ベースラインとパフォーマンス履歴を使用して、Office 365 のパフォーマンスをチューニングする
Office 365とビジネスの間の接続パフォーマンスをチェックする簡単な方法がいくつかあります。これによって、接続の大まかなベースラインを確立できます。 クライアント コンピューター接続のパフォーマンス履歴を把握すると、新しい問題の早期検出、問題の特定、予測に役立ちます。
パフォーマンスの問題に取り組むのに慣っていない場合、この記事は、一般的な質問を検討するのに役立つよう設計されています。 発生している問題がパフォーマンスの問題であり、Office 365サービス インシデントではないことはどのようにわかりますか? どのように良いパフォーマンス、長期的な計画を立てることができますか? パフォーマンスを見守るにはどうすればよいですか? Office 365の使用中にチームまたはクライアントのパフォーマンスが低下していて、これらの質問について疑問に思う場合は、お読みください。
重要
現在、クライアントとOffice 365の間にパフォーマンスの問題がありますか? Office 365のパフォーマンストラブルシューティング計画に記載されている手順に従います。
Office 365パフォーマンスについて知っておくべきこと
Office 365は、自動化と実際のユーザーによって監視される大容量の専用 Microsoft ネットワーク内に存在します。 Office 365 クラウドの保守の一部として、可能な場合はパフォーマンスのチューニングと合理化が行われます。 Office 365 クラウドのクライアントはインターネット経由で接続する必要があるため、Office 365 サービス全体のパフォーマンスを微調整する取り組みも進行中です。
パフォーマンスの向上がクラウドで実際に停止することはありません。そのため、クラウドを正常かつ迅速に維持する経験はありません。 場所からOffice 365への接続でパフォーマンスの問題が発生した場合は、サポート ケースから始めたり待ったりしないことをお勧めします。 代わりに、問題の調査を '内側のアウト' から開始する必要があります。 つまり、ネットワーク内から開始し、Office 365に向けて作業を進めます。 サポートでケースを開く前に、データを収集し、問題を調査して解決する可能性のあるアクションを実行できます。
重要
Office 365での容量計画と制限に注意してください。 この情報を使用すると、パフォーマンスの問題を解決しようとするときに、先に進みます。 Microsoft 365 と Office 365 サービスの説明へのリンクを次に示します。 これは中央のハブであり、Office 365によって提供されるすべてのサービスには、ここから独自のサービスの説明に移動するリンクがあります。 つまり、SharePoint の標準の制限を確認する必要がある場合は、たとえば、[ SharePoint サービスの説明 ] をクリックして SharePoint の [制限] セクションを見つけます。
パフォーマンスがスライディング スケールであることを理解して、トラブルシューティングに進む必要があります。 理想化された価値を達成し、永続的に維持することではありません。 多数のユーザーのオンボーディングや大規模なデータ移行などの高帯域幅のタスクは負荷が高いため、パフォーマンスへの影響を 計画 します。 パフォーマンス目標の概念はありますが、多くの変数がパフォーマンスに影響するため、パフォーマンスは異なります。
パフォーマンスのトラブルシューティングは、特定の目標を達成し、それらの数値を無期限に維持することではなく、すべての変数を使用して既存のアクティビティを改善することです。
さて、パフォーマンスの問題はどのように見えますか?
まず、発生している内容が実際にパフォーマンスの問題であり、サービス インシデントではないことを確認する必要があります。 パフォーマンスの問題は、Office 365のサービス インシデントとは異なります。 それらを区別する方法を次に示します。
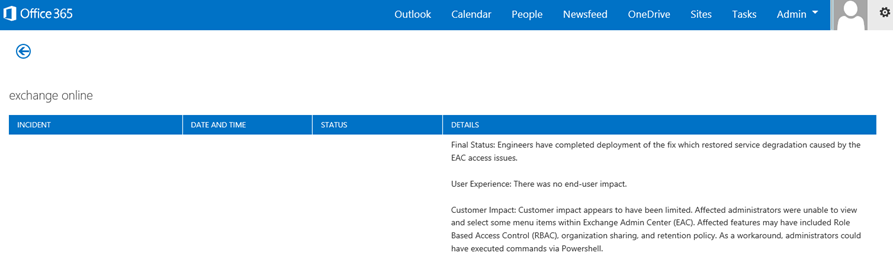
サービス インシデントは、Office 365 サービス自体に問題がある場合に発生します。 Microsoft 365 管理センターの [現在の正常性] に赤または黄色のアイコンが表示される場合があります。 Office 365に接続しているクライアント コンピューターのパフォーマンスが低下している可能性があります。 たとえば、現在の正常性で赤いアイコンが報告され、Exchange の横に [調査中] と表示された場合は、Exchange Onlineを使用してクライアント メールボックスが遅いと苦情を申し立てるorganizationのユーザーから通話を受け取る場合もあります。 その場合は、Exchange Onlineのパフォーマンスがサービスの問題の被害を受けたと考えるのが妥当です。
![[Office 365正常性] ダッシュボードで、Exchange を除くすべてのワークロードが緑色で表示されます。このダッシュボードには、Service Restored が表示されます。](../media/ec7f0325-9e61-4e1a-bec0-64b87f4469be.png?view=o365-worldwide)
この時点で、Office 365管理者は、[現在の正常性] をチェックし、詳細と履歴 (多くの場合) を表示して、システムのメンテナンスを最新の状態に保つ必要があります。 [現在の正常性] ダッシュボードは、サービスの変更と問題について更新するために作成されました。 正常性履歴、管理者から管理者に書き込まれたメモと説明は、測定に役立ち、進行中の作業について投稿し続けるのに役立ちます。
パフォーマンスの問題は、インシデントによってパフォーマンスが低下する可能性がありますが、サービス インシデントではありません。 パフォーマンスの問題は次のようになります。
管理センター の現在の正常性 がサービスのレポートに関係なく、パフォーマンスの問題が発生します。
フローに使用された動作は、完了するまでに長い時間がかかるか、完了しない場合があります。
問題をレプリケートすることも、適切な一連の手順を実行した場合に発生する可能性もあります。
問題が断続的な場合は、パターンが存在する可能性があります。 たとえば、午前 10 時までに、Office 365に常にアクセスできないユーザーからの呼び出しが行われることがわかります。 呼び出しは正午頃に終了します。
このリストは、おそらくよく知られていると思います。もしかしたら馴染みすぎるかもしれません。 パフォーマンスの問題であることを認識すると、質問は "次に何をしますか?この記事の残りの部分は、正確に判断するのに役立ちます。
パフォーマンスの問題を定義してテストする方法
パフォーマンスの問題は時間の経過と同時に発生することが多いため、実際の問題を定義するのは困難な場合があります。 問題コンテキストの良いアイデアを持つ適切な問題ステートメントをCreateし、繰り返し可能なテスト手順を実行する必要があります。 十分な情報を提供しない問題ステートメントの例を次に示します。
受信トレイから予定表に切り替えることは、以前は気付かなかったものであり、今ではコーヒーブレイクです。 以前と同じように動作させることができますか?
ファイルを SharePoint にアップロードすると、永久に時間がかかっています。 なぜ午後は遅いですが、他の時間は速いですか? それは速いだけではできないのですか?
上記の問題ステートメントによってもたらされるいくつかの大きな課題があります。 具体的には、扱うあいまいさが多すぎます。 例:
受信トレイと予定表の切り替えがどのようにノート PC で動作したかは不明です。
ユーザーが "高速ではいけない" と言うと、"高速" とは何ですか?
"永遠" の期間はどのくらいですか? 数秒ですか? または数分? または、ユーザーは昼食を取ることができ、アクションは戻ってから 10 分後に完了しますか?
管理者とトラブルシューティング ツールは、このような一般的なステートメントから問題の 詳細 を認識できません。 たとえば、問題がいつ発生し始めたのかはわかりません。 トラブルシューティング ツールは、ユーザーが自宅で動作することを知らず、ホーム ネットワーク上の間の切り替えが遅い場合にのみ表示される場合があります。 または、ユーザーがローカル クライアントで他の RAM 集中型アプリケーションを実行していること。 管理者は、ユーザーが古いオペレーティング システムを実行しているか、最近の更新プログラムを実行していない可能性があります。
ユーザーがパフォーマンスの問題を報告すると、収集する情報が多くなります。 情報の取得と記録は、問題のスコープと呼ばれます。 パフォーマンスの問題に関する情報を収集するために使用できる基本的なスコープリストを次に示します。 この一覧は網羅的ではありませんが、開始する場所です。
問題は何日に発生し、昼と夜の時間帯を中心にしていますか?
どのような種類のクライアント コンピューターを使用していて、ビジネス ネットワーク (VPN、有線、ワイヤレス) に接続する方法
あなたはリモートで作業していましたか、それともオフィスにいましたか?
別のコンピューターで同じ操作を試して、同じ動作を確認しましたか?
取り下げるアクションを記述できるように、問題が発生する手順について説明します。
パフォーマンスは数秒または数分でどのくらい遅くなりますか?
世界のどこにありますか?
これらの質問の中には、他の質問よりも明白なものもあります。 ほとんどの場合、トラブルシューティング ツールには問題を再現するための正確な手順が必要です。 結局のところ、問題を記録する方法と、問題が修正されたかどうかをテストする方法は何ですか? "問題が表示された日時は何ですか"、"世界のどこにありますか?" のような情報は、同時に使用できる情報です。 ユーザーが作業していた時間によっては、数時間の時間差によって、会社のネットワークの一部でメンテナンスが既に進行中である可能性があります。 たとえば、会社にはハイブリッド SharePoint Searchなどのハイブリッド実装があり、Microsoft 365 の SharePoint とオンプレミスの SharePoint Server 2013 インスタンスの両方で検索インデックスを照会できるため、オンプレミス ファームで更新が進行中である可能性があります。 会社がすべてクラウドに存在する場合、システム メンテナンスには、ネットワーク ハードウェアの追加または削除、会社全体の更新プログラムのロールアウト、DNS またはその他のコア インフラストラクチャへの変更が含まれる場合があります。
パフォーマンスの問題のトラブルシューティングを行う場合は、犯罪現場に少し似ています。証拠から結論を導き出すには、正確かつ注意が必要です。 これを行うには、証拠を収集して良い問題の声明を得る必要があります。 これには、コンピューターのコンテキスト、ユーザーのコンテキスト、問題が開始されたとき、およびパフォーマンスの問題を公開した正確な手順が含まれている必要があります。 この問題ステートメントは、ノートの一番上のページである必要があります。 解決に取り組んだ後に問題ステートメントをもう一度説明することで、実行したアクションが問題を解決したかどうかをテストして証明する手順を実行します。 これは、作業がいつ完了したかを知るために重要です。
パフォーマンスが良かったときに見える方法を知っていますか?
運がよければ、誰も知らない。 誰も番号を持っていませんでした。 つまり、「Office 365で受信トレイを起動するのにかかった時間は何秒でしたか」という単純な質問や、「エグゼクティブが Lync Online 会議を行ったときにどのくらいの時間がかかったか」という簡単な質問には答えられませんでした。これは、多くの企業にとって一般的なシナリオです。
ここで見つからないのは、パフォーマンス ベースラインです。
ベースラインは、パフォーマンスのコンテキストを提供します。 会社のニーズに応じて、ベースラインを頻繁に行う必要があります。 大企業の場合、運用チームはオンプレミス環境のベースラインを既に使用している可能性があります。 たとえば、月の最初の月曜日にすべての Exchange サーバーにパッチを適用し、3 番目の月曜日にすべての SharePoint サーバーにパッチを適用した場合、オペレーション チームは、重要な機能が動作していることを証明するために、パッチ適用後に実行されるタスクとシナリオの一覧を持っている可能性があります。 たとえば、受信トレイを開き、[送受信] をクリックしてフォルダーを更新するか、SharePoint でサイトのメイン ページを参照し、エンタープライズ Search ページに移動し、結果を返す検索を実行します。
アプリケーションがOffice 365にある場合、最も基本的なベースラインの一部は、ネットワーク内のクライアント コンピューターからエグレス ポイント、またはネットワークを離れてOffice 365に出るポイントまでの時間 (ミリ秒) を測定できます。 調査して記録できる便利なベースラインを次に示します。
クライアント コンピューターとエグレス ポイント (プロキシ サーバーなど) の間のデバイスを特定します。
発生するパフォーマンスの問題に関するコンテキスト (IP アドレス、デバイスの種類、cetera など) を持つデバイスを把握する必要があります。
プロキシ サーバーは一般的なエグレス ポイントであるため、Web ブラウザーをチェックして、使用するように設定されているプロキシ サーバー (存在する場合) を確認できます。
ネットワークを検出してマップできるサードパーティ製のツールがありますが、デバイスを知る最も安全な方法は、ネットワーク チームのメンバーに依頼することです。
インターネット サービス プロバイダー (ISP) を特定し、連絡先情報を書き留めて、帯域幅の数を確認します。
社内で、クライアントとエグレス ポイントの間のデバイスのリソースを特定するか、ネットワークの問題について話す緊急連絡先を特定します。
ツールを使用した単純なテストで計算できるベースラインを次に示します。
クライアント コンピューターからエグレス ポイントまでの時間 (ミリ秒単位)
エグレス ポイントからOffice 365までの時間 (ミリ秒単位)
参照時にOffice 365の URL を解決するサーバーの世界の場所
ISP の DNS 解決の速度 (ミリ秒単位)、パケット到着の不整合 (ネットワーク ジッター)、アップロード、ダウンロード時間 (ミリ秒単位)
これらの手順を実行する方法に慣れていない場合は、この記事で詳しく説明します。
ベースラインとは
問題が発生した場合の影響はわかりますが、過去のパフォーマンス データがわからない場合は、パフォーマンスがどれだけ悪くなったか、いつになるかを示すコンテキストを持つことはできません。 そのため、ベースラインがなければ、パズルを解決するための重要な手がかりが見つかりません:パズルボックス上の画像。 パフォーマンスのトラブルシューティングでは、 比較のポイントが必要です。 単純なパフォーマンス ベースラインは、取りにくいわけではありません。 運用チームは、スケジュールに従ってこれらを実行する必要があります。 たとえば、接続が次のようになります。
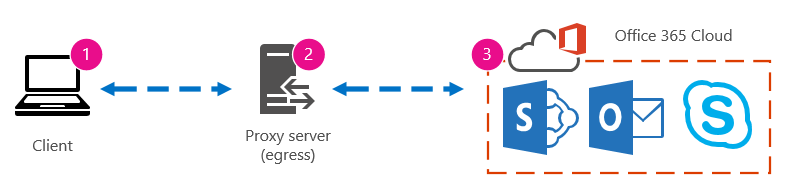
つまり、ネットワーク チームに確認し、プロキシ サーバーを介してインターネットに会社を辞め、クライアント コンピューターがクラウドに送信するすべての要求をプロキシが処理していることがわかりました。 この場合は、介在するすべてのデバイスを一覧表示する接続の簡略化されたバージョンを描画する必要があります。 次に、クライアント、エグレス ポイント (インターネット用にネットワークを離れる場所)、およびOffice 365 クラウドの間のパフォーマンスをテストするために使用できるツールを挿入します。
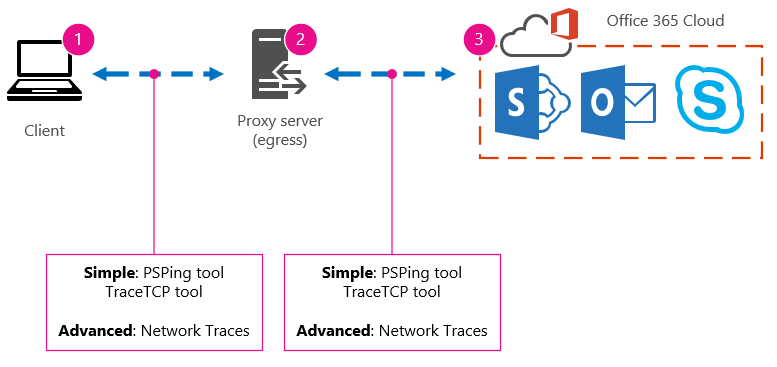
オプションは、パフォーマンス データを見つけるために必要な専門知識の量のため 、Simple と Advanced として一覧表示されます。 ネットワーク トレースには、PsPing や TraceTCP などのコマンド ライン ツールを実行する場合と比較して、多くの時間がかかります。 これら 2 つのコマンド ライン ツールは、ICMP パケットを使用しないために選択されました。これは、Office 365によってブロックされます。また、クライアント コンピューターまたはプロキシ サーバー (アクセス権がある場合) を離れてOffice 365に到着するまでにかかる時間がミリ秒単位であるためです。 1 台のコンピューターから別のコンピューターへのホップごとに時間値が設定され、ベースラインに最適です。 重要なことに、これらのコマンド ライン ツールを使用すると、コマンドにポート番号を追加できます。これは、Office 365が Secure Sockets Layer と Transport Layer Security (SSL および TLS) で使用されるポートであるポート 443 経由で通信するため便利です。 ただし、他のサード パーティ製ツールは、状況に応じてより優れたソリューションになる場合があります。 Microsoft はこれらのツールをすべてサポートしていないので、何らかの理由で PsPing と TraceTCP を動作させることができない場合は、Netmon などのツールを使用してネットワーク トレースに進みます。
営業時間の前にベースラインを取得し、再び大量の使用時に、次に数時間後に再び使用できます。 つまり、最終的には次のようなフォルダー構造が存在する可能性があります。

ファイルの名前付け規則も選択する必要があります。 次に、いくつかの例を示します:
Feb_09_2015_9amPST_PerfBaseline_Netmon_ClientToEgress_Normal
Jan_10_2015_3pmCST_PerfBaseline_PsPing_ClientToO365_bypassProxy_SLOW
Feb_08_2015_2pmEST_PerfBaseline_BADPerf
Feb_08_2015_8-30amEST_PerfBaseline_GoodPerf
これを行うにはさまざまな方法がありますが、dateTime><という形式<を使用すると、テスト>で何が起こっているかから始めるのに適しています。 これについて熱心に取り組むと、後で問題のトラブルシューティングを行う際に大いに役立ちます。 その後、「2 月 8 日に 2 つのトレースを取り、1 つは良いパフォーマンスを示し、1 つは悪い結果を示したので、比較することができます」と言うことができます。 これはトラブルシューティングに役立ちます。
履歴ベースラインを維持するには、整理された方法が必要です。 この例では、単純なメソッドで 3 つのコマンド ライン出力が生成され、結果がスクリーンショットとして収集されましたが、代わりにネットワーク キャプチャ ファイルが作成されている可能性があります。 最適なメソッドを使用します。 履歴ベースラインを保存し、オンライン サービスの動作の変化に気付いた時点で参照します。
パイロット中にパフォーマンス データを収集する理由
Office 365 サービスのパイロット中よりもベースラインの作成を開始する時間は、これ以上ありません。 オフィスには何千人ものユーザー、数十万人、または 5 人のユーザーがいる場合がありますが、少数のユーザーでもテストを実行してパフォーマンスの変動を測定できます。 大企業の場合、Office 365をパイロットする数百人のユーザーの代表的なサンプルを数千人に外向きに投影できるため、問題が発生する前に発生する可能性がある場所を把握できます。
小規模企業の場合、オンボーディングでは、すべてのユーザーが同時にサービスにアクセスし、パイロットがいない場合は、パフォーマンス対策を維持して、パフォーマンスの悪い操作のトラブルシューティングを行う必要がある可能性のあるすべてのユーザーにデータを表示します。 たとえば、突然建物の周りを歩き回ることができる場合は、以前はすばやく発生した中規模のグラフィックをアップロードするのに時間がかかります。
ベースラインを収集する方法
すべてのトラブルシューティング 計画では、少なくとも次のことを識別する必要があります。
使用しているクライアント コンピューター (コンピューターまたはデバイスの種類、IP アドレス、問題の原因となったアクション)
クライアント コンピューターが世界のどこにあるか (たとえば、このユーザーがネットワークへの VPN 上にあるか、リモートで作業しているか、会社のイントラネット上にあるか)
クライアント コンピューターがネットワークから使用するエグレス ポイント (トラフィックが ISP またはインターネットのビジネスを離れるポイント)
ネットワークのレイアウトは、ネットワーク管理者から確認できます。 小規模なネットワークを使用している場合は、インターネットに接続しているデバイスを確認し、レイアウトに関する質問がある場合は ISP に問い合わせてください。 参照の最終的なレイアウトのグラフィックをCreateします。
このセクションは、簡単なコマンド ライン ツールとメソッド、およびより高度なツール オプションに分かれています。 最初に簡単な方法について説明します。 ただし、現在パフォーマンスの問題が発生している場合は、高度な方法に進み、サンプルのパフォーマンストラブルシューティング アクション プランを試す必要があります。
単純なメソッド
これらの簡単な方法の目的は、時間の経過に伴う単純なパフォーマンス ベースラインの取得、理解、適切な格納を学習し、Office 365パフォーマンスについて通知できるようにすることです。 前に説明したように、単純な単純な図を次に示します。
注:
TraceTCP は、要求の処理にかかる時間 (ミリ秒単位)、1 台のコンピューターから次のコンピューターへの接続数を示すのに便利なツールであるため、TraceTCP が含まれています。 TraceTCP では、ホップ中に使用されるサーバーの名前を指定することもできます。これは、サポートのMicrosoft Office 365トラブルシューティング ツールに役立ちます。 > TraceTCP コマンドは、次のような非常に単純な場合があります。 >tracetcp.exe outlook.office365.com:443> コマンドにポート番号を含めてください。 >TraceTCP は無料ダウンロードですが、Wincap に依存しています。 Wincap は、Netmon によっても使用およびインストールされるツールです。 また、高度なメソッドのセクションでは Netmon も使用します。
複数のオフィスがある場合は、クライアントからの一連のデータもそれらの場所に保持する必要があります。 このテストでは待機時間を測定します。この場合は、クライアントが要求をOffice 365に送信してから要求に応答するまでの時間を表す数値値Office 365。 テストは、クライアント コンピューター上のドメイン内で発生し、ネットワーク内からエグレス ポイント経由で、インターネット経由でOffice 365、戻るラウンド トリップを測定します。
エグレス ポイント (この場合はプロキシ サーバー) に対処するには、いくつかの方法があります。 1 から 2、2 から 3 までトレースし、ミリ秒単位で数値を追加して、最終的な合計をネットワークの端に取得できます。 または、Office 365 アドレスのプロキシをバイパスするように接続を構成することもできます。 ファイアウォール、リバース プロキシ、または 2 つの組み合わせがある大規模なネットワークでは、トラフィックが多数の URL に対して通過できるようにするプロキシ サーバーで例外を作成する必要がある場合があります。 Office 365で使用されるエンドポイントの一覧については、「OFFICE 365 URL と IP アドレス範囲」を参照してください。 認証プロキシがある場合は、まず次の例外をテストします。
ポート 80 と 443
TCP と HTTP
次のいずれかの URL に送信されるConnections。
*.microsoftonline.com
*.microsoftonline-p.com
*.sharepoint.com
*.outlook.com
*.lync.com
osub.microsoft.com
プロキシの干渉や認証を行わずに、すべてのユーザーがこれらのアドレスにアクセスできるようにする必要があります。 小規模なネットワークでは、Web ブラウザーのプロキシ バイパス リストにこれらを追加する必要があります。
インターネット エクスプローラーのプロキシ バイパス リストにこれらを追加するには、[ツール>] [インターネット オプション]、[LAN の>設定>Connections詳細設定] の順に>移動します。 [詳細設定] タブには、プロキシ サーバーとプロキシ サーバー ポートもあります。 [詳細設定] ボタンにアクセスするには、[LAN のプロキシ サーバーを使用する] チェック ボックスをオンにする必要がある場合があります。 [ ローカル アドレスのプロキシ サーバーをバイパスする] がオンになっていることを確認します。 [詳細設定] を選択すると、例外を入力できるテキスト ボックスが表示されます。 上に示したワイルドカード URL をセミコロンで区切ります(例:
*.microsoftonline.com;*.sharepoint.com
プロキシをバイパスすると、Office 365 URL で ping または PsPing を直接使用できるようになります。 次の手順では、ping outlook.office365.com をテストします。 または、PsPing またはコマンドにポート番号を指定できる別のツールを使用している場合は、 portal.microsoftonline.com:443 に対して PsPing を実行して、平均ラウンドトリップ時間 (ミリ秒) を確認します。
ラウンドトリップ時間 (RTT) は、outlook.office365.com などのサーバーに HTTP 要求を送信し、サーバーが行ったことを確認する応答を返すのにかかる時間を測定する数値値です。 これは RTT と省略される場合があります。 これは比較的短い時間である必要があります。
このテストを行うには、PSPing または Office 365 によってブロックされる ICMP パケットを使用しない別のツールを使用する必要があります。
PsPing を使用して、Office 365 URL から直接、全体的なラウンド トリップ時間をミリ秒単位で取得する方法
次の手順を実行して、管理者特権のコマンド プロンプトを実行します。
[開始] をクリックします。
[スタート Search] ボックスに「cmd」と入力し、Ctrl キーを押しながら Shift キーを押しながら Enter キーを押します。
[ユーザー アカウント制御] ダイアログ ボックスが表示された場合、このボックスに希望する動作が表示されていることを確認し、[継続] をクリックします。
ツール (この場合は PsPing) がインストールされているフォルダーに移動し、次のOffice 365 URL をテストします。
psping admin.microsoft.com:443
psping microsoft-my.sharepoint.com:443
psping outlook.office365.com:443
psping www.yammer.com:443
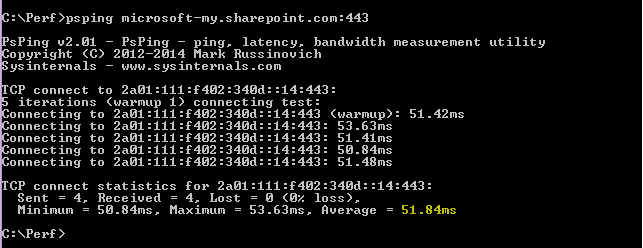
必ず 443 のポート番号を含めます。 Office 365は暗号化されたチャネルで動作します。 ポート番号を指定せずに PsPing を実行すると、要求は失敗します。 短いリストに ping を実行したら、平均時間 (ミリ秒単位) を探します。 それはあなたが記録したいものです!
プロキシ バイパスに慣れていない場合、手順を追って実行する場合は、まずプロキシ サーバーの名前を確認する必要があります。 [インターネット エクスプローラー] で、[ツール>] [インターネット オプション] Connections>[LAN 設定>] [詳細設定] の順に>移動します。 [ 詳細設定 ] タブには、プロキシ サーバーが一覧表示されます。 このタスクを完了して、コマンド プロンプトでそのプロキシ サーバーに ping を実行します。
プロキシ サーバーに ping を実行し、ステージ 1 から 2 のラウンド トリップ値をミリ秒単位で取得するには
次の手順を実行して、管理者特権のコマンド プロンプトを実行します。
[開始] をクリックします。
[スタート Search] ボックスに「cmd」と入力し、Ctrl キーを押しながら Shift キーを押しながら Enter キーを押します。
[ユーザー アカウント制御] ダイアログ ボックスが表示された場合、このボックスに希望する動作が表示されていることを確認し、[継続] をクリックします。
ブラウザーで使用するプロキシ サーバーの名前またはプロキシ> サーバーの IP アドレスに「ping」<と入力し、Enter キーを押します。 PsPing またはその他のツールがインストールされている場合は、代わりにそのツールを使用できます。
コマンドは、次のいずれかの例のようになります。
ping ourproxy.ourdomain.industry.business.com
ping 155.55.121.55
ping ourproxy
psping ourproxy.ourdomain.industry.business.com:80
psping 155.55.121.55:80
psping ourproxy:80
- トレースがテスト パケットの送信を停止すると、平均 (ミリ秒単位) の一覧が表示される小さな概要が表示されます。これは、後の値です。 プロンプトのスクリーンショットを撮り、名前付け規則を使用して保存します。 この時点で、ダイアグラムに値を入力するのにも役立つ場合があります。
早朝にトレースを取得した可能性があり、クライアントはプロキシ (またはインターネットに出るエグレス サーバー) にすばやくアクセスできます。 この場合、数値は次のようになります。
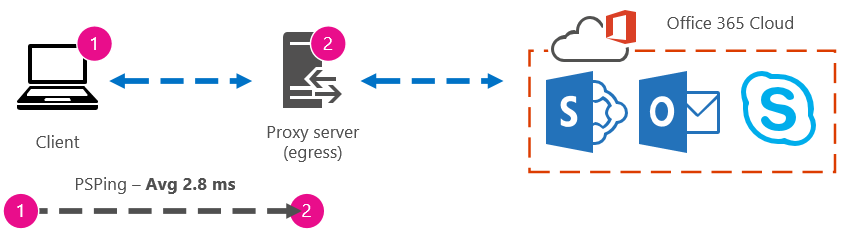
クライアント コンピューターがプロキシ (またはエグレス) サーバーにアクセスできる少数のクライアント コンピューターの 1 つである場合は、そのコンピューターにリモート接続して、そこから Office 365 URL に PsPing コマンド プロンプトを実行することで、テストの次の脚を実行できます。 そのコンピューターにアクセスできない場合は、ネットワーク リソースに問い合わせて次の脚に関するヘルプを確認し、その方法で正確な数値を取得できます。 不可能な場合は、問題のOffice 365 URL に対して PsPing を取得し、プロキシ サーバーに対する PsPing または Ping 時間と比較します。
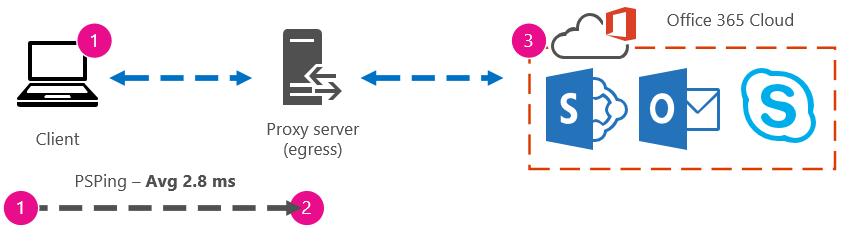
たとえば、クライアントからOffice 365 URL までの 51.84 ミリ秒があり、クライアントからプロキシ (またはエグレス ポイント) までの 2.8 ミリ秒がある場合、エグレスからOffice 365までの 49.04 ミリ秒があります。 同様に、1 日の高さの間にクライアントからプロキシに 12.25 ミリ秒、クライアントから Office 365 URL までの 62.01 ミリ秒の PsPing がある場合、Office 365 URL へのプロキシ エグレスの平均値は 49.76 ミリ秒です。

トラブルシューティングの観点から見ると、これらのベースラインを維持するだけで興味深いものが見つかる場合があります。 たとえば、プロキシまたはエグレス ポイントからOffice 365 URL までの待機時間が一般的に約 40 ミリ秒から 59 ミリ秒で、クライアントからプロキシまたはエグレス ポイントの待機時間が約 3 ミリ秒から 7 ミリ秒である場合 (その時間帯に表示されるネットワーク トラフィックの量に応じて)、プロキシまたはエグレス ベースラインに最後の 3 つのクライアントが表示される場合、問題が発生することがわかります。45 ミリ秒の待機時間。
高度なメソッド
Office 365するインターネット要求で何が起こっているのかを本当に知りたい場合は、ネットワーク トレースについて理解する必要があります。 HTTPWatch、Netmon、Message Analyzer、Wireshark、Fiddler、Developer Dashboard ツール、またはその他のツールがネットワーク トラフィックをキャプチャしてフィルター処理できる限り、これらのトレースに使用するツールは関係ありません。 このセクションでは、これらのツールの 1 つ以上を実行して、問題のより完全な画像を取得すると便利であることがわかります。 テストする場合、これらのツールの一部は、独自の権限でプロキシとしても機能します。 コンパニオン記事「Office 365のパフォーマンストラブルシューティング計画」で使用されるツールには、Netmon 3.4、HTTPWatch、WireShark が含まれます。
パフォーマンス ベースラインの取得はこの方法の単純な部分であり、多くの手順はパフォーマンスの問題のトラブルシューティングと同じです。 パフォーマンスのベースラインを作成するより高度な方法では、ネットワーク トレースを取得して格納する必要があります。 この記事の例のほとんどは SharePoint を使用しますが、テストと記録をサブスクライブするOffice 365 サービス全体で一般的なアクションの一覧を作成する必要があります。 ベースラインの例を次に示します。
SPO のベースライン リスト - ** 手順 1: ** SPO Web サイトのホーム ページを参照し、ネットワーク トレースを実行します。 トレースを保存します。
SPO のベースライン リスト - 手順 2: エンタープライズ Search経由で用語 (会社名など) をSearchし、ネットワーク トレースを実行します。 トレースを保存します。
SPO のベースライン リスト - 手順 3: 大きなファイルを SharePoint ドキュメント ライブラリにアップロードし、ネットワーク トレースを実行します。 トレースを保存します。
SPO のベースライン リスト - 手順 4: OneDrive Web サイトのホーム ページを参照し、ネットワーク トレースを実行します。 トレースを保存します。
この一覧には、ユーザーが SharePoint に対して実行する最も重要な一般的なアクションが含まれている必要があります。 OneDrive に移動してトレースする最後の手順では、SharePoint ホーム ページの読み込み (多くの場合、企業によってカスタマイズされる) と OneDrive ホーム ページの読み込みの比較が組み込まれています。これは、ほとんどカスタマイズされません。 これは、読み込みが遅い SharePoint サイトに関する基本的なテストです。 この違いのレコードをテストに組み込むことができます。
パフォーマンスの問題が発生している場合、多くの手順はベースラインを取る場合と同じです。 ネットワーク トレースが重要になるため、次に重要なトレースを取得する 方法 を処理します。
パフォーマンスの問題に対処するには、 現在、パフォーマンスの問題が発生している時点でトレースを実行する必要があります。 ログを収集するための適切なツールが必要であり、アクション プラン (可能な限り最適な情報を収集するために実行するトラブルシューティングアクションの一覧) が必要です。 まず、テストの日時を記録して、タイミングを反映したフォルダーにファイルを保存できるようにします。 次に、問題の手順自体に絞り込みます。 これらは、テストに使用する正確な手順です。 基本的な点を忘れないでください。問題が Outlook のみの場合は、問題の動作が 1 つのサービスでのみ発生することを必ず記録Office 365。 この問題の範囲を絞り込むには、解決できる内容に焦点を当てるのに役立ちます。