイルから必要な情報が抽出されているかどうかが表示されます。 この情報を使用して、ドキュメントを特定するときの分類子の有効性を判断します。
抽出器をさらに絞り込む
重複するエンティティがあり、1 つの値または特定の数の値のみを抽出する場合は、処理方法を指定するルールを設定できます。 抽出された情報を絞り込むルールを追加するには、次の手順に従います。
モデルのホーム ページの [ エンティティ抽出器 ] セクションで、絞り込む抽出器を選択し、[ 抽出された情報の絞り込み] を選択します。
![[抽出された情報の絞り込み] オプションが強調表示されている [エンティティ抽出器] セクションのスクリーンショット。](../media/content-understanding/refine-extracted-info.png)
[ 抽出された情報の絞り込み ] ページで、次のいずれかの規則を選択します。
- 最初の値の 1 つ以上を保持する
- 最後の値の 1 つ以上を保持する
- 重複する値の削除
- 最初の行の 1 つ以上を保持する
- 最後の行の 1 つ以上を保持する
![ルール オプションを示す [抽出された情報の絞り込み] ページのスクリーンショット。](../media/content-understanding/refine-extracted-info-page.png)
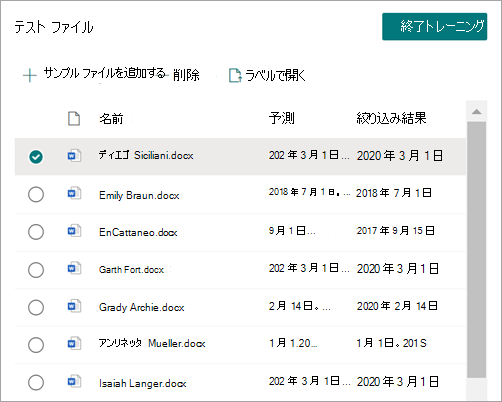
使用する行または値の数を入力し、[ 絞り込み] を選択します。
行または値の数を変更してルールを編集する場合は、編集する抽出器を選択し、[ 抽出された情報を絞り込む] を選択し、番号を変更して、[保存] を選択 します。
抽出器をテストすると、[テスト ファイル] リストの [絞り込み結果] 列に絞り込みを表示できます。
抽出器で絞り込みルールを削除する場合は、ルールを削除する抽出元を選択し、[ 抽出された情報の絞り込み] を選択して、[削除] を選択 します。
関連項目
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示